目录
将IMEI(MEID)+uin进行MD5,取其前7位就是密码(32位小写),保存下来
对EnMicroMsg.db解密(使用sqlcipher这个工具数据库查看)
导语
是否还在为无法导出聊天级录而苦恼?史上最强攻略来了,不用root手机,不用会代码,不限制任何机型,只要你有一颗想动手的心!
工具
- 电脑(笔记本,台式都行)
- md5转换网址
原理
微信聊天数据是一个db文件,而我们知道db里面是各种表,表里就有我们想要的聊天信息,但是微信的数据库不可能不加密,经过百度我们可以知道它的密码是由微信的uin号加上手机的IMEI码进行MD5加密取前7位构成的,但是数据库文件肯定不让我们获得,除非获得手机最高权限,也就是root,但是现在的手机基本不准root了,咋办呢?其实这不是难题,有电脑啥都好说。因此我们就可以大展手脚了。
步骤
- 首先登录电脑微信,备份聊天记录到电脑上
- 电脑下载安卓模拟器(鄙人用的是夜神)
- 获取手机IMEI码
- 安卓模拟器下载并安装微信
- 模拟器登录微信
- 获取微信的uin号
- 将IMEI(MEID)+uin进行MD5,取其前7位就是密码(32位小写),保存下来
- 电脑微信还原聊天记录到安卓模拟器微信上
- 获得数据库文件复制到电脑上
