第一章 介绍
历史背景
关于网络学科发展的历史背景,可以查阅维基百科 网络科学
以下为部分节选:
网络科学是研究诸如电信网络,计算机网络,生物网络,认知和语义网络以及社交网络之类的复杂网络的学术领域,考虑由节点(或顶点)表示的不同元素或参与者以及元素或参与者之间的连接作为链接(或边缘)。该领域利用包括数学图论,理论统计力学,数据挖掘和数据挖掘在内的理论和方法来自计算机科学的信息可视化,来自统计学的推理建模和来自社会学的社会结构…
网络分析的种类
每天,网络数据都从许多不同的领域搜集而来。每个领域都有他独有的问题以及研究方向,尽管如此,但从统计角度看,一套涉及网络科学相关领域共有任务和工具的方法论体系已经形成。与此同时,根据统计分类法,对跨不同领域的网络数据的分析中所面临的许多不同任务进行分类是可能的,并且确实是非常有用的。对应于网络本身的建模和推理,与网络上的过程相对应。
可视化和描述性网络
数据的描述性分析通常是标准统计学入门课程中遇到的第一个主题。相似地,一个网络的可视化和量化描述经常是网络分析的第一步。实际上,在实际操作中,描述性分析占了网络分析的绝大多数。有大量可用的网络概念是已经按照规定被定义好了的,这一类指标将会在 用R语言对网络数据进行统计分析(五) 中被详细介绍。这些特征从描述与单个顶点或边相关的性质到子图的性质,一直到图的整体性质,以一种有效的方式通过使用网络特征的技巧将基础复杂系统中的利益相关的问题与相应网络的适当概括性指标相匹配。
网络建模和推论
除了如何观察一个网络的外观以及描述它的结构,我们可能对网络如何出现更感兴趣。哲学意义上,我们可以认为网络的本质是反映了与我们感兴趣的复杂系统相关联的一些潜在过程的结果,而我们迫切地想知道这些过程的基本方面是什么。另外,在获得网络的实际方式中,相应测量和构建处理是我们要考虑的重中之重。这种关注提供了网络建模的动力和相关统计推论的工具。
网络建模得到了大量关注。一般说来,网络建模有两大类,分别是数学类和统计类。数学建模经常通过指定简单概率规则来生成网络,试图抓住某一特定机制或原则。相反的,统计建模指的是至少在一定程度上我们尽可能的去拟合观测数据。例如,评价网络中某些变量对边缘结构的解释能力,可以用统计推断的常用方法去影响和评估你和效果。
最简单的数学网络模型就是掷硬币模型。掷硬币模型对基于独立同分布硬币抛出结果的顶点对进行边的随机分配。许多论文中也提供了各种各样的统计网络模型,其中许多是经典统计中的并行模型。比如,指数随机图模型类似于广义线性模型,都是基于指数族形式。类似的,潜在网络模型指的是至少部分边界出现未知变量,则在层次建模中直接并行使用隐变量。随机块模型则可以看作是混合模型的一种形式。然而,考虑到数据通常具有高维度和扩展性,这类模型的规范及其拟合通常不那么标准。我们从协作建模到各种设置,都使用了这样的模型。
网络处理
在复杂系统的要素中,网络图往往是网络分析的首要重点。在许多背景中,实际上一些属性和系统中感兴趣的元素是相关联的。在这样的设定前提下,元素间的相互作用是一种影响数量的重要方式,因此网络图可能仍然与建模和分析相关。更确切地说,我们可以将一个随机过程描绘成”生活”在网络上,并由网络中的顶点进行索引。在这个过程中的所有问题,都可以被解释成静态或动态网络过程中的预测问题。
