我们之前做的搜索使用的是Solr的单机版来实现的,正是由于我们现在商品数据量不多,才几千条而已。如果商品数据量变得非常庞大,比如说淘宝,淘宝上面的商品数量特别多,我们用一个单机版的Solr能实现吗?这里面就可能有问题了,一个是数据量特别庞大,每一个服务器存储容量是有上限的,一旦磁盘存不下了怎么办呢?这是不是有问题啊?还有就是由于淘宝的用户访问量很多,搜索的人也有很多,并发量很高,这种情况使用一个Solr服务,极有可能撑不住,这种时候怎么办呢?这种时候我们就需要使用Solr集群了。
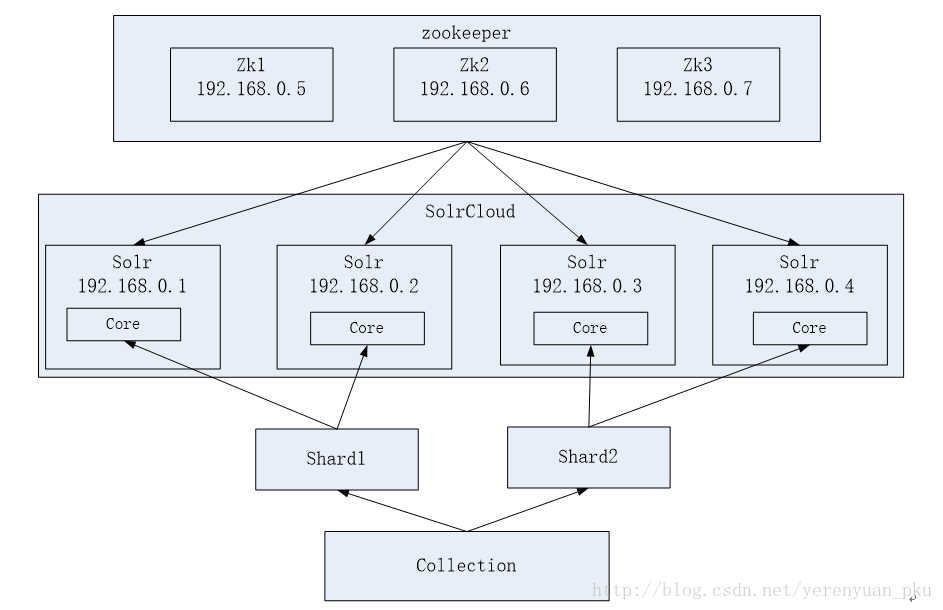
下面我们来搭建Solr集群,先来看下我们要搭建的集群架构图,如下图所示。
zookeeper作为集群的管理工具,有以下几个作用:
- 集群管理:容错、负载均衡。
- 配置文件的集中管理。
- 集群的入口。
因为我们需要实现zookeeper的高可用,所以需要搭建zookeeper集群。zookeeper集群节点数量建议是奇数,因此至少需要三个zookeeper服务器。从上图可以看到Solr集群由三台注册中心(zookeeper集群)和四台部署有Solr的设备组成,这样看来搭建Solr集群需要7台服务器,我们要模拟一个7台服务器的话,需要7台虚拟机,7台虚拟机跑起来也很有一定难度,由于我们只是练习Solr集群搭建,使用一台虚拟机就可以了,一台虚拟机上面需要搭建3个zookeeper实例,4个Solr实例,每一个Solr实例就是一个tomcat,所以我们需要4个tomcat,3个zookeeper就行了。这里建议虚拟机的内存得给大一点,至少得给1个G。
下面我们一步一步来搭建Solr集群。在搭建Solr集群之前,我们还得搭建zookeeper集群。
zookeeper集群搭建
新建一台虚拟机
我们在安装单机版的Solr的时候就已经新建了一台虚拟机,因此这儿不必再新建一台虚拟机了,就使用原有的虚拟机就可以了。
安装JDK环境
我们在安装单机版的Solr时就已经安装过JDK了,这儿我不想再多费口舌。而且关于如何在Linux系统上安装JDK,我的Linux系统上安装JDK这篇文章已经说的很清楚了。
搭建zookeeper集群
首先,将zookeeper的压缩包上传到服务器上,我下载的zookeeper的压缩包如下图所示。
关于怎样将文件上传到Linux系统上,我想我已经说的要吐了,所以这儿不再浪费口舌。与以往一样,我把zookeeper-3.4.6.tar.gz上传到了用户主目录(即root)下,如下图所示。
接着,我们使用tar zxf zookeeper-3.4.6.tar.gz命令将zookeeper的压缩包解压缩到用户主目录(即root)下,解压完之后,可以看到解压后的zookeeper-3.4.6目录。
紧接着先在/usr/local目录下面创建一个solr-cloud目录,然后我们把zookeeper-3.4.6往/usr/local/solr-cloud目录下面复制三份。
进入/usr/local/solr-cloud目录中,可以看到有三个zookeeper实例。
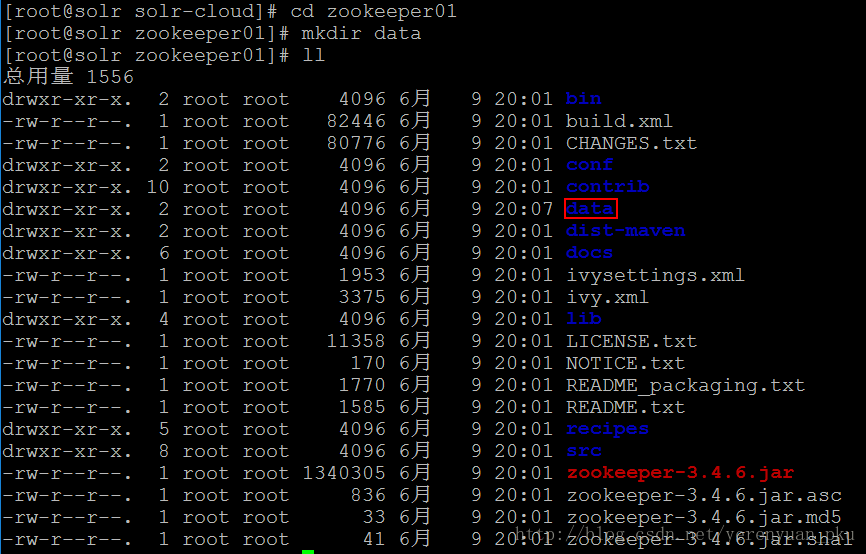
下面我们进入到zookeeper01目录中,使用mkdir data命令在该目录中创建一个data目录,创建成功之后使用ll命令查看一下zookeeper01目录,效果如下:
然后使用echo 1 >> myid命令在data目录下创建一个myid文件,文件名就叫做“myid”,其内容就是每个实例的id,例如1、2、3。创建完myid文件之后,即可使用cat myid命令查看文件的内容。
接着我们就要修改配置文件了。进入到zookeeper01/conf目录下,可以看到该目录下有个zoo_sample.cfg文件。
紧接着我们需要使用mv zoo_sample.cfg zoo.cfg命令将zoo_sample.cfg文件改下名字,改为zoo.cfg,修改成功之后使用ll命令查看一下conf目录,效果如下:
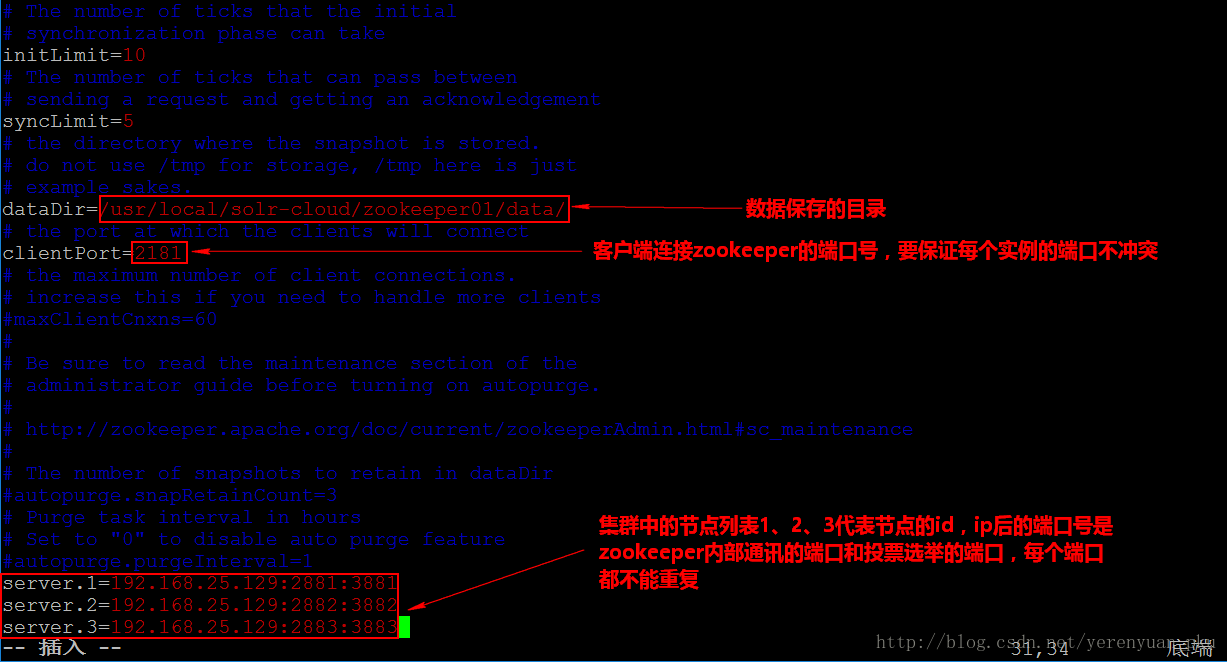
接下来我们就要修改zoo.cfg文件了,我们使用的命令是vim zoo.cfg,在打开的文件中修改”dataDir”的路径为我们上面创建的data的绝对路径,即/usr/local/solr-cloud/zookeeper01/data/,除此之外还要修改一下clientPort所指定的端口号,clientPort是客户端要连接zookeeper的端口号,现在我们要启动三个zookeeper实例,这个端口号不能冲突,所以需要改一下端口号。最后还得在文件的最后添加上三行配置,如下图所示。
修改完zoo.cfg之后,按esc退出编辑模式,然后再输入:wq命令来保存并退出zoo.cfg,这样我们便配置好了。
我们配置好zookeeper01这个实例之后,可以仿照zookeeper01实例的配置来配置好zookeeper02和zookeeper03这两个实例,这样三个zookeeper实例就配置好了。
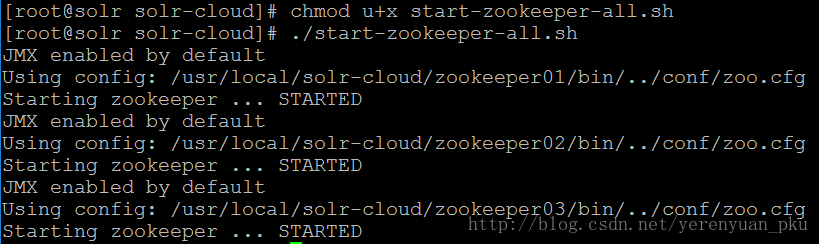
下面我们需要启动每个zookeeper实例。如果想启动每个zookeeper实例的话,不必每个实例一个个启动,这样太麻烦了,我们可以写个批处理程序来把它们一下子启动起来。在solr-cloud目录下使用vim start-zookeeper-all.sh命令来创建一个批处理文件,文件内容为:




cd /usr/local/solr-cloud/zookeeper01/bin
./zkServer.sh start
cd /usr/local/solr-cloud/zookeeper02/bin
./zkServer.sh start
cd /usr/local/solr-cloud/zookeeper03/bin
./zkServer.sh start保存完该文件之后,使用ll命令查看一下solr-cloud目录,可以发现start-zookeeper-all.sh文件,如下图所示。
但是这个批处理程序是不能运行的,所以你需要使用chmod u+x start-zookeeper-all.sh命令改一下它的权限,这样我们就可以使用./start-zookeeper-all.sh命令来启动每个zookeeper实例了。
启动完每个zookeeper实例之后,我们先查看一下zookeeper01的状态,发现该节点的zookeeper的角色是follower,如下图所示。
接着看下zookeeper02的状态,发现该节点的zookeeper角色是follower,如下图所示。
最后看下zookeeper03的状态,发现该节点的zookeeper的角色是leader(领导者),这说明我们的zookeeper集群搭建成功了!