- 对EnMicroMsg.db解密(使用sqlcipher这个工具数据库查看)
- 导出数据库表格为csv文件
- 完成
步骤截图
-
首先登录电脑微信,备份聊天记录到电脑上
- 这一步就不用截图了,自己手机跟电脑连在同一个wifi下,然后电脑端选择备份记录到电脑,手机确认就可以了,备份完后自己手机登出微信帐号
-
电脑下载安卓模拟器(鄙人用的是夜神)
- 这一步也不用截图了,自己下载模拟器去
-
安卓模拟器下载并安装微信
-
模拟器登录微信
-
获取微信的uin号
- 模拟器微信登录成功后打开模拟器文件管理器

- 打开微信存储路径,这里模拟器会使用root模式,模拟器一般都是root的,微信存储路径一般为data/data/com.tencent.mm/MicoMsg
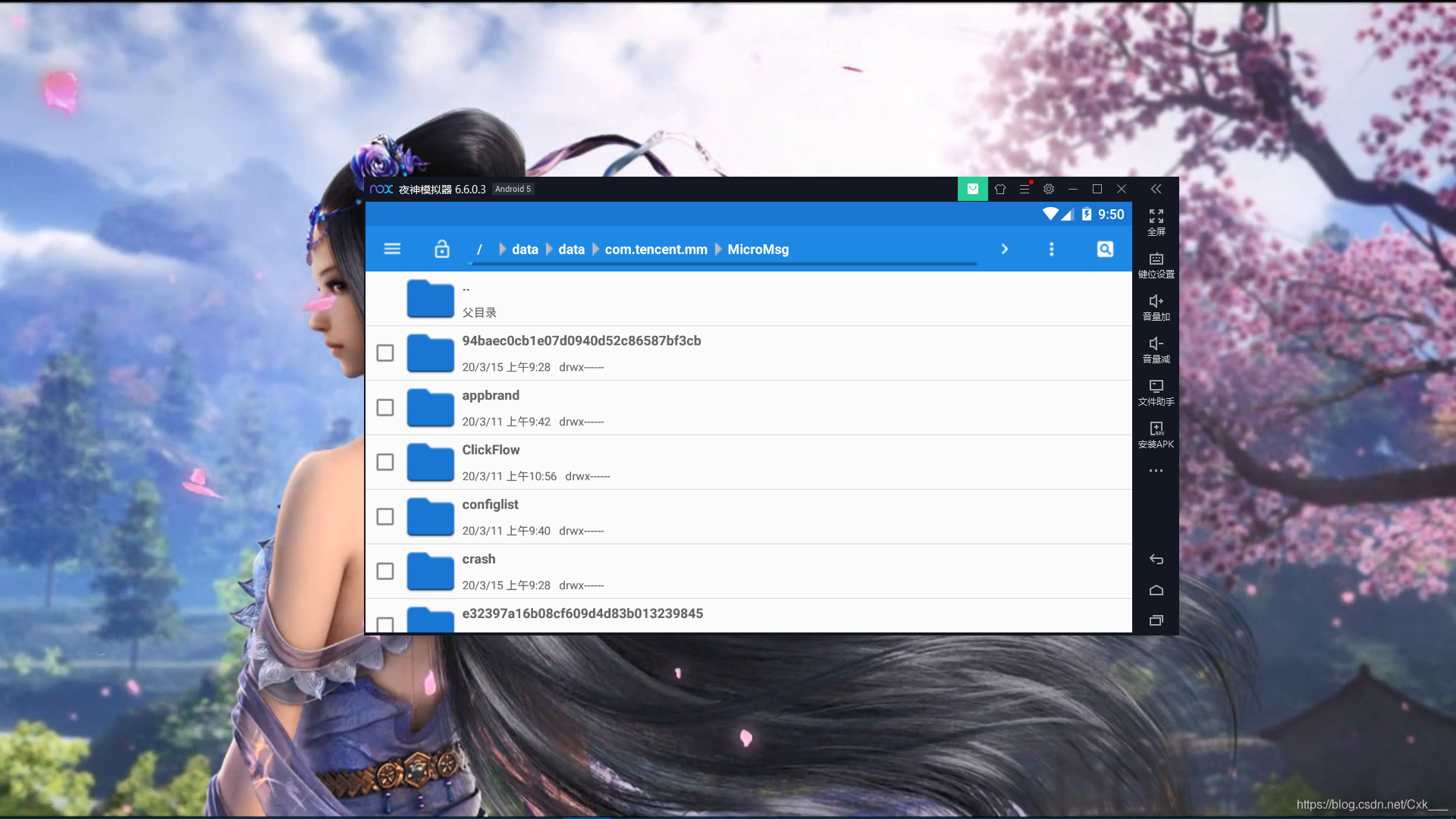
- 进入MicoMsg后在当前文件夹下找到system_config_prefs.xml文件
- 将该文件复制出来,夜神有个模拟器跟电脑共享文件夹,在旁边,叫文件助手,我们先选中该文件,然后打开安卓共享文件夹,进入粘贴选择项就ok了
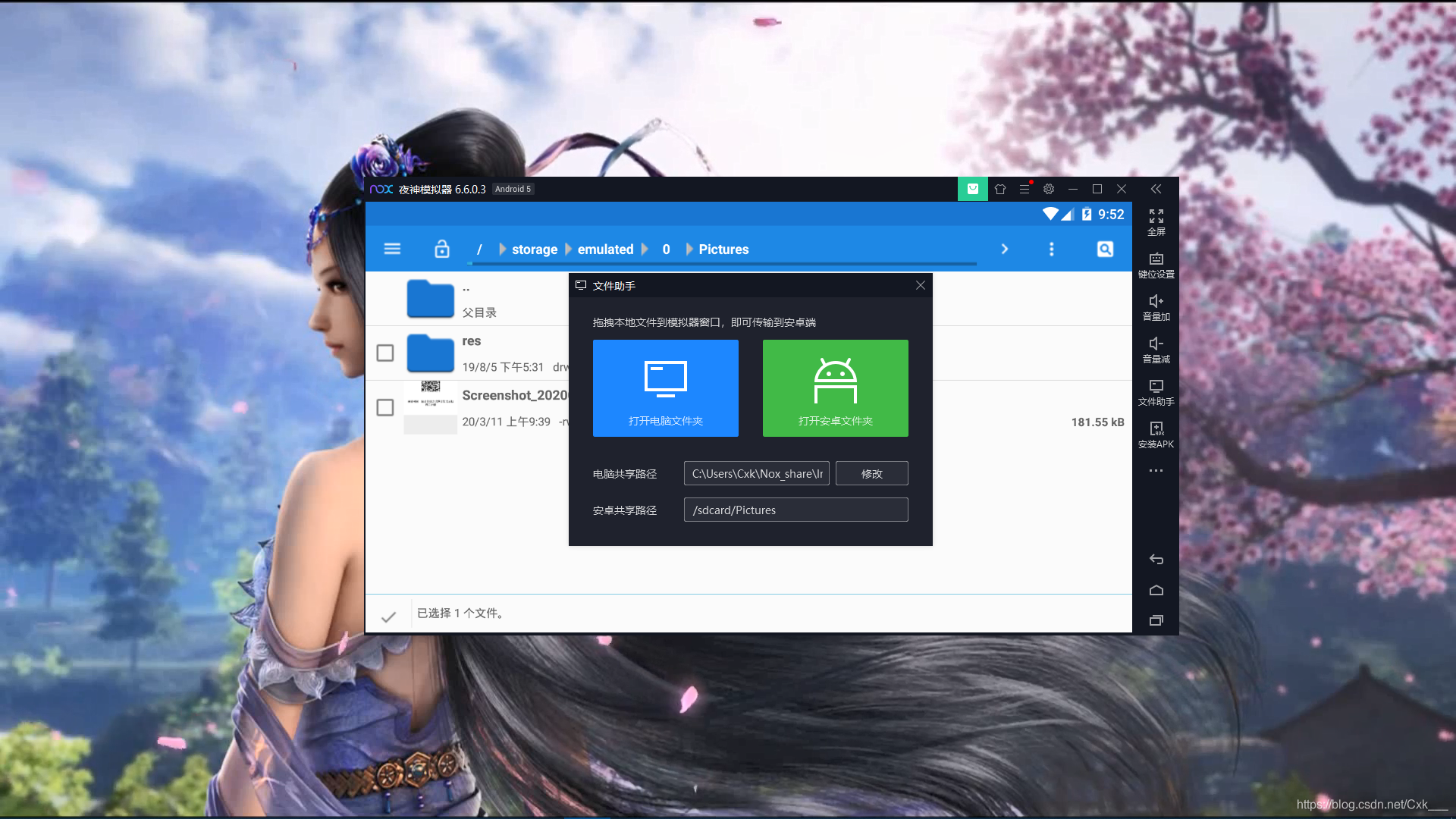
