一:概念
c++不是一个完全面向对象的语言,它是基于面向对象的语言,因为我们的c++语言中还包含C语言的东西,而我们的C语言是一个面向过程的语言
面向对象的的三大特征:封装继承多态
类:里面有数据(变量)和方法(函数)
三种访问限定符:public:可从类的外部直接访问,private/protected不可从外部直接访问
每个限定符可以使用多次,每个限定符的作用域是从此限定符开始到下一个限定符结束
如果不加限定符,则默认为私有
我们可以在类里定义函数,也可以只在类里声明,在别的文件里定义函数
类的实例化对象:我们在刚开始创建一个类的时候编译器是不会给它开辟空间的,而我们在对类实例化除对象的时候才会给类开辟除空间
那么我们的类编译器在开辟空间的时候,是怎么开辟空间的的呢?
我们其实可以发现,在给类开辟空间的时候,是不会给函数开辟空间(这是因为,要是我们给类的每一个实例化的对象的函数的开辟空间的话,那么就太浪费空间了,所以编译器在优化的时候,讲这些一样的函数放在一个公共空间里,所以你sizeof类的时候只有变量占用的空间。而这个歌变量占用空间是和结构体一样要
内存对齐
的,对齐的规则和结构体的规则相同)
说到这我们其实可以发现一个问题,那么为什么结构体和类要内存对齐呢?有的人说是为了提升效率,那为什么会提升效率呢?
我们在根据地址来读取数据的时候都是四个字节四个字节读取的,所以我们在进行内存对齐了之后再访问数据的时候就可以直接一次就找到,要是没有进行内存对齐的话,我们在访问数据的时候就有可能得访问两遍
知道了这些我们来看一下这两个类的大小
1.
class A
{
};
2.class B
{
void test();
};
用sizeof来计算这两个类大小的话,我们都可以发现这两个类的大小都是1
首先我们来看第一个类,很明显他是一个空类,那空类的大小为什么回事1呢,我们可以这样想,当我们在对这个类实例化出对象的时候,它的大小早已经在定义类的时候就定义出了大小那么我们难道说实例化出的这个对象的大小是1么,所以空类的大小就是1
第二个类,首先我们在计算类的大小的时候,是不计算类里成员函数的大小的,只计算变量的大小,我们发现这个类里没有变量,只有函数,那么他其实也就相当于一个空类,那么其实大小也就相当于空类的大小,亦是1
二:c++的默认成员函数
1.this指针
首先我们来看一段代码
#define
_CRT_SECURE_NO_WARNINGS
1
#include
<iostream>
class
Date
{
public
:
void
date()
{
printf(
"%d-%d-%d "
, _year, _month, _date);
//cout << _year << "-" << end1;
}
private
:
int
_year = 2018;
int
_month = 03;
int
_date = 18;
};
int
main()
{
Date
A;
A.date();
return
0;
}
这段代码打出来的内容是2018-03-18,那么我们可以发现,我们又没有对这个函数进行传参。那为什么函数打出来成员变量的值呢?
