数据库innodb的行锁模式
InnoDB实现了两种类型的行锁,
- 1共享锁(S)
允许一个事务去读取一行,阻止其他事务获取该行的排它锁 - 2排它锁(X)
允许获得排他锁的事务去修改该行的数据,并且组织其他事务获取该行的 共享锁和排他锁
对于UPDATE ,DELETE,INSERT语句,mysql会自动给涉及到的数据行添加排他锁,对于普通SELECT语句是不添加任何锁的,但是呢可以通过显示的添加共享锁或者排他锁,
- 1共享锁 select * from test where … lock in share mode
- 2排他锁 select * from test where … for update
我们先看一下对select 使用共享锁的例子
- 事务1

- 事务2
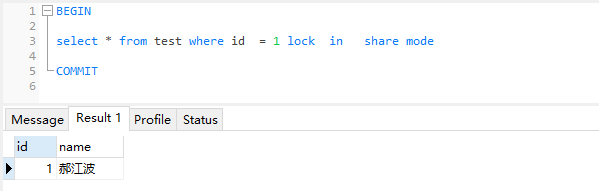
从图上可以看到,这2个sql语句 通过显示的添加共享锁,在不同的事务中,都可以查出数据
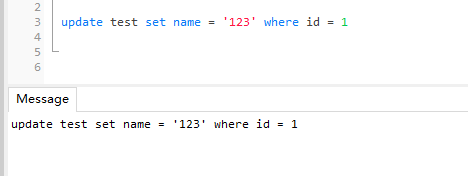
但是如果我在另一个事务中执行 update 语句,当前事务则会被阻塞,因为共享锁禁止其他事务获取该行的排他锁 - 事务1
我们再看对select显示的使用排他锁的例子
-
事务1
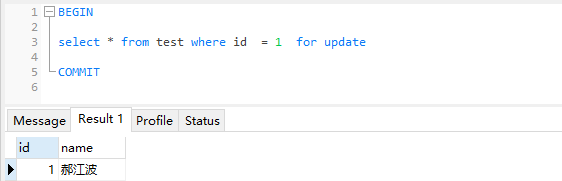
-
事务2 (由于 update 语句也是使用排他锁,这里使用 update 代替)
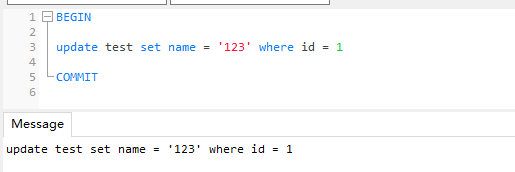 我们可以看到事务2在这里阻塞了
我们可以看到事务2在这里阻塞了 -
事务3(获取该行的共享锁)
事务3也在这里被阻塞 -
事务(注意! 此处获取的是id为2行的排他锁)
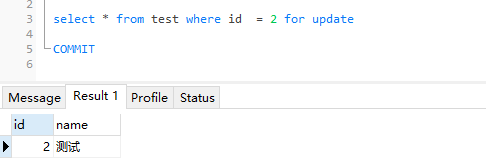
可以看到我们可以获取到id为2行的排他锁
说明一个事务获取了某一行的排他锁,其他事务无法再次获取该行的排他锁和共享锁,而获取某一行的共享锁,其他事务仍然可以获取该行的共享锁,但是其他事务无法获取该行的排他锁。
innoDB的行锁实现方式
InnoDB的行锁是对索引项加锁来实现的,如果该表并没有创建索引,那么会使用隐藏的聚簇索引来来对记录加锁(什么是聚簇索引,可以理解为索引和数据在一起存放,找到了索引就等于找到了数据,innoDB的数据是和主键在一起存放的,找到了主键就等于找到了数据)
innoDB的行锁分为3种情形
- 1 Record lock: 对索引项加锁
- Gap lock: 对索引项之间的间隙加锁,索引项的第一条数据之前的间隙和最后一条数据之后的间隙加锁,比如 where id > 1 and id < 3 会对 大于 1 的之前的间隙, 以及 小于 3的最后一条记录的之后的间隙加锁
- Next-key Lock: 前两种的组合,对记录以及前面的间隙加锁
这种机制意味着如果没有使用索引,则会对表中的所有数据加锁,如果不使用索引,就会通过隐藏的聚簇索引对记录加锁,因为没走索引,查询计划就是全表扫描,所以每一行以及每一行的间隙都会被innoDB加锁,变相的等于给整个表加锁,但是性能开销要比直接的表锁开销更大!
next-key 锁
当使用范围查询并请求获取共享或排他锁时,InnoDB会给符合条件的已有数据的索引项加锁,对于键值条件在范围内但是不存在的记录,叫做“间隙”
innoDB也会对这些间隙加锁
比如 where id > 300 这个条件,虽然大于300的这个id 并不存在,但是因为这个id 是 符合 id > 300 的这个范围的,属于间隙的范畴,所以也会被加锁,除了范围查询之外,innoDB也会对相等,但是也会使用next-key对不存在的记录加锁!
