文章目录
- Question1:Netty-简要介绍一下Netty?
- Answer1:
- Question2:Netty-介绍一下 Reactor线程模型?
- Answer2:
- Question3:Netty-介绍一下Netty无锁设计?
- Answer3:
- Question4:Netty-谈一谈使用Netty实现高性能的序列化框架?
- Answer4:
- Question5:RPC-简要介绍一下RPC?
- Answer5:
- Question6:RPC-谈一谈RPC所涉及的相关技术?
- Answer6:
- Question7:RPC-介绍一下RPC的大致流程?
- Answer7:
- Question8:RPC-谈一谈RPC中的消息结构?
- Answer8:
- Question9:RPC-谈一谈RPC的通讯过程?
- Answer9:
- Question10:附加-简要阐述一下RMI及其实现步骤?
- Answer10:
- Question11:附加-简要阐述一下Protoclol Buffer?
- Answer11:
- Question12:附加-简要阐述一下Thrift?
- Answer12:
面向面试的博客,以问答式Q/A方式呈现。
Java面试专栏:云计算 https://blog.csdn.net/qq_36963950/article/details/105228870
Java面试专栏:zookeeper https://blog.csdn.net/qq_36963950/article/details/105200255
Java面试:SSM(Spring+SpringMVC+Mybatis) https://blog.csdn.net/qq_36963950/article/details/105230985
Java面试专栏:微服务 https://blog.csdn.net/qq_36963950/article/details/105265993
Java面试专栏:Netty 与 RPC https://blog.csdn.net/qq_36963950/article/details/105266425
Java面试专栏:计算机网络 https://blog.csdn.net/qq_36963950/article/details/105297603
Java面试专栏:Kafka https://blog.csdn.net/qq_36963950/article/details/105333460
Java面试专栏:RabbitMQ https://blog.csdn.net/qq_36963950/article/details/105335758
Java面试专栏:大数据Hadoop https://blog.csdn.net/qq_36963950/article/details/105336055
Java面试专栏:大数据Spark https://blog.csdn.net/qq_36963950/article/details/105336060
Java面试专栏:大数据Storm https://blog.csdn.net/qq_36963950/article/details/105336074
Java面试专栏:大数据Hbase https://blog.csdn.net/qq_36963950/article/details/105336095
Java面试专栏:负载均衡 https://blog.csdn.net/qq_36963950/article/details/105336111
Java面试专栏:数据库 https://blog.csdn.net/qq_36963950/article/details/105336136
Question1:Netty-简要介绍一下Netty?
Answer1:
第一,介绍Netty
