ECC的全称是Error Checking and Correction,是一种用于Nand的差错检测和修正算法。如果操作时序和电路稳定性不存在问题的话,NAND Flash出错的时候一般不会造成整个Block或是Page不能读取或是全部出错,而是整个Page(例如512Bytes)中只有一个或几个bit出错。ECC能纠正1个比特错误和检测2个比特错误,而且计算速度很快,但对1比特以上的错误无法纠正,对2比特以上的错误不保证能检测。
校验码生成算法:ECC校验每次对256字节的数据进行操作,包含列校验和行校验。对每个待校验的Bit位求异或,若结果为0,则表明含有偶数个1;若结果为1,则表明含有奇数个1。列校验规则如表1所示。256字节数据形成256行、8列的矩阵,矩阵每个元素表示一个Bit位。
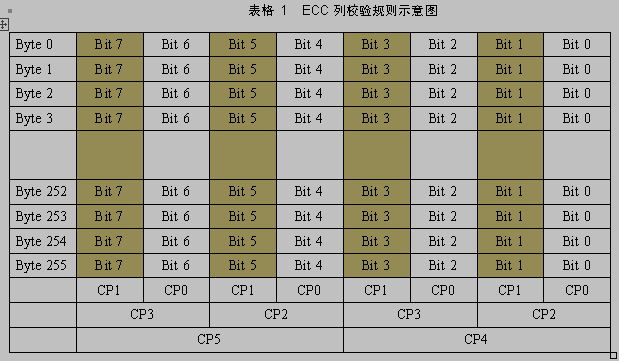
其中CP0 ~ CP5 为六个Bit位,表示Column Parity(列极性),
CP0为第0、2、4、6列的极性,CP1为第1、3、5、7列的极性,
CP2为第0、1、4、5列的极性,CP3为第2、3、6、7列的极性,
CP4为第0、1、2、3列的极性,CP5为第4、5、6、7列的极性。
用公式表示就是:CP0=Bit0^Bit2^Bit4^Bit6, 表示第0列内部256个Bit位异或之后再跟第2列256个Bit位异或,再跟第4列、第6列的每个Bit位异或,这样,CP0其实是256*4=1024个Bit位异或的结果。CP1 ~ CP5 依此类推。
行校验如下图所示
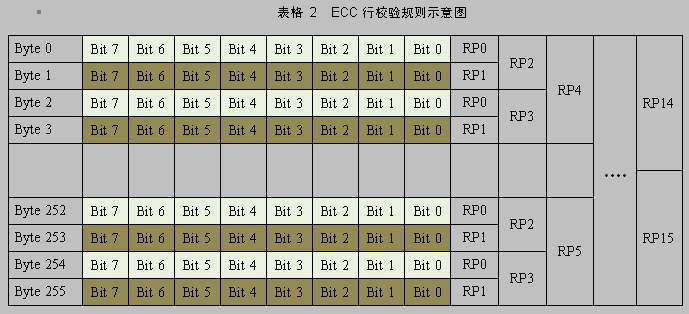
其中RP0 ~ RP15 为十六个Bit位,表示Row Parity(行极性),
RP0为第0、2、4、6、….252、254 个字节的极性
RP1-----1、3、5、7……253、255
RP2----0、1、4、5、8、9…..252、253 (处理2个Byte,跳过2个Byte)
RP3---- 2、3、6、7、10、11…..254、255 (跳过2个Byte,处理2个Byte)
RP4---- 处理4个Byte,跳过4个Byte;
RP5---- 跳过4个Byte,处理4个Byte;
RP6---- 处理8个Byte,跳过8个Byte
RP7---- 跳过8个Byte,处理8个Byte;
RP8---- 处理16个Byte,跳过16个Byte
RP9---- 跳过16个Byte,处理16个Byte;
RP10----处理32个Byte,跳过32个Byte
RP11----跳过32个Byte,处理32个Byte;
RP12----处理64个Byte,跳过64个Byte
RP13----跳过64个Byte,处理64个Byte;
RP14----处理128个Byte,跳过128个Byte
RP15----跳过128个Byte,处理128个Byte;
可见,RP0 ~ RP15 每个Bit位都是128个字节(也就是128行)即128*8=1024个Bit位求异或的结果。
综上所述,对256字节的数据共生成了6个Bit的列校验结果,16个Bit的行校验结果,共22个Bit。在Nand中使用3个字节存放校验结果,多余的两个Bit位置1。存放次序如下表所示:
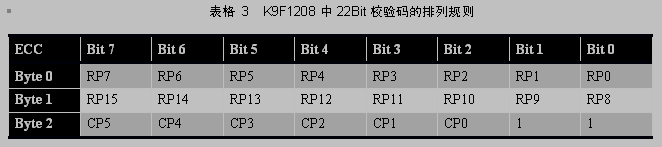
以K9F1208为例,每个Page页包含512字节的数据区和16字节的OOB区。前256字节数据生成3字节ECC校验码,后256字节数据生成3字节ECC校验码,共6字节ECC校验码存放在OOB区中,存放的位置为OOB区的第0、1、2和3、6、7字节。
校验码生成算法的C语言实现
在Linux内核中ECC校验算法所在的文件为drivers/mtd/nand/nand_ecc.c,其实现有新、旧两种,在2.6.27及更早的内核中使用的程序,从2.6.28开始已经不再使用,而换成了效率更高的程序。可以在Documentation/mtd/nand_ecc.txt 文件中找到对新程序的详细介绍。
首先分析一下2.6.27内核中的ECC实现,源代码见:
http://lxr.linux.no/linux+v2.6.27/drivers/mtd/nand/nand_ecc.c
43/*
44 * Pre-calculated 256-way 1 byte column parity
45 */
46static const u_char
nand_ecc_precalc_table[] = {
47 0x00, 0x55, 0x56, 0x03, 0x59, 0x0c, 0x0f, 0x5a, 0x5a, 0x0f, 0x0c, 0x59, 0x03, 0x56, 0x55, 0x00,