Solr集群搭建
我们说过Solr要运行在tomcat中,所以这4个Solr节点也就是4个tomcat,要保证4个tomcat都能启动,它们的启动端口就不能冲突,所以我们需要将这4个tomcat的端口号给改一下。由于我们之前已经搭了一个Solr单机版,Solr本身就是一个web工程,我们就可以直接把单机版配好的那个Solr直接复制到我们这个集群里面,这样就可以用了。还有一个Solr单机版的那个solrhome我们也可以直接用,所以我们就不再直接配置了。
下面我讲一下我本人是如何搭建Solr集群的。
首先,将用户主目录(即root)下的apache-tomcat-7.0.47复制4份到/usr/local/solr-cloud/目录下,这样就能创建4个tomcat实例了,如下图所示。
然后将这4个tomcat的端口号给改一下,使每个tomcat运行在不同的端口。我们先到tomcat01的conf目录下(/usr/local/solr-cloud/tomcat01/conf)修改server.xml文件,依次修改下面这三段配置的port的值,如下所示。
- 将port的值由8005改为8105
- 将port的值由8080改为8180
- 将port的值由8009改为8109


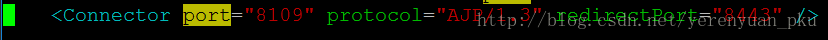
按照上面步骤依次修改tomcat02、tomcat03和tomcat04这3个tomcat的端口号。改完之后,在solr-cloud目录下使用ll命令查看一下该目录,可以看到4个tomcat实例,如下图所示。
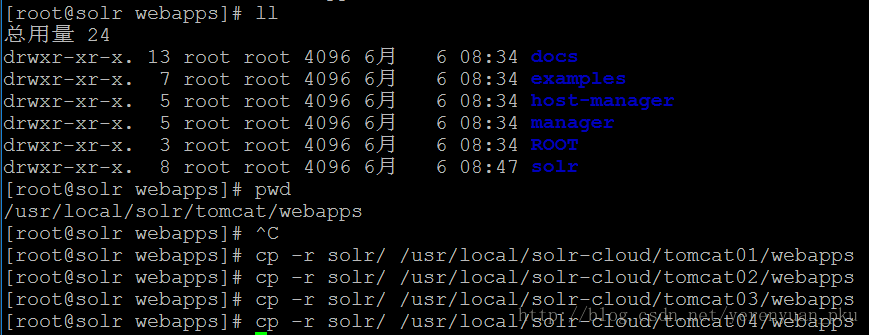