Netty是互联网中间件领域使用最广泛最核心的网络通信框架,几乎所有互联网中间件或者大数据领域均离不开Netty。Netty 是一个高性能、异步事件驱动的 NIO 框架,基于 JAVA NIO 提供的 API 实现。它提供了对TCP、UDP 和文件传输的支持,作为一个异步 NIO 框架,Netty 的所有 IO 操作都是异步非阻塞的,通过 Future-Listener 机制,用户可以方便的主动获取或者通过通知机制获得 IO 操作结果。
第二,Netty高性能实现方式
在IO编程过程中,当需要同时处理多个客户端接入请求时,可以利用多线程或者IO多路复用技术进行处理。IO多路复用技术通过把多个 IO的阻塞复用到同一个 select 的阻塞上,从而使得系统在单线程的情况下可以同时处理多个客户端请求。与传统的多线程/多进程模型比,I/O 多路复用的最大优势是系统开销小,系统不需要创建新的额外进程或者线程,也不需要维护这些进程和线程的运行,降低了系统的维护工作量,节省了系统资源。
与Socket类和ServerSocket类相对应,NIO也提供了SocketChannel和ServerSocketChannel 两种不同的套接字通道实现。
Netty高性能实现方式1:多路复用通讯方式
Netty 架构按照 Reactor 模式设计和实现,其通讯包括服务端通信和客户端通信。
Netty服务端通信序列图如下:
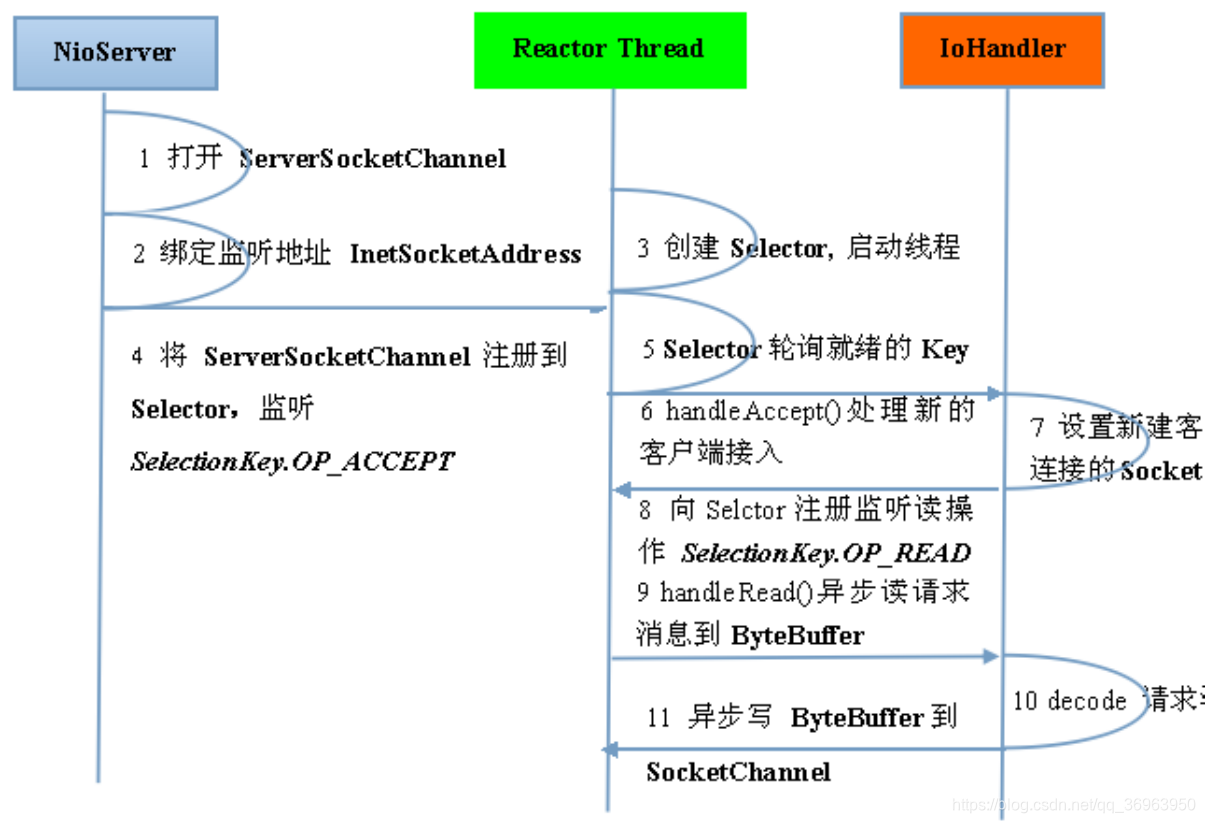
注意:上图中的读写操作都是异步进行的,即异步读、异步写。
图中操作包括:
OP_Accept handleAccept() 接受连接
OP_Read handleRead() 异步读
Netty客户端通信序列图如下:
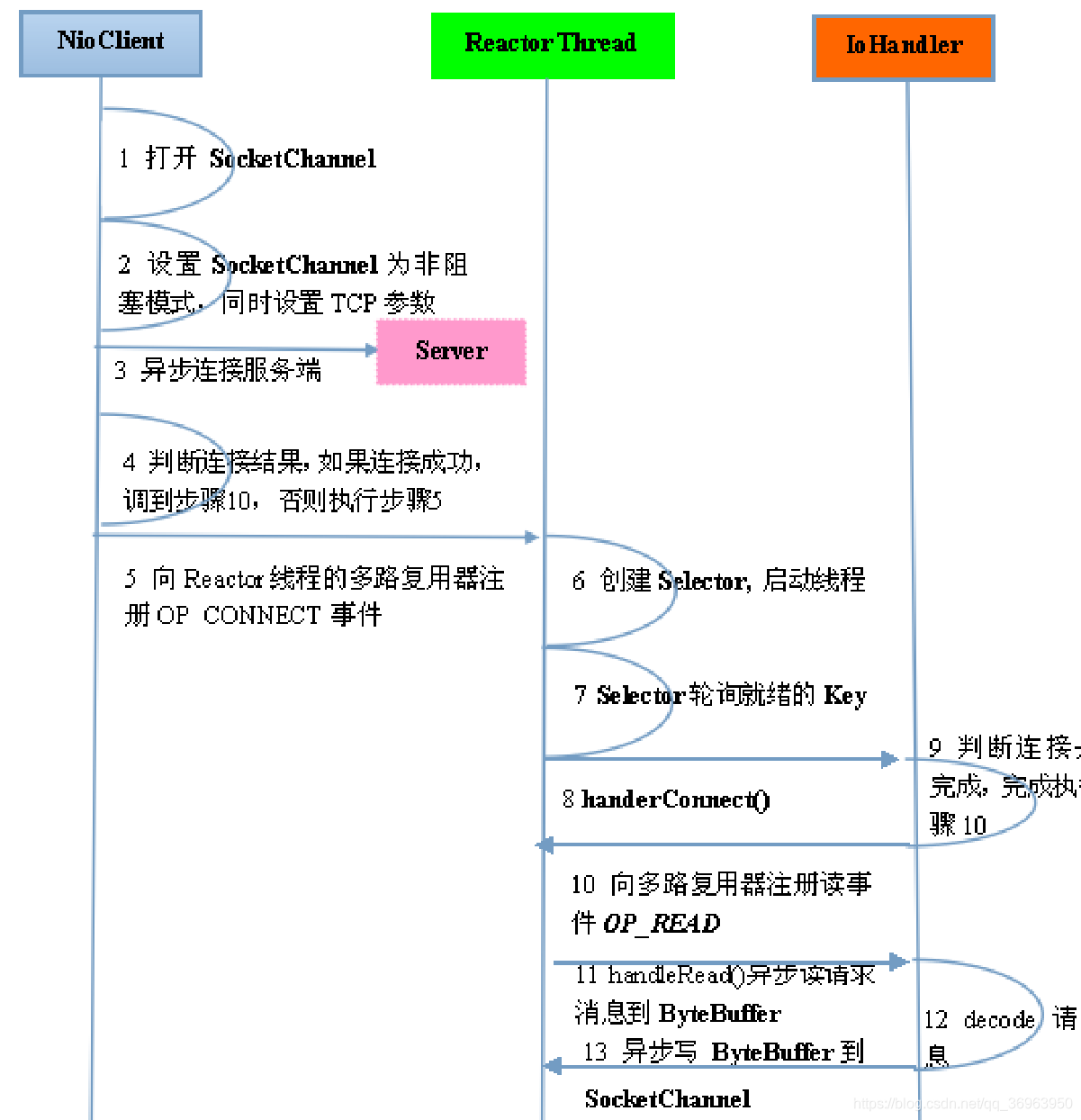
注意:上图中的读写操作都是异步进行的,即异步读、异步写。
图中操作包括:
OP_Connect handleConnect() 发出连接
OP_Read handleRead() 异步读
Netty 的 IO 线程 NioEventLoop 由于聚合了多路复用器 Selector,可以同时并发处理成百上千个客户端 Channel,由于读写操作都是非阻塞的,这就可以充分提升 IO 线程的运行效率,避免由于频繁 IO 阻塞导致的线程挂起。
Netty高性能实现方式2:异步通讯 NIO
由于 Netty 采用了异步通信模式,一个 IO 线程可以并发处理 N 个客户端连接和读写操作,这从根本上解决了传统同步阻塞 IO 一连接一线程模型,架构的性能、弹性伸缩能力和可靠性都得到了极大的提升。
Netty高性能实现方式3:零拷贝 (DIRECT BUFFERS 使用堆外直接内存 )
- Netty 的接收和发送 ByteBuffer 采用 DIRECT BUFFERS,使用堆外直接内存进行 Socket 读写,不需要进行字节缓冲区的二次拷贝。如果使用传统的堆内存(HEAP BUFFERS)进行 Socket 读写,JVM 会将堆内存 Buffer 拷贝一份到直接内存中,然后才写入 Socket 中。相比于堆外直接内存,消息在发送过程中多了一次缓冲区的内存拷贝。
- Netty 提供了组合 Buffer 对象,可以聚合多个 ByteBuffer 对象,用户可以像操作一个 Buffer 那样方便的对组合 Buffer 进行操作,避免了传统通过内存拷贝的方式将几个小 Buffer 合并成一个大的Buffer。
- Netty的文件传输采用了transferTo方法,它可以直接将文件缓冲区的数据发送到目标Channel,避免了传统通过循环 write 方式导致的内存拷贝问题。
Netty高性能实现方式4:内存池(基于内存池的缓冲区重用机制)
随着 JVM 虚拟机和 JIT 即时编译技术的发展,对象的分配和回收是个非常轻量级的工作。但是对于缓冲区 Buffer,情况却稍有不同,特别是对于堆外直接内存的分配和回收,是一件耗时的操作。为了尽量重用缓冲区,Netty 提供了基于内存池的缓冲区重用机制。
Question2:Netty-介绍一下 Reactor线程模型?
