存储体系概述
计算系系统的记忆设备,用来存放程序和数据。
存储器的分类
-
按存储介质(能寄存0 1两种代码并能区别两种状态的元器件)分类
磁表面存储器:是在金属或塑料基体表面涂一层磁性材料作为记录介质,工作时磁层随载体高速运转,用磁头在磁层上进行读写操作。信息被记录在磁层上,信息的轨迹就是磁道。磁鼓、磁带、磁盘。非易失性存储器。磁芯存储器:磁芯是由硬磁材料做成的环状元件,在磁芯中穿有驱动线和读出线,用以进行读写操作。非易失性存储器体积大,工艺复杂,功耗大,几乎不使用。
半导体存储器:采用超大规模集成电路工艺制成芯片。体积小,功耗低,存取时间短。掉电信息丢失,现已研制出用非挥发性材料制成的半导体存储器,非易失性。按其材料的不同,分为双极性(TTL)半导体存储器和MOS半导体存储器,前者速度快,后者集成度高,制造简单,成本低廉,功耗小。
光存储器:应用激光在记录介质(磁光材料)上进行读写,非易失性存储器。光盘。
纸带存储器
-
按存取方式分类
随机读写存储器(random access memory, 即 RAM):存储单元既能被读又能被写,通过指令可以随即时地、按地址对各个存储单元进行访问,访问所需时间基本固定,而与存储单元地址无关。易失性存储器。分为静态RAM,动态RAM。在计算机系统中,主存储器都采用随机存储器。只读存储器(Read-only Memory, ROM):对其内容只能读出不能写入的存储器, 即预先一次性写入的存储器。与随机存储器可共同作为主存的一部分,统一构成主存的地址域。只读存储器断电后仍能保存信息。掩膜式只读存储器( Mask read-only memory, 即 MROM),在制造芯片时其内容就已经预先写入,内容通常是固定不变的程序、汉字字型库、字符及图形符号等;可编程只读存储器(programmable ROM,即 PROM),用户只可以对该种存储器芯片写一次。可擦除可编程序的只读存储器(erasable PROM, 即 EPROM),用户对该种存储器芯片写入后,可以用紫外线擦除其内容,再重新写入新内容。电可擦除的可编程序的只读存储器(electrically EPROM, 即 E2PROM),功能与 EPROM 相同,区别在于 E2PROM 是用电擦除的。闪存(Flash memory)是在 EPROM 和 E2PROM 的基础上发展而来的,它的基本存储单元结构类似 EPROM,但是它的擦除方式和 E2PROM 一样,用电擦除。
相联存储器(Content Addressesd Memory ,即 CAM),访问一个字是通过它的部分内容而不是地址进行检索。
顺序存储器(串行访问存储器)(SAS),这种存储器只能按某种顺序来存取,存取时间和存储单元的物理位置有关,如磁带等。 (磁盘属于部分串行访问的存储器)
直接存取存储器(DAS):这种存储器的存取时间与信息所在的物理位置有关,它寻址时,首先根据地址编码的部分信息找到信息所在的范围,然后再在此范围内进行顺序检索, 从而找到目标信息。如磁盘、磁鼓存储器。其容量大,又能长久保存信息,尽管寻址较慢, 但价格较低,适合作辅助存储器。
-
按信息的可保存性分类
在断电后还能保存信息的存储器称为永久记忆的存储器;反之,称为非永久记忆的存储器。 -
按在计算机系统中的作用分类
寄存器:通常制作于CPU芯片内,CPU内可以有十几个,几十个寄存器,速度最快,价位最高,容量最小。主存储器:可以与CPU直接交换信息。用于存放将要运行的程序和数据。
辅助存储器:主存的后援存储器,存放当前暂时不用的程序和数据,不能与CPU直接交换信息。容量大,速度慢,每位价格低。
高速缓冲存储器 Cache :用在速度不同的两个存储器之间,起到缓冲作用。
存储器的层次结构
-
寄存器:容量小,访问时间是几个纳秒,可以满足 CPU的要求。
高速缓存 Cache:容量可以是几 MB,它的访问时间是寄存器访问时间的几倍。
主存:在各种不同类型的存储器中,主存是最重要的部分,任何程序如果要在计算机中执行,则首先必须将其调入主存才能由 CPU 执行。主存容量一般在几十到数千 MB 之间,它的访问时间是几十个纳秒。
辅存:CPU不能直接访问辅存,辅存只能与只能与主存交换信息。用来存放暂时没有用到的程序和数据文件。容量更大,位成本最低,速度更慢。
-
缓存和主存的层次:主要解决 CPU和主存的速度不匹配的问题。为了改进存储器的速度性能,可以采用两种方法:提高主存储器的速度,其技术是将主存划分成若干个模块,采用多模块交叉存储技术,实现多个模块的并行存取,从而达到提高的目的。或在 CPU 和主存之间增加高速缓冲存储器,该缓存容量小而速度快,可将主存中要用的指令和数据调入其中,使 CPU 可以与高速缓存直接交换信息。因为对速度要求高, 所以对 CPU和高速缓存之间的信息交换的控制管理由硬件来实现。速度接近缓存,高于主存,容量和价位接近于主存。
-
主存和辅存的层次:主要解决存储系统的容量问题。主存和辅存层次采用虚拟存储器技术,以大容量的辅助存储器依托,把当前要用到的或经常要用到的部分信息存放在主存中,而把其他尚未用到或不常用到的信息存放在辅助存储器中,当 CPU需要用到这些信息时,再将他们从辅存中调入主存,供 CPU访问。速度接近于主存,容量,价格接近于辅存。虚拟存储器的这种调度工作是通过软硬件结合的方法把主存和辅存统一成一个整体,构成主存-辅存层次。主存和辅存之间的数据调动是由硬件和OS共同完成的。
-
存储系统的工作原理是:CPU 首先访问 Cache,如果 Cache 中没有所需要的内容,则存储系统通过辅助硬件到主存中去找;如果主存没有 CPU 要访问的内容,则存储系统通过辅助硬件或软件,到辅存中去找;然后把找到的数据逐级调入相应的存储器。
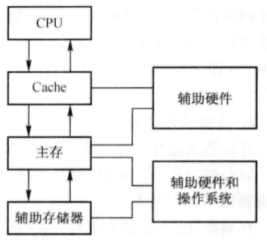
主存储器
概述
-
根据某个MAR中的地址访问某个存储单元时,需要经过地址译码,驱动电路才能找到所需访问的单元。读出时,需要经过读出放大器,才能将被选中的单元的存储字送到MDR。写入时,MDR中的数据必须经过写入电路才能真正的写入到被选中的单元中。
-
主存中存储单元地址的分配按字寻址或按字节寻址。
主存储器性能指标
-
存储容量
存储器由许多可存放一位二进制信息的存储位元组成,若干个这样的存储位元组成一个存储单元,可以通过地址来存取相应的存储单元。相邻存储单元的地址是连续的。存储器中所有存储单元的位数都是相同的。存储单元最重要特性就是它是最小的可编址单元。通常把 8 个二进制位称为一个字节,若干个字节再组合成字,一个字所包括的二进制位数称为字长。大多数计算机的指令对字操作,而存储器按字节编址。存储容量是指存储器所能容纳的二进制信息总量。通常存储容量用存储单元数与每个单元的位数(即存储位元个数)的乘积表示,或用字节数表示。即:存储容量=存储字数(存储单元数)×字长。常用的计量存储器空间的单位是 K、M和 G。存储器地址码的位数决定了主存的可直接寻址的最大空间。 -
存储器的速度
存取时间:取数时间是存储器接到读命令信号到其数据输出端有信号输出为止的时间,它取决于存储介质和访问机构的类型。写入时间是从存储器接到有效地址开始,到数据写入被选中单元为止所需的全部时间。存储周期:存储器进行一次完整的读写操作所需要的全部时间,也就是,连续两次访问存储器所需的最小时间间隔。
显然存储周期>存取时间,因为任何存储器由于读放、驱动源和存储体的连线都必须有一段稳定恢复时间,读出后不能立即进行访问。CPU 要根据取数时间确定启动一个访存请求后,必须等待多长时间才能取数据。
存储器带宽:是单位时间可写入存储器或从存储器取出信息的最大数量。存储器带宽的计量单位通常是位/秒或字节/秒。存储器带宽是衡量数据传输速率的重要技术指标。
提高存储器带宽的措施:缩短存取周期。增加存储字长,使每个存取周期可读写更多的二进制位数。增加存储体。
-
存储器的价格
存储器的价格常用每位的价格(位价)来衡量。它不仅包含了存储元件的价格,还包括为该存储器操作服务的外围电路的价格。简单系统中逻辑门的延迟较小,所以系统的复杂性越小,能够达到的工作速度就越高。尺寸小的系统中的信号在线路上的传输延迟较小,所以系统的尺寸越小,能够达到的工作速率越高。 -
存储器的可靠性
-
访问方式
-
信息存储的永久性
主存储器的工作原理
CPU 与存储器通过总线连接

