聚合报告-数据的分析实现
得到响应时间和其他的参数后,jmeter是怎么实现数据的收集和分析呢?
如何监控服务器端的cup等资源消耗情况呢?
jmeter如何实现
在线程组监听器添加聚合报告就可以收集数据。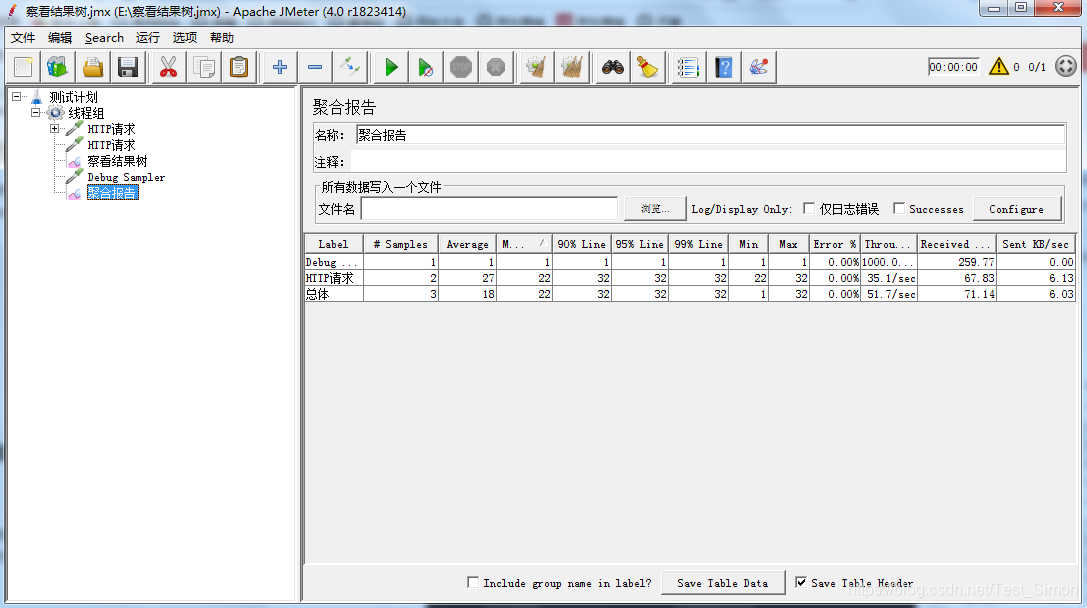
题外话-自己试着实现下
监控过程中如何实现监控数据与请求数据同步-线程守护的问题
比如下面的代码,请求执行完毕之后监控方法的线程任然会继续进行数据收集造成冗余数据产生,影响我们的分析结果的真实性。
import requests, time,random,hashlib,json,base64,threading
class kodcloud:
def __init__(self):
# self.session = requests.session()
self.access_token = ''
def Home_page(self):
for i in range(20):
start_time = int(time.time() * 1000)
resp = requests.get("http://127.0.0.1/index.php?user/login")
end_time = int(time.time() * 1000)
print("登陆的响应时间:%d毫秒"%(end_time-start_time))
#假装我在监控数据
def monitor(self):
i = 0
while True:
i= i+1
print("监控到的数据为%d"%i)
time.sleep(1)
if __name__=='__main__':
for i in range(30):
cd = kodcloud()
threading.Thread(target=cd.Home_page()).start()
threading.Thread(target=kodcloud().monitor()).start()
我们要设置线程的执行,让一旦主线程结束子线程也跟着结束。
看下面的代码
import time ,threading
def test():
for i in range(11):
print(time.strftime('%H:%M:%S'))
time.sleep(1)
if __name__ == '__main__':
# 线程在CPU面前没有区别
print("主线程开始")
t = threading.Thread(target=test).start()
print("主线程结束")
输出结果为:
主线程开始
17:42:16
主线程结束
17:42:17
17:42:18
17:42:19
17:42:20
17:42:21
17:42:22
主线程从print(“主线程开始”)语句开始print(“主线程结束”)语句结束,子线程继续执行。
实现方法
1)将子线程合并到主线程:
import time ,threading
def test():
for i in range(11):
print(time.strftime('%H:%M:%S'))
time.sleep(1)
if __name__ == '__main__':
# 线程在CPU面前没有区别
# t.join是将当前的线程加入到主线程之中(将线程加入两个print之间)
print("主线程开始")
t = threading.Thread(target=test)
t.start()
t.join()
print("主线程结束")
t.join()是把子线程t合并到主线程上去了。
得到结果是:
主线程开始
17:50:29
17:50:30
17:50:31
17:50:32
17:50:33
17:50:34
17:50:35
17:50:36
17:50:37
17:50:38
17:50:39
主线程结束
import time ,threading
def test():
for i in range(11):
print(time.strftime('%H:%M:%S'))
time.sleep(1)
if __name__ == '__main__':
# 主线程一旦结束,子线程t马上结束 t变为守护进程
print("主线程开始")
t = threading.Thread(target=test)
t.setDaemon(True)