Answer2:
常用的 Reactor 线程模型有三种,Reactor 单线程模型, Reactor 多线程模型, 主从 Reactor 多线程模型。
第一,Reactor 单线程模型
含义:服务端用于接收客户端连接的是个 1 个单独的 NIO 线程,且由同一个 NIO 线程上面完成所有的 IO 操作。
NIO 线程的职责如下:
- 作为 NIO 服务端,接收客户端的 TCP 连接;
- 作为 NIO 客户端,向服务端发起 TCP 连接;
- 读取通信对端的请求或者应答消息;
- 向通信对端发送消息请求或者应答消息。
由于 Reactor 模式使用的是异步非阻塞 IO,所有的 IO 操作都不会导致阻塞,理论上一个线程可以独立处理所有 IO 相关的操作。从架构层面看,一个 NIO 线程确实可以完成其承担的职责。
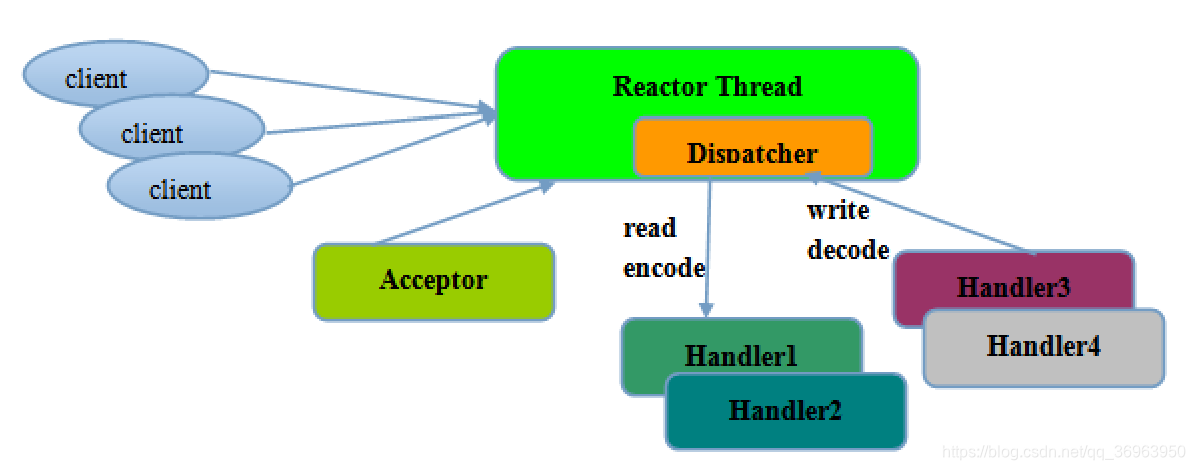
对于上图的解释:
1、各个概念:client表示客户端对象,Reactor Thread表示Reactor线程,Acceptor表示客户端对象消息接收者,Dispatcher表示Reactor线程的分发器,Handler1-4都是表示处理程序。
2、整个流程:因为Reactor 模式使用的是异步非阻塞 IO,所以一个NIO 线程可以完成整个流程。开始,客户端对象Client发出TCP连接请求,然后,Acceptor 接收客户端的 TCP 连接请求消息,链路建立成功之后,通过 Dispatcher 将对应的ByteBuffer派发到指定的 Handler 上进行消息解码,图中表示Handler3、Handler4将数据写出到Reactor线程,Handler1、Handler2将从Reactor线程读入数据。
第二,Reactor 多线程模型
含义:服务端用于接收客户端连接的是个 1 个单独的 NIO 线程,然后,一组 NIO 线程上面完成所有的 IO 操作。
Reactor 多线程模型有专门一个NIO 线程——Acceptor 线程用于监听服务端,接收客户端的 TCP 连接请求; 网络 IO 操作-读、写等由一个 NIO 线程池负责,线程池可以采用标准的 JDK 线程池实现,它包含一个任务队列和 N个可用的线程,由这些 NIO 线程负责消息的读取、解码、编码和发送。
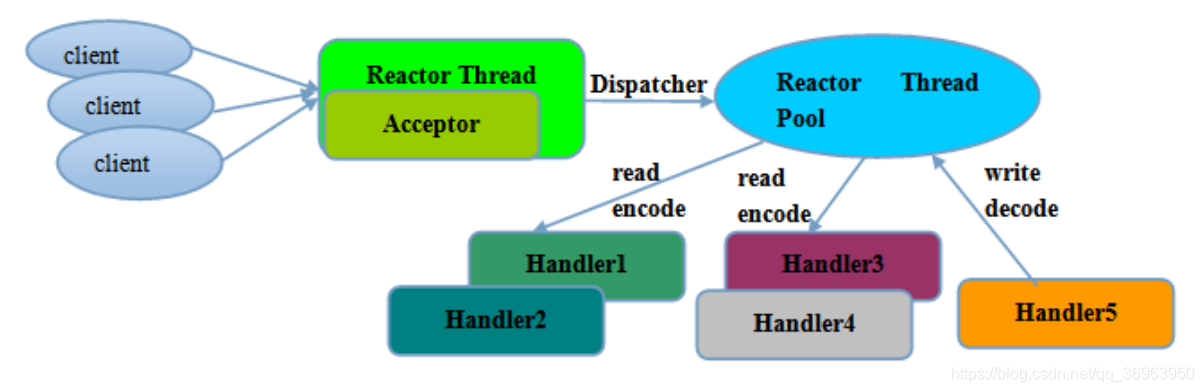
对于上图的解释:
1、各个概念:client表示客户端对象,Reactor Thread表示Reactor线程,Acceptor表示客户端对象消息接收者,Dispatcher表示Reactor线程的分发器,Reactor Thread Pool表示 一个 NIO 线程池,里面有N个 NIO线程,即一组NIO 线程,Handler1-5都是表示处理程序。
2、整个流程:开始,客户端对象Client发出TCP连接请求,然后,Acceptor 接收客户端的 TCP 连接请求消息,链路建立成功之后,通过 Dispatcher 将对应的ByteBuffer派发到指定的 Handler 上进行消息解码(中间通过线程池Reactor Thread Pool),图中表示