-
在“读”存储器时,CPU 通过地址总线和控制总线分别给出所需字的存储器地址和访存“读”控制信号,然后等待存储器将读出的字送到数据总线上,并通知 CPU“读”操作完成,CPU 从数据总线上读取这个字,结束“读”存储器的工作。
-
在“写”存储器时,CPU 通过地址总线和数据总线分别给出欲写字的存储器地址和字的内容,CPU 还通过控制总线给出访存“写”控制信号,然后等待,存储器将数据总线上送来的字写入指定地址的存储单元,并通知 CPU“写”操作完成,CPU结束“写”存储器的工作。
-
计算机中的任何操作都是按照时间节拍有序进行的,由于各器件的操作都存在延时,为保证读/写的可靠性,应当在存储器的地址输入端和数据端分别安排一个寄存器,用来存放地址信号和数据信号,这两个寄存器分别称为存储器地址寄存器(MAR)和存储器缓冲寄存器(MBR) 或存储器数据寄存器(MDR)。
半导体存储芯片
-
采用超大规模集成电路工艺,在一个芯片内集成具有记忆功能的存储矩阵,译码驱动电路和读写电路。译码驱动能把地址线送来的地址信号翻译成对应存储单元的选择信号,该信号在读写电路的配合下完成对被选中单元的读写操作。读写电路包括读出放大器和写入电路,用来完成读写操作。
存储芯片通过地址总线、数据总线和控制总线与外部链接。地址线是单向输入的,其位数与芯片容量有关。数据线是双向的(可用成对出现的数据线分别作为输入或输出),其位数与芯片可读出或写入的数据位数有关。地址线和数据线的位数共同决定了芯片的容量。控制线主要有读写控制线(决定芯片进行读写操作)与片选线(选择存储芯片)两种。不同存储芯片的读写控制线和片选线可以不同。
-
半导体芯片的译码驱动方式
线选法:用一根字选择线(字线)直接选中一个存储单元的各位。结构简单,适用于容量不大的存储芯片。重合法:被选单元由X,Y两个方向的地址决定,选择存储单元中的一位。
随机读写存储器

随机读写存储器一般为半导体读写存储器。双极型的存储速度比 MOS 型的快,但 MOS 型的集成度高,故双极型 (TTL)半导体主要用于小容量的高速存储器,MOS 半导体主要用于大容量存储器。
静态 MOS 存储器(SRAM)
-
存储位元
存储位元是组成存储器的基础,每个存储位元能存储一位二进制信息“0”或者“1”。T1-T6组成了一个 SRAM 的存储位元。T1、T2 是工作管,T3、T4 是负载管,T1~T4 组成两个反向器,它们交叉耦合,组成一个触发器,T5、T6、T7、T8是门控管。

当该存储位元未被选中时,X、Y 地址译码线为低电平,T5-T8 截止,触发器和两条位线隔开。若 T1 截止,A 点高电位,T2导通,B 点低电位,B 点的低电位又使 T1 更加截止,这是一个稳定状态,此时,存储位元存储的信息是“1”;反之,T2 截止,B 点高电位,T1 导通, A 点低电位,A 点的低电位又使 T2 更加截止,此时,存储位元存储的信息是“0”。读操作时,X、Y 地址译码线上是高电位,选中该存储位元,T5-T8导通,A、B 两点分别与位线 D 与 D#相连,存储位元的信息被送到 I/O 和 I/O#线上。I/O 和 I/O#线接着一个差动放大器,从其电流方向,可以判断存储位元所存信息是“1”还是“0”。也可以只有一个输出端接到外部,看其有无电流通过,就可以判断所存信息是“1”还是“0”。
写操作时,X、Y 地址译码线上是高电位,选中该单元,T5-T8导通,A、B 两点分别与位线 D 与 D#相连。写“1”,则在 I/O 线上输入高电位,在 I/O#线上输入低电位,使 A 点变高电位,B 点变低电位,从而使 T1 截止 T2导通,存储位元中存入“1”;写“0”,则 在 I/O 线上输入低电位,在 I/O#线上输入高电位,使 A 点变低电位,B 点变高电位,从而使 T2 截止 T1 导通,存储位元中存入“0”。
只要不对 SRAM 断电,存放在里面的数据就一直保存着。SRAM 的速度很快,一般来说访问时间是几个纳秒,因此,SRAM 被广泛的用在第二级 Cache 中。
-
SRAM 存储器的组成
在静态存储器中,包括存储体、读写电路、地址译码电路和控制电路等部分,其中存储体是所有存储位元的集合;地址译码电路对访存时来自地址总线的内容译码,把用二进制代码表示的地址转换成输出端的高电位,驱动相应的读写电路,以便选择所要访问的存储单元。 -
地址译码方式有两种:线性译码方式和双向译码方式。
线性译码方式
每一行代表一个字,每一列对应于这个字的一个位。在这种方式中,地址译码器只有一个,译码器的输出叫字选线,字选线选择某个字(即某个存储单元)的所有位。线性译码方式适用于小容量的存储器。
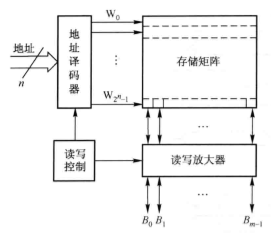
双向译码方式
双向译码方式适用于二维译码矩阵, 它将存储器的地址分为 X 和 Y 两段,分别用水平和垂直两个译码器译码,每个译码器各自输出若干条选择线,每个基本的存储位元位于 X 和 Y 选择线的交点,当两条选择线都处于有效电位 时,该存储位元被选中。整个存储器由若干个这样的集成片组成一个立体结构,每一片的 X 地址和 Y 地址相同的位组成存储器的一个字,双向译码方式适用于大容量的存储器。

线性译码方式的优点是结构简单,缺点是所用的选择线太多,而双向译码方式就可以很好地解决这个问题。一个 n 位地址的存储器,如果按照线性译码方式,那么共有 2n根选择线,若按照双向译码方式,则每个译码器只有 n/2 个地址输入,2n/2 个输出,于是整个存储器共有 2n/2+1 根选择线。
-
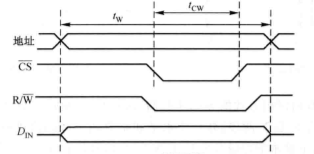
SRAM 的读/写过程
读:在整个读周期中,读信号始终有效,先加上需要访问的地址,并在读/写端加上有效信号,等信号稳定后,再加上片选信号,经过一段时间延时,数据被读到输出端的缓冲寄存器中,至此方可撤去片选信号,然后再撤去地址和其他控制信号。TR 是读操作所需的最小周期,在此周期内,地址不能改变;TA 是取数时间,定义为从地址线上的信号稳定到数据能从存储器读出所需的最短时间,显然小于读周期;TCO定义为从片选信号 CS#有效到数据能被读出所需的最短时间。

