题目
- 以下是RNG S8 8强赛失败后,官微发表道歉微博下一级评论
数据说明:
rng_comment.txt文件中的数据:
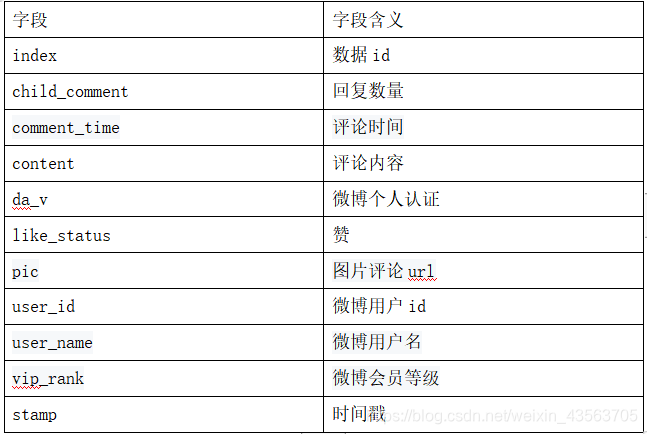
数据下载:
链接:https://pan.baidu.com/s/1OvNOmCQgANXfOuMUst0L5A
提取码:uaz9
1.1.在kafak中创建rng_comment主题,设置2个分区2个副本
bin/kafka-topics.sh --create --zookeeper node01:2181,node02:2181,node03:2181 --replication-factor 2 --partitions 3 --topic rng_comment
1.2.数据预处理,把空行过滤掉
package com.wzy.kafka
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Datas {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("Word").setMaster("local[*]")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN")
val datas = sc.textFile("file:///E:\\SparkCode\\SparkSql\\SparkSqlDya22_0409\\src\\rng.txt")
datas.filter(x => {
var file = x.split("\t");
file.length == 11
}).coalesce(1).saveAsTextFile("file:///E:\\SparkCode\\SparkSql\\SparkSqlDya22_0409\\src\\new_rng.txt")
}
}
1.3.请把给出的文件写入到kafka中,根据数据id进行分区,id为奇数的发送到一个分区中,偶数的发送到另一个分区
package com.wzy.kafka;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.io.*;
import java.util.Properties;
public class Producer {
public static void main(String[] args) throws IOException {
//1、配置kafka集群
Properties props = new Properties();
//kafka服务器地址
props.put("bootstrap.servers", "node01:9092,node02:9092,node03:9092");
//消息确认机制
props.put("acks", "all");
//重试机制
props.put("retries", 0);
//批量发送的大小
props.put("batch.size", 16384);
//消息延迟
props.put("linger.ms", 1);
//批量的缓冲区大小
props.put("buffer.memory", 33554432);
//kafka数据中key value的序列化
props.put("key.serializer","org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer","org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<>(props);
String line=null;
BufferedReader bufferedReader = new BufferedReader(new FileReader(new File("E:\\SparkCode\\SparkSql\\SparkSqlDya22_0409\\src\\new_rng")));
int partitioner=0;
while ((line=bufferedReader.readLine())!=null){
if (Integer.parseInt(line.split("\t")[0])%2==0){
partitioner=1;
}else{
partitioner=2;
}
ProducerRecord record = new ProducerRecord("spark_02", partitioner, partitioner + "", line);
kafkaProducer.send(record);
}
bufferedReader.close();
kafkaProducer.close();
}
}
1.4.使用Spark Streaming对接kafka
1.5.使用Spark Streaming对接kafka之后进行计算
在mysql中创建一个数据库rng_comment
在数据库rng_comment创建vip_rank表,字段为数据的所有字段
create table vip_rank
(
indes varchar(200) null,
child_comment varchar(200) null,
comment_time varchar(200) null,
content varchar(200) null,
da_v varchar(200) null,
like_status varchar(200) null,
pic varchar(200) null,
user_id varchar(200) null,
user_name varchar(200) null,
vip_rank varchar(200) null,
stamp varchar(200) null
);
在数据库rng_comment创建like_status表,字段为数据的所有字段
create table like_status
(
indes varchar(200) null,
child_comment varchar(200) null,
comment_time varchar(200) null,
content varchar(200) null,
da_v varchar(200) null,
like_status varchar(200) null,
pic varchar(200) null,
user_id varchar(200) null,
user_name varchar(200) null,
vip_rank varchar(200) null,
stamp varchar(200) null
);
在数据库rng_comment创建count_conmment表,字段为 时间,条数
-- auto-generated definition
create table count_conmment
(
time varchar(50) null,
count varchar(50) null
);
1.5.1.查询出微博会员等级为5的用户,并把这些数据写入到mysql数据库中的vip_rank表中
1.5.2.查询出评论赞的个数在10个以上的数据,并写入到mysql数据库中的like_status表中
1.5.3.分别计算出2018/10/20 ,2018/10/21,2018/10/22,2018/10/23这四天每一天的评论数是多少,并写入到mysql数据库中的count_conmment表中
package com.wzy.streaming
import java.sql.DriverManager
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.dstream.{DStream, InputDStream}
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
object StreamingAndKafka {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("Kafka").setMaster("local[*]")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN")