- 然后打开模拟器文件助手,打开电脑端文件夹就可以看到system_config_prefs.xml文件,我们用记事本打开就可以找到uin号,复制保存下来

-
获取手机IMEI码
- 打开自己模拟器的设置界面,这里以夜神为例,在手机与网络就有生成的IMEI码,使用默认的,不要随机创建,复制保存下来
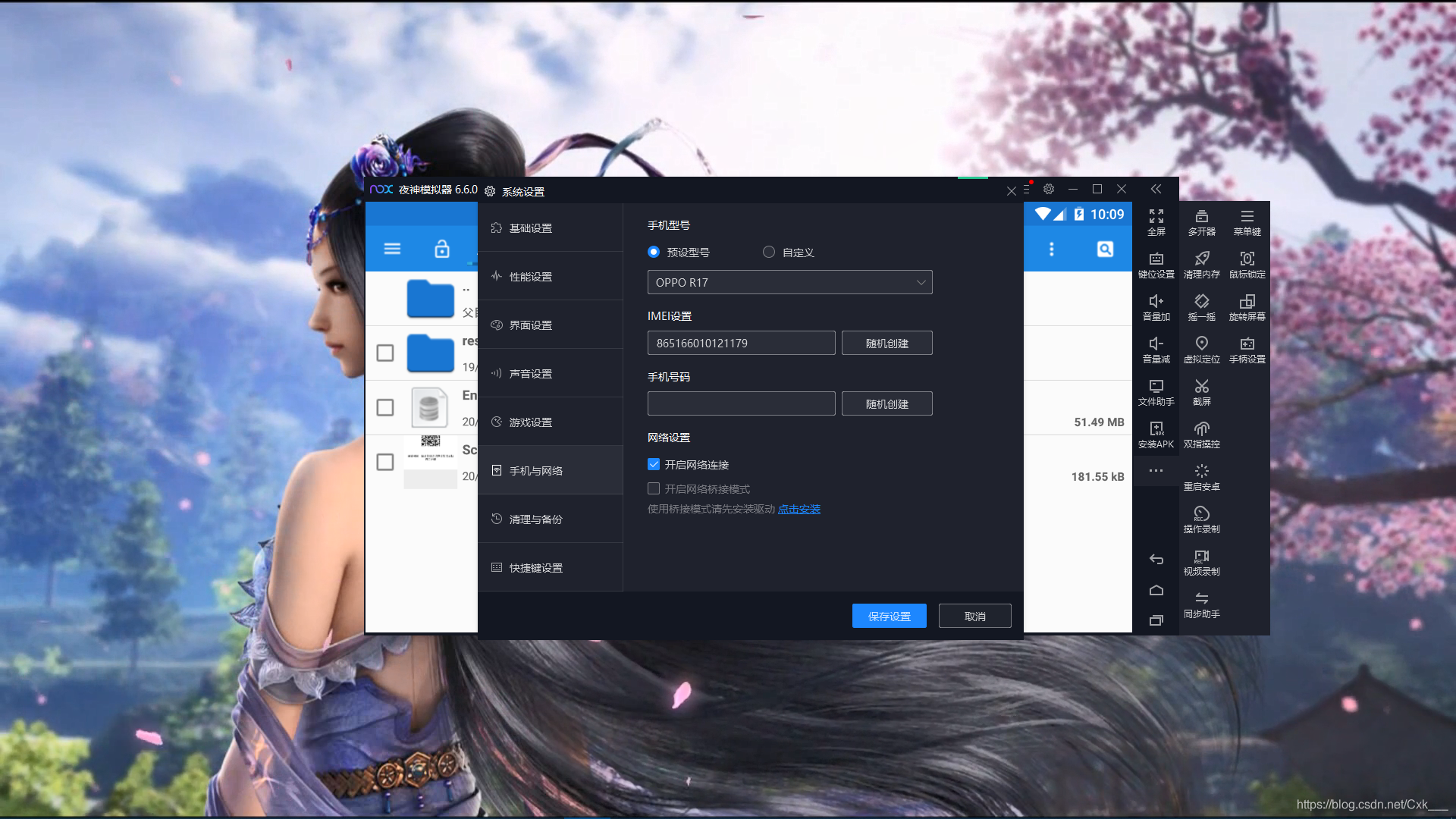
-
将IMEI(MEID)+uin进行MD5,取其前7位就是密码(32位小写),保存下来
- 到该网站进行转换,选择32位(小)md5转换网址
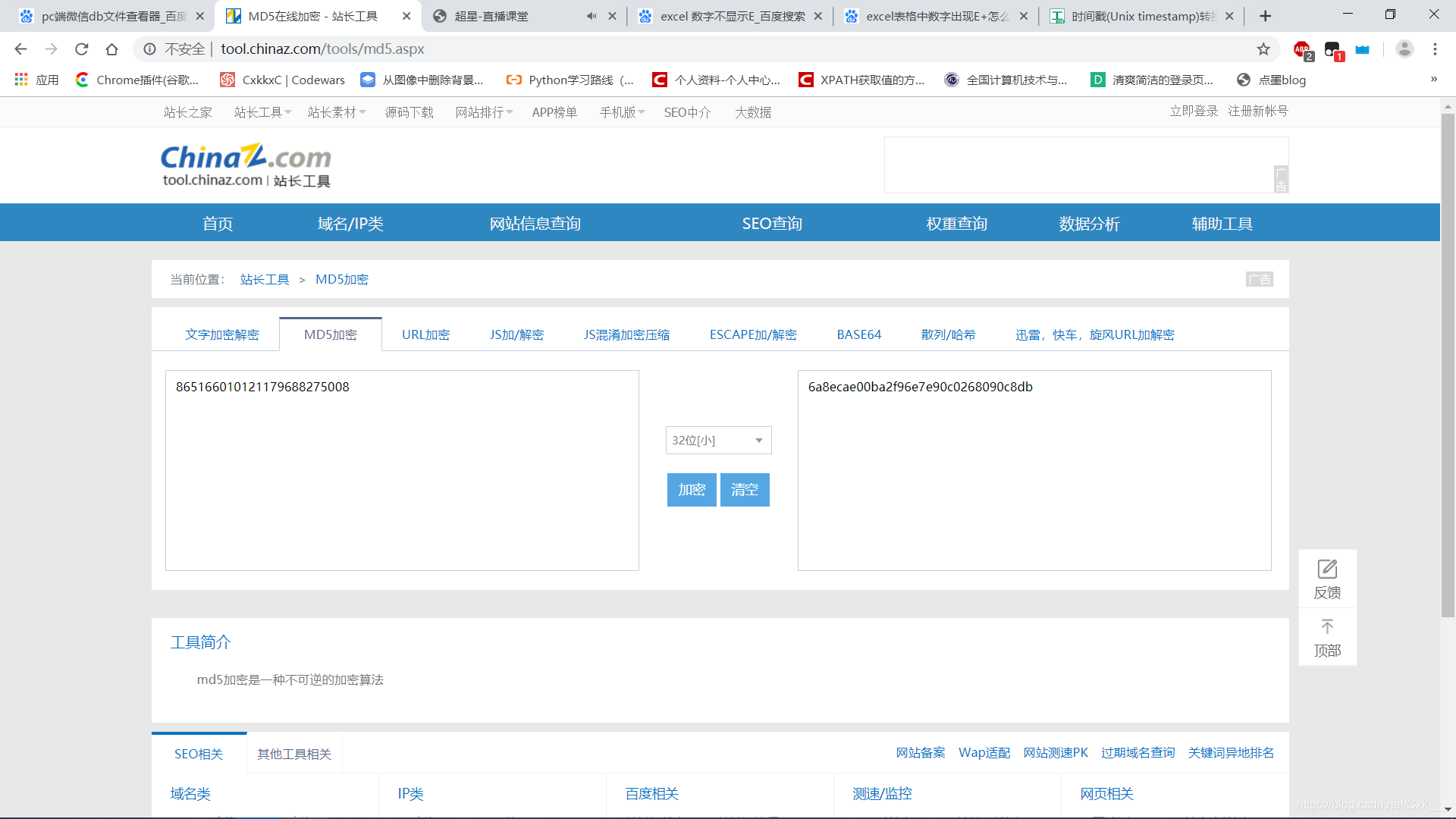
-
uin: 688275*** imei: 865166010121179 md5: 6a8ecae00ba2f96e7e90c0268090c8db 前七位: 6a8ecae
-
电脑微信还原聊天记录到安卓模拟器微信上
-
获得数据库文件复制到电脑上
- 到刚才所说的微信路径下找到EnMicroMsg.db并选择复制到电脑共享文件夹下
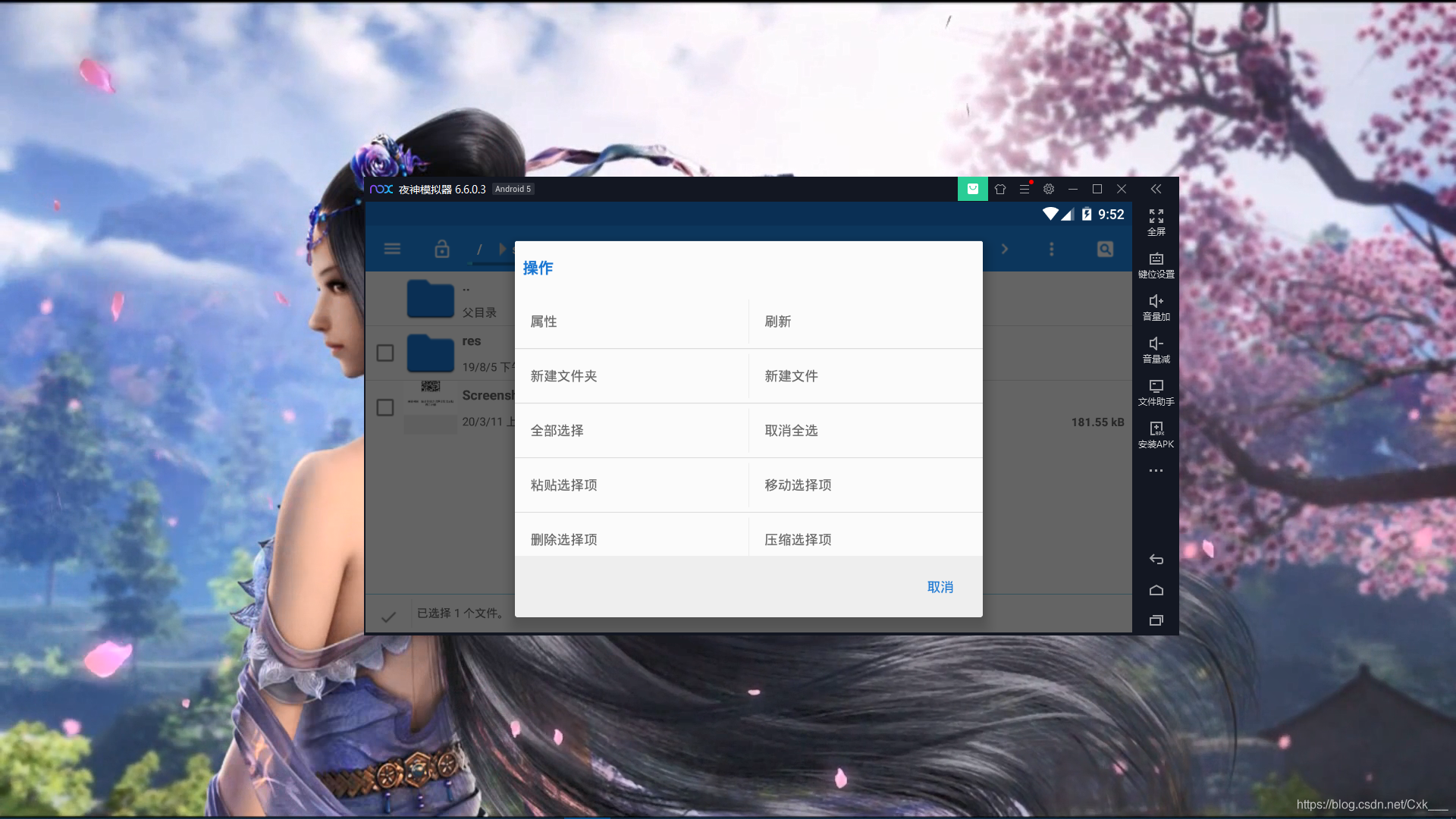
-
对EnMicroMsg.db解密(使用sqlcipher这个工具数据库查看)
