1.原文链接
https://tech.meituan.com/spark-tuning-basic.html
2.介绍:
在看过美团点评的文章后,我觉得对Spark的调优写的十分棒,我决定综合自己对其的理解写一篇针对这篇文章的代码调优方面的读后感。以加深对其的理解。调优分为基础篇和高级篇,我先对比较倾向于代码的基础篇进行讲解。
3.正文
原则一:避免重复的RDD
RDD的根本就是一个数据集,我们需要从外部数据源或者容器类中获取数据,创建RDD,在编程中我们不应对相同的一份数据进行多次读取,创建多个RDD,这对集群来说是一种资源的浪费。
原则二:尽可能复用同一个RDD
在对不同的数据执行算子操作时还要尽可能地复用一个RDD,例如一个RDD中有key-value,我们需要对value进行操作,不需要新建一个RDD接手value的数据,而是可以使用_.2这个操作,来复用原始的RDD来得到想要的数据。这样做可以尽量减少RDD的数量,也减少了算子操作的数量。
原则三:对多次使用的RDD进行持久化
这个十分简单,就是对多次使用的RDD进行一个持久化的操作(persist()),这么做的好处是减少对RDD的重复计算,提高效率。Spark对于执行多算子默认原理为,每次你对一个RDD执行一个算子操作时,都会重新从源头处计算一遍,计算出那个RDD来,然后再对这个RDD执行你的算子操作。这种方式的性能是很差的。我们可以保留一个中间状态,使得RDD不必做一些重复而无用的操作。例如:
//这段代码中reduce算子操作会重新读取数据。
val rdd1 = sc.textFile("hdfs://192.168.0.1:9000/hello.txt")
rdd1.map(...)
rdd1.reduce(...)
//避免这种问题可以对rdd1进行两种方式的处理
1.使用cache()
val rdd1 = sc.textFile("hdfs://192.168.0.1:9000/hello.txt").cache()
2.使用persist()方法
val rdd1 = sc.textFile("hdfs://192.168.0.1:9000/hello.txt").persist(StorageLevel.MEMORY_AND_DISK_SER)
总结:这两种方式的关系可以在源码中发现,cache()方法就是persist(StorageLevel.MEMORY_ONLY),这样就可以了解有关持久化这两个方法的作用与关系
def persist(newLevel: StorageLevel): this.type = {
if (isLocallyCheckpointed) {
// This means the user previously called localCheckpoint(), which should have already
// marked this RDD for persisting. Here we should override the old storage level with
// one that is explicitly requested by the user (after adapting it to use disk).
persist(LocalRDDCheckpointData.transformStorageLevel(newLevel), allowOverride = true)
} else {
persist(newLevel, allowOverride = false)
}
}
/**
