前言
为什么要写这个应用?因为博主爱看动漫,但是有些动漫需要VIP,而且有些动漫在我用的那几个视频网站里甚至都搜不到资源,相信爱看动漫的铁汁应该也遇到过这个问题。于是我就想着自己写一个动漫应用,这样就能一站式解决我的看番需求了,因为之前用爬虫写过一个小说APP,所以理由当然的第一时间就想到了用爬虫来完成这个应用。然后找资源网站,实现功能代码,优化观看体验。。。终于,在今天这个应用的1.0.0版本实现了。写下这篇文章一是记录整个开发的流程,便于日后参考,二是分享出来有需要的可以借鉴一下。下面进入正题。
正文
一、寻找合适的网站
这一步就是根据自己需求,去找合适的网站,之后的数据都要通过这个网站来获取。博主需要爬取的是动漫资源,自然是找那种资源全面且免费的。刚开始是想爬B站,但是有些视频资源需要会员才能看,于是放弃,后续也没多久就锁定了目标-xxxx(就不透露姓名了哈哈),因为我之前有用这个网站看过一个B站收费的番。
二、获取目标网站的Html内容
1.获取网站的搜索接口
博主想要做的是输入搜索关键词就能出来相应的搜索内容,于是我需要先搞到网站的搜索接口地址,这一步很简单,只需要在网站的搜索条里输入一个关键词,按F12打开开发者模式,点击搜索,再在开发者界面的network选项里查看调用的网址即可,或者直接看浏览器的网址输入条也行,一般你会得到这样一个网址:www.xxxx.com?keyword=xxx。这样的网址就一目了然,你要检索某个关键词,只需要拼接在keyword参数后面就行了,一般搜索接口地址都大同小异,你参照上面的地址找到相应的搜索词字段就行。
2.获取搜索接口的html内容
这一步建议使用Jsoup自带的api去请求,流程相当简单:
Connection connection = Jsoup.connect(Constant.SAKURA_NEXT_PAGE_BASE_URL);
connection.userAgent(Constant.USER_AGENT_FORPC);
connection.data("searchword", word);
connection.postDataCharset("GB2312");
Document document = connection.method(Connection.Method.POST).post();
//关键参数:
public static final String USER_AGENT_FORPC = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36";细节解析:
1.Jsoup.connect()--参数传入你想要解析的网站链接地址,如www.baidu.com;
2.connection.userAgent()--将UA设置为PC端UA,以获取PC端打开该网页时的HTML内容,如果不设置的话默认为手机端UA;
3.connection.posetDataCharset()--设置传递参数的编码方式,因为博主访问的网页编码方式是GB2312,因此传入了GB2312。这一步一般网站不用设置,因为大部分都是UTF-8编码,jsoup默认的参数格式也是UTF-8编码;
4.document--post请求后得到的document会把通过解析html内容得到的所有element放进去,简而言之,你想要的这个网址的一切元素都在document里存着,后续通过jsoup的解析api一一获取即可,具体有哪些解析用的api可以到jsoup的github项目地址里查看,不去看也没关系,下一步就会提到一些常用的解析api。
三.html内容解析
这一步需要你结合网址的html内容去做,因为需要使用到元素的id、class等属性值。建议你打开浏览器,进入要解析的网址,按下F12审查元素,逐个解析你想要的内容。
提供一下我解析动漫搜索结果方法,可以作为你解析html的参考:

private void parseDocuments(Document document){
waitDialog.show();
searchResultBeanList = new ArrayList<>();
lastPageCodeList.clear();
if(searchType == Constant.FLAG_SEARCH_ANIM){
Element baseElement = document.selectFirst("div.pics");
Elements urlElements = baseElement.select("a[href][title]");
Elements imgElements = baseElement.select("img[src]");
Elements liElements = baseElement.getElementsByTag("li");
try{
Element pagesElement = document.selectFirst("div.pages");
basePageUrl = Constant.SAKURA_NEXT_PAGE_BASE_URL.concat(pagesElement.selectFirst("a[href]").attr("href"));
LogUtils.i(TAG+" basePageUrl : "+basePageUrl);
if(TextUtils.isEmpty(basePageUrl) || basePageUrl.equals(Constant.SAKURA_NEXT_PAGE_BASE_URL)){
refreshLayout.setEnableLoadMore(false);
}else{
refreshLayout.setEnableLoadMore(true);
}
}catch (Exception e){
e.printStackTrace();
refreshLayout.setEnableLoadMore(false);
LogUtils.e(TAG+" 该动漫没有更多分页");
}
if(Utils.isListEmpty(liElements)){
tv_no_data.setVisibility(View.VISIBLE);
recyclerView.setVisibility(View.GONE);
waitDialog.dismiss();
LogUtils.e(TAG+" no search result find");
return;
}
List<Element> aliasList = new ArrayList<>();
List<Element> infoList = new ArrayList<>();
List<Element> descList = new ArrayList<>();
for(Element li : liElements){
Element firstSpan = li.selectFirst("span");
aliasList.add(firstSpan);
Element secondSpan = li.after(firstSpan).selectFirst("span");
infoList.add(secondSpan);
Element p = li.selectFirst("p");