写:先加上地址和读/写信号,同时数据信号也加到数据总线上,等信号稳定后,再加上片选信号,经过一段时间延时,数据被写入存储器相应单元中,至此方可撤去片选信号,然后在撤去地址和其他控制信号。在有效数据出现前,RAM的数据线上存在着前一时刻的数据Dout,故在地址线发生变化后,CS#,R/W#需要滞后 taw再有效,以避免将无效数据写入到RAM错误。但写允许失效后,地址必须保持一段时间,称为写恢复时间。RAM数据线上的有效数据必须在CS#,R/W#失效前的tDW时刻出现,并延续一段时间,以保证数据可靠写入。TW是写操作所需的最小周期, TCW定义为片选信号 CS#必须有效的最短时间。
-
有些 RAM 的读/写过程与此不同:读操作先加上地址和片选信号(有的片选信号就是地址的一部分),再加读/写信号(读),经过一段时间延时,数据被读到输出端的缓冲寄存器中。写操作先加上地址和片选信号和数据信号,再加上读/写控制信号(写),经过一段时间延时,数据被写入存储器相应单元中。
计算机实际运行时,分配给读/写操作的周期应大于上述时间,以保证操作的正确执行。
动态 MOS 存储器(DRAM)
-
存储位元:当该存储位元未被选中时,字线为低电平,电容 C 上有电荷,则存储位元存储的信息是 “1”;反之,存储位元存储的信息是“0”。
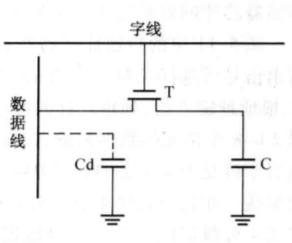
读操作时,字线上是高电位,选中该存储位元,T 导通。存储在电容 C 上的电荷通过 T 输 出到数据线上,通过读出放大器电路输出。电容上有电荷表示原来存的是“1”,无电荷表示原来存的是“0”。写操作时,字线上送高电位,T 管导通,写入信息由数据线存入电容 C。
由此可见,对 DRAM 存储位元的读操作就是对电容 C 的放电过程,是破坏性的读,因此,有必要在读完以后再把原来的数据写回存储位元,这个过程称为“再生”。
电容存在着漏电阻,因此电容中的电荷很快就会通过漏电阻放电而中和,为了长时间保存信息,就必须定时补充电荷,这就是所谓的 “刷新”。
其实刷新与再生是一回事,都是将电容上的信息重写一遍,只不过再生是配合读操作进行的,而刷新是定期对存储矩阵进行扫描,扫至哪一个位元,就将该存储位元读/写一次,所以刷新与再生的执行过程都是先读后写。
DRAM 集成度高、功耗低、成本低。现在的微型计算机中大都采用 DRAM 作为主存。除了单管结构外,还有三管、四管结构的 DRAM 存储位元, 其存储机理与单管结构的存储位元并无区别,只是读/写方式有些不同。总之,存储位元所用的晶体管越多,占用硅片面积越大,但外围电路就相对简单写;反之,矩阵简单,外围电路就相对复杂。
-
DRAM 存储器的组成

逻辑上, 存储器组织成 4 个 2048×2048 的方阵,可以采用各种物理排列。 22 位的存储器地址被分为两组,每组都从这 11 根地址线输入,第一次选择高 11 位地址(行地址),第二次选择低 11 位地址(列地址),这种方法称为时分复用。在时分复用的情况下,行地址选通信号(RAS#)和列地址选通信号(CAS#)为芯片提供时序控制信号。地址线的分时复用和方阵型行列结构,每增加一个专用的地址引脚,便使得行地址和列地址的指示范围加倍,因此存储器芯片的容量以 4 的倍数增长。 行译码器有 11 根地址输入线,输出 211=2048 根译码信号,每一根行译码输出信号可选择控制一行位元(共 2048 个,即连接到 2048 个位元的字线)。同样列译码器有 11 根地址输入线,列译码器输出 211=2048 根译码信号,每一根列译码信号连接控制某一列 2048 个电位元的数据的输入输出。只有被行、列译码信号同时选中的位元才被激活。由于存储器矩阵是由 4 个 2048×2048 模块组成,每个模块有一根数据线 i D 相连,4 个模块组成 4 位数据线。在每个模块中,行、列译码信号同时选中的位只可有一位,4 个模块则共有 4 位被选中,组成 4 位数据位。
在“写”存储器时,选中的位线根据相应的数据线值经放大器放大后写入位元中; “读” 存储器时,每一选中的位元值经读出放大器输出到数据线上。因为此 DRAM 只有 4 位位元参与读/写,因此,必须将多片 DRAM 连接到 DRAM 控制器上才能在总线上读写一个字。
刷新电路,每几个毫秒,DRAM 对所有存储位元刷新一次,防止数据丢失。
-
DRAM 的读/写过程

在读周期中,行地址选通信号 RAS#的下降沿时送行地址,列地址选通信号 CAS#的下降沿时送列地址,读/写控制信号 R/W#在列地址信号出现之前加入(R/W#=1),等到被行、列地址所选中单元的数据读出有效后,RAS#和 CAS#同时上升,此时将数据输出到 MDR。写周期与此类似, 同样是在 RAS#的下降沿时送行地址,在 CAS#的下降沿时送列地址,在列地址信号出现之前加入读/写控制信号 R/W#(R/W#=0),但在 R/W#的上升沿将 MDR 中的数据写进指定的单元。写入数据应在CAS#有效前的一段时间出现,他的保持时间应为CAS#有效后的一段时间,这是因为数据的写入实际上是有CAS#的下降沿激发而成的。即WE,CAS#有效均要大于数据Din有效的时间。
DRAM 的刷新
-
所有的 DRAM 都需要刷新操作,刷新过程需要外部电路的支持,所以 DRAM 的外部接口比 SRAM 的复杂。DRAM 采用“读出”方式进行刷新,从上一次刷新结束到下一次对整个 DRAM 全部刷新一遍为止,这一段时间间隔称为刷新周期。
-
简单的刷新操作是,当刷新所有存储位元时,DRAM 芯片并不进行实际的读写操作,刷新计数器产生行地址,刷新计数器的值被当作行地址输出到行译码器,并且激活 RAS#线,从而使得相应行的所有位元被刷新。 另一种刷新操作是利用 CAS#信号比 RAS#信号提前动作来实现刷新。这是因为在 DRAM 器件内部具有刷新地址计数器,每个刷新周期这个地址计数器自动加 1,故不需要外加的刷新地址计数器。
-
通常, DRAM 允许的单元刷新间隔时间是 2ms,其刷新电路的工作方式一般有三种。
-
集中式刷新

指在一个刷新周期中,利用一段固定的时间,依次对 DRAM 的所有行逐一刷新, 在刷新期间禁止读/写存储器,这段禁止读/写存储器的时间又称为访存“死区”。集中式刷新的缺点是在刷新期间,存储器处于禁止访问状态,“死区”时间过长,不利于系统并行设计。但是,集中式刷新的硬件电路简单、 设计处理容易。64K×1 位 DRAM 芯片中,存储电路由 4 个独立的 128×128 的存储矩阵组成。设存储器存储周期为 500ns,单元刷新间隔是 2ms。则每个刷新周期内可安排 4000 个周期,其中必须有 128 个周期用于刷新,其余 3872 个周期用于正常的访存操作。那么,访存“死区”时间为 128 ×500ns=64μ s,占整个刷新周期的 3.2%。
-
分散式刷新