- 复制出来后模拟器就没啥用了,交给电脑了
- 我们打开sqlcipher这个工具数据库打开EnMicroMsg.db输入密码就可以查看了
- 聊天记录在message这个表格中,我们按图中所示导出该表格为csv文件
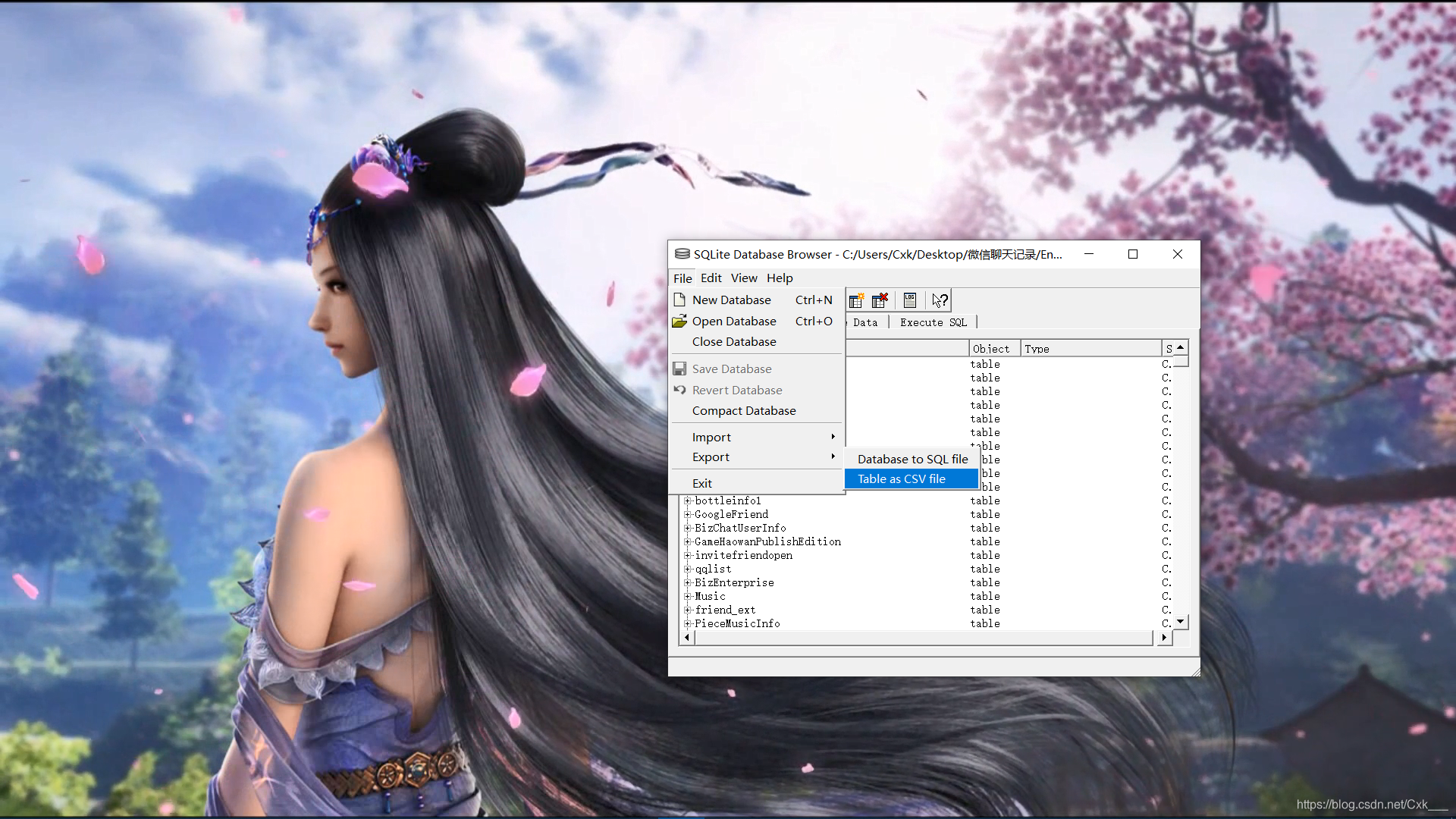
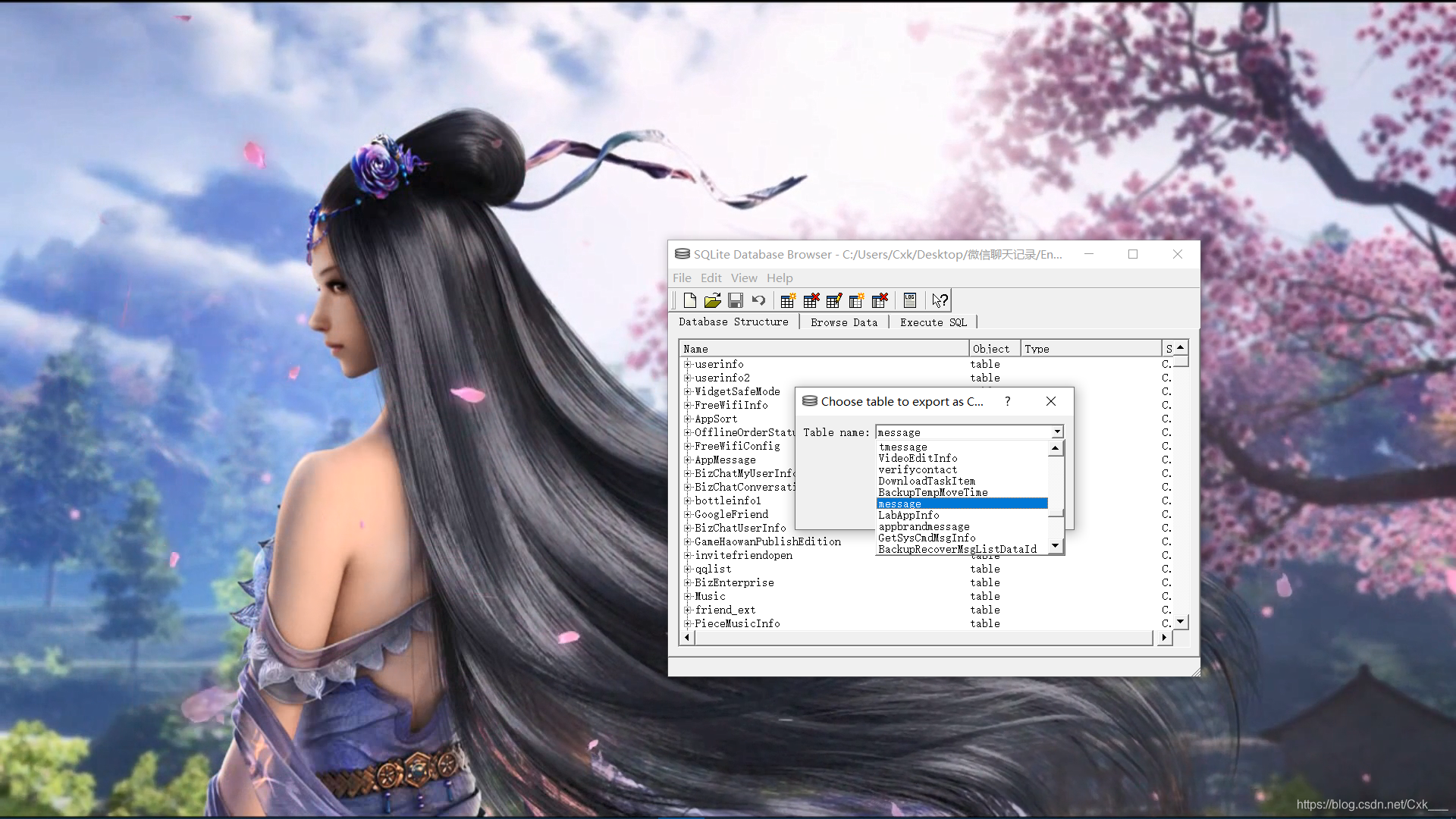
- 导出成功
-
导出数据库表格为csv文件打开

- 表格属性中isSend值为1就是我们本人发送,0则是对方发送,createTime 聊天时间戳 content 聊天内容
-
完成

附加做成词云代码
import openpyxl
import threading
#多线程处理,本人聊天记录为73622行,四个线程处理,每个17000多行,我先将无关列删去,留下四列,序号,isSend,createTime,还有content,所以我选择判断是谁发送的,再保存聊天记录
def cxk1():
for i in range(2,17905):
try:
#判断是谁发送
if str(sh.cell(row=i, column=1).value)=='0':