* Persist this RDD with the default storage level (`MEMORY_ONLY`).
*/
def persist(): this.type = persist(StorageLevel.MEMORY_ONLY)
/**
* Persist this RDD with the default storage level (`MEMORY_ONLY`).
*/
def cache(): this.type = persist()
持久化级别
| 持久化级别 | 解释 |
|---|---|
| MEMORY_ONLY | 使用未序列化的Java对象格式,将数据保存在内存中。如果内存不够存放所有的数据,则数据可能就不会进行持久化。那么下次对这个RDD执行算子操作时,那些没有被持久化的数据,需要从源头处重新计算一遍。这是默认的持久化策略,使用cache()方法时,实际就是使用的这种持久化策略。 |
| MEMORY_AND_DISK | 使用未序列化的Java对象格式,优先尝试将数据保存在内存中。如果内存不够存放所有的数据,会将数据写入磁盘文件中,下次对这个RDD执行算子时,持久化在磁盘文件中的数据会被读取出来使用。 |
| MEMORY_ONLY_SER | 基本含义同MEMORY_ONLY。唯一的区别是,会将RDD中的数据进行序列化,RDD的每个partition会被序列化成一个字节数组。这种方式更加节省内存,从而可以避免持久化的数据占用过多内存导致频繁GC。 |
| MEMORY_AND_DISK_SER | 基本含义同MEMORY_AND_DISK。唯一的区别是,会将RDD中的数据进行序列化,RDD的每个partition会被序列化成一个字节数组。这种方式更加节省内存,从而可以避免持久化的数据占用过多内存导致频繁GC。 |
| DISK_ONLY | 使用未序列化的Java对象格式,将数据全部写入磁盘文件中。 |
| MEMORY_ONLY_2, MEMORY_AND_DISK_2, 等等. | 对于上述任意一种持久化策略,如果加上后缀_2,代表的是将每个持久化的数据,都复制一份副本,并将副本保存到其他节点上。这种基于副本的持久化机制主要用于进行容错。假如某个节点挂掉,节点的内存或磁盘中的持久化数据丢失了,那么后续对RDD计算时还可以使用该数据在其他节点上的副本。如果没有副本的话,就只能将这些数据从源头处重新计算一遍了。 |
推荐阅读源码,就可以发现StorageLevel类的构造函数一共初始化了五个布尔型的参数,而这五个布尔型的参数,就是这众多持久化级别的由来
class StorageLevel private(
private var _useDisk: Boolean,
private var _useMemory: Boolean,
private var _useOffHeap: Boolean,
private var _deserialized: Boolean,
private var _replication: Int = 1)
object StorageLevel {
val NONE = new StorageLevel(false, false, false, false)
val DISK_ONLY = new StorageLevel(true, false, false, false)
val DISK_ONLY_2 = new StorageLevel(true, false, false, false, 2)
val MEMORY_ONLY = new StorageLevel(false, true, false, true)