descList.add(p);
}
for(int i=0;i<urlElements.size();i++){
SearchResultBean resultBean = new SearchResultBean();
Element a = urlElements.get(i);
resultBean.setUrl(Constant.SAKURA_SEARCH_URL+a.attr("href"));
resultBean.setCover(imgElements.get(i).attr("src"));
resultBean.setTitle(imgElements.get(i).attr("alt"));
resultBean.setAlias(aliasList.get(i).text());
resultBean.setInfos(infoList.get(i).text());
resultBean.setDesc(descList.get(i).text());
searchResultBeanList.add(resultBean);
String title = resultBean.getTitle();
if(!TextUtils.isEmpty(title)){
lastPageCodeList.add(title.hashCode());
}
}
}else if(searchType == Constant.FLAG_SEARCH_FILM_TELEVISION){
Element pageElement = document.selectFirst("div.page");
if(pageElement != null){
Element pageA = pageElement.selectFirst("a[target]");
if(pageA == null){
refreshLayout.setEnableLoadMore(false);
LogUtils.e(TAG+" no more pages");
}else{
basePageUrl = Constant.JIJI_BASE_URL.concat(pageA.attr("href"));
LogUtils.i(TAG+" basePageUrl = "+basePageUrl);
if(TextUtils.isEmpty(basePageUrl) || basePageUrl.equals(Constant.JIJI_BASE_URL)){
refreshLayout.setEnableLoadMore(false);
}else{
refreshLayout.setEnableLoadMore(true);
}
}
}
Element listContainerElement = document.selectFirst("ul.serach-ul");
if(listContainerElement == null || listContainerElement.childrenSize() == 0){
tv_no_data.setVisibility(View.VISIBLE);
recyclerView.setVisibility(View.GONE);
waitDialog.dismiss();
LogUtils.e(TAG+" no film datas");
return;
}
Elements sectionListElements = listContainerElement.select("li");
LogUtils.i(TAG+" sctionListElements size = "+sectionListElements.size());
for(int i=0;i<sectionListElements.size();i++){
SearchResultBean resultBean = new SearchResultBean();
Element sectionElement = sectionListElements.get(i);
//解析a标签@{
Element aTag = sectionElement.selectFirst("a.list-img");
String url = Constant.JIJI_BASE_URL.concat(aTag.attr("href"));
resultBean.setUrl(url);
String title = aTag.attr("title");
resultBean.setTitle(title);
Element imgTag = aTag.selectFirst("img.loading");
String cover = imgTag.attr("src");
resultBean.setCover(cover);
Element scoreElement = aTag.selectFirst("label.score");
String score = scoreElement.text();
resultBean.setScore(score);
Element sectionCountElement = aTag.selectFirst("label.title");
String sectionCount = sectionCountElement.text();
resultBean.setSectionCount(sectionCount);
//@}
//解析p标签列表@{
Elements pList = sectionElement.select("p");
if(pList.size() > 0){
//导演列表
Elements directorAList = pList.get(0).select("a");
if(directorAList != null && directorAList.size() > 0){
List<String> directorList = new ArrayList<>();
for(int k=0;k<directorAList.size();k++){
String director = directorAList.get(k).text();
directorList.add(director);
}
resultBean.setDirectorList(directorList);
}
//演员列表
Elements actorAList = pList.get(1).select("a");
if(actorAList != null && actorAList.size() > 0){
List<String> actorList = new ArrayList<>();
for(int j=0;j<actorAList.size();j++){
String actor = actorAList.get(j).text();
actorList.add(actor);
}
resultBean.setActorList(actorList);
}
//type
String type = pList.get(2).text().replaceAll("\"","");