Handler5 将数据写出到Reactor线程,Handler1、Handler2、Handler3、Handler4将从Reactor线程读入数据。
第三,主从 Reactor 多线程模型
含义:服务端用于接收客户端连接的是一个独立的 NIO 线程池,而且由一组 NIO 线程上面完成所有的 IO 操作。
Acceptor 接收到客户端 TCP 连接请求处理完成后(可能包含接入认证等),将新创建的SocketChannel 注册到 IO 线程池(sub reactor 线程池)的某个 IO 线程上,由它负责SocketChannel 的读写和编解码工作。Acceptor 线程池仅仅只用于客户端的登陆、握手和安全认证,一旦链路建立成功,就将链路注册到后端 subReactor 线程池的 IO 线程上,由 IO 线程负责后续的 IO 操作。
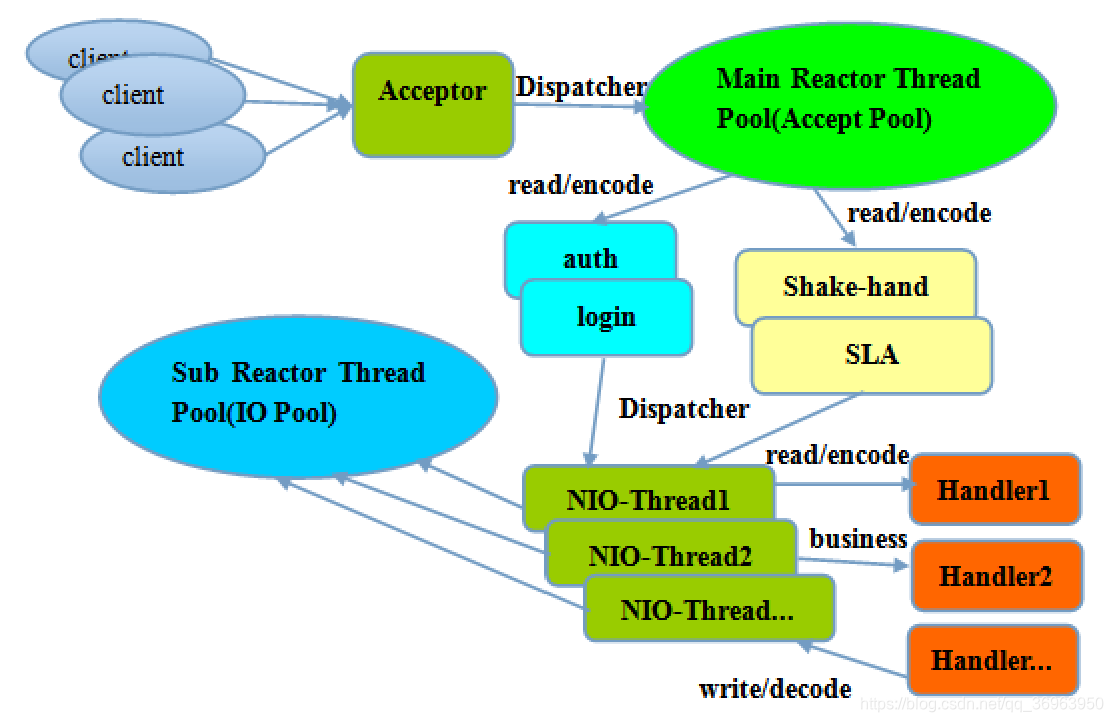
对于上图的解释:
1、各个概念:client表示客户端对象,Acceptor表示客户端对象消息接收者,Dispatcher表示分发器,Main Reactor Thread Pool(Accept Pool)表示主Reactor线程池,是接收客户端连接Reactor线程池,所以也称为Accept Pool接收池,auth表示认证、login表示登录、shake-hand表示握手、SLA表示服务级别协议,都是中间过程,Dispatcher表示分发器,Sub Reactor Thread Pool(IO Pool)表示从Reactor线程池,用于IO,又称为IO Pool,里面有N个 NIO线程,即一组NIO 线程,NIO-Thread1、NIO-Thread2、NIO-Thread…表示 从Reactor线程池 中的 一组NIO 线程,Handler1-Handler…都是表示处理程序。
2、整个流程:开始,客户端对象Client发出TCP连接请求,然后,Acceptor 接收客户端的 TCP 连接请求消息,分发到主Reactor线程池,主Reactor线程池中线程完成与客户端的登陆、握手和安全认证,链路建立成功之后,通过 Dispatcher 将对应的ByteBuffer派发到指定的 Handler 上进行消息解码(中间通过线程池Sub Reactor Thread Pool),图中Handler1、Handler2、Handler…表示的就是这个意思。
第四,一表小结
| Reactor线程模型 | 服务端接收客户端连接 客户端与服务端建立链路连接 |
完成IO操作 |
|---|---|---|
| Reactor单线程模型 | 一个Reactor线程 | 一个Reactor线程 |
| Reactor多线程模型 | 一个Reactor线程 | Reactor Thread Pool,是一个Reactor线程池 |
| 主从Reactor多线程模型 | Main Reactor Thread Pool(Accept Pool)主Reactor线程池,又称为接收者池 | Sub Reactor Thread Pool(IO Pool)从Reactor线程池,又称为IO池 |
Question3:Netty-介绍一下Netty无锁设计?
