文章来因:
客官们,久等了,在家上网课,上的无聊,想看个电影放松一下,但是却不知道看啥电影,想起最近学习的爬虫,于是找电影天堂爬个电影信息,不就知道看那个电影了,上菜
实战内容:直接上代码,重要的地方有注释
各位客官,那个菜不和胃口,可以翻看前面的菜单
爬虫(1)爬虫概述,爬虫抓包工具
爬虫(2)urllib和parse库的介绍和常用函数介绍和使用
爬虫(3)request.Request类的介绍和简单爬虫实战
爬虫(4)ProxyHandler处理器(代理设置)
爬虫(5)一文搞懂cookie原理和使用(客官里面请,下饭文章吃饱再走)
爬虫(6)cookie信息保存到本地和加载
爬虫(7)一文搞懂爬虫的网络请求,requests库的使用
Xpath详解
爬虫实战(8)-爬取豆瓣网最近要上映的电影
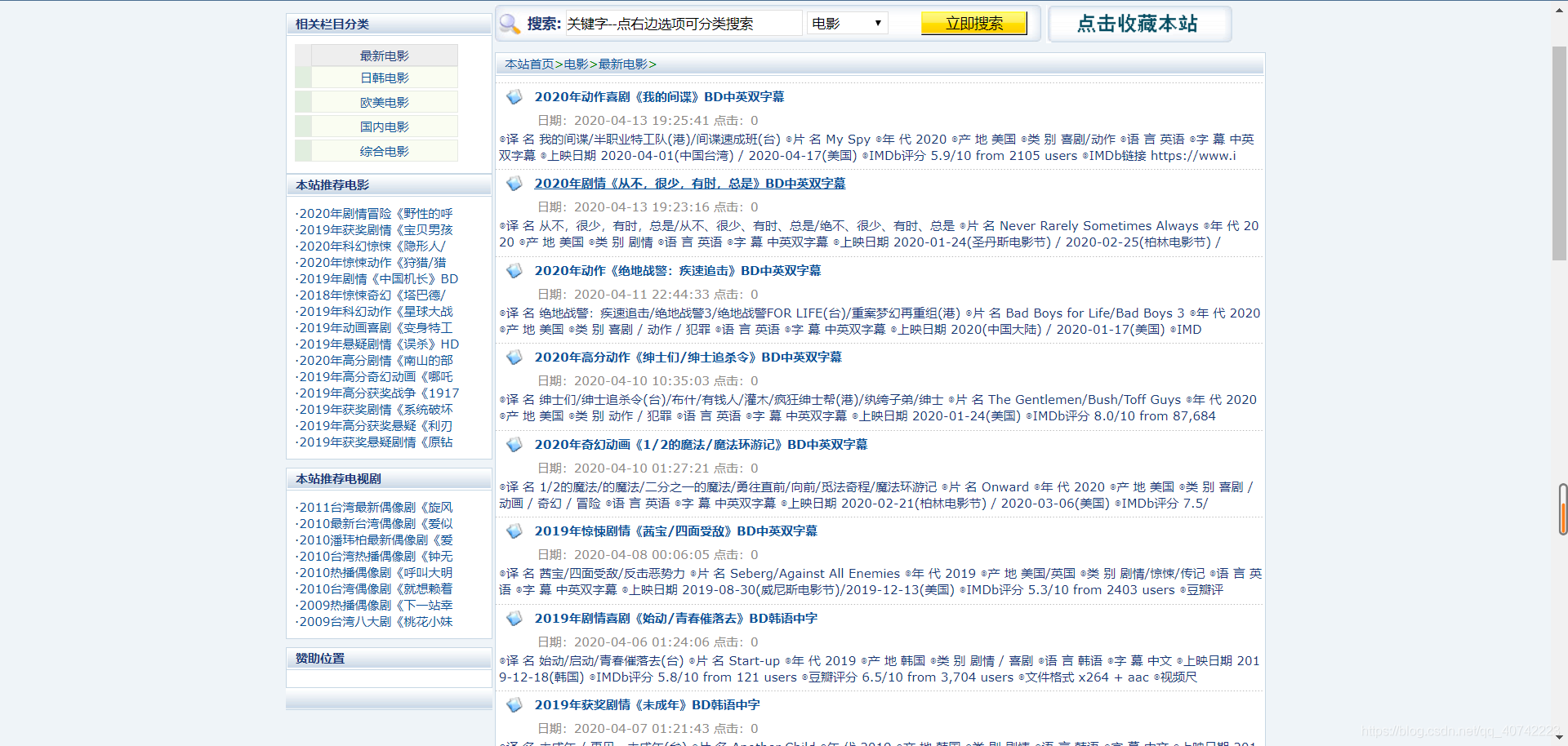
本文中的很多注释,都是在爬虫时的一些思想过程,代码不是一蹴而就,需要细细分析,“步步为营”
#encoding: utf-8
import requests
from lxml import etree
import time
import csv
from retrying import retry
BASE_DOMAIN = 'https://www.dytt8.net/'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.92 Safari/537.36',
}
@retry(stop_max_attempt_number=5)
def get_detail_urls(url):
'''获取一页的所有的电影的url'''
response = requests.get(url, headers=headers,timeout=3)
if response.status_code !=200:
raise requests.RequestException('My_request_get error!!!')