在这种方式下,系统把对每一行的刷新分散到各个存储周期中。每个存储周期被分为两个阶段,前一阶段内进行正常的访存操作,后一阶段刷新某一行,则存储周期增长了一倍。分散刷新没有充分利用最大允许的刷新周期,延长了存储周期,缩短了刷新周期,从而降低 了计算机系统的运算速度。以 64K×1 位 DRAM 芯片为例,存储电路由 4 个独立 的 128×128 的存储矩阵组成。单元刷新间隔是 2ms,芯片存储周期仍为 500ns,那么存储器存储周期为 1μ s(=1000ns),刷新周期为 128μ s。在每个 2ms 内包含了 2000 个存储周期,存储矩阵中的每行在一个 2ms 内被刷新 10 次以上。
-
异步式刷新
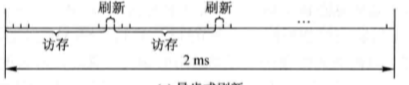
异步刷新采取折中的办法,在 2ms 内分散地把各行刷新一遍。这样就避免了分散式刷新中不必要的多次刷新,提高了整机速度。同时又解决了集中式刷新中“死区”时间过长的问题。以 64K×1 位 DRAM 芯片为例,存储电路由 4 个独立的 128×128 的存储矩阵组成。单元刷新间隔是 2ms,存储器存储周期是 500ns,则刷新信号的周期为 2ms/128=15.625μ s。刷新电路每隔 15.625μ s 产生一个刷新信号,刷新一行存储单元的内容。
-
在同样大小的芯片中,DRAM的集成度高与SRAM。DRAM行列地址按先后顺数输送,减少了芯片引脚,封装尺寸也减少。DRAM的功耗比SRAM小。DRAM比SRAM便宜。由于使用动态元件,DRAM的速度比SRAM慢。
只读存储器
-
只读存储器简称 ROM,它只能读出,不能写入,它的最大优点是具有非易失性,即撤去电源,数据照样存在。目前大量使用的是半导体 ROM 集成存储芯片。
-
掩膜式只读存储器(MROM)
掩膜式只读存储器中的内容是由生产过程中的一种掩膜工艺决定的,一旦生产完毕,信息就不能更改,以后只能读其内容而不能改写了。掩膜式只读存储器可靠性高,集成度高,价格便宜, 适合于程序成熟、批量生产的场合,用户可向厂家定做,生产批量一般都在 10 万片以上才较为合算。 -
可编程只读存储器(PROM)
可编程只读存储器 PROM 的内容是由用户在使用前一次性写入的,此后就只能读其内容而不能改写了。熔丝式 PROM,其内部是许多熔丝组成的阵列,熔丝的接通表示存“1”, 断开表示存“0”。在 PROM 产品出厂时,每个存储位的熔丝均接通,用户一次性写入,即 PROM 的编程原理就是在芯片的特定管脚上加上高电平,使选定的熔丝被烧断。熔丝被烧断后就不能再接通了。除了熔丝式 PROM 外,还有 PN 结击穿型 PROM。 目前,PROM 已基本被淘汰。 -
可多次编程序的只读存储器
光擦除可编程只读存储器(EPROM)芯片上有一个石英窗口,当紫外线照射该窗口达到 15 分钟时,EPROM 里的内容就被全部擦除了。电擦除可编程只读存储器(E2PROM) 可以在电路板上用电直接擦除,不必从电路板上取下来,而且速度比 EPROM 快。E2PROM 改写的次数是有限的,一般为 10 万次。其读写操作可按每个位或字节进行,类似 SRAM,但每字节的写入周期要几毫秒,比 SRAM 长得多。这两类器件编程时都是用电和写入软件将新数据写入。
-
闪述存储器(Flash Memory)
闪存是近年在EPROM和E2PROM基础上发展起来的另一种快速的非易失性存储器, 它既有 E2PROM 写入方便的优点,又有 EPROM 的高集成性。和 EPROM 一样的是它用单管存储一位信息,和 E2PROM 一样的是它采用电擦除方式,可以按块擦除和重写,且闪存的擦除也不需要从电路中拿下来。E2PROM 的擦除是逐点进行的,就是说在对每一点编程时先将该点擦除然后烧写; Flash 工艺的 ROM 则是一次性擦除的,因此其编程速度比普通的 E2PROM 快。现在所用的各类常见主板和一部分显示适配器(显卡)都是采用 Flash ROM 作为 BIOS 芯片,现在的许多掌上计算机和移动电话中也大量采用了这种 Flash ROM 作为主存储器。
主存储器与 CPU 的连接
现代微型计算机(PC)的主存储器基本包括两个部分
- ROM,又叫非易失性存储器。其内部存放的是生产厂家烧写的固定指令和数据,这类指令和数据是对计算机进行初始化的低级操作和控制程序(即 BIOS 程序),使计算机能开机运行。在一般情况下 ROM 内的程序是固化的,不能改写,只能从中读出信息,但是现在的许多微型计算机中的 ROM 采用了快速的闪存(Flash Memory)来制造,从而可以用一些特殊的程序改写 ROM,对计算机 BIOS 进行升级。
- RAM。主存的绝大部分是由 RAM 构成的,因此 RAM 对主存的性能起着决定性的因素RAM 又被称为易失性存储器。CPU 现场操作的大部分二进制信息都是存放在 RAM 中的。
存储器芯片介绍
因其不同的工作原理,不同存储器芯片封装的引脚类型不同。
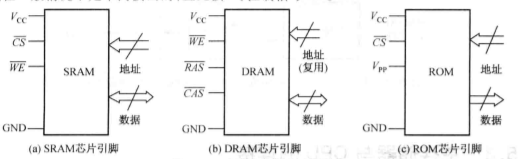
典型的 SRAM 芯片引脚,除工作电压 VCC和接地 GND 外,一般还有地址线、双向数据线和片选 CS#及输出使能 OE#。
DRAM 芯片容量普遍比 SRAM 芯片容量大得多,除与 SRAM 相同的芯片引脚外,DRAM 还有行地址选通信号 RAS#和列地址选通信号 CAS#引脚。
各种 ROM 芯片的引脚类型比较类似,不同的是,ROM 芯片除工作电源 VCC外,还有程序电压 VPP引脚,其数据线在一般情况下是单向读出的。
为了与主存储器连接, CPU芯片提供的相关引脚一般有:地址线、数据线、访存控制信号 MREQ#和 R/W#等信号。
存储容量的扩展
-
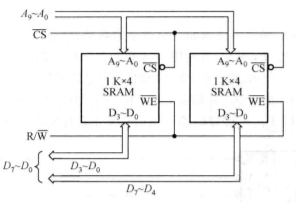
位扩展
位扩展的目的是增加同一个地址的存储单元的位数。位扩展的操作是:将参加位扩展的存储芯片的 CS#、 WE#和地址线分别连在一起,不同存储芯片的数据端分别引出。其中一片的数据线作为高位, 另一片的数据线作为低位。
-
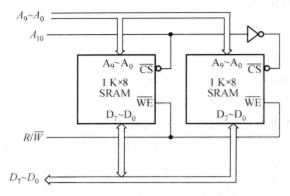
字扩展
字扩展指增加存储器中字的数量,即容量扩展。字扩展的结果是两个 SRAM 芯片作为一个整体顺序编址,而存储器的字长与SRAM 芯片字长一样。字扩展的操作是:将参加字扩展的存储芯片的数据线、读写控制信号 WE#和地址线分别连在一起,由片选信号来区分各芯片的地址范围,从而选择对不同的存储芯片进行读写操作。
-
字位扩展
字位扩展指按字扩展的方法增加存储器字的数量,同时按位扩展的方法增加存储字长。一个存储器的容量假定为 M×N 位,若使用 t×k 位的芯片(t<M,k<N),则一共需要(M/t) ×( N/k) 个存储器芯片。