许多基于网络的视角本质上是动态的。因此,无不奇怪的,在网络定义的许多过程中也被认为是动态的。以公共卫生和疾病控制位例,比如通过人群了解疾病的传播(H1N1流感病毒),可以通过网络图来模拟二进制动态过程(表示受感染和未受感染)的扩散,其中顶点代表个人,而边则代表个体之间的接触。数学建模(同时使用了确定性和随机模型)仍然是这类建模过程的主要工具,但是基于网络的统计建模逐渐得到越来越多的使用,特别是当获得更高质量以及更广泛的网络数据成为可能的时候。另一个类似的想法和建模是关于消费者产品选择的模型,比如预测下一代iPhone发布的早起使用者变换。
除此之外,我们还将研究网络流的统计方法。从原产地到目的地,涉及到一些物流、人员和商品的流动。流动是一种特殊类型的动态过程,比如交通网络(航空公司)和通信网络(互联网信息包的移动)。
为什么要选择R语言来处理
可以使用各种工具进行网络分析。其中一些是标准的,比如经典的Pajek工具或者更新的Gephi。另一些则被嵌入到编程环境中,并被用作编程库。之后有一些例子是Pyhton的NetworkX和R中的igraph。如果现状持续发展,R正在迅速成为统计研究的实际标准,大多数新的统计都是在R中使用的。
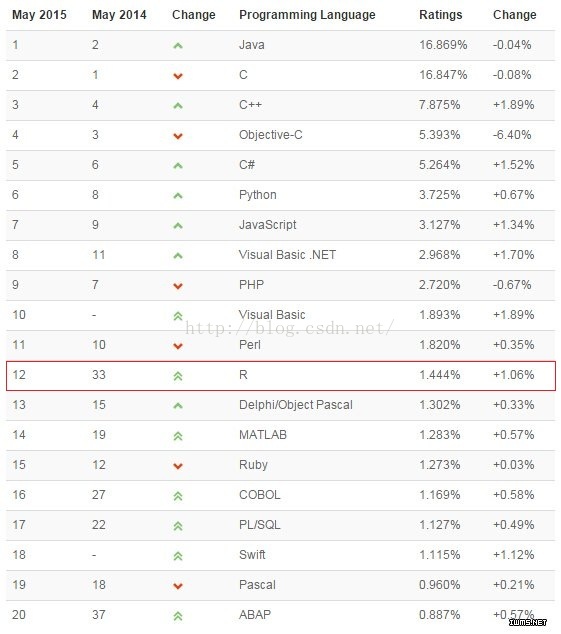
虽然网络分析是一个跨学科领域,但他并不是这趋势的例外。几个r包实现了多个网络分析算法,提供了用于操作网络数据和实现网络算法的通用工具。r支持高质量图形和通用的文件格式,并且r支持可扩展性,目前已经超过5000个扩展包,研发速度还在加快。
作为一门完整的编程语言,r为网络研究提供了很大的灵活性。新的网络分析算法可以在现有的网络科学包上快速建立原型,其中最常用的是igraph包。
方便的扩展性:
– 可通过相应接口连接数据库,例如 Oracle、DB2、MySQL。
– 同 Python、Java、C、C++等语言进行互调。
– 提供 API 接口均可以调用,例如 Google、Twitter、Weibo。
– 其他统计软件大部分均可调用R,例如 SAS、SPSS、Statistica 等。
– 甚至一些比较直接的商业应用,例如 Oracle R Enterprise、R add-on for Teradata、Sybase RAP 等。
关于r语言的质量:
很多人认为R语言是 GNU 开源项目软件,因此软件的使用是“没有任何保证”的。但在美国,R的计算结果被 FDA(Food and Drug Administration) 所承认;并且有报告指出与其他商业软件相比,R的 Bug 数量非常少【注:UCLA (2006). R relative to statistical packages. Technical report, UCLA.】。
R 开发的核心团队对于R的新功能持异常谨慎的态度,比如 cairographics 从 2007 年开始酝酿,直到上一个大版本(2011年)才引入到R标准安装程序;byte-compile 功能更是经历了从 1999-2011年近 12 年的孵化【注:Ripley,B. (2011). The r development process. Technical report,Department of Statistics,University of Oxford.】。从这个角度讲,R语言的代码质量以及运算结果的可信性是完全可以保证的。
当然,这里所说的是R的标准安装程序包,并不代表所有扩展包的质量。毕竟 3400+ 的扩展包质量良莠不齐,虽然不乏一些优秀的包(如 Rcpp、RODBC、VGAM、rattle),但必然存在一些扩展包质量不佳的情况。