其实类的每一个成员函数都会有一个this指针
特点:
每个成员函数都会有一个隐藏的参数即this指针
编译器会对this指针进行处理,在对象调用函数的时候,类的地址作为一个实参传递给成员函数的第一个形参this指针
此this指针为编译器自己处理的,我们不可以在函数的定义中定义此this指针,也不能在调用时显示调用此函数的对象的地址给this指针
(即不能调用,但可以在函数内部使用)
2.类的默认成员函数
类的默认成员函数有6个分别为:构造函数,拷贝构造函数,析构函数,赋值运算符重载,取地址操作符重载,const修饰的取地址操作符重载
构造函数
我们一般在定义成员变量的时候,一般都会将这些变量定义为私有的不允许外部去改变它的值,那么我们怎么去初始化这些私有的成员变量呢
我们的c++里就给我们带了一个默认的初始化的函数,这个函数在我们定义对象的时候,调用一次对变量进行初始化
特点:
函数名为:类名
函数无返回值(无参的构造函数说它无参数,其实他的形参里有一个this指针将对象的地址作为参数传入函数,对这个对象进行初始化)
在构造对象的时候编译器直接调用一次
构造函数可以重载
构造函数可以在类外定义也可以在类里定义
如果我们在定义类的时候没有电话已构造函数,那么c++编译器里会自动生成一个缺省的构造函数,但是只要我们定义了一个构造函数,那么这个编译器里自带的构造函数就不会生效
我们在定义构造函数的时候
,
无参的构造函数和全部缺省的构造函数都认为是缺省的构造函数所以只能有一个
(
因为我们在调用这两个构造函数的时候,都是无参的,那么编译器会不知道调用的是哪个函数,所以这两个函数只能有一个)
构造函数可以有多个可以被重载,可以带参数
在实例化出对象之前,调用构造函数之后会得到一个匿名对象
拷贝构造函数
拷贝构造函数就是在实例化一个新对象的同时,将另一个它
同类的对象
的值拷贝给这个新对象
特点:
此函数就是构造函数的一个重载
拷贝构造必须使用引用传参,不然会导引发递归的无穷调用
如果我们没有人为的定义一个拷贝构造函数,那么c++的编译器也会自带一个缺省的拷贝构造函数,然后这个默认的函数便会生效
那么我们思考一下不用引用传参的话为什么会导致递归的无穷调用呢?
class Date
{
private:
int _year;
int _month;
int _day;
};
int main()
{
Date d;
Date(d2);//调用拷贝构造函数
}
如果在调用我们自己定义的拷贝构造函数(参数为传值)的时候,我们知道在传参的时候,形参是实参的一份临时拷贝,而我们在将实参传递给形参的时候就要调用一次拷贝函数而在调用拷贝函数的时候又要进行参数的拷贝,这是一个死循环,所以我们在传参的时候一定要传引用,就可以很顺利的将值拷贝进去
那么什么时候回调用到拷贝构造函数呢?
1)在我们用一个对象初始化另一个对象的时候
2)一个对象以值传递的方式进入函数体(形参的实例化,形参是实参的一份临时拷贝)
3)一个对象以值传递的方式从函数返回(将此值放入一个临时的寄存器里进行返回)
我们要注意的是在进行指针的拷贝的时候一定要自己写,不能使用默认的拷贝构造函数,因为我们拷贝出来的指着指向同一块内存,在进行析构函数调用的时候就会有问题,因为你两个对象要析构两次,但两次都是析构同一块内存,就会报错
析构函数
当一个函数的声明周期结束的时候,c++编译器会自动调用一个函数来销毁我们在堆上开辟的空间,此函数就为析构函数
特点:
函数名为:~类名
析构函数无参无返回值
一个类有且只有一个析构函数,我们没有人为的定义,编译器会自动生成一个缺省的析构函数
对象的生命周期结束的时候,编译器自动调用析构函数
析构函数并不是删除对象,而是做一些清理工作
当一个类的生命周期结束的时候,函数的调用栈桢自动销毁,但是如果我们在堆上开辟了空间,编译器是不会自动销毁的,这就需要我们人为的去释放空间,这就是析构函数的作用