resultBean.setType(type);
//area
Element areaA = pList.get(3).selectFirst("a");
if(areaA != null){
String area = areaA.text();
resultBean.setArea(area);
}
//上映时间
String publishDate = pList.get(4).text().replaceAll("\"","");
resultBean.setPublishDate(publishDate);
//更新时间
String updateDate = pList.get(5).text().replaceAll("\"","");
resultBean.setUpdateDate(updateDate);
//剧情介绍
String desc = pList.get(6).text().replaceAll("\"","");
resultBean.setDesc(desc);
}
//@}
LogUtils.d(TAG+" "+resultBean.toString());
searchResultBeanList.add(resultBean);
if(!TextUtils.isEmpty(title)){
lastPageCodeList.add(title.hashCode());
}
}
}
waitDialog.dismiss();
}上面这个方法的作用就是把解析的内容存到bean类里,然后通过List<bean>填充内容到RecyclerView的适配器里,这样就成功把网页的搜索结果展示到自己的应用中了。当然,有可能你搜索的结果会有好几页,也就是有好几个html去放置你要的搜索结果,这就需要实现分页了,博主的项目中已经实现了,整个流程说起来比较繁琐,烦请移步github项目地址查看。
细节解析:
1.document.selectFirst("div.pics")--选取第一个class为pics的div元素;
2.document.selectFirst("div#pics")--选取第一个id为pics的div元素(代码里没有用到,补充一下这个用法);
3.baseElement.select("a[href][title]")--选取所有同时包含href和title两个属性的a标签;
4.baseElement.getElementsByTag("li")--获取所有li标签;
5. .attr("href")--获取标签的href属性值;
6. .text()--获取标签内的文本内容,举个栗子:<b>content</b>,b.text()得到的就是content;
7.document.select("div.pics.large")--获取第一个class为pics large的div元素(补充介绍,获取class有多个的元素)。
知道上面介绍的几种解析方式后,做一个爬虫够用了,博主整个应用写下来也就用到了以上几种方式。是不是帮你省去了逛github的时间~。~
四、播放视频
是不是以为这一步就是把视频的地址加载进VideoView或者什么播放器控件里就能看了?NONONO,很遗憾没有你想的辣么简单(其实博主一开始也是这么想的)。实际情况就是你并没有办法获取到视频的资源链接地址,因为html里面没有,只有把视频内容封装进去的一个网址,就是咱到人家网址里看视频的那种页面,有广告、推荐内容等等。不能用视频播放器播放那咋办呢?还能咋办,只能用WebView加载视频播放地址观看了呗(当然,你如果有更好的办法欢迎在评论区分享)。
用WebView加载视频播放地址确实可以看,但是一般这种播放页面都会插很多广告进去,博主解析的网站播放页面甚至有YELLOW广告,这怎么敢拿去公开给人用呢,到时候举报我涉H我可是吃不了兜着走,必须把这些垃圾广告和与观看内容无关的东西屏蔽才行。
1.屏蔽(清除)网页中除视频播放控件以外的元素
这一步可费了我不少功夫,查了很多资料才完成,跟你们要给个免费的点赞关注不过分吧?下面言归正传。
1.创建js文件,写入对应的js脚本代码
在项目assets文件夹中创建一个文件,以js后缀结尾,写入js脚本代码。这里提供我的js代码(pureVideo.js)作为参考:
javascript:window.customScript.log('==========start===========');
var child = document.children;
var arr = [];
function fn(obj){
for(var i=0;i<obj.length;i++){
if(obj[i].children){
fn(obj[i].children);
}
arr.push(obj[i]);
}
}
fn(child);
for(var i=0;i<arr.length;i++){
var tagName = arr[i].tagName;
var id = arr[i].id;
var playerDiv = document.getElementsByClassName('player')[0];
if(tagName.indexOf('HTML') != -1 || tagName.indexOf('BODY') != -1
|| (tagName.indexOf('HEAD') != -1 && tagName.indexOf('HEADER') == -1)
|| id.indexOf('mobile-index') != -1 || arr[i].parentNode == playerDiv){
continue;
}
var className = arr[i].className;
if(className == '' || (className.indexOf('player') == -1 && className.indexOf('playbox') == -1)
|| className.indexOf('-') != -1){
arr[i].parentNode.removeChild(arr[i]);
}
}
var html = document.getElementsByTagName('html')[0];
window.customScript.log('html : '+html.innerHTML);
window.customScript.onJSLoadComplete();
//var videoParent = document.getElementById('mobile-index');
//videoParent.setAttribute('style','position:fixed;align-items: \"center\";');细节解析博主在另外一篇博文里说的很详细了,请点这里查看。
2.使用js脚本
同样,博主在另一篇博客里写的很详细了,请点这里查看。脚本执行完毕后,视频播放页面就只剩下纯粹的视频播放器了,放一下清除广告的前后对比照给你们看下:
去广告前:
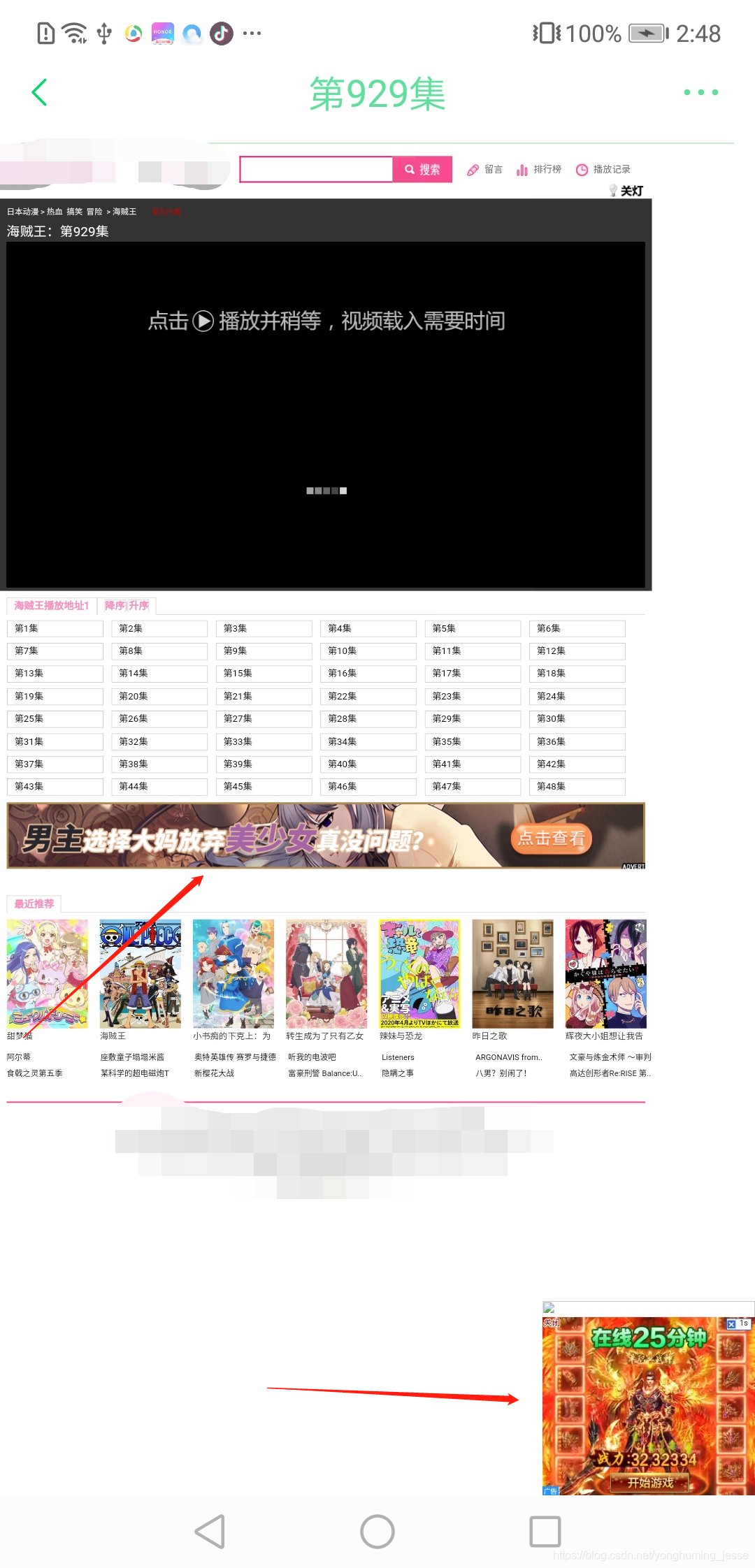
去广告后:

前后一对比你们应该就知道去广告的重要性了吧?