主存储器与 CPU 的连接
- 根据 CPU 芯片提供的地址线数目,确定 CPU 访存的地址范围,并写出相应的二进制地址码;
- 根据地址范围的容量,确定各种类型存储器芯片的数目和扩展方法;
- 分配 CPU 地址线。CPU芯片提供的地址线数目是一定的,且大于每一个存储芯片提供的地址线数量。对每一个存储芯片,CPU地址线的低若干位直接连接存储芯片的地址线,这些地址线的数量刚好等于存储芯片提供的地址线数量。剩下的CPU高若干位地址线(对于不同存储芯片而言,其数量是不同的)皆参与形成存储芯片的片选信号;
- CPU的数据线与存储芯片的数据线不一定相等,因此,必须对存储芯片扩位,使其数据位数与CPU的数据线数相等。
- CPU读写命令线一般可直接与存储芯片的读写控制端相连,通常高电平为读,低电平为写。有些CPU的读写命令线是分开的,此时CPU的读命令线应与存储芯片的允许读控制端相连,CPU的读命令线应与存储芯片的允许读控制端相连,CPU的写命令线应与存储芯片的允许写控制端相连。
- 片选线的连接是CPU与存储芯片正确工作的关键。存储器由许多存储芯片组成,那一片被选中完全按取决于该存储芯片的片选控制端CS#是否能够接受到来自CPU的片选有效信号。片选有效信号与CPU的访问控制信号MREQ#有关,因为只有当CPU要求访存时,才需要选择存储芯片。
高速存储器
- 提高存储器速度有以下几种有效途径:主存采用更高速的技术来缩短存储器的读出时间,或加长存储器的字长,使 CPU 一次可存取的数据宽度加长; 采用并行操作的多端口存储器; 在 CPU和主存之间加入一个高速缓冲存储器(Cache),以缩短读出时间;
在每个存储器周期中存取几个字。
双端口存储器
-
双端口存储器指同一个存储器具有两组相互独立的读写控制线路,允许两个独立的 CPU 或控制器同时异步地访问存储单元,是一种高速工作的存储器。
-
双端口 RAM 是一种常用的双端口存储器,其最大的特点是存储数据共享。

2K×16 位的 SRAM ,提供了两个相互独立的端口,即左端口和右端口。它们分别具有各自的地址线、数据线和控制线,可以对存储器中任何位置上的数据进行独立的存取操作。 当左端口和右端口的地址不相同时,在两个端口上同时进行读写操作,不会发生冲突。当任一端口被选中驱动时,就可对整个存储器进行读写,每一个端口都有自己的片选控制信号和输出使能控制信号。若左、右端口同时访问相同的存储单元,则会发生读写冲突,忙信号 BUSY#的设置解决了此问题。这时,判断逻辑决定对哪个端口优先进行读写操作,而暂时关闭另一个被延迟的端口(通过置 BUSY#=0 来实现)。读写操作对 BUSY#=0 的端口无效,直到优先端口完成读写操作后, 被延迟端口的 BUSY#复位,被延迟端口才开放,允许进行读写操作。FIFO(先进先出的存储器)则是另一种常用的双端口存储器,其内部存储器均采用双端口 RAM,但是,FIFO 只允许两个端口一个写,一个读,因此 FIFO 是一种半共享式存储器。在双机系统中,只允许一个 CPU往 FIFO 写数据,另一个 CPU从 FIFO 读数据。
多体交叉存储器
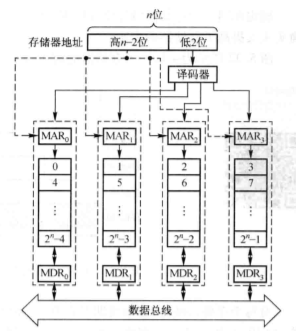
- 多体交叉存储器可以在不改变每个存储体存取周期的情况下,提高存储器的带宽。
- 多体交叉结构的主存由 M 个一字宽的存储体(或称存储模块)组成,每个存储体有相同的容量和存取速度,又有各自独立的地址寄存器、地址译码器、读写电路和驱动电路。
- 由于每个存储体都是一字宽,因而总线的宽度是一字宽,只要送到各存储体的 M 个地址不发生冲突(任何两个地址不同属于一个存储体),M 个存储体就可以同时读出 M 个字。CPU 同时访问 M 个存储体,由存储器控制部件控制它们分时使用数据总线进行信息传递。(同时读出,分时传送)
- 多体交叉存储器的编址方法是这样的:CPU 给出的存储器地址的低 x 位(2x=M),译码选择 M 个不同的存储体,剩下的高若干位则是存储字在存储体内的相对地址。连续的存储器字地址分布在相邻的不同存储体内,同一个存储体内的地址都是不连续的。
- 每个存储体的字长都等于数据总线宽度,存储体存取一个字的存储周期为 T,总线传送周期为 τ,存储器的交叉存储体数为 M,为了实现流水线方式存取,应当满足 T=Mτ ,T/τ 称为交叉存取度,**当交叉存储体数大于或等于 T/τ 时,可以保证启动某模块后经 Mτ 时间再次启动该模块时,它的上次存取操作已经完成。**这样,连续读取 M 个字所需的时间为 t=T+(M-1)τ ,相比在同一个存储体内连续读取 M 个字所需的时间来说,采用多体交叉存储器的组织方式大大提高了存储器的带宽。对每个存储体而言,存取周期没有缩短。宏观上,在一个存取周期内,存储器向 CPU提供了 4 个存储字。
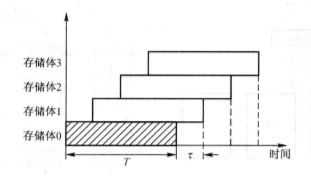
- 排队器:为了防止两个以上的请求源同时请求访问同一个存储体,并防止将代码错送到另一个请求源等各种错误的发生,在控存内设置一个排队器来确定请求源的优先级别:对已发生代码丢失的请求源应列为最高优先级,对严重影响CPU工作的请求源给予次高优先级。
- 控存标记触发器用来接受排队器的输出信号,一旦相应某请求源的请求,其被置为1,以便启动节拍发生器工作。
- 节拍发生器产生固定节拍,与机器主脉冲同步,使控制线路按一定时序发出信号。
- 控制线路将排队器给出的信号与节拍发生器提供的节拍信号配合,向存储器各部件发出各种控制信号,实现对总线的控制及完成存储器的读写操作,并向请求源发出回答信号,表示存储器已经响应请求。
相联存储器
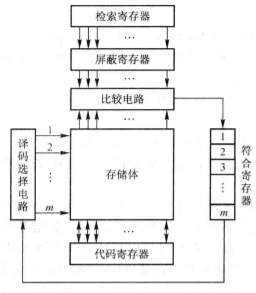
-
相联存储器是一种随机存取类的存储器。在相联存储器中,一个字是通过它的部分内容而不是它的地址进行检索的。相联存储器的检索是对一个字中某些指定位进行检查比较,看是否与特定的样式相匹配,若匹配,则检索成功,否则检索不成功。这种比较能在所有字中同时进行,这使得相联存储器如同普通的随机存储器一样,检索时间是固定的,不依赖于存储位置或前面的存取样式。
-
如果按顺序查找,在按地址访问的存储器中寻访一个字的平均操作是 m/2 次(m 是存储器的字数总和),而在相联存储器中仅需要一次检索操作,因此大大提高了处理速度。
-
相联存储器主要用于虚拟存储器中存放段表、页表和快表,在高速缓存中存放 Cache 行地址,以及在数据库与知识库中按关键字检索。
-
存储器采用高速半导体存储器组成。检索寄存器用来存放检索字,检索寄存器的位数和相联存储器的存储字的位数相等,每次检索时,取检索寄存器中若干位为检索项。屏蔽寄存器用来存放屏蔽码,屏蔽一些不用选择查找的字段,屏蔽寄存器的位数和检索寄存器的位数相同。符合寄存器用来存放查询比较的结果,其位数等于相联存储器的地址数,每一位对应一个存储字,位的序数就是相联存储器的地址。比较电路用于将检索项 、和存储器中所有单元内容的相应位进行比较,如果符合就将符合寄存器的相应位置“1”,否则置“0”。代码寄存器用来存放存储体中读出的代码,或存放向存储体中写入的代码。
相联存储器通过关键字寻访存储器,所谓关键字就是用于寻址存储器的字段,于是,存放在存储器中的字可以看成具有下列格式: KEY DATA ,其中,KEY 是关键字,DATA 是被读写的信息。
高性能的存储芯片
- SDRAM(同步DRAM)能在系统时钟的控制下进行数据的读出和写入,CPU给出的地址和控制信号会被SDRAM锁存,直到指定的时钟周期数后再响应。此时CPU可以执行其他任务而无需等待。支持猝发式访问模式,即CPU发出一个地址就可以连续访问一个数据块。
- RDRAM(RambusDRAM)采用专门的DRAM和高性能的芯片接口取代现有的存储器接口。主要解决存储器带宽的问题,通过高速总线获得存储器请求(包括地址,操作类型和字节数),总线最多可寻址320块RDRAM芯片,传输速率可达1.6GBps。不像传统的DRAM采用RAS#,CAS#和WE#信号来控制,而是采用异步的,面向块的传输协议传送地址信息和数据信息。一个RDRAM芯片就像一个存储系统,通过一种新的互连电路将各个芯片连接成一个环,数据通信在主存控制器的控制下进行,数据交换以包为单位。
- 带cache的DRAM(CDRAM),又称为增强型的DRAM(EDRAM)。首先在行选通信号的作用下,将高位地址经地址线输入,分别保存在行地址锁存器中和最后读出行地址锁存器中,由此指定的全部数据被读到SRAM中暂存,然后在列选通信号的作用下,将列地址输入,保存到地址锁存器中。在读命令有效时,读出数据。下次读数据时输入的行地址立即与最后读出行锁存器的内容比较,相同则说明数据在SRAM中,在输入列地址,读出数据,否则驱动DRAM阵列更新SRAM,再读数据。
高速缓冲存储器 Cache
-
程序局部性原理认为,在一个较短的时间间隔 内,程序访问的地址往往集中在一个不大的范围内。时间局部性说的是,若某个地址被访问,则在不久的将来仍有可能被访问。空间局部性说的是若某个地址被访问,则这个地址周围的单元也很可能被访问。
-
所以根据程序局部性原理,把 Cache 介于 CPU 和主存之间,Cache中存储频繁使用的指令和数据。这样,访存操作的平均速度就提高了。Cache 不是主存容量的扩充,它保存的内容是主存中某些单元的副本。
Cache 的基本原理
-
CPU 与 Cache 之间的数据交换以字为单位,而 Cache 与主存之间的数据交换以字块为单位。一个块由若干字组成,是定长的,在 Cache 中数据块大小称为行,在主存中数据块大小称为块,行与块是等长的。
-
Cache 除了包含存储体外,还包含控制逻辑。若 Cache 在 CPU 芯片外,它的控制逻辑一般与主存控制逻辑合在一起,称为主存/Cache 控制器;若 Cache 在 CPU内,则由 CPU提供它的控制逻辑。Cache 及其控制逻辑完全由硬件实现。
-
分配给 Cache 的地址存放在一个相联存储器中,当 CPU提供字地址时,相联存储器按内容进行查找,从而判定 Cache 是否“命中”。此外,从结构上讲, Cache 还应该包含标记、行数据有效位、替换位等部分,这些内容在不同计算机系统中不尽相同, 其设计与具体的 Cache 案例有关。
-
计算机系统中有了 Cache 以后, CPU访存读一个字时,首先 Cache 控制逻辑根据地址判断这个字是否在 Cache 中,若在,就立即送给 CPU,称为 Cache “读命中”;否则,称为 Cache “读不命中”,通常有两种方法解决 Cache 的“读不命中”情况:其一,将主存中该字所在的数据块复制到 Cache 中,然后再把这个字传送给 CPU;其二,启动常规的主存读周期,把此字从主存读出送到 CPU,与此同时,把包含这个字的数据块从主存中读出送到 Cache 中。两种方法中,都有可能发生 Cache 中行数据的替换,即当 Cache 已没有空闲的位置容纳即将装入的新行时,只能按照某种替换算法选择某一旧行被新行替换掉。