析构函数只能有一个,不能被重载不能带参数
运算符重载
首先我们来看一个最要的
赋值运算符的重载:
重点是区分赋值运算符的重载和拷贝构造函数
赋值运算符是在给一个已经定义好了的对象进行赋值,而拷贝构造函数则是对一个对象进行定义的同时进行赋值
例如:
拷贝构造函数
Date A;
Date();//调用构造函数
Date B(A);//
赋值运算符重载:
Date A;
Date();
Date B;
B=A;//此为赋值运算符的重载
那我们接下来再看一个
Date A;
Date();
Date B=A;/
/此还是拷贝构造函数
最后我们来说一个构造函数,拷贝函数,赋值运算符的重载的不同:
当我们定义一个空类的时候这几个函数都默认都存在
但是在使用的时候,我们要一定要区分请拷贝构造和赋值运算符的重载
只需记住这三句话就可以:
对象不存在,且没用别的对象来初始化,就是调用了构造函数;
对象不存在,且用别的对象来初始化,就是拷贝构造函数;
对象存在,用别的对象来给它赋值,就是赋值函数;
三:const&内联&友元&静态成员
const
const修饰成员函数的时候,写在函数的后边,const修饰this指针所指向的对象就是保证调用这个const成员函数在调用者内部不会被改变
并且编译器在执行的时候会这样,红字部分是编译器做的,并且因为是const修饰的,变量不可变
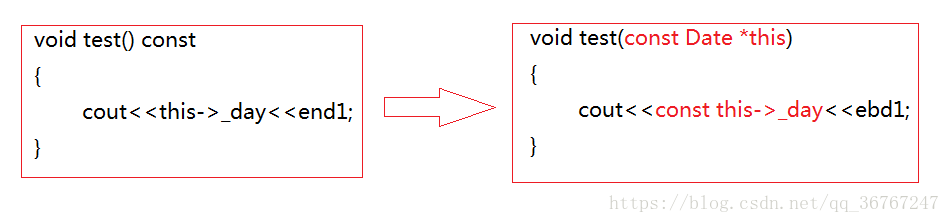
并且:
const的对象可以调用const修饰的成员函数,同样的非const对象也可以调用非const的成员函数
const对象不可以调用非const修饰的成员函数,因为这是对权限的一种放大
非const对象可以调用const修饰的成员函数,这是对权限的一种缩小
我们只要记住一句话,权限只能缩小不能放大即可
inline(内联)
在说内联函数之前,我们先说C语言中的宏:
那么宏的优点和缺点是什么?
首先宏分为两种:宏函数:没有类型的检查;不方便调试;代码的可读性和可维护性差;
宏常量:可读性和可维护性较强
而我们的c++编译器则针对宏函数的这些缺点做了改进,引入了内联
c++编译器会在内联函数的的调用的地方将此内联函数展开,这直接就少掉了函数压栈的开销,提高了代码运行的效率
内联的特点:在类里定义的函数都默认为内联函数
内联是一种以空间换时间的一种做法,但是如果代码太长或者有递归则不适用内联
内联对于编译器来说只是一个建议,至于最后是不是内联函数还是取决于编译器
inline必须和定义放在一起才会成为内联函数,只是将inline和声明放在一起是不起作用的
所以c++建议使用内联,const,enum去尽量的代替#define
那么用这些代替宏的好处都有啥呢?
首先增强了代码的复用性:比如说我们有时候在宏里定义一个变量,调用一次这个宏还行,但是调用两次就会出现变量重定义的情况,代码的复用性就不时很好,但是其实我们可一个给宏的两边加上一对花括号即可,单数最根本解决此问题依旧还是函数的内联
也提高了性能
友元(friend)
友元函数:
在c++的类中声明一个函数,这个函数可以访问这个类里的成员函数和成员变量,就想我们在类里定义的成员函数一样
特点:友元函数不是类的成员函数
友元函数可访问类的所有成员,私有和保护成员也一样
友元类:整个类可以是另一个类的友元类,友元类得成员函数都是另一个类的友元函数,都可以访问另一个类的成员
但是我们所说的友元,是单向性的,不是双向性的,并且友元这个东西破坏了函数的封装,所以友元不宜多用,在恰当的地方用
静态成员
在类里用static修饰的成员为静态成员
类的静态成员是类的所有成员所共享的(就像类的成员函数一样静态的类的成员变量都保存在一个公共的区域供所有对象使用)
注意:类的静态成员函数没有this指针,所以我们在调用的时候用,类型,作用域访问符,直接访问该成员函数