五、实现收藏和历史记录
不能光能看视频就完事儿了,收藏和历史记录这种基本功能还是要提供的。这里博主是把相应的数据存到本地数据库里了,用的ROOM数据库框架,之前写的文章里吐槽并介绍了ROOM数据库的用法(点这里跳转),现在想来当时我吐槽它应该是没有充分体会到它的便利之处,经过这个项目我对ROOM框架黑转粉了,强推一波!
这里简单讲一下思路,
收藏:搜索结果页面跳转到选集页面时,把点击的这个搜索结果对应的bean类传过去,然后在选集页面点击收藏时把bean存到数据库中,在收藏页面从数据库中把数据取出即可。
观看历史:在选集页面点击某一集后,把搜索结果页面传递过来的bean连同点击时间、播放的集数一起存进数据库中,在观看历史页面从数据库中把数据取出即可。
因为之后会涉及到数据刷新问题,然后又不是自己公司的后台给的接口,没法儿要求人家给我一个唯一标识字段,于是我使用动漫名的hashCode值作为一条数据的唯一标识。基本不存在同名的动漫,因此用这个来作为唯一标识是可行的。
实现流程详见github项目地址。
六、项目UI展示
在博主写这篇文章的时候,已经把影视剧资源爬取的功能也写完了,因此你会看到列表页里有一些电视剧资源。
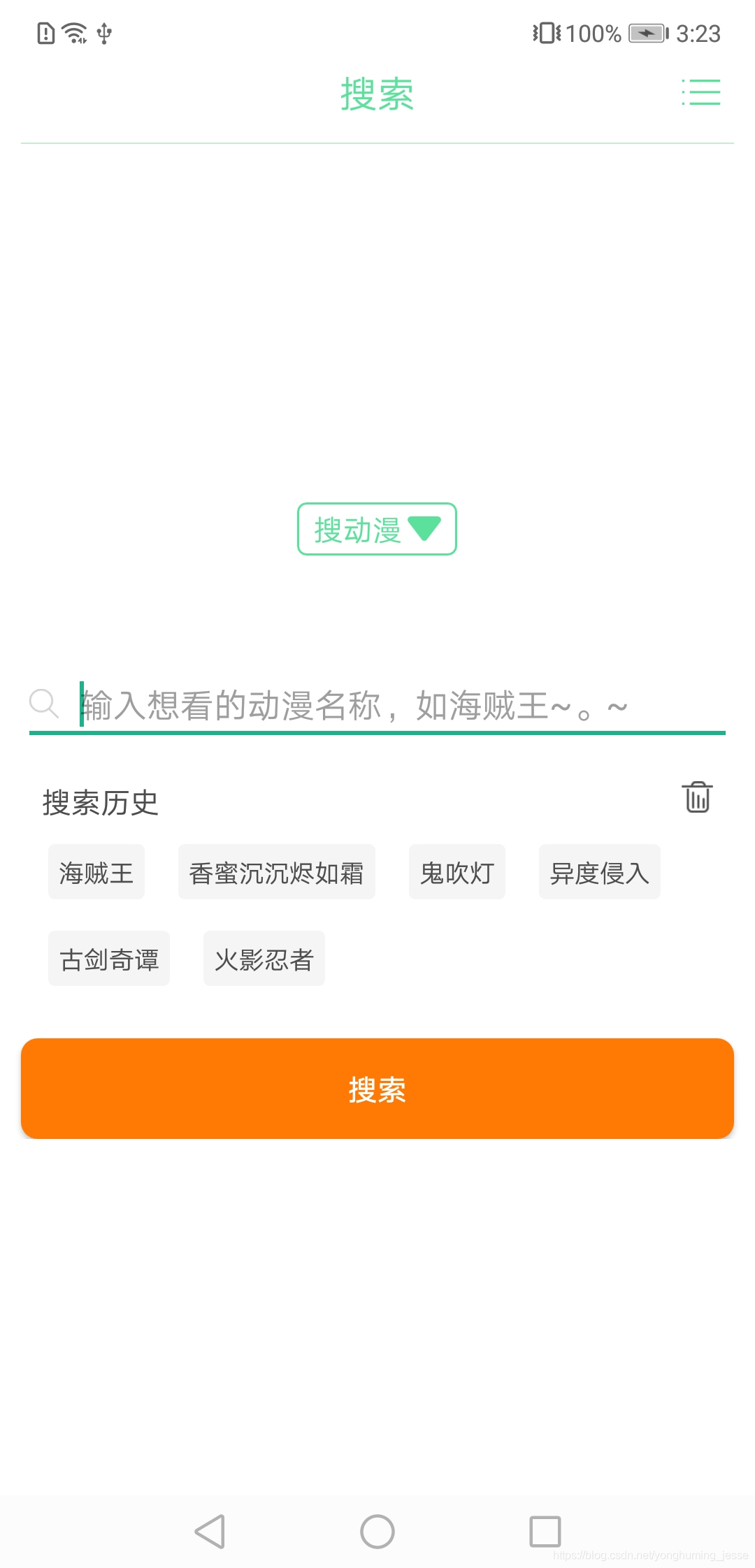
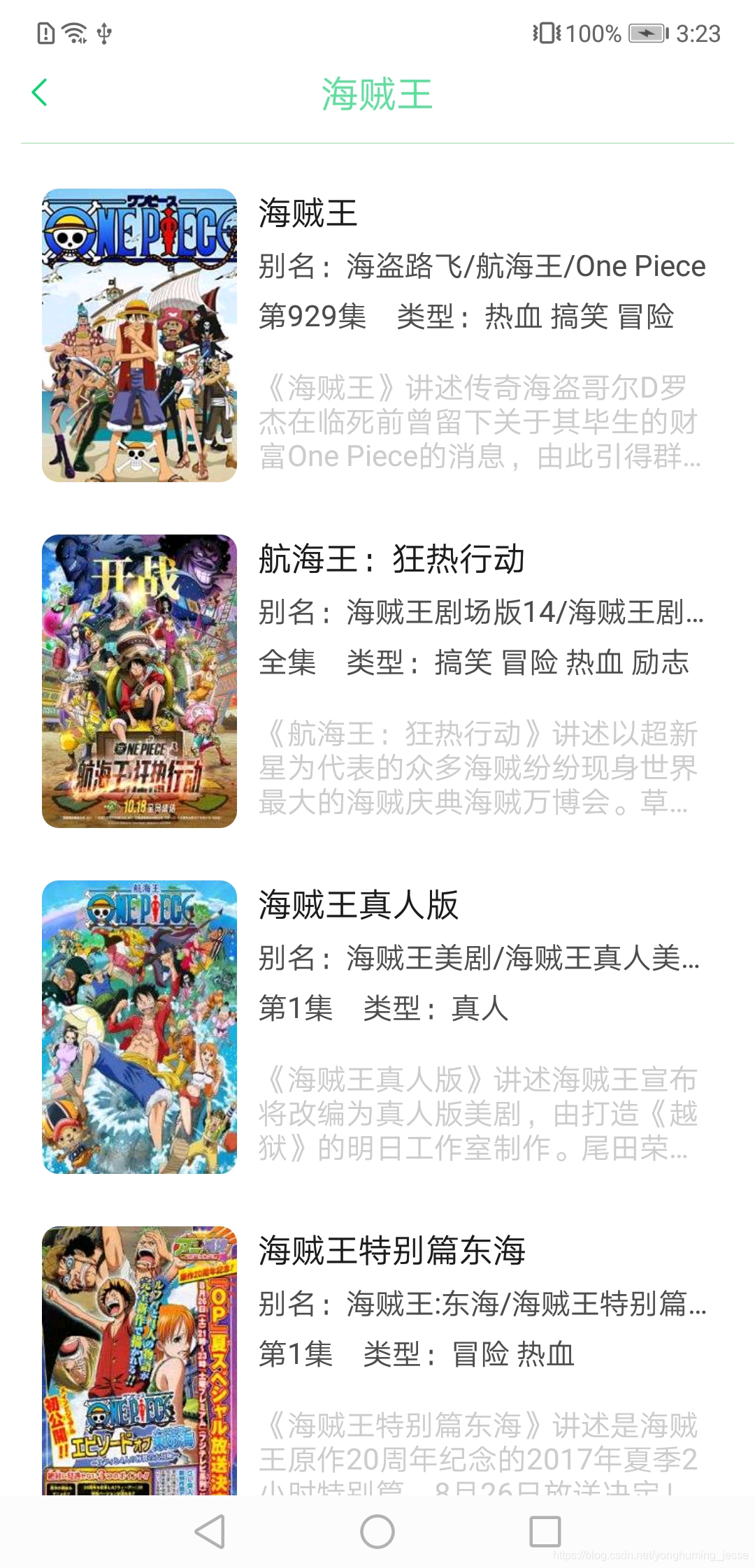

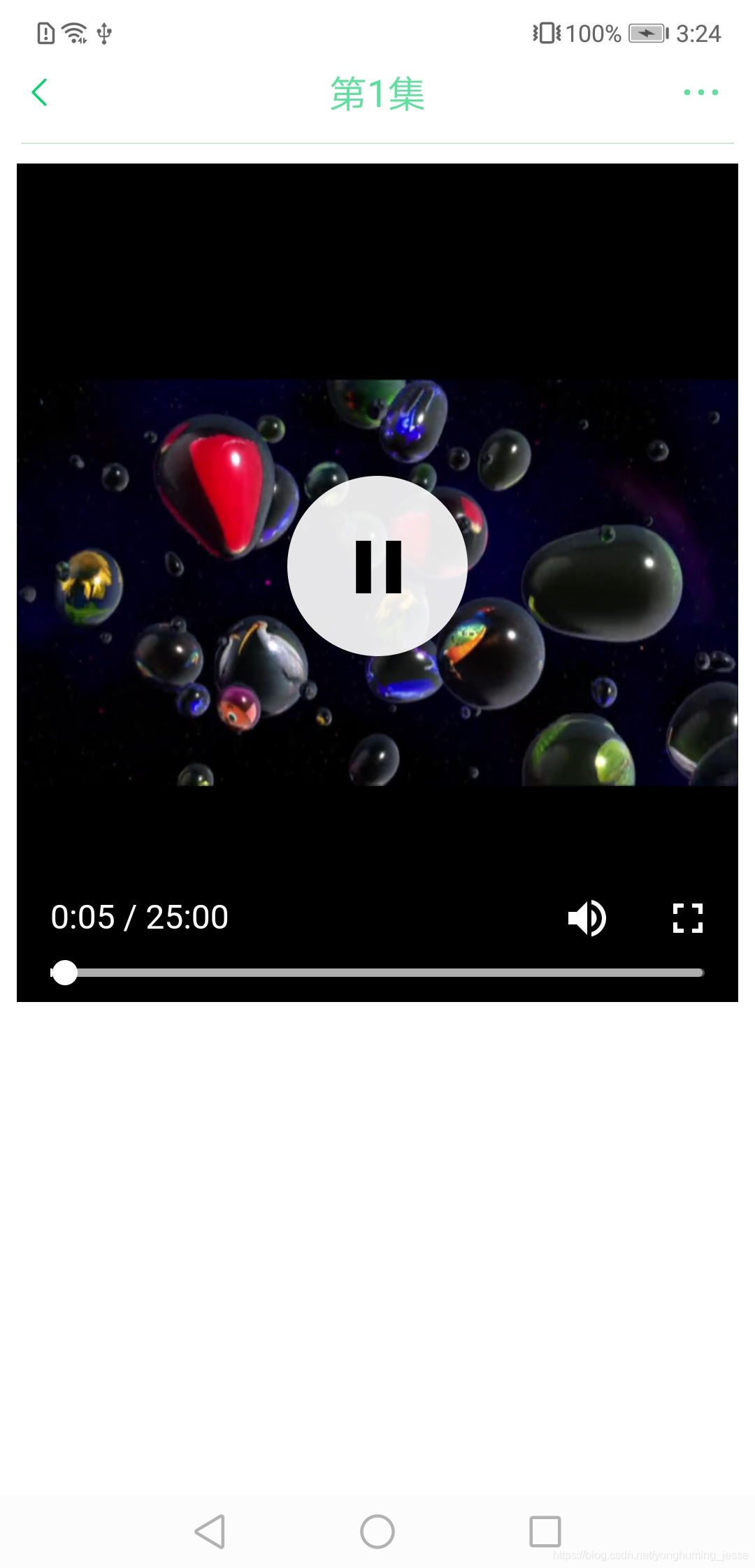

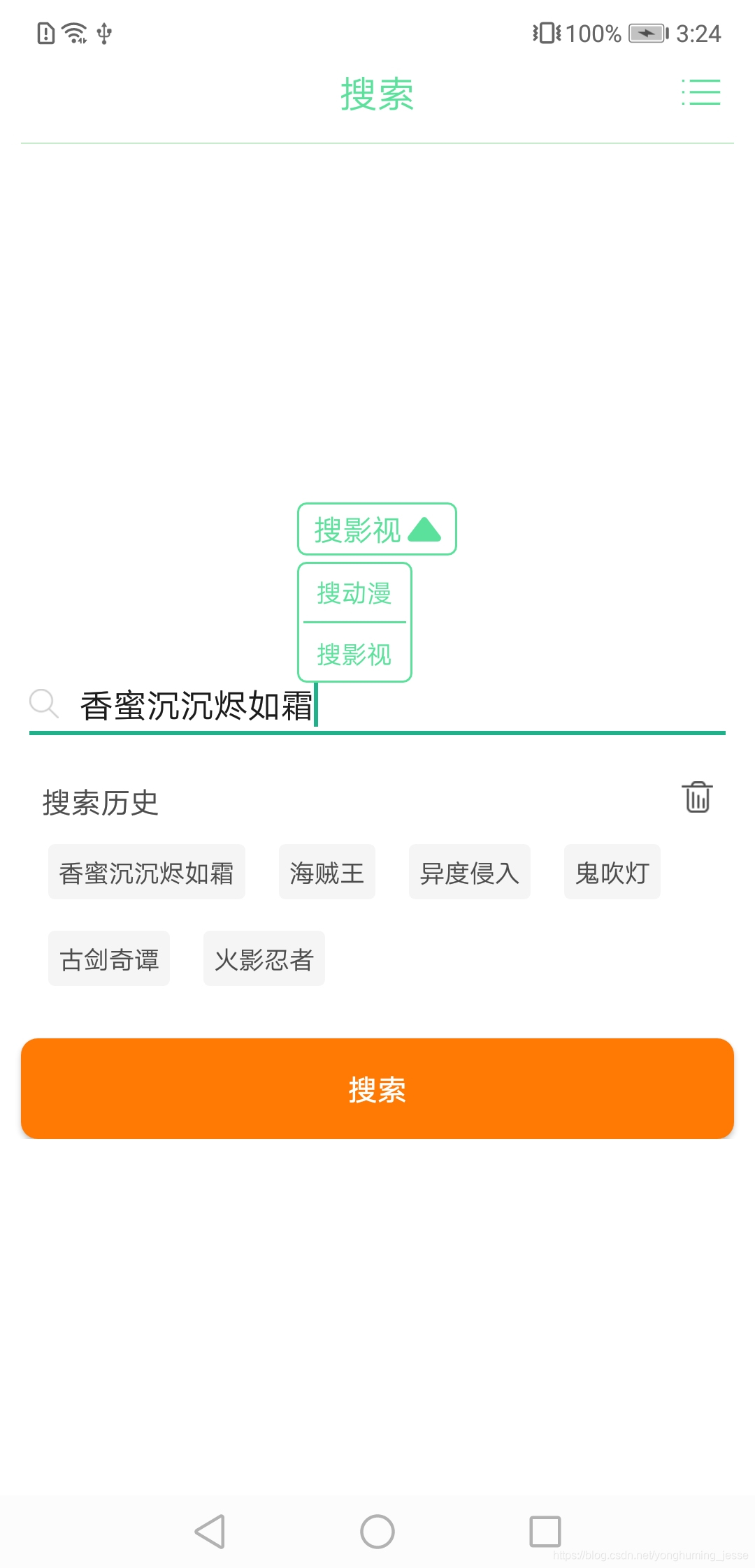