-
Cache 的命中率
在所有的存储器访问中由 Cache 满足 CPU需要的部分应占很高的比例, 即 Cache 的命中率应接近于 1。在一个程序执行期间,设 Nc表示 Cache 完成存取的总次数, Nm表示主存完成存取的总次数, h 定义为命中率,命中率指 CPU访问主存数据时,命中 Cache 的次数占全部访问次数的比率; 反之,失效率就指 CPU访问主存数据时,不命中 Cache 的次数,占全部访问次数的比率。命中率h=Nc/(Nc+Nm)*100%。若 tc表示命中时 Cache 的访问时间,tm表示 Cache 不命中时主存的访问时间,则 Cache/主存系统的平均访问时间ta为: ta=h·tc+(1-h)tm或ta=h·tc+(1-h)(tm+tc)。我们追求的目标是,以较小的硬件代价使 Cache/主存系统的平均访问时间 ta越接近 tc越好。 设 r=tm/tc表示主存慢于 Cache 的倍率,e 表示访问效率,则有: e=tc/ta=tc/(h·tc+(1-h)tm)=1/(h+(1-h)r)=1/(r+(1-r)h)。由上述公式看出,为提高访问效率,命中率 h 越接近 1 越好,r 值以 5—10 为宜,不宜太大。命中率 h 与程序的行为、Cache 的容量、组织方式、块的大小有关。
-
一般而言,cache容量越大,其CPU命中率就越高,当cache容量达到一定值时,命中率不会因容量的增大而有明显的提高。
-
块长与命中率之间的关系取决于程序的局部特性,当块由小到大增长时,起初会因为局部性原理使命中率有所提高,当倘若继续增大块长,命中率可能下降,因为所装入缓存的有用数据反而少于被替换掉的有用数据。由于块长增大,导致缓存中块数的减少,命中率下降。
-
cache的基本结构

地址映射变换机构:将CPU送来的主存地址转换为cache地址。主要是主存块号与cache块号的转换。若建立了对应关系,则CPU可以直接访问cache存储体。否则分为cache已满和cache未满的情况。
主存与 Cache 的地址映射方式
-
为了把主存块放到 Cache 中,必须应用某种方法把主存地址定位到 Cache 中,称为地址映射。主存地址与 Cache 地址间存在着对应关系,这个关系称为映射函数。地址映射完全由硬件实现,变换过程很快,软件人员未感觉到 Cache 的存在,这种特性称为 Cache 的透明性。 设i表示主存块号, j表示Cache行号, 主存容量为2m块, Cache容量为2c行, 每个字块中含 2b 个字。
-
直接映射
直接映射是一种多对一的映射关系,主存的一块只能拷贝到 Cache 的一个特定行位置上去。 在直接映射方式下,Cache 的行号 j 和主存的块号 i 有如下函数关系j=i mod 2c 。按照这个映射关系,主存地址被划分成块内地址、字块地址和高位标记三部分。

根据 Cache 的行数将主存分为若干大组,每个大组包 含 2c个数据块,每个大组中地址偏移量相同的数据块,映射到 Cache 中的同一行,该 Cache 行地址等于偏移量的值。由此可知,每个 Cache 行最多有 2m-c个主存字块可能映射过来,所以, Cache 的标记只需 m-c 位即可指明该 Cache行对应的主存块来源,即数据块在主存中所处的大组的组号。直接映射方式下,CPU 访存的过程描述:CPU 给出一个字的 m+b 位主存地址,Cache 控制逻辑将中间的 c 位地址取出,作为 Cache 的行地址,通过访问存放 Cache 行地址的相联存储器, 取出标记字。将取出的标记与主存的高 t=m-c位相比较,若符合且行数据有效,则命中;否则是不命中。
直接映像的缺点是机制不灵活,Cache 命中率低。
-
全相联映射
全相联映射中,主存地址被划分成块内地址和高位标记两部分。将主存中一个块的地址(块号)与块的内容(字)一起存入 Cache 行中。其中块地址存于 Cache 的标记部分。这种带全部块地址一起保存的方法,可使主存的一个块直接拷贝到 Cache 中的任意一行上。