接下来就要部署Solr的war包了,之前我们弄了一个Solr单机版,现在只须把单机版的Solr工程复制到集群中的tomcat中即可。具体做法是将/usr/local/solr/tomcat/webapps目录下的Solr工程分别复制4份到我们刚才那4个tomcat下面,如下图所示。
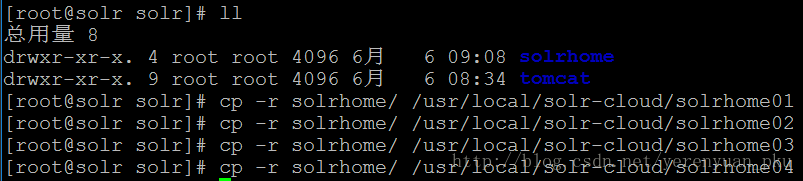
接着为每个Solr实例创建一个对应的solrhome,使用单机版的solrhome即可。具体做法是将/usr/local/solr目录下的solrhome分别复制4份到/usr/local/solr-cloud目录下,如下图所示。
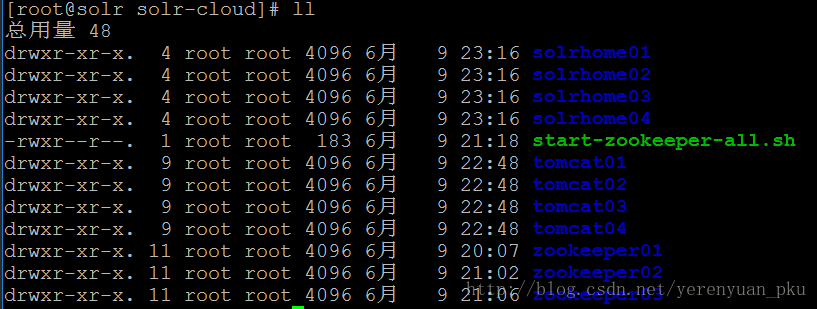
我们可在solr-cloud目录下使用ll命令查看一下该目录,可以看到4个solrhome,如下图所示。
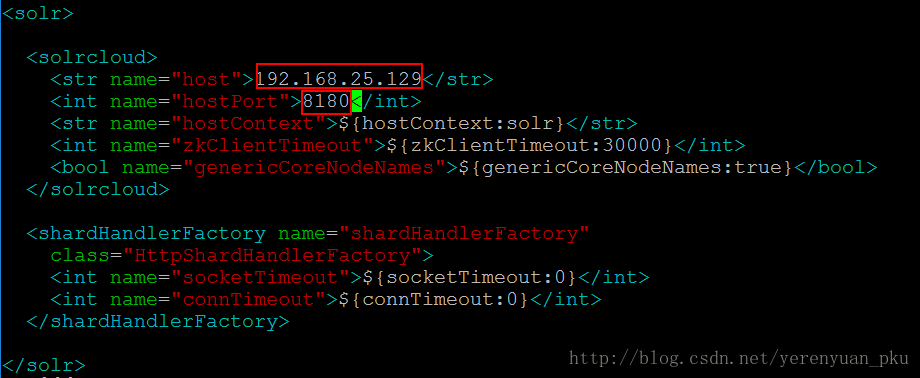
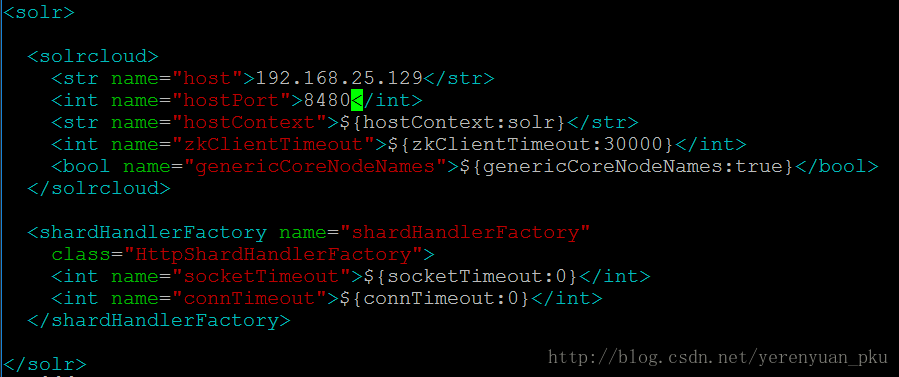
solrhome有了之后,我们还须对solrhome里面的solr.xml配置文件进行修改。每个solrhome下都有一个solr.xml文件,修改该文件时我们修改的只有<solrcloud>里面的前两项——host和hostPort,host的值修改为我们solr的IP地址,hostPort修改为我们刚才为tomcat修改的端口号,其它不用动。
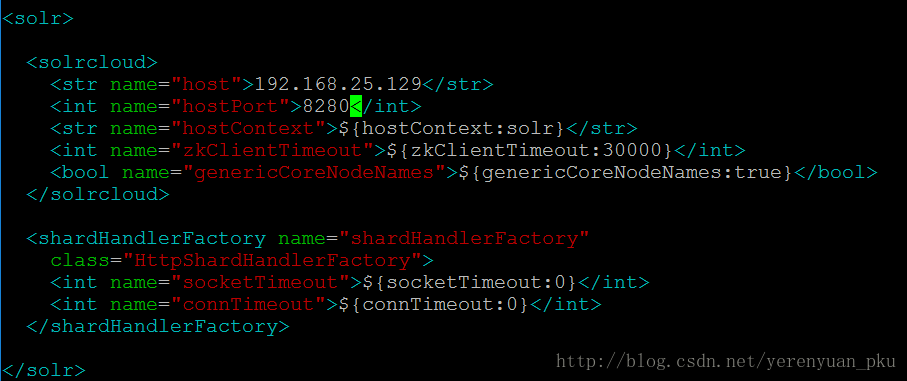
以上是solrhome01里面的solr.xml文件的修改。同理我们还需要对solrhome02、solrhome03、solrhome04里面的solr.xml文件进行相关配置,下面是solrhome02里面的solr.xml文件的配置。