48 0x65, 0x30, 0x33, 0x66, 0x3c, 0x69, 0x6a, 0x3f, 0x3f, 0x6a, 0x69, 0x3c, 0x66, 0x33, 0x30, 0x65,
49 0x66, 0x33, 0x30, 0x65, 0x3f, 0x6a, 0x69, 0x3c, 0x3c, 0x69, 0x6a, 0x3f, 0x65, 0x30, 0x33, 0x66,
50 0x03, 0x56, 0x55, 0x00, 0x5a, 0x0f, 0x0c, 0x59, 0x59, 0x0c, 0x0f, 0x5a, 0x00, 0x55, 0x56, 0x03,
51 0x69, 0x3c, 0x3f, 0x6a, 0x30, 0x65, 0x66, 0x33, 0x33, 0x66, 0x65, 0x30, 0x6a, 0x3f, 0x3c, 0x69,
52 0x0c, 0x59, 0x5a, 0x0f, 0x55, 0x00, 0x03, 0x56, 0x56, 0x03, 0x00, 0x55, 0x0f, 0x5a, 0x59, 0x0c,
53 0x0f, 0x5a, 0x59, 0x0c, 0x56, 0x03, 0x00, 0x55, 0x55, 0x00, 0x03, 0x56, 0x0c, 0x59, 0x5a, 0x0f,
54 0x6a, 0x3f, 0x3c, 0x69, 0x33, 0x66, 0x65, 0x30, 0x30, 0x65, 0x66, 0x33, 0x69, 0x3c, 0x3f, 0x6a,
55 0x6a, 0x3f, 0x3c, 0x69, 0x33, 0x66, 0x65, 0x30, 0x30, 0x65, 0x66, 0x33, 0x69, 0x3c, 0x3f, 0x6a,
56 0x0f, 0x5a, 0x59, 0x0c, 0x56, 0x03, 0x00, 0x55, 0x55, 0x00, 0x03, 0x56, 0x0c, 0x59, 0x5a, 0x0f,
57 0x0c, 0x59, 0x5a, 0x0f, 0x55, 0x00, 0x03, 0x56, 0x56, 0x03, 0x00, 0x55, 0x0f, 0x5a, 0x59, 0x0c,
58 0x69, 0x3c, 0x3f, 0x6a, 0x30, 0x65, 0x66, 0x33, 0x33, 0x66, 0x65, 0x30, 0x6a, 0x3f, 0x3c, 0x69,
59 0x03, 0x56, 0x55, 0x00, 0x5a, 0x0f, 0x0c, 0x59, 0x59, 0x0c, 0x0f, 0x5a, 0x00, 0x55, 0x56, 0x03,
60 0x66, 0x33, 0x30, 0x65, 0x3f, 0x6a, 0x69, 0x3c, 0x3c, 0x69, 0x6a, 0x3f, 0x65, 0x30, 0x33, 0x66,
61 0x65, 0x30, 0x33, 0x66, 0x3c, 0x69, 0x6a, 0x3f, 0x3f, 0x6a, 0x69, 0x3c, 0x66, 0x33, 0x30, 0x65,
62 0x00, 0x55, 0x56, 0x03, 0x59, 0x0c, 0x0f, 0x5a, 0x5a, 0x0f, 0x0c, 0x59, 0x03, 0x56, 0x55, 0x00
63};
为了加快计算速度,程序中使用了一个预先计算好的列极性表。这个表中每一个元素都是unsigned char类型,表示8位二进制数。表中8位二进制数每位的含义:

这个表的意思是:对0~255这256个数,计算并存储每个数的列校验值和行校验值,以数作数组下标。比如 nand_ecc_precalc_table[ 13 ] 存储13的列校验值和行校验值,13的二进制表示为 00001101, 其
CP0 = Bit0^Bit2^Bit4^Bit6 = 0;
CP1 = Bit1^Bit3^Bit5^Bit7 = 1;
CP2 = Bit0^Bit1^Bit4^Bit5 = 1;
CP3 = Bit2^Bit3^Bit6^Bit7 = 0;
CP4 = Bit0^Bit1^Bit2^Bit3 = 1;
CP5 = Bit4^Bit5^Bit6^Bit7 = 0;
其行极性RP = Bit0^Bit1^Bit2^Bit3^Bit4^Bit5^Bit6^Bit7 = 1;
则nand_ecc_precalc_table[ 13 ] 处存储的值应该是 0101 0110,即0x56.