CPU给出了一个字 m+b位的主存地址,为了快速检索,主存地址中 m 位的块号与 Cache 中所有行的标记同时在比较器中进行比较。如果块号命中,则按字地址从 Cache 中读取一个字;否则,Cache 不命中。全相联映像的优点是机制灵活,命中率高。缺点是硬件开销大,要进行 2c 路比较,通常采用相联存储器来实现。在全相联映射中,调入 Cache 的行采用高速 SRAM 存储器存储,按地址访问,而记录对应行的主存高位标记部分采用相联存储器来实现,这样可以按所查找的内容快速查找主存地址所对应的块是否存在于 Cache 中。
全相联映射方式的主要缺点是比较器电路难于设计和实现,因此只适合于小容量的 Cache。
-
组相联映射
组相联方式将 Cache 的行分成 2c-r组,每组 2r行。主存的字块存放到 Cache 中的哪个组是固定的, 至于映射到该组哪一行是灵活的。 即有如下函数关系: j=(i mod 2c-r)*2r+k,其中 0≤k≤2^r -1^。

按照 Cache 的组数将主存分为若干大组,每个大组包含 2c-r个数据块,每个大组中偏移量相同的数据块,映射到 Cache 中的同一组, 该Cache组地址等于偏移量的值。由于每一个Cache组都包含2r行,数据块应该复制到该Cache组中的哪一行,则遵循全相联映射方式。主存地址中的低 b 位对应块内地址,中间 c-r 位对应 Cache 的组地址,高 m-c+r 位对应 Cache 行的标志。当 CPU 给定一个主存地址时,首先用中间的 c-r 位找到 Cache 的相应组,然后将高 m-c+r 位与该组 2r行中的所有标记同时进行比较。哪行的标记与之相符,哪行命中。此后再以主存地址的低 b 位检索此行中的字,完成所要求的存取操作。如果此组没有一行的标记与之相符, 即 Cache 不命中。组相联映像的优点是大大增加了映射的灵活性,主存中一块可映射到 Cache 的 2r块,提高了命中率。每次比较只是进行 2r路比较,r 较小时,硬件开销不是很大。组相联映像通常采用 2 路、4 路和 8 路比较,即取 r=1,r=2,r=3。
替换算法
当新的一块数据需要装入 Cache 时,原来存储的一个 Cache 行必须被替换。对于直接映射, 某个特定的块只可能有一个相对应的行,因此,不需要对将被替换的 Cache 行进行选择。
- 随机替换算法
在发生替换时,该算法随机挑选一个候选的 Cache 行来进行替换,而与使用情况无关,其结果往往导致 Cache 的命中率很差。但是,统计表明,与 Cache 的其他替换算法相比较,随机替换只在性能上稍逊于其他基于 Cache 行使用情况的算法。 - 先进先出算法(FIFO)
在发生替换时,该算法把最先调入的那一个 Cache 行替换出去。FIFO 算法用循环或环行缓冲技术很容易实现,是一般来说,采用先进先出算法也不能得到很高的 Cache 命中率。 开销小,易实现。 - 最近最少使用算法(LRU)
该算法统计哪一个Cache行是近段时间使用次数最少的Cache行,需替换时就将它替换出去。 采用该替换算法能得到较高的 Cache 命中率。 可以通过为每个 Cache 行设置一个计数器来实现 LRU 替换算法,Cache 每命中一次,命中行的计数器被清零,其他行的计数器加 1,需要替换时,就将计数器值最大的行替换出去。
写策略
- 写贯穿策略(Write Through)
最简单的的写策略,其定义如下:当 CPU 写 Cache 命中时,所有写操作既对 Cache 也对主存进行;当 CPU 写 Cache 不命中时,直接写主存,然后有两种做法: 其一,不将该数据所在的块拷贝到 Cache 行,称为 WTNWA 法;其二,将该数据所在块拷贝到 Cache 的某行,称为 WTWA 法。 写贯穿策略保证了主存数据总是有效。在多处理器系统中,任何其他的 CPU-Cache 模块监视对主存的访问,以保证自己的 Cache 和主存的一致性,从而产生了大量的存储信息量,可能引起瓶颈问题。增加了访存次数,读操作不涉及对主存的写操作,写操作的时间就是访问主存的时间。相对于写回策略,写贯穿策略中,只要写入 Cache,就要对主存写操作,使 Cache 不能在 CPU和主存之间起到写方面的高速缓存作用,就降低了 Cache 的功效。 - 写回策略(Write Back)
当 CPU写 Cache 命中时,写操作只是对 Cache 进行, 而不修改主存的相应内容,仅当此 Cache行被换出时,相应的主存内容才被修改;当 CPU写 Cache 不命中时,先将该数据所在块拷贝到 Cache 的某行,余下操作Cache 写命中时相同。 写操作的时间就是访问cache的时间,可以减少主存的写操作次数,但在读操作cache失效时要发生数据替换,引起被替换块写回主存的操作。为了区别 Cache 行是否被改写过,应为每个 Cache 行设置一个修改位,CPU 修改 Cache 行时,标记其修改位,当此 Cache 行被换出时,判别此 Cache 行的修改位,从而决定是否将 Cache 行数据写回主存相应单元。减少了对主存写的次数,使 Cache 在 CPU 和主存之间读/写两方面都起到了高速缓存的作用,但是其控制相对复杂,最大的弊端就是存在导致 Cache 和主存数据不一致的隐患。 - 当 CPU 访存写一个字时,Cache 控制逻辑根据地址判断这个字是否在 Cache 中,若不在, 称为 Cache“写不命中”,此时,直接将该字写入主存中,且不再调入 Cache;否则,称为 Cache “写命中”,
Cache 的多层次设计
-
第一,容量问题。Cache 容量越大、性能越好,价格也越高;
第二,Cache 中行的大小问题。设置合适大小的行,能使 CPU 的效率提高很多;
第三,如何组织 Cache 的问题。采取哪种地址映射方式、哪种替换策略,使 Cache 中的字和主存中的字相对应, 以及保持 Cache 一致性的问题;
第四,指令和数据共用同一个 Cache 还是分享不同 Cache 的问题。共用同一个 Cache 的设计简单,但是效率相对较低,用不同的 Cache 分别存放指令和数据是当前 Cache 发展的趋势;
第五,Cache 的层次问题。近年来,CPU芯片的特点之一是把 Cache 做到片内,片外同一封装内还有容量大一些的二级 Cache,甚至在封装之外可能还有第三级 Cache。 -
单级 Cache 与两级 Cache
由于集成度的提高,当今的计算机系统已经实现了将 Cache 置于处理器芯片以内,这样的 Cache 被称为片内 Cache,而位于处理器芯片以外的 Cache 被称为片外 Cache,由比主存动态RAM和ROM存取速度更快的静态RAM组成,片外 Cache 通过外部总线与 CPU连接。片内 Cache 因为减少了 CPU在外部总线上的活动,所以加快了执行时间。 CPU内部的数据路径较短,存取片内 Cache 甚至比零等待状态的总线周期还要快, 在这段时间内,总线空闲,可用于其他传送。通常,对于片内 Cache 而言,仍需要一个位于片外的 Cache 配合其工作,片外 Cache 由 SRAM 组成,片内 Cache(L1 Cache)和片外 Cache(L2 Cache)构成了两级 Cache。两级 Cache 必须包含 L2 Cache,原因是: 如果没有 L2 Cache,CPU要求访问一个不在 L1 Cache 的存储单元时,CPU必须通过总线访问主存。总线速度和访存时间通常较慢,这就导致了低性能。如果使用了 L2 Cache,则经常丢失的信息可以很快被取来。如果 SRAM 快得与总线速度匹配,则数据能够用零等待状态存取。L2 Cache 的内容是主存的子集,L1 Cache 的内容又是 L2 Cache 的子集。L2 Cache 负责整个系统中 Cache 和主存的一致性,L1 Cache 负责响应 L2 Cache,与 L2 Cache 一起维护 L1 和 L2 两级 Cache 的一致性。从而保证了 L1、L2 两级 Cache 和主存的一致性。
-
统一 Cache 和分离 Cache
传统的 Cache 是指令与数据混放的,近年来,通常把 Cache 分离为两个部分:指令 Cache 和数据 Cache,分别存放指令和数据。 统一 Cache 的优点在于:对于给定的 Cache 容量,有比分离 Cache 更高的命中率。因为它会在获取指令和数据的负载之间进行自动平衡。只需设计和实现一个 Cache。分离 Cache 仍然是 Cache 结构发展的趋势,特别适用于超标量流水线中。与主存结构有关,若主存是统一的,则cache是统一的,否则是分立的。
与机器对指令执行的控制方式有关,当采用超前控制(在当前指令执行过程尚未结束时就提前将下一条准备执行的指令取出)或流水线控制时,一般采用分离缓存。超前控制和流水线控制特别强调指令的预取和指令的并行执行,因此必须将指令和数据分开,否则可能出现取指令和取数据对缓存的争用。通常处理器会提前取指令,并把要执行的指令装入缓冲器或流水线,指令与数据混放的 Cache 在执行单元和指令预取器同时发出访问请求时,发生阻塞,Cache 只能先为执行单元服务,使它能完成当前的指令,这样的竞争降低了系统性能, 干扰了指令流水线的有效使用,而指令与数据分离的 Cache 则解决了这一问题。
-
Cache 一致性问题
当代多处理器系统中,通常每个处理器都有一或两级 Cache。因此也产生了 Cache 的一致性问题。同一数据的多个副本能同时存在于不同的 Cache 中,若允许处理器自由地修改它们自己的副本,就会导致存储器的不一致。 解决 Cache 一致性的方法通常可分为软件方法和硬件方法,也有两者结合的方法。其中,硬件解决方法分成两大类:目录协议和监听协议。监听协议有两种基本的方法:写-无效和写-更新。写-无效协议的定义是:系统任一时刻可有多个读者,但是只有一个写者。一个数据可能因为读而被几个 Cache 共享。当某个 Cache 要对该行写时,先发布通知,使其他 Cache 中此行无效, 使此行成为写 Cache 专有。一旦行变为专有,拥有者处理器就可以进行本地写操作,直到其他处理器要求访问此行为止。
写-无效协议又被称为 MESI 协议, MESI 协议是目前使用最广泛的解决 Cache 一致性问题的方法。在 MESI 协议中,数据 Cache 的每个标记包括两个状态位,每行都处于修改(Modified)、专有(Exclusive)、共享(Shared)和无效(Invalid)四种状态中的一种。 修改状态的定义是:此 Cache 行已被修改(不同于主存)并仅在这个 Cache 可用。 专有状态的定义是:此 Cache 行同于主存但不出现于任何其他 Cache 中。 共享状态的定义是:此 Cache 同于主存并可出现于另外的 Cache 中。 无效状态的定义是:此 Cache 行不含有效数据。
当一个局部 Cache 读不命中时,处理器启动存储器读,以读取包含有此不命中地址的主存行。 处理器在总线上发布一个信号,通知所有其他处理器/Cache 单元监听此事务。 当前 Cache 行读命中时,处理器简单地读取所需数据项,状态没有任何改变。
局部 Cache 出现写不命中时,处理器启动存储器读,来读取含有此不命中地址的主存行。为了写修改的目的,处理器在总线上发出一个“读用于修改”信号。当此行装入后,它立即标志为修改态并进行写修改。 当局部 Cache 写命中时,以后的操作取决于 Cache 行的当前状态:若是共享状态,则完成写修改之前,处理器必须先得到此行的专有权。处理器在总线上发布写命中信号,Cache 中含有此行共享副本的各处理器将各自的 Cache 行状态由共享变成无效。然后,启动处理器完成写修改, 并将它的行副本状态由共享转换成修改态。 若是专有状态,则处理器已有对此行的排他性控制,故它只需简单地完成写修改,并将此行的状态转换成修改即可。 若是修改状态,则处理器已有对此行的排他性控制,故它只需简单地完成写修改即可。
外存储器
从存储系统中各层次的分工角度看,外存在功能上是内存的后备和补充,所以又称为辅助存储器。 外存成本低、容量大,具备非易失性,在掉电甚至脱机后能长期保存信息。
磁盘存储器
-
磁盘存储器的优点是:存储容量大,位价格低;存储介质可以重复使用;记录信息可以长期保存而不丢失,甚至可以脱机存档。 磁盘存储器包括硬磁盘和软磁盘。
-
磁表面存储器的技术指标
记录密度:单位长度内所存储的二进制信息量。磁盘沿半径方向单位长度的磁道数称为道密度,单位是tpi(道每英寸),磁道与磁道之间需要保持一定的距离,相邻两磁道中心线之间的距离称为道距,道密度为道距的倒数。单位长度磁道能记录二进制信息的位数称为位密度或线密度,单位为bpi(位每英寸),磁带存储器主要用位密度来衡量。在磁盘各磁道上所记录的信息量是相同的,而位密度不同,一般指最大位密度。存储容量:所能存储的二进制信息的总数量。非格式化容量是磁表面可以利用的磁化单位总数。格式化容量是指按某种特定的记录格式所能存储信息的总量,一般为非格式化容量的60%-70%。
平均寻址时间:寻道时间,旋转延迟。硬磁盘的平均寻址时间比软磁盘的平均寻址时间短。磁带的寻址时间是指磁带空转到磁头应访问的记录区段所在位置的时间。
数据传输率:单位时间内磁表面存储器向主存传送数据的位数,与记录的密度和记录介质的运动速度有关。辅存和主机的接口逻辑应有足够快的传送速度,来完成接收发送信息。
误码率:衡量出错概率的参数,为出错位数和读出信息位数之比。
-
记录原理:通过磁头和记录介质的相对运动完成读写操作。