Answer3:
Netty 采用了串行无锁化设计,在 IO 线程内部进行串行操作,避免多线程竞争导致的性能下降。表面上看,串行化设计似乎 CPU 利用率不高,并发程度不够。但是,通过调整 NIO 线程池的线程参数,可以同时启动多个串行化的线程并行运行,这种局部无锁化的串行线程设计相比一个队列-多个工作线程模型性能更优。
这种串行无锁又称为局部无锁,因为一个串行处理中只有一个IO线程运行,绝对不存在任何多线程争用的安全问题,所以去掉同步锁换来更高的效率,所以称为串行无锁/局部无锁。
当然,可以多个串行化线程并行运行,互不干扰,最大程度提高效率。

对于上图的解释:
图中概念:NioEventLoop 表示一个基于JDK NIO的异步事件循环类,read表示读操作,write表示写操作,两个Handler表示处理程序,encode表示编码,decode表示解码,ChannelPipeline 表示一个是ChannelHandler的容器。
整个流程:Netty 的 NioEventLoop 使用read读取到消息之后,直接调用 ChannelPipeline 的fireChannelRead(Object msg),通过必要的编码和解码后,将数据写出到NioEventLoop 中。
Netty 的 NioEventLoop 读取到消息之后,直接调用 ChannelPipeline 的fireChannelRead(Object msg),只要用户不主动切换线程,一直会由 NioEventLoop 调用到用户的 Handler,期间不进行线程切换,这种串行化处理方式避免了多线程操作导致的锁的竞争,从性能角度看是最优的。
Question4:Netty-谈一谈使用Netty实现高性能的序列化框架?
Answer4:
由于Netty 默认提供了对 Google Protobuf 的支持,通过扩展 Netty 的编解码接口,用户可以实现其它的高性能序列化框架,例如 Thrift 的压缩二进制编解码框架。
- SO_RCVBUF(接收缓冲区) 和 SO_SNDBUF(发送缓冲区):通常建议值为 128K 或者 256K。
- SO_TCPNODELAY(小包封大包,防止网络阻塞):TCP_NODELAY选项是用来控制是否开启Nagle算法,Nagle算法是为了提高较慢的广域网传输效率,通过将缓冲区内的小封包自动相连,组成较大的封包,阻止大量小封包的发送阻塞网络,从而提高网络应用效率。但是对于时延敏感的应用场景需要关闭该优化算法。
- RPS(软中断 Hash 值和 CPU 绑定):全称为 Receive Packet Steering,即接收包转向,是google贡献给linux kernel的一个patch,开启 RPS 后可以实现软中断,提升网络吞吐量。RPS 根据数据包的源地址、源端口、目的地址和目的端口,计算出一个 hash 值,然后根据这个 hash 值来选择软中断运行的 cpu;从上层来看,也就是说将每个连接和 cpu 绑定,并通过这个 hash 值来均衡软中断在多个 cpu 上,提升网络并行处理性能。
Question5:RPC-简要介绍一下RPC?
Answer5:
RPC,即 Remote Procedure Call(远程过程调用),调用远程计算机上的服务,就像调用本地服务一样。RPC 可以很好的解耦系统,如 WebService 就是一种基于 Http 协议的 RPC。整个 RPC 整体框架如下:
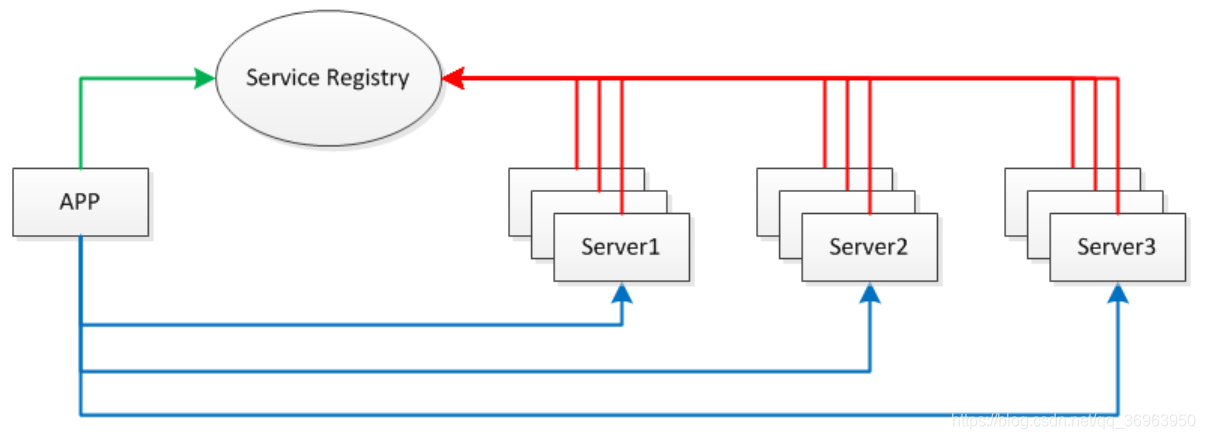
对于上图的理解:
1、各个概念:Service Registry表示服务注册,APP表示application应用程序,Server1、Server2、Server3表示服务器。
2、整个流程:RPC很好的解耦系统客户端和服务端,使调用远程计算机上的服务,就像调用本地服务一样,图中APP和三个Server表示是就是这个意思。
Question6:RPC-谈一谈RPC所涉及的相关技术?