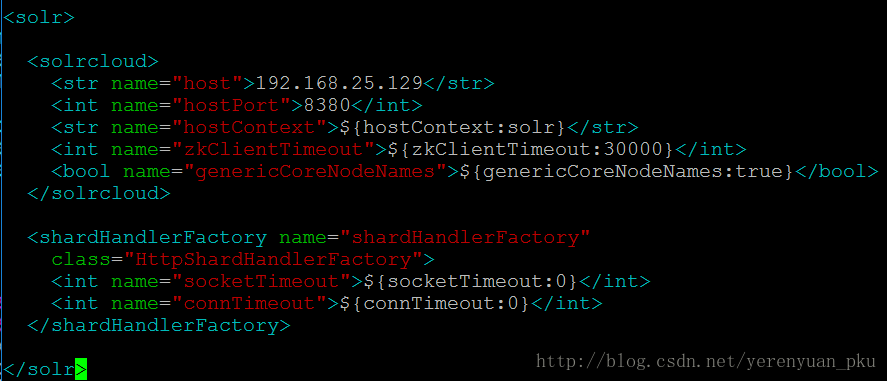
下面是solrhome03里面的solr.xml文件的配置。
下面是solrhome04里面的solr.xml文件的配置。
solrhome配置好了之后,接下来需要关联每一个solrhome和Solr,即需要修改每一个Solr工程的web.xml文件。
以上是tomcat01里面的web.xml文件的修改。同理我们还需要对tomcat02、tomcat03、tomcat04里面的web.xml文件进行相关配置。下面是tomcat02里面的web.xml文件的配置。
下面是tomcat03里面的web.xml文件的配置。
下面是tomcat04里面的web.xml文件的配置。
这样,Solr服务就和自己的solrhome关联起来了。现在每一个Solr都对应一个solrhome,都有其自己的配置文件,如果我们要想保证每一个Solr实例的配置文件都一样的话,那么这个配置文件就应该集中管理,要集中管理我们应该使用谁来管理呢?这时候就需要用到zookeeper了,zookeeper集中管理配置文件,所以我们应该把配置文件上传到zookeeper。那好了,接下来考虑上传哪些配置文件?我们只须把solrhome/collection1/conf目录上传到zookeeper即可,上传任意solrhome中的conf目录都可以哟!其中conf目录下面最重要的两个配置文件是schema.xml和solrconfig.xml。我们只要上传一份就行了,这样的话,每个Solr要连接zookeeper,它就从zookeeper上读取这一份配置文件,每一个Solr实例都共用这一份就可以了。我们已经确定下来上传什么东西了,接下来就是怎么上传的问题了?我们可使用工具上传配置文件,先找到该工具所在的位置,如下图所示。