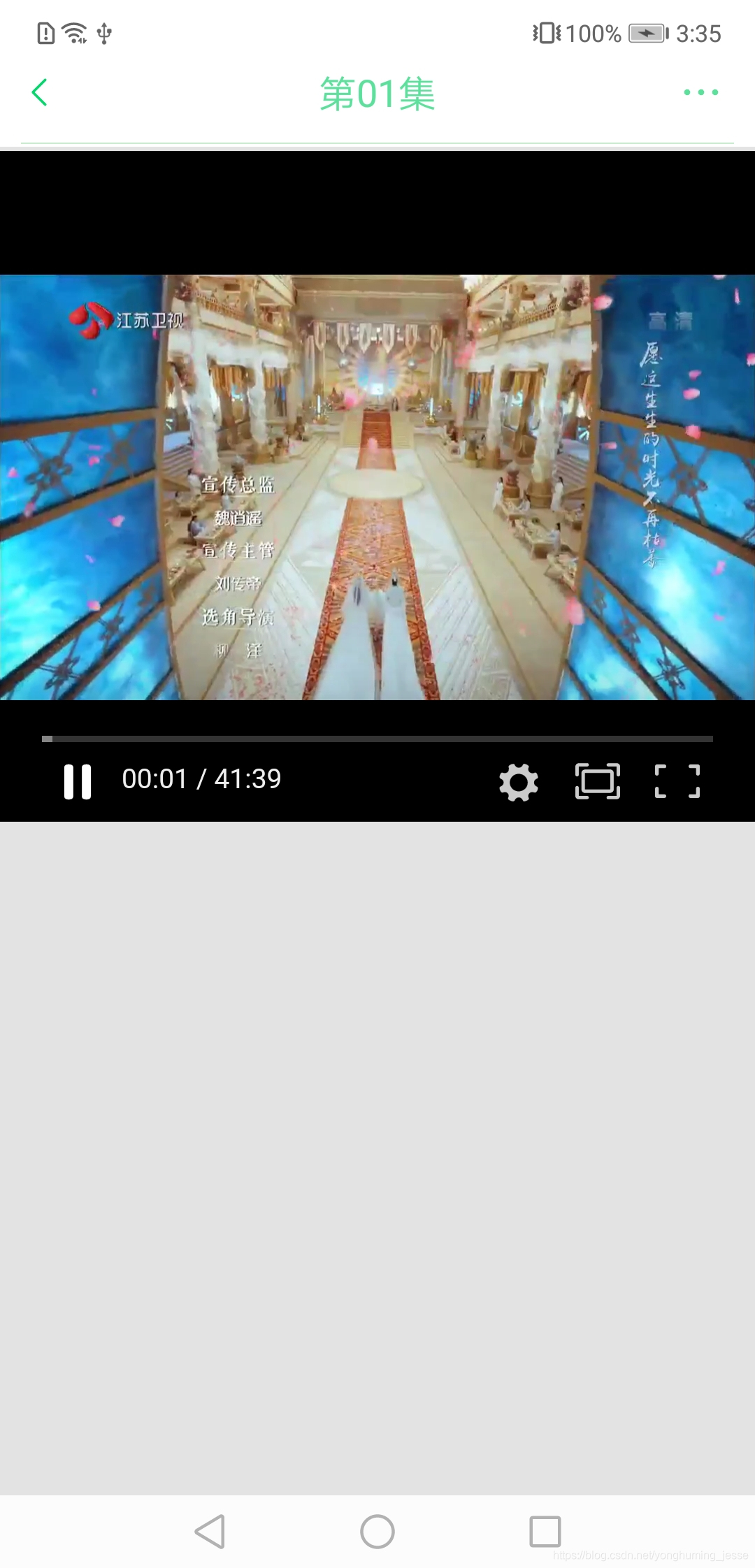

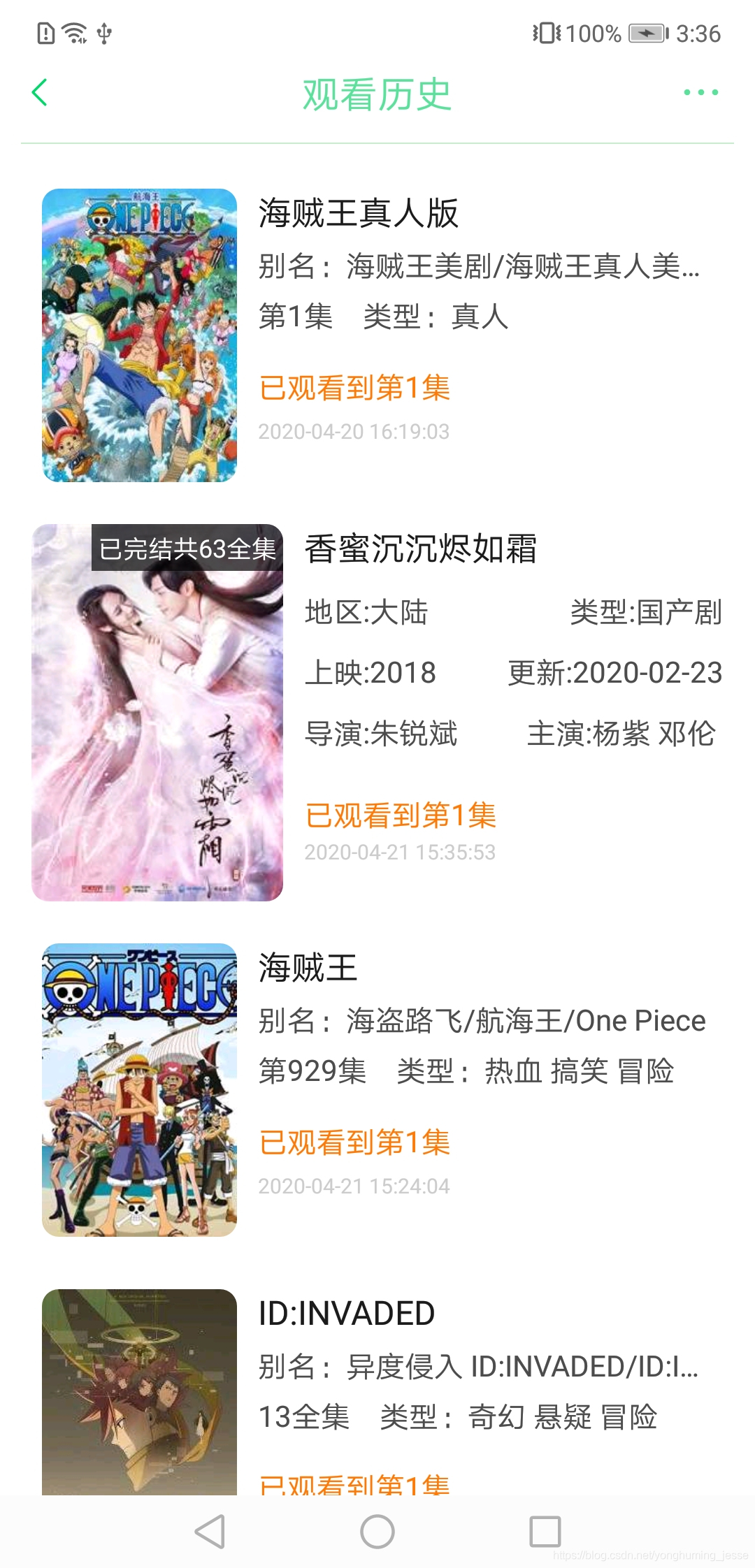
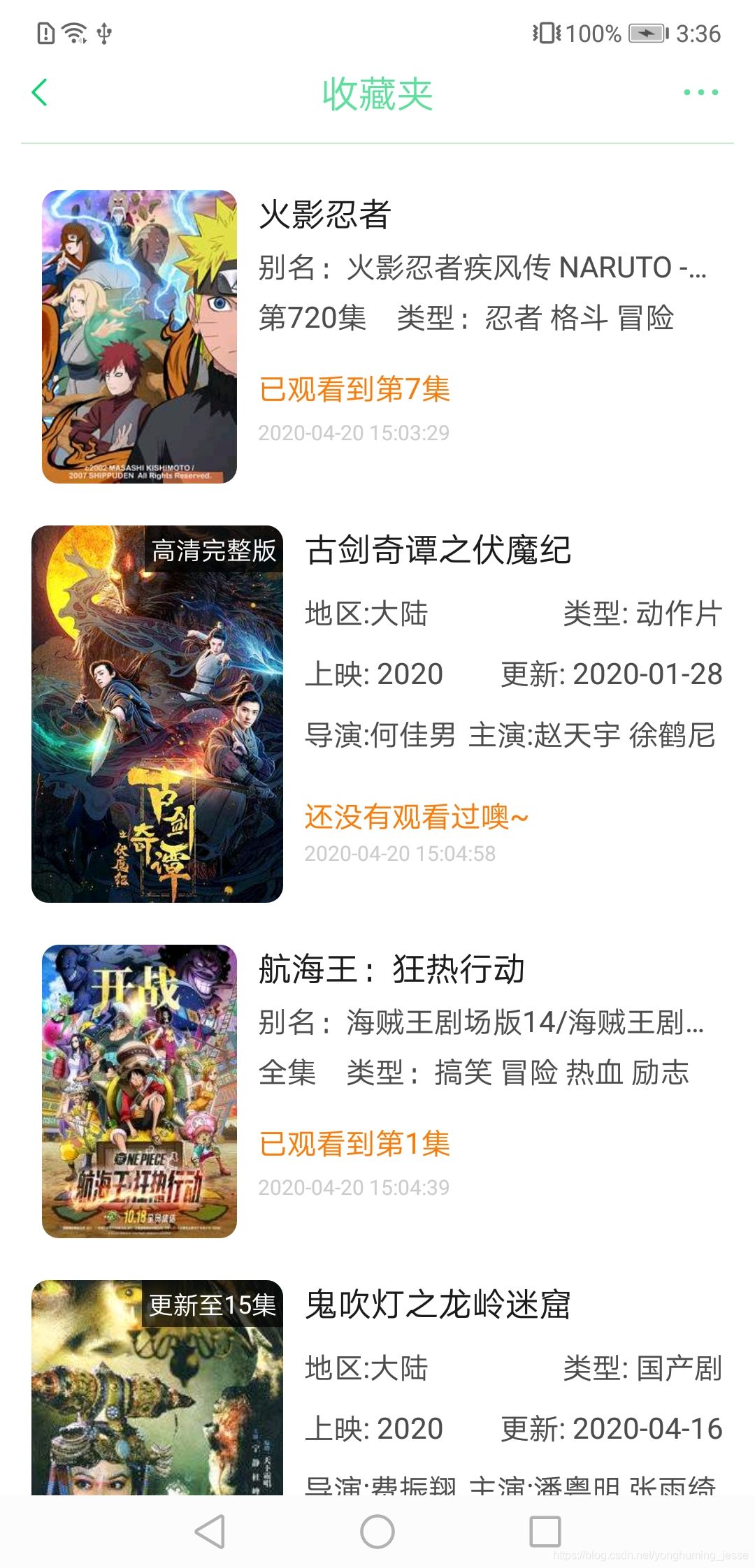
上面的图基本涵盖了所有UI了,如果有想使用的这里是APP下载地址。提醒:当前版本因为影视网站的重定向问题,影视剧只能看第一集,其他集数无法跳转成功,因此可以拿去看番剧,想看影视剧后续解决了这个问题会更新资源,届时再下载吧。
总结
爬虫用到的主要技术其实就是html解析,当你使用jsoup去写爬虫的时候,你会发现爬虫的开发过程变得异常简单,当然,依然需要你的耐心和细心去一步一步爬取你需要的数据。其次就是如果你要发出来给别人用的话,UI和用户体验方面也需要加入一点思考、费一点功夫。
附上github上的项目地址:https://github.com/hellojessehao/BiliParser
以上就是这篇文章给的全部内容了,如果帮到你了给个免费的赞和关注吧,这是博主更新下去的全部动力。
如果有问题欢迎评论区留言。