val MEMORY_ONLY_2 = new StorageLevel(false, true, false, true, 2)
val MEMORY_ONLY_SER = new StorageLevel(false, true, false, false)
val MEMORY_ONLY_SER_2 = new StorageLevel(false, true, false, false, 2)
val MEMORY_AND_DISK = new StorageLevel(true, true, false, true)
val MEMORY_AND_DISK_2 = new StorageLevel(true, true, false, true, 2)
val MEMORY_AND_DISK_SER = new StorageLevel(true, true, false, false)
val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, false, 2)
val OFF_HEAP = new StorageLevel(true, true, true, false, 1)
原则四:尽量避免使用shuffle类算子
Shuffle操作就是将不同节点上相同的key拉到一个节点上,对这些key值相同的数据进行聚合或join操作。但是跨节点传输,必然会发生网络的I/O,如果k有一个key值相同的比较多,传输到一个节点,内存不够,就需要打到磁盘上,这就是产生磁盘的I/O和数据倾斜,所以应尽量避免Shuffle。但是在生产中,join操作往往是不可避免的,我们可以使用广播变量实现一个Spark版本的MapJoin。如下:
val rdd2Data = rdd2.collect()
val rdd2DataBroadcast = sc.broadcast(rdd2Data)
val rdd3 = rdd1.map(rdd2DataBroadcast...)
总结:
这种方式也是有一定问题的,我们应该选择小的RDD作为广播变量。因为广播变量是需要将变量广播到每一个executer中,如果RDD过大势必会占用很多资源。原则五:使用map-side预聚合的shuffle操作
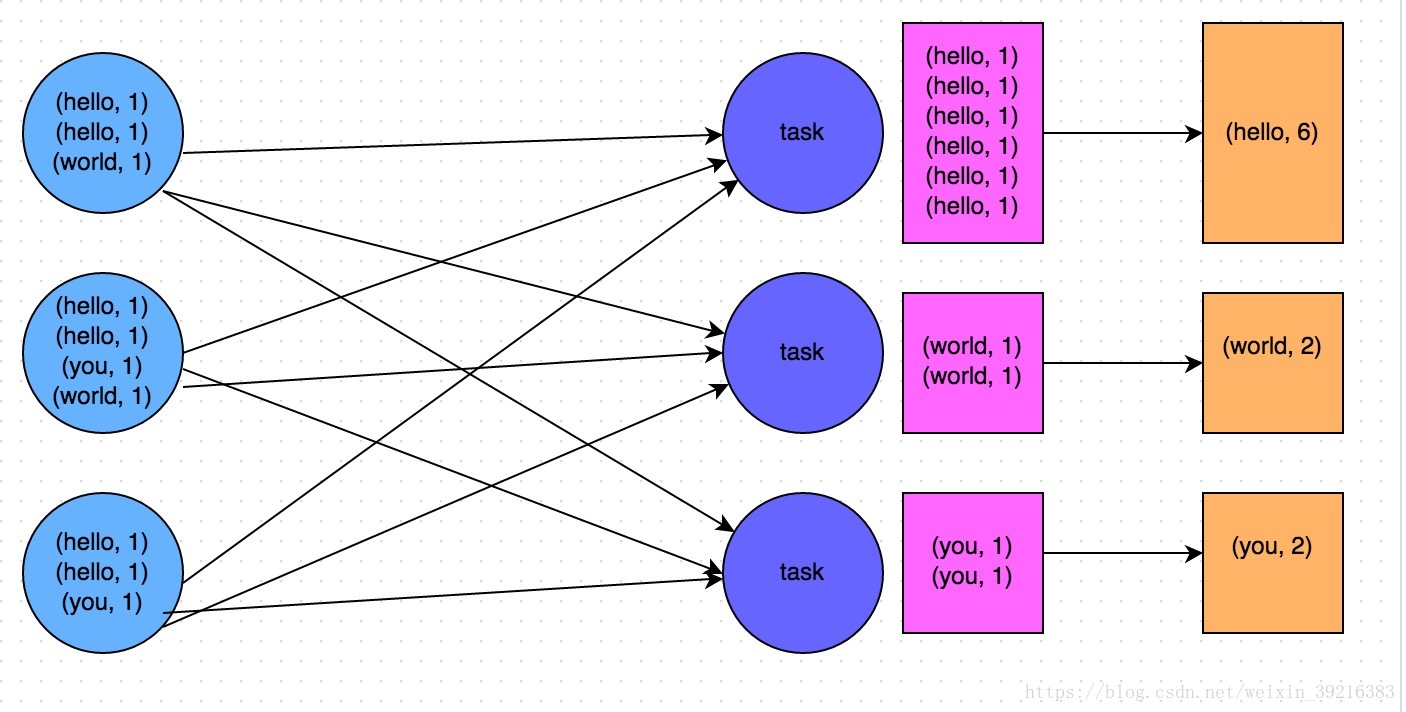
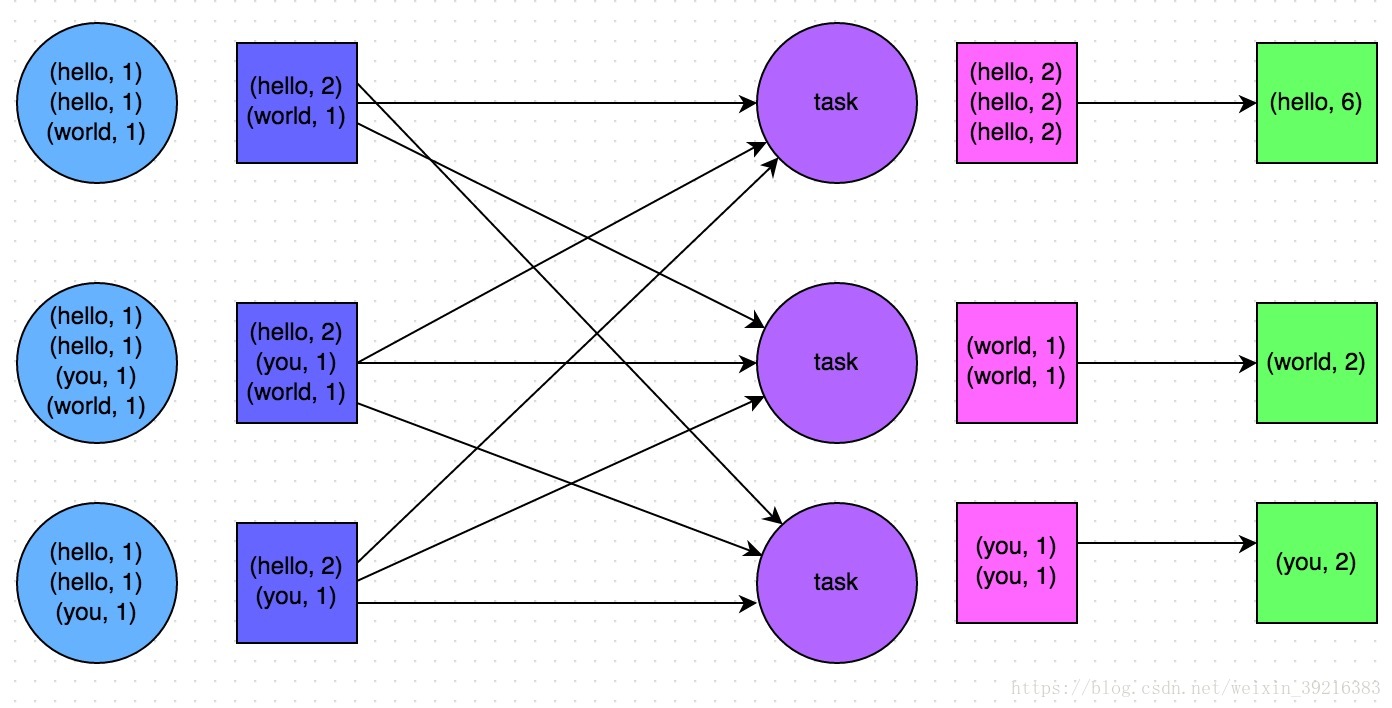
这个问题主要是reducebykey和groupbykey的区别,reducebykey在map端进行了一次类似于MR的combiner的操作,这样可以大大减少网络I/O时传输的数据量。而groupbykey则是将key-value原封不动的传输到reduce端。
GroupByKey
ReduceByKey
原则六:使用高性能的算子
- 使用ReduceByKey代替GroupByKey
- 使用mapPartitions替代普通map
mapPartitions会一次性处理一个分区的数据,相对于map一行一行的处理效率提高了很多。但是分区可能过大,出现OOM,注意调大Driver端内存。
源码如下,从入参就可以看出区别:
def map[U: ClassTag](f: T => U): RDD[U] = withScope {
val cleanF = sc.clean(f)
new MapPartitionsRDD[U, T](this, (context, pid, iter) => iter.map(cleanF))
}