注意,数组nand_ecc_precalc_table的下标其实是我们要校验的一个字节数据。
理解了这个表的含义,也就很容易写个程序生成这个表了。程序见附件中的 MakeEccTable.c文件。
有了这个表,对单字节数据dat,可以直接查表 nand_ecc_precalc_table[ dat ] 得到 dat的行校验值和列校验值。 但是ECC实际要校验的是256字节的数据,需要进行256次查表,对得到的256个查表结果进行按位异或,最终结果的 Bit0 ~ Bit5 即是256字节数据的 CP0 ~ CP5.
/* Build up column parity */
for(i = 0; i < 256; i++) {
/* Get CP0 - CP5 from table */
idx = nand_ecc_precalc_table[*dat++];
reg1 ^= (idx & 0x3f);
//这里省略了一些,后面会介绍
}
reg1

在这里,计算列极性的过程其实是先在一个字节数据的内部计算CP0 ~ CP5, 每个字节都计算完后再与其它字节的计算结果求异或。而表1中是先对一列Bit0求异或,再去异或一列Bit2。 这两种只是计算顺序不同,结果是一致的。 因为异或运算的顺序是可交换的。
行极性的计算要复杂一些。
nand_ecc_precalc_table[] 表中的 Bit6 已经保存了每个单字节数的行极性值。对于待校验的256字节数据,分别查表,如果其行极性为1,则记录该数据所在的行索引(也就是for循环的i值),这里的行索引是很重要的,因为RP0 ~ RP15 的计算都是跟行索引紧密相关的,如RP0只计算偶数行,RP1只计算奇数行,等等。
当往NAND Flash的page中写入数据的时候,每256字节我们生成一个ECC校验和,称之为原ECC校验和,保存到PAGE的OOB(out-of-band)数据区中。
当从NAND Flash中读取数据的时候,每256字节我们生成一个ECC校验和,称之为新ECC校验和。
将从OOB区中读出的原ECC校验和新ECC校验和按位异或,若结果为0,则表示不存在错(或是出错了,ECC无法检测的错误);若3个字节异或结果中存在11个比特位为1,表示存在一个比特错误,且可纠正;若3个字节异或结果中只存在1个比特位为1,表示 OOB区出错;其他情况均表示出现了无法纠正的错误。
假设ecc_code_raw[3] 保存原始的ECC校验码,ecc_code_new[3] 保存新计算出的ECC校验码,其格式如下表所示:
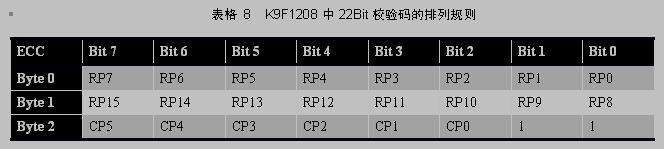
对ecc_code_raw[3] 和 ecc_code_new[3] 按位异或,得到的结果三个字节分别保存在s0,s1,s2中,如果s0s1s2中共有11个Bit位为1,则表示出现了一个比特位错误,可以修正。定位出错的比特位的方法是,先确定行地址(即哪个字节出错),再确定列地址(即该字节中的哪一个Bit位出错)。
确定行地址的方法是:
设行地址为unsigned char byteoffs,抽取s1中的Bit7,Bit5,Bit3,Bit1,作为 byteoffs的高四位, 抽取s0中的Bit7,Bit5,Bit3,Bit1 作为byteoffs的低四位, 则byteoffs的值就表示出错字节的行地址(范围为0 ~ 255)。
确定列地址的方法是:
抽取s2中的Bit7,Bit5,Bit3 作为 bitnum 的低三位,bitnum其余位置0,则bitnum的表示出错Bit位的列地址 (范围为0 ~ 7)。
参考博客的最后给举出了一个示例,可以帮助理解。