Answer6:
RPC所涉及的相关技术:
- 服务发布与订阅:使用 Zookeeper 发布与订阅,服务端使用 Zookeeper 注册服务地址,客户端使用 Zookeeper 获取可用的服务地址。
- 通信:使用 Netty 作为通信框架。
- Spring:使用 Spring 配置服务,加载 Bean,扫描注解。
- 动态代理:客户端使用代理模式透明化服务调用。
- 消息编解码:使用 Protostuff 序列化和反序列化消息。
Question7:RPC-介绍一下RPC的大致流程?
Answer7:
RPC大致流程如下:
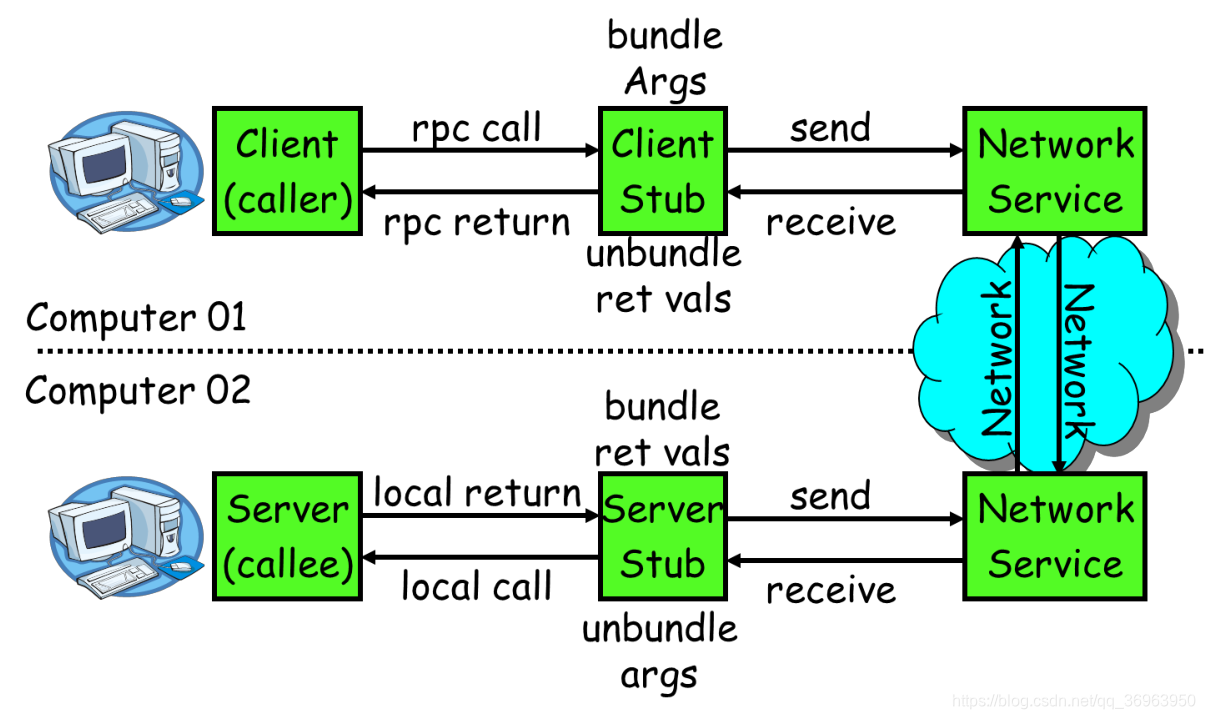
上图的中的流程(从上到下)为:
- rpc call:服务消费方(client)调用以本地调用方式调用服务;
- send:client stub 接收到调用后负责将方法、参数等组装成能够进行网络传输的消息体;然后client stub 找到服务地址,并将消息发送到服务端;
- receive:server stub 收到消息后进行解码;
- local call:server stub 根据解码结果调用本地的服务;
- local return:本地服务执行并将结果返回给 server stub;
- send:server stub 将返回结果打包成消息并发送至消费方;
- receive:client stub 接收到消息,并进行解码;
- rpc return:服务消费方得到最终结果。
RPC 的目标就是要 2~7 这些步骤都封装起来,让用户对这些细节透明,这样一来,用户调用远程计算机上的服务,就像调用本地服务一样了,用户只能看到第1步 rpc call 和 第8步 rpc return。在JAVA语言中, 一般使用动态代理方式实现远程调用。
Question8:RPC-谈一谈RPC中的消息结构?
Answer8:
客户端的请求消息结构一般需要包括以下内容:
消息数据结构 (接口名称 + 方法名 + 参数类型和参数值 + 超时时间 + requestID )
- 接口名称:在我们的例子里接口名是“HelloWorldService”,如果不传,服务端就不知道调用哪个接口了;
- 方法名:一个接口内可能有很多方法,如果不传方法名服务端也就不知道调用哪个方法;
- 参数类型和参数值:一个方法的参数列表中有很多参数,每一个参数包括参数类型和参数值,参数类型有很多,比如有 bool、int、long、double、string、map、list,甚至如 struct(class);以及相应的参数值;
- 超时时间:该请求的达到某个时间未返回而视为请求失败。
- requestID:标识唯一请求 id。
服务端返回的消息结构一般包括以下内容:
返回值+状态 code+requestID
- 返回值:服务端给客户端的有意义的返回值;
- 状态code:该请求的网站状态,和返回值一起使用;
- requestID:标识唯一请求 id。
Question9:RPC-谈一谈RPC的通讯过程?