# 查看网页的编码方式,网页是什么编码方式就用什么方式解码
text = response.content.decode('gbk', 'ignore')
html = etree.HTML(text)
detail_urls = html.xpath("//table[@class= 'tbspan']//a/@href")
detail_urls = map(lambda url:BASE_DOMAIN+url,detail_urls)
return detail_urls
@retry(stop_max_attempt_number=5)
def parse_detall_page(url):
"""解析电影的详情页面的信息"""
movie ={}
response = requests.get(url,headers=headers,timeout=3)
text = response.content.decode('gbk','ignore')
html = etree.HTML(text)
title = html.xpath("//div/div/div/h1/font/text()")[0]
movie['title']=title
# for x in title:
# print(title)
zoom = html.xpath("//div[@id='Zoom']")[0]
# print(zoom)
try:
img = zoom.xpath(".//img/@src")[0]
movie['imgage']=img
except IndexError:
pass
infos = zoom.xpath(".//text()")
# print(infos)
for index,info in enumerate(infos):
##enumerate返回两个值,一个是信息,一个是下标
if info.startswith('◎年\u3000\u3000代'):
#替换年代并去除前后空格
info= info.replace("◎年\u3000\u3000代","").strip()
movie["year"]= info
elif info.startswith("◎产 地"):
info = info.replace("◎产 地","").strip()
movie["country"] = info
elif info.startswith("◎类 别"):
info = info.replace("◎类 别","").strip()
movie["type"] =info
elif info.startswith("◎语 言"):
info = info.replace("◎语 言","").strip()
movie["language"]=info
elif info.startswith("◎片 长"):
info = info.replace("◎片 长", "").strip()
movie["timelong"] = info
elif info.startswith("◎豆瓣评分"):
info = info.replace("◎豆瓣评分","").strip()
movie["pingfen"]=info
elif info.startswith("◎导 演"):
info = info.replace("◎导 演","").strip()
movie["daoyan"]=info
elif info.startswith("◎主 演"):
info = info.replace("◎主 演","").strip()
actors =[info]
for x in range(index+1,len(infos)):
actor = infos[x].strip()
if actor.startswith("◎"):
break
actors.append(actor)
# print(actors)
movie['actors']= actors
elif info.startswith("◎简 介"):
info = info.replace("◎简 介","")
for x in range(index+1,len(infos)):
profile = infos[x].strip()
if profile.startswith("【下载地址】"):
break
# print(profile)
movie["profile"] = profile
download = html.xpath("//td[@bgcolor='#fdfddf']/a/@href")[0]
movie['download_url'] = download
return movie