#保存第四列的聊天记录
file.write('傻猪:'+sh.cell(row=i, column=4).value+'\n')
else:
file.write('\t\t\t\t\t\t\t'+sh.cell(row=i, column=4).value+':帅哥凯'+'\n')# A表示列,1表示行
except:
continue
print('1_ok')
def cxk2():
for i in range(17905,35810):
try:
if str(sh.cell(row=i, column=1).value)=='0':
file.write('傻猪:'+sh.cell(row=i, column=4).value+'\n')
else:
file.write('\t\t\t\t\t\t\t'+sh.cell(row=i, column=4).value+':帅哥凯'+'\n')# A表示列,1表示行
except:
continue
print('2_ok')
def cxk3():
for i in range(35810,53715):
try:
if str(sh.cell(row=i, column=1).value)=='0':
file.write('傻猪:'+sh.cell(row=i, column=4).value+'\n')
else:
file.write('\t\t\t\t\t\t\t'+sh.cell(row=i, column=4).value+':帅哥凯'+'\n')# A表示列,1表示行
except:
continue
print('3_ok')
def cxk4():
for i in range(53715,71622):
try:
if str(sh.cell(row=i, column=1).value)=='0':
file.write('傻猪:'+sh.cell(row=i, column=4).value+'\n')
else:
file.write('\t\t\t\t\t\t\t'+sh.cell(row=i, column=4).value+':帅哥凯'+'\n')# A表示列,1表示行
except:
continue
print('4_ok')
def fun1():
th=threading.Thread(target=cxk1)
th.setDaemon(True)#守护线程
th.start()
def fun2():
th=threading.Thread(target=cxk2)