def mapPartitions[U: ClassTag](
f: Iterator[T] => Iterator[U],
preservesPartitioning: Boolean = false): RDD[U] = withScope {
val cleanedF = sc.clean(f)
new MapPartitionsRDD(
this,
(context: TaskContext, index: Int, iter: Iterator[T]) => cleanedF(iter),
preservesPartitioning)
}foreachPartitions替换foreach
一般作为写入数据库的最佳方式使用filter之后进行coalesce操作
提到coalesce算子就不得不说说repartition算子,这两个算子的关系我们也可以通过源码来看出来
def repartition(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope {
coalesce(numPartitions, shuffle = true)
}从代码中可以看出来repartition调用了coalesce,并且是需要shuffle。之所以需要在过滤之后重新分区,是一种针对小文件问题的解决方案。举个例子,一共十个分区每个分区存了100条数据,我提一种极端的情况,经过了多重过滤,每个分区只剩下了10条数据,那么这是不是对分区资源的一种浪费。所以需要重新分区。
原则七:广播大变量
广播大变量的重点在于一个“大”字,首先我们要了解一下spark的部分执行流程,rdd使用外部变量,是将这个外部变量的副本通过网络传输的方式存入到每一个运行这个应用程序的task上去。如果这个变量足够大,那么在网络I/O上消耗的时间是十分可观的,而且还需要占用十分多的存储空间。针对这种“大”的外部变量(100M,甚至1G),我们可以将变量广播,使这个变量的副本只存在于每个Executer中,这样就大大减少了变量的副本数,大大的提升了效率。执行代码如下:
val list1 = ...
val list1Broadcast = sc.broadcast(list1)
rdd1.map(list1Broadcast...)
原则八 :使用Kryo优化序列化性能
针对Kryo,我单独写一篇博客如下:
Kryo序列化
原则九:优化数据结构
Java中,有三种类型比较耗费内存:
- 对象,每个Java对象都有对象头、引用等额外的信息,因此比较占用内存空间。
- 字符串,每个字符串内部都有一个字符数组以及长度等额外信息。
- 集合类型,比如HashMap、LinkedList等,因为集合类型内部通常会使用一些内部类来封装集合元素,比如Map.Entry。
因此Spark官方建议,在Spark编码实现中,特别是对于算子函数中的代码,尽量不要使用上述三种数据结构,尽量使用字符串替代对象,使用原始类型(比如Int、Long)替代字符串,使用数组替代集合类型,这样尽可能地减少内存占用,从而降低GC频率,提升性能。
但是在笔者的编码实践中发现,要做到该原则其实并不容易。因为我们同时要考虑到代码的可维护性,如果一个代码中,完全没有任何对象抽象,全部是字符串拼接的方式,那么对于后续的代码维护和修改,无疑是一场巨大的灾难。同理,如果所有操作都基于数组实现,而不使用HashMap、LinkedList等集合类型,那么对于我们的编码难度以及代码可维护性,也是一个极大的挑战。因此笔者建议,在可能以及合适的情况下,使用占用内存较少的数据结构,但是前提是要保证代码的可维护性。