# yiming = html.xpath("//p/br[1]")[0]
# movie['yiming']= yiming
# pianming = html.xpath("//p/br[2]")[0]
# movie["pianming"]=pianming
# year =html.xpath("//p/br[3]")[0]
# movie["year"]=year
# address = html.xpath("//p/br[4]")[0]
# movie["address"]=address
# leibie = html.xpath("//p/br[5]")[0]
# movie["leibie"]=leibie
# uptime = html.xpath("//p/br[8]")[0]
# movie["uptime"]= uptime
# pingfen = html.xpath("//p/br[10]")[0]
# movie["pingfen"]=pingfen
# timelong= html.xpath("//p/br[12]")[0]
# movie["timelong"]= timelong
def spider():
"""页面滚动"""
base_url = 'https://www.dytt8.net/html/gndy/dyzz/list_23_{}.html'
movies = []
for x in range(1,100):
#第一个for循环,是用来控制页数
#爬取1-10页
url = base_url.format(x)
# print(url)
#需要先放到get_detail_urls中
details_urls = get_detail_urls(url)
for details_url in details_urls:
#第二个for循环时遍历一页中所有的电影详情的url
movie = parse_detall_page(details_url)#返回一个movie的字典
movies.append(movie)
print(movies)
# break
# break
header = {
'title',
'imgage',
'year',
'country',
'type',
'language',
'pingfen',
'timelong',
'daoyan',
'actors',
'profile',
'download_url'
}
with open('dainyingtiantang3.csv', 'w', encoding='utf-8', newline='')as fp:
writer = csv.DictWriter(fp, header)
# csv.writeheader()
# writer.writerow(['1','2'',3','4'])
writer.writerows(movies)
if __name__ == '__main__':
spider()
# uls = html.xpath('//div[@ class = "co_content8"]/ul')[0]
# tables = uls.xpath(".//table")
# for table in tables:
# # 测试拿到了所有的table
# # print(etree.tostring(table, encoding=('utf-8')).decode('utf-8'))
# names = table.xpath(".//tr[2]/td[2]/b/a/text()")[0]
#
# #这行代码相当于下面的python代码
# #lambda表达式表示其中的元素每一项都做同一件事
# hrefs = table.xpath(".//tr[2]/td[2]/b/a/@href")
# jianjie = table.xpath(".//tr[4]/td[1]/text()")[0]
#
# urls = map(lambda url: BASE_DOMAIN + hrefs, hrefs) # lambda表达式,相当于python中一个匿名的函数
# return names,urls,jianjie
# hrefs = table.xpath(".//tr[2]/td[2]/b/a/@href")[0]
# def abc(url):
# return BASE_DOMAIN+url
# index = 0
# for href in hrefs:
# href= abc(hrefs)
# hrefs[index]=href
# index += 1
# print(BASE_DOMAIN + hrefs)
# for herf in herfs:
# print(etree.tostring(herf,encoding=('utf-8')).decode('utf-8'))
# break
# print(etree.tostring(herfs, encoding=('utf-8')).decode('utf-8'))
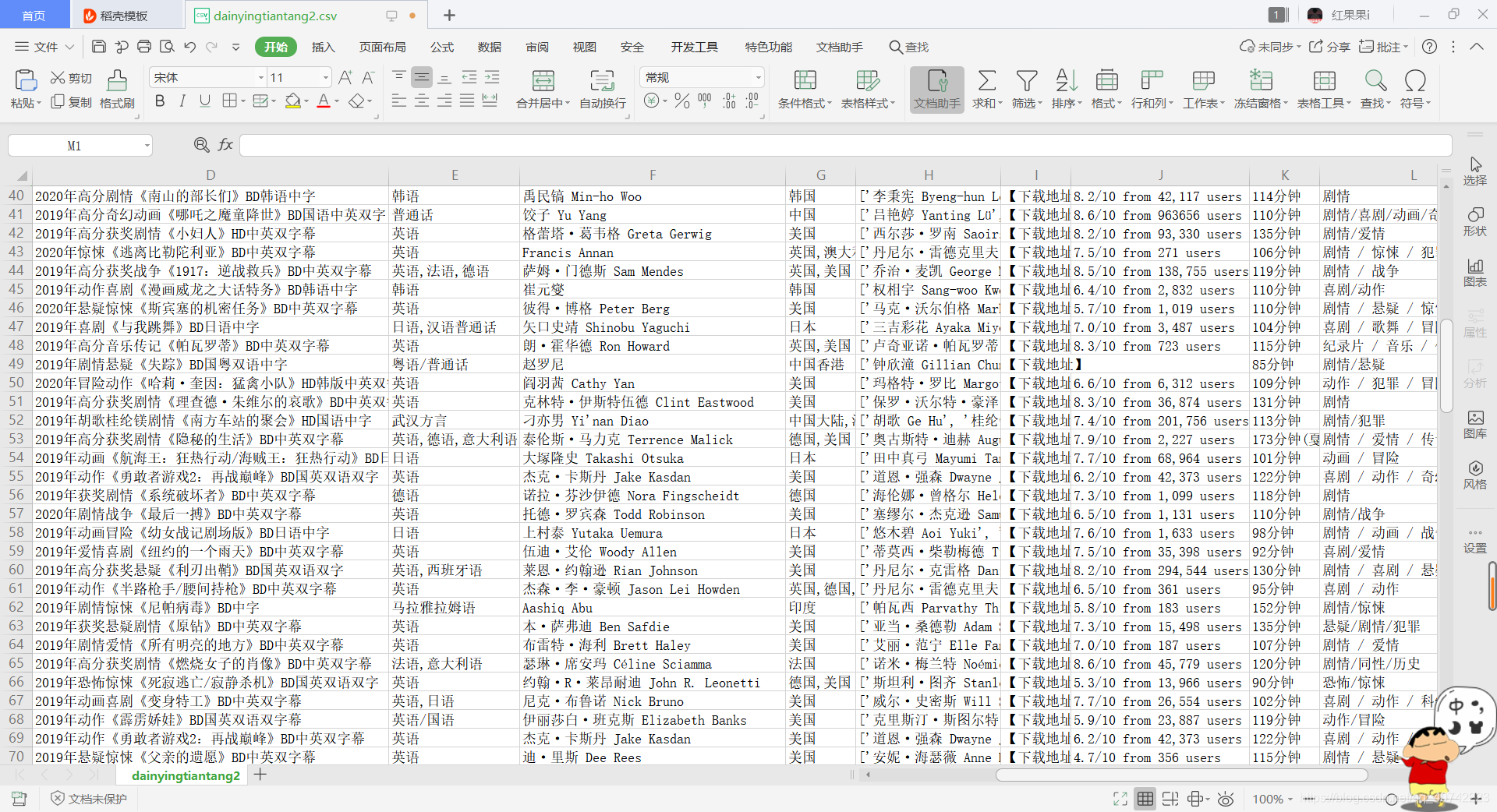
最后:我为了让客官们方便查看,我把爬取的数据存储到了Excel中,各位客官放心"食用"
写在后面的话:
最近一段时间都在学习爬虫系列,各位客官有兴趣的不妨点个赞?
最后送大家一句话共勉:一约既定,万山无阻