th.setDaemon(True)#守护线程
th.start()
def fun3():
th=threading.Thread(target=cxk3)
th.setDaemon(True)#守护线程
th.start()
def fun4():
th=threading.Thread(target=cxk4)
th.setDaemon(True)#守护线程
th.start()
#将聊天记录导出到txt文件
file = open('CxkAndLhm.txt','w')
#你导出的微信聊天记录文件,先将csv转为xlsx文件
wb = openpyxl.load_workbook('weixin.xlsx')
sh = wb['weixin']
fun1()
fun2()
fun3()
fun4()
wb.close()
file.close()
# 词云库
from wordcloud import WordCloud
import PIL .Image as image
import numpy as np
with open("CxkAndLhm.txt") as fp:
text=fp.read()
# print(text)
# 将文本放入WordCoud容器对象中并分析
# 词云图片
mask = np.array(image.open("1.jpg"))
#字体:C:\Windows\Fonts\FZSTK.TTF C:\Windows\Fonts\FZLTCXHJW.TTF
font="C:\Windows\Fonts\FZLTCXHJW.TTF"
WordCloud =WordCloud(
# 设置字体,不指定就会出现乱码
font_path=font, # 这个路径是pc中的字体路径
# 设置背景色
background_color='white',
# 词云形状
mask=mask,
# 允许最大词汇
max_words=100,
# 最大号字体
max_font_size=100,
# 设置有多少种随机生成状态,即有多少种配色方案
random_state=30,
# 清晰度
scale=3
).generate(text)
image_produce = WordCloud.to_image()
image_produce.show()
print('完成')

结语
到这我们就完成了微信聊天数据的导出,我们可以用导出的数据进行处理了,做成词云或者数据清洗都行。编写不易,留赞可行?