t.start()
time.sleep(5)
print("主线程结束")
t.setDaemon(True)主线程一旦结束,子线程t马上结束 t变为守护进程
主线程开始
18:15:36
18:15:37
18:15:38
18:15:39
18:15:40
主线程结束
18:15:41
**守护线程t.setDaemon(True)在线程开始之前将其设置为守护线程。
情景理解法:
比如我要参加马拉松比赛,我好比就是个主线程,我的任务是跑到目的终点,我开跑10分钟后我的朋友骑车跟着我大喊加油,我的朋友就相当于是个子线程。
不设置守护线程t.setDaemon(True)情况是什么样的?
这种情况好比我跑完了都回家睡觉了,我的朋友还在马路上给我喊加油,线程疯了。
设置守护线程t.setDaemon(True)后相当于我跑完到终点后我的朋友就不喊加油了,和我一起回家了。
t.join()把子线程t合并到主线程上去了,join必须在线程启动之后调用,子线程没有结束主线程就不会结束。我们先找到主线程的开始点和结束点,主线程就是最先开始的线程。
t.join()合并到主线程的方法类似于这种情景:
我开车行驶在马路上我的任务是从街道的一端开到另一端,突然前面出现了一个30s红灯红灯的任务是亮30s,这个场景下我的车就好比主线程程,红灯相当于子线程。**
线程threading.trhread(),()中
target=test,target=后面的方法没有括号否则会有错误。
数据收集和处理
可以用设置全局变量的方法来收集数据。
import requests, time,random,hashlib,json,base64,threading
# 设置收集信息
cpu_list = []
rt_wait=[]
class kodcloud:
def __init__(self):
# self.session = requests.session()
self.access_token = ''
def Home_page(self):
for i in range(8):
start_time = int(time.time() * 1000)
resp = requests.get("http://127.0.0.1/index.php?user/login")
end_time = int(time.time() * 1000)
print("登陆的响应时间:%d毫秒"%(end_time-start_time))
rt_wait.append(end_time-start_time)
def monitor(self):
i=0
while True:
i=i+1
print("监控到的数据为-------------------"+str(i))
time.sleep(1)
cpu_list.append(i)
下图代码中t1.join()的地方就明显阻塞了主线程的进行后边的代码无法运行。
<十辆车要等到最后一个红灯变绿一起走>
Home_page 和 monitor应该是同时进行的。所以应该把t1.join()放在t2.start()后面。
if __name__=='__main__':
for i in range(10):
cd = kodcloud()
t1 = threading.Thread(target=cd.Home_page)
t1.start()
t1.join()
t2 = threading.Thread(target=kodcloud().monitor)
t2.setDaemon(True)
t2.start()
print(cpu_list)
print(rt_wait)
数据处理无非是求平均值,最大最小值,方差,平均差,90%数据所处范围,正太分布计算等等。直接调用对应的方法就可以计算。
def average(list):
sum = 0
for num in list:
sum +=num
avg =sum/len(list)
return round(avg,2)
def min_max(list):
list.sort()
min = list[0]
max = list[len[list] -1]
return min,max
def persent(list,ratio):
list.sort
index = int(len(list) * ratio/100)
return list[index-1]