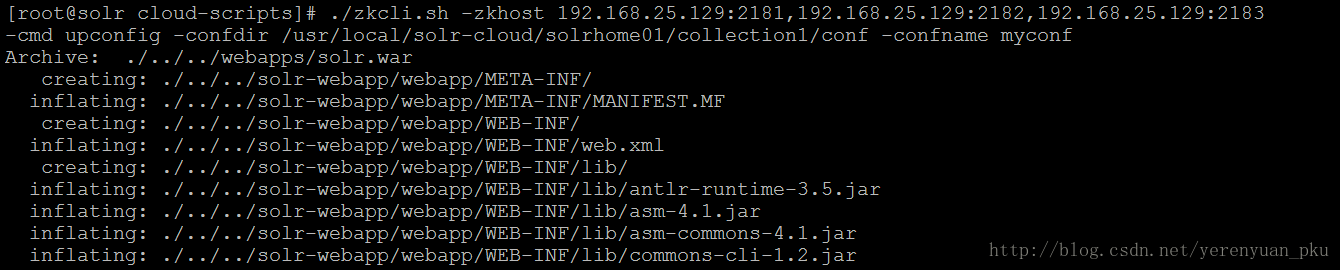
下面我们使用该zkcli.sh脚本文件来执行上传操作,我们要上传的文件目录是/usr/local/solr-cloud/solrhome01/collection1/conf,执行上传操作的命令如下:





./zkcli.sh -zkhost 192.168.25.129:2181,192.168.25.129:2182,192.168.25.129:2183 -cmd upconfig -confdir /usr/local/solr-cloud/solrhome01/collection1/conf -confname myconf
上传成功后,我们到任何一台zookeeper上检验一下配置文件是否已经被上传上来了,我们到zookeeper01的bin目录下,如下图所示。
接着使用命令./zkCli.sh来登录服务端,如下图所示。
登录成功之后,使用命令ls /来查看下根目录下是否有configs目录,如下所示,发现已经有了。
再看configs目录下是否有myconf目录,如下图所示,发现是有的。
我们还可以看看myconf目录下的所有文件,这些都是我们刚才上传的配置文件,如下图所示。
如果我们想退出,可使用quit命令。
下面我们需要修改每一个tomcat下面的bin目录下的catalina.sh文件,关联Solr和zookeeper。
首先,我们来到tomcat01的bin目录下,如下图所示,可以看到catalina.sh文件。
修改catalina.sh文件,添加JAVA_OPTS=”-DzkHost=192.168.25.129:2181,192.168.25.129:2182,192.168.25.129:2183”,如下图所示。