Answer9:
步骤一:使用 AtomicLong 生成 requestID
client 线程每次通过 socket 调用一次远程接口前,生成一个唯一的 ID,requestID(requestID 必需保证在一个 Socket 连接里面是唯一的),一般常常使用 AtomicLong从 0 开始累计数字生成唯一 ID;
步骤二:存放回调对象 callback 到全局 ConcurrentHashMap
将 处 理 结 果 的 回 调 对 象 callback , 存 放 到 全 局 ConcurrentHashMap 里 put(requestID, callback);
步骤三:synchronized 获取回调对象 callback 的锁并自旋 wait
当线程调用 channel.writeAndFlush()发送消息后,紧接着执行 callback 的 get()方法试图获取远程返回的结果。在 get()内部,则使用 synchronized 获取回调对象 callback 的锁,再先检测否已经获取到结果,如果没有,然后调用 callback 的 wait()方法,释放callback 上的锁,让当前线程处于等待状态。
步骤四:监听消息的线程收到消息,找到 callback 上的锁并唤醒
服务端接收到请求并处理后,将response结果(此结果中包含了前面的requestID)发送给客户端,客户端 socket 连接上专门监听消息的线程收到消息,分析结果,取到requestID,再从前面的 ConcurrentHashMap 里面 get(requestID),从而找到callback 对象,再用 synchronized 获取 callback 上的锁,将方法调用结果设置到callback 对象里,再调用 callback.notifyAll()唤醒前面处于等待状态的线程。
public Object get() {
synchronized (this) { // 旋锁
while (true) { // 是否有结果了
if (!isDone){
wait(); //没结果释放锁,让当前线程处于等待状态
}else{
//获取数据并处理
}
}
}
}
private void setDone(Response res) {
this.res = res;
isDone = true;
synchronized (this) { //获取锁,因为前面 wait()已经释放了 callback 的锁了
notifyAll(); // 唤醒处于等待的线程
}
}
Question10:附加-简要阐述一下RMI及其实现步骤?
Answer10:
第一,RMI
含义:RMI,英文全称 Remote Method Invocation,译为远程方法调用。
Java 远程方法调用,即 Java RMI(Java Remote Method Invocation)是 Java 编程语言里,一种用于实现远程过程调用的应用程序编程接口。它使客户机上运行的程序可以调用远程服务器上的对象。远程方法调用特性使 Java 编程人员能够在网络环境中分布操作。RMI 全部的宗旨就是尽可能简化远程接口对象的使用。
第二,RMI实现步骤
- 编写远程服务接口,该接口必须继承 java.rmi.Remote 接口,方法必须抛出java.rmi.RemoteException 异常;
- 编写远程接口实现类,该实现类必须继承 java.rmi.server.UnicastRemoteObject 类;
- 运行 RMI 编译器(rmic),创建客户端 stub 类和服务端 skeleton 类;
- 启动一个 RMI 注册表,以便驻留这些服务;
- 在 RMI 注册表中注册服务;
- 客户端查找远程对象,并调用远程方法;
六个步骤代码如下:
1:创建远程接口,继承 java.rmi.Remote 接口
public interface GreetService extends java.rmi.Remote {
String sayHello(String name) throws RemoteException;
}
2:实现远程接口,继承 java.rmi.server.UnicastRemoteObject 类
public class GreetServiceImpl extends java.rmi.server.UnicastRemoteObject
implements GreetService {
private static final long serialVersionUID = 3434060152387200042L;
public GreetServiceImpl() throws RemoteException {
super();
}
@Override
public String sayHello(String name) throws RemoteException {
return "Hello " + name;
}
}
3:生成 Stub 和 Skeleton;
4:执行 rmiregistry 命令注册服务
5:启动服务
LocateRegistry.createRegistry(1098);
Naming.bind("rmi://10.108.1.138:1098/GreetService", new GreetServiceImpl());
6.客户端调用
GreetService greetService = (GreetService)
Naming.lookup("rmi://10.108.1.138:1098/GreetService");
System.out.println(greetService.sayHello("Jobs"));
Question11:附加-简要阐述一下Protoclol Buffer?
Answer11:
protocol buffer 是 google 的一个开源项目,它是用于结构化数据串行化的灵活、高效、自动的方法,例如 XML,不过它比 xml 更小、更快、也更简单。你可以定义自己的数据结构,然后使用代码生成器生成的代码来读写这个数据结构。你甚至可以在无需重新部署程序的情况下更新数据结构。
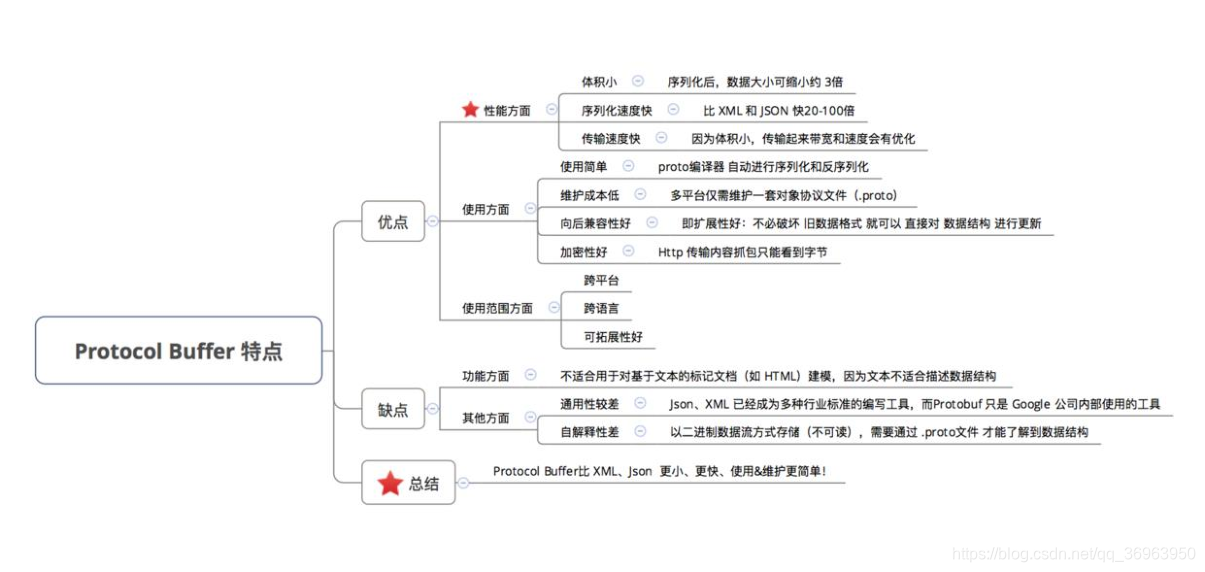
Protocol Buffer 的序列化 & 反序列化简单 & 速度快的原因是:
- 编码 / 解码 方式简单(只需要简单的数学运算 = 位移等等)
- 采用 Protocol Buffer 自身的框架代码 和 编译器 共同完成Protocol Buffer 的数据压缩效果好(即序列化后的数据量体积小)的原因是:
a. 采用了独特的编码方式,如 Varint、Zigzag 编码方式等等
b. 采用 T - L - V 的数据存储方式:减少了分隔符的使用 & 数据存储得紧凑
Question12:附加-简要阐述一下Thrift?