val ssc = new StreamingContext(sc, Seconds(5))
//准备连接Kafka的参数
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "node01:9092,node02:9092,node03:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "SparkKafkaDemo",
//earliest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费
//latest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,消费新产生的该分区下的数据
//none:topic各分区都存在已提交的offset时,从offset后开始消费;只要有一个分区不存在已提交的offset,则抛出异常
//这里配置latest自动重置偏移量为最新的偏移量,即如果有偏移量从偏移量位置开始消费,没有偏移量从新来的数据开始消费
"auto.offset.reset" -> "latest",
//false表示关闭自动提交.由spark帮你提交到Checkpoint或程序员手动维护
"enable.auto.commit" -> (false: java.lang.Boolean)
)
val topic = Array("spark_02")
//2.使用KafkaUtil连接Kafak获取数据
val recordDStream: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream[String, String](ssc,
LocationStrategies.PreferConsistent,//位置策略,源码强烈推荐使用该策略,会让Spark的Executor和Kafka的Broker均匀对应
ConsumerStrategies.Subscribe[String, String](topic, kafkaParams))//消费策略,源码强烈推荐使用该策略
var url="jdbc:mysql://localhost:3306/rng_comment?characterEncoding=UTF-8"
var user="root"
var password="root"
//3.获取VALUE数据
val result: DStream[Array[String]] = recordDStream.map(_.value().split("\t"))
//1.5.1.查询出微博会员等级为5的用户,并把这些数据写入到mysql数据库中的vip_rank表中
result.filter(x=>x(9)=="5").foreachRDD({
rdd=>{
rdd.foreachPartition({
iter=>({
val connection = DriverManager.getConnection(url, user, password)
var sql=
"""
|insert into
|vip_rank values
|(?,?,?,?,?,?,?,?,?,?,?)
|
|""".stripMargin
iter.foreach({
lien=>{
val statement = connection.prepareStatement(sql)
statement.setString(1,lien(0))
statement.setString(2,lien(1))
statement.setString(3,lien(2))
statement.setString(4,lien(3))
statement.setString(5,lien(4))
statement.setString(6,lien(5))
statement.setString(7,lien(6))
statement.setString(8,lien(7))
statement.setString(9,lien(8))
statement.setString(10,lien(9))
statement.setString(11,lien(10))
statement.executeUpdate()
statement.close()
}
})
connection.close()
})
})
}
})
//1.5.2.查询出评论赞的个数在10个以上的数据,并写入到mysql数据库中的like_status表中
result.filter(x=>x(5).toInt>10).foreachRDD{
rdd=>{
rdd.foreachPartition{
iter=>{
val connection = DriverManager.getConnection(url, user, password)
var sql=
"""
|insert into
|like_status values
|(?,?,?,?,?,?,?,?,?,?,?)
|
|""".stripMargin
iter.foreach{
lien=>{
val statement = connection.prepareStatement(sql)
statement.setString(1,lien(0))
statement.setString(2,lien(1))
statement.setString(3,lien(2))
statement.setString(4,lien(3))
statement.setString(5,lien(4))
statement.setString(6,lien(5))
statement.setString(7,lien(6))
statement.setString(8,lien(7))
statement.setString(9,lien(8))
statement.setString(10,lien(9))
statement.setString(11,lien(10))
statement.executeUpdate()
statement.close()
}
}
connection.close()
}
}
}
}
//1.5.3.分别计算出2018/10/20 ,2018/10/21,2018/10/22,2018/10/23这四天每一天的评论数是多少,并写入到mysql数据库中的count_conmment表中
val timeDataRdd: DStream[Array[String]] = result.filter {
x => {
val time: Array[String] = x(2).split(" ")
//2018/10/20 ,2018/10/21,2018/10/22,2018/10/23
if (time(0).equals("2018/10/20") || time(0).equals("2018/10/21") || time(0).equals("2018/10/22") || time(0).equals("2018/10/23")) {
true
} else {
false
}
}
}
timeDataRdd.foreachRDD {
rdd => {
rdd.groupBy(x => x(2).split(" ")(0)).map(x => x._1 -> x._2.size).foreachPartition {
iter => {
val connection = DriverManager.getConnection(url, user, password)
var sql =
"""
|insert into
|count_conmment values
|(?,?)
|
|""".stripMargin
iter.foreach {
lien => {
val statement = connection.prepareStatement(sql)
statement.setString(1, lien._1)
statement.setString(2, lien._2 + "")
statement.executeUpdate()
statement.close()
}
}
connection.close()
}
}
}
}
ssc.start() //开启
ssc.awaitTermination() //等待优雅停止
}
}