修改完tomcat01之后,我们再修改其它三个tomcat,添加的内容完全一样,我就不啰嗦了。
现在我们的Solr知道zookeeper的地址了,Solr会主动连接zookeeper,把自己的一些状态信息汇报给zookeeper,比如说自己的ip地址和端口号等,zookeeper
就能连接到tomcat了,它们之间就建立了一个通信关系。
下面我们要启动每个tomcat实例,启动之前要确保zookeeper集群是启动状态。如果想启动每个tomcat实例的话,不必每个实例一个个启动,这样太麻烦了,我们可以写个批处理程序来把它们一下子启动起来。在solr-cloud目录下使用vim start-tomcat-all.sh命令来创建一个批处理文件,文件内容为:




/usr/local/solr-cloud/tomcat01/bin/startup.sh
/usr/local/solr-cloud/tomcat02/bin/startup.sh
/usr/local/solr-cloud/tomcat03/bin/startup.sh
/usr/local/solr-cloud/tomcat04/bin/startup.sh保存完该文件之后,使用ll命令查看一下solr-cloud目录,可以发现start-tomcat-all.sh文件,如下图所示。
但是这个批处理程序是不能运行的,所以你需要使用chmod u+x start-tomcat-all.sh命令改一下它的权限,这样我们就可以使用./start-tomcat-all.sh命令来启动每个tomcat实例了。
我们可以使用tail -f /usr/local/solr-cloud/tomcat01/logs/catalina.out命令查看第一个tomcat的启动日志。