Answer12:
Apache Thrift 是 Facebook 实现的一种高效的、支持多种编程语言的远程服务调用的框架。
实际上,目前流行的服务调用方式有很多种,如基于 SOAP 消息格式的 Web Service,基于 JSON 消息格式的 RESTful 服务等。其中所用到的数据传输方式包括 XML,JSON 等,然而 XML 相对体积太大,传输效率低,JSON 体积较小,新颖,但还不够完善。
Thrift采用接口描述语言定义并创建服务,支持可扩展的跨语言服务开发,所包含的代码生成引擎可以在多种语言中,如 C++, Java, Python, PHP, Ruby, Erlang, Perl, Haskell, C#, Cocoa,Smalltalk 等创建高效的、无缝的服务,其传输数据采用二进制格式,相对 XML 和 JSON 体积更小,对于高并发、大数据量和多语言的环境更有优势。
为什么要 Thrift:
1、多语言开发的需要
2、性能问题
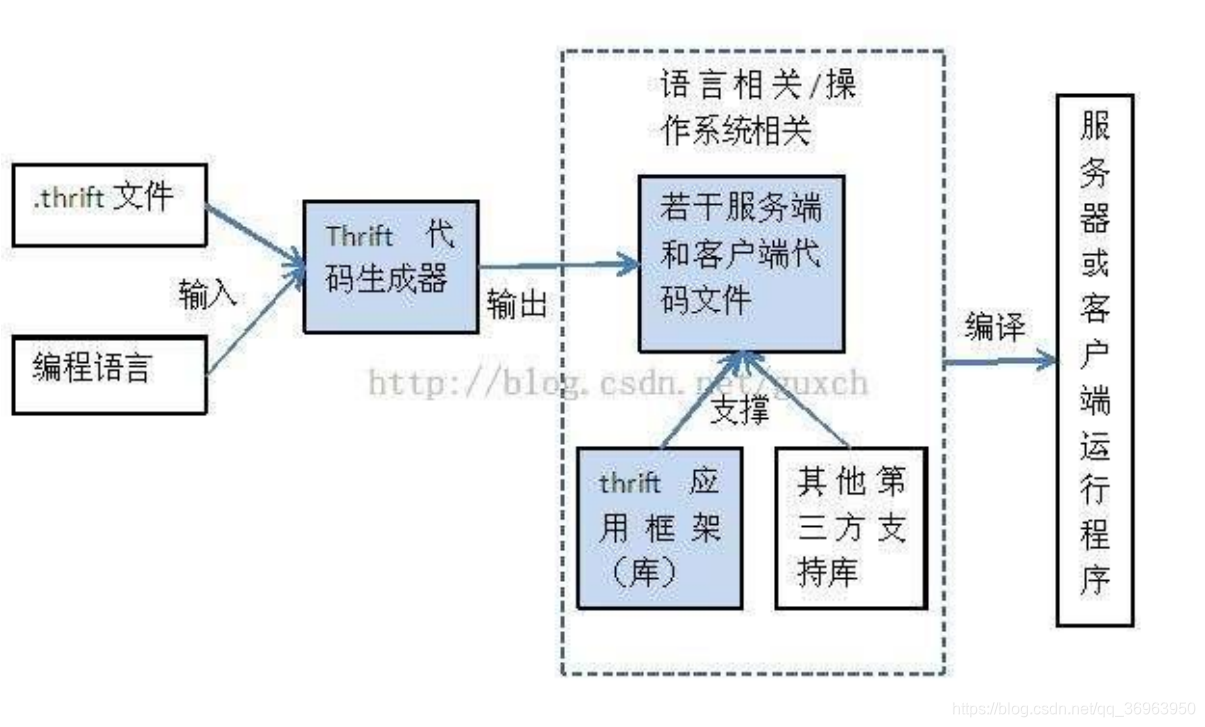
对于上图所示,阐述使用Thrift两个原因:
1、多语言开发的需要 :.thrift文件和编程语言一起通过Thrift代码生成器,这样,由于.thrift文件的存在,Thrift很好的解决了多语言程序的问题。
2、性能问题:Thrift传输数据采用二进制格式,相对 XML 和 JSON 体积更小,对于高并发、大数据量和多语言的环境更有优势,很好的解决性能问题。
Java面试专栏:云计算 https://blog.csdn.net/qq_36963950/article/details/105228870
Java面试专栏:zookeeper https://blog.csdn.net/qq_36963950/article/details/105200255
Java面试:SSM(Spring+SpringMVC+Mybatis) https://blog.csdn.net/qq_36963950/article/details/105230985
Java面试专栏:微服务 https://blog.csdn.net/qq_36963950/article/details/105265993
Java面试专栏:Netty 与 RPC https://blog.csdn.net/qq_36963950/article/details/105266425
Java面试专栏:计算机网络 https://blog.csdn.net/qq_36963950/article/details/105297603
Java面试专栏:Kafka https://blog.csdn.net/qq_36963950/article/details/105333460
Java面试专栏:RabbitMQ https://blog.csdn.net/qq_36963950/article/details/105335758
Java面试专栏:大数据Hadoop https://blog.csdn.net/qq_36963950/article/details/105336055
Java面试专栏:大数据Spark https://blog.csdn.net/qq_36963950/article/details/105336060
Java面试专栏:大数据Storm https://blog.csdn.net/qq_36963950/article/details/105336074
Java面试专栏:大数据Hbase https://blog.csdn.net/qq_36963950/article/details/105336095
Java面试专栏:负载均衡 https://blog.csdn.net/qq_36963950/article/details/105336111
Java面试专栏:数据库 https://blog.csdn.net/qq_36963950/article/details/105336136