为了防止防火墙给集群搭建带来不必要的麻烦,建议关掉防火墙,关闭防火墙的命令是service iptables stop,禁止防火墙重启的命令是chkconfig iptables off。如下图所示。
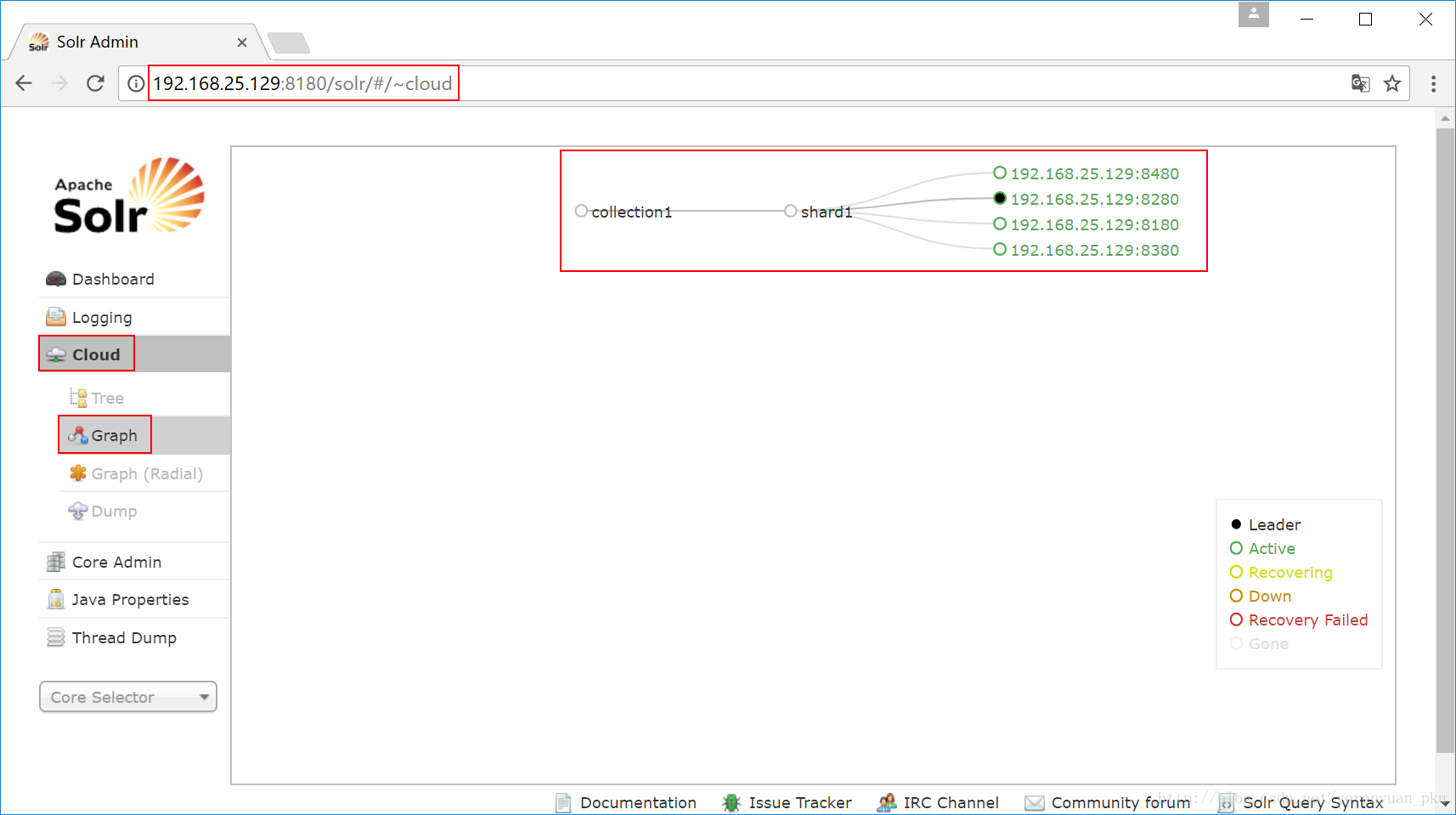
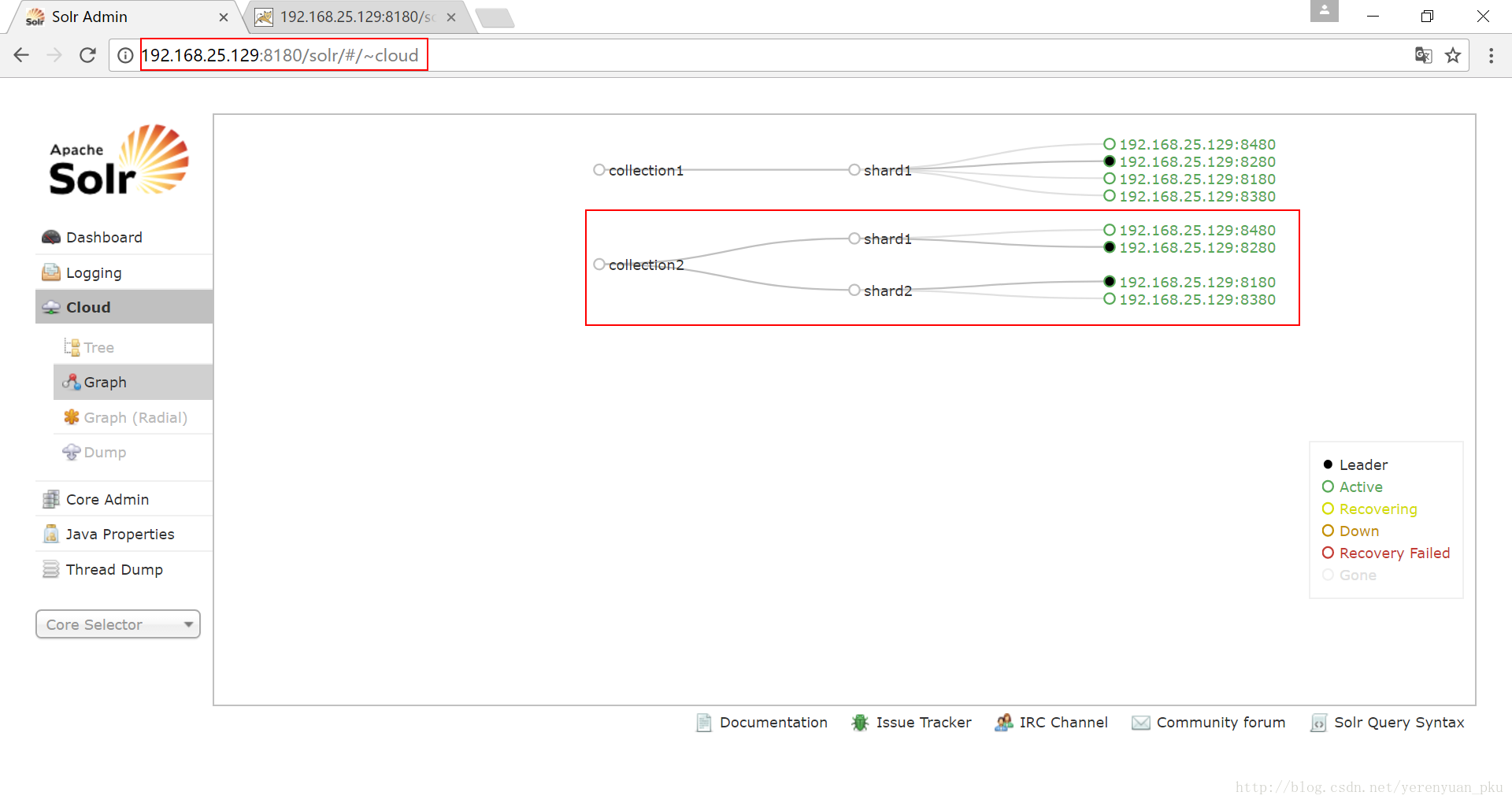
下面我们就来访问Solr集群,我们访问任何一台Solr的首页,点击”Cloud”,可以看到如下图所示的效果,可知当前还没有进行分片处理。
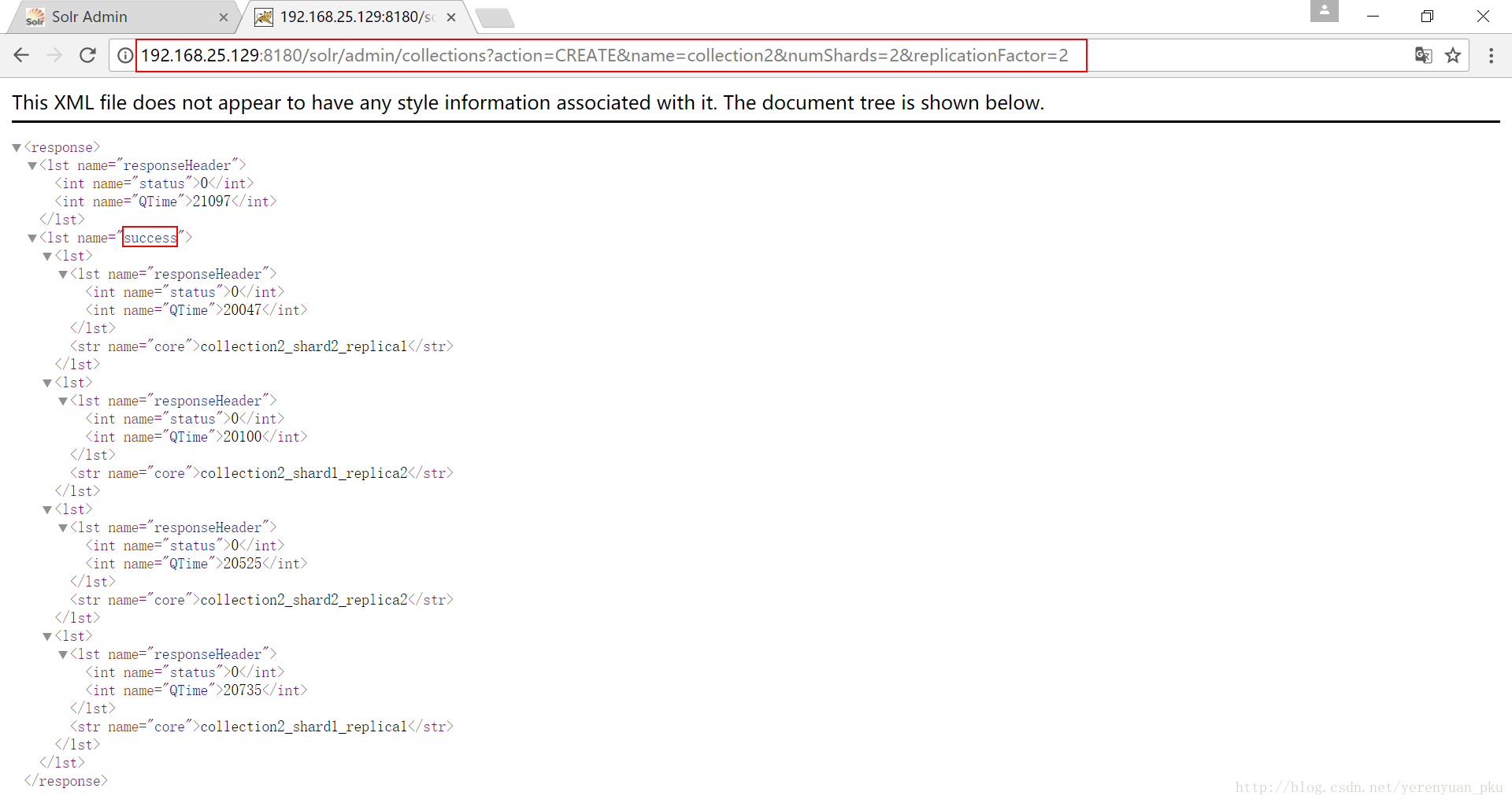
接下来我们创建新的Collection进行分片处理,使用的命令是http://192.168.25.129:8180/solr/admin/collections?action=CREATE&name=collection2&numShards=2&replicationFactor=2,执行结果如下图所示。
我们再看看Solr首页的云图,发现多了一个collection2的库,如下图所示。
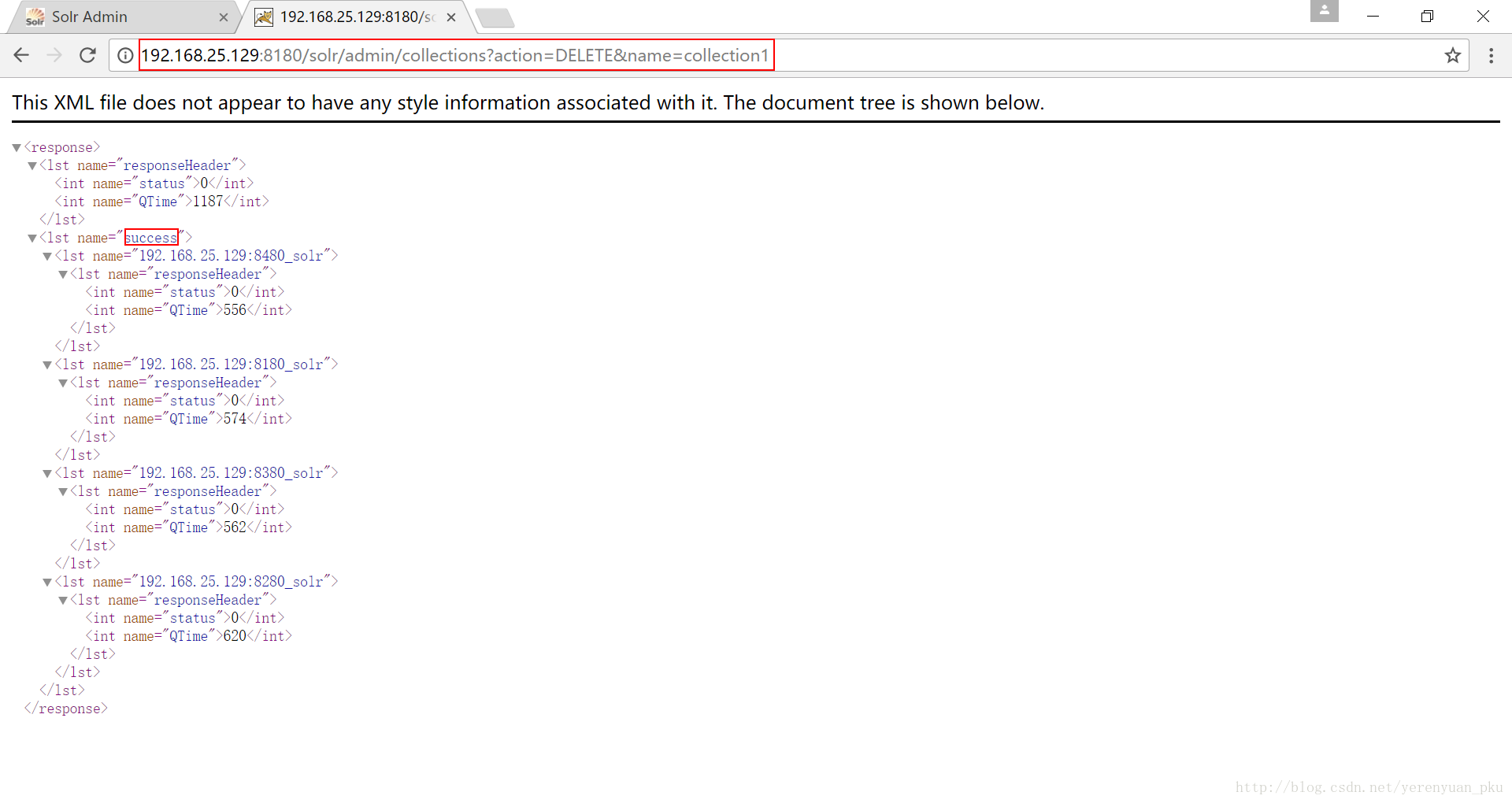
我们把没有分片的collection1删除掉,使用的命令是http://192.168.25.129:8180/solr/admin/collections?action=DELETE&name=collection1,如下图所示。
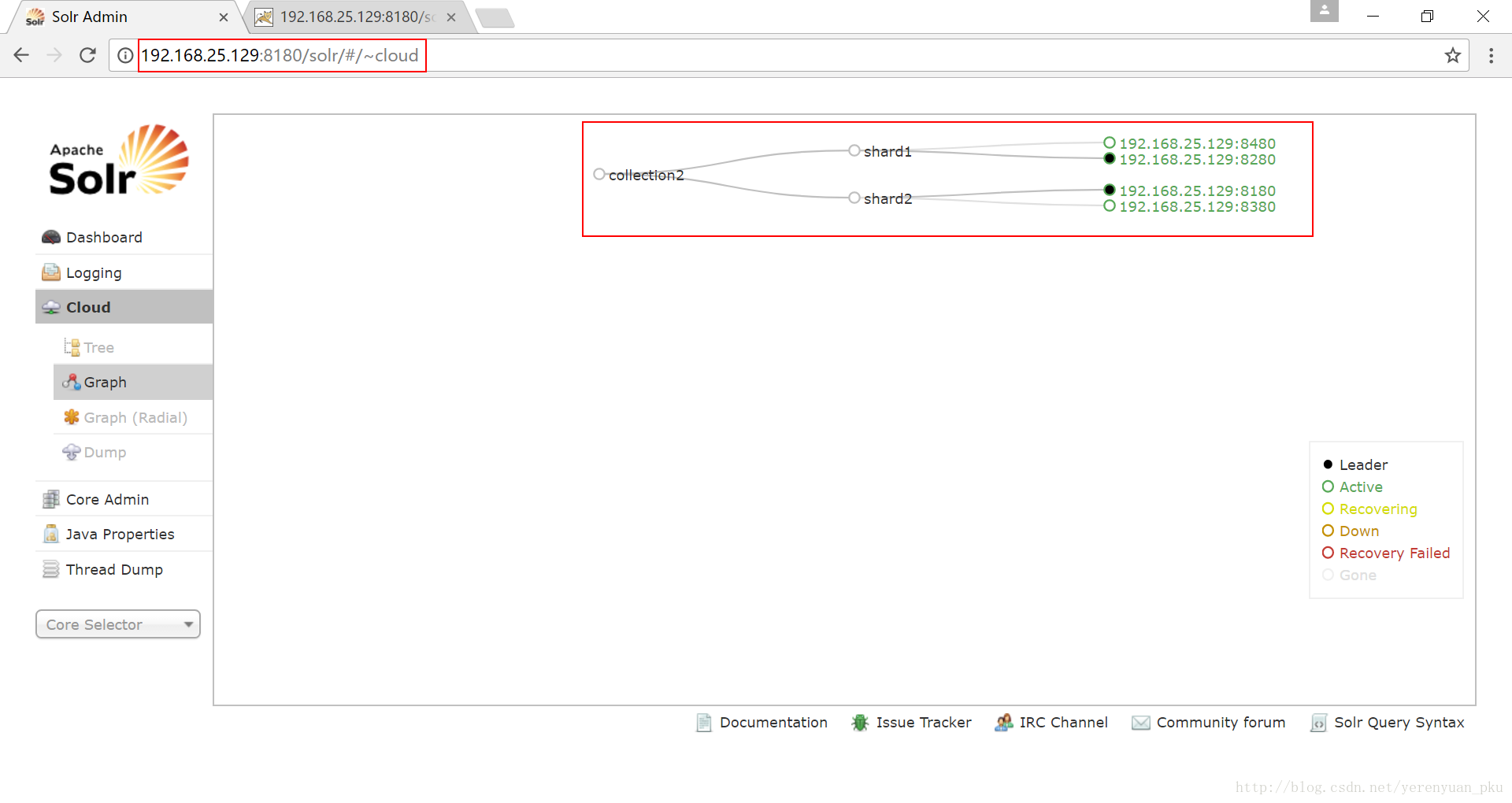
我们再来查看Solr首页云图,发现现在只剩下有分片的collection2了,我们的SolrCloud集群搭建成功了!!!