-
磁表面存储器的记录方式



-
评价记录方式的主要指标


硬磁盘
-
硬磁盘存储器的盘片是由硬质铝合金材料制成的,其表面涂有一层可被磁化的硬磁特性材料。
-
根据磁头的工作方式
固定磁头型磁盘存储器:其磁头位置固定不动,磁盘上的每一个磁道都对应一个磁头,盘片也可不更换。省去了磁头沿盘片径向运动所需寻找磁道的时间,存取速度快,只要磁头进入工作状态即可进行读写操作。
移动磁头型磁盘存储器:在存取数据时磁头在盘面上做径向运动。这类存储器可以由一个盘片组成,也可有多个盘片装在一个同心主轴上,每个记录面各有一个磁头。所有磁头连成一体,固定在一个支架上可以移动,任何时刻各磁头都位于距圆心相等距离的磁道上,这组磁道称为一个柱面。
按磁盘是否具有可换性
可换盘磁盘存储器:盘片可以脱机保存,可以在互为兼容的磁盘存储器之间交换数据,便于扩大存储容量,可以只换单片,也可以将整个磁盘组换下。固定盘磁盘存储器。
移动磁头型硬盘存储器应用很广,其典型结构为温彻斯特硬磁盘,简称温盘。是一种可移动磁头固定盘片的磁盘存储器,温盘的磁头与盘面不接触,且随气流浮动,因此使用寿命较长。温彻斯特硬磁盘把磁头、盘片、小车、导轨以及主轴等制作成一个整体,以利于密封,安装和拆卸。温盘的优点是防尘性能好,可靠性高,对使用环境要求不高。
-
硬磁盘存储器的结构:磁盘存储器主要由记录介质(盘片),磁盘控制器,磁盘驱动器三大部分组成。
磁盘驱动器:主机外的一个独立装置,又称磁盘机,包括定位驱动系统、数据控制系统和主轴系统。主轴系统的主要部件是主轴电机和控制电路。受传动机构控制,可使磁盘组做高速旋转运动。磁头分装在读写臂上,连成一体,固定在小车上。在音圈电机带动下,小车可以平行移动,带着磁头做盘的径向运动,以便找到目标磁道。磁头具备浮动特性,当盘面做高速旋转时,依靠盘面形成的高速气流将磁头微微托起,使磁头与盘面形成微小的气隙。整个驱动定位系统是一个带有速度和位置反馈的闭环调节自控系统。由位置检测电路测得磁头的即时位置,并与磁盘控制器送来的目标磁道位置进行比较,找出位差,再根据磁头即时平移的速度求出磁头正确运动的方向和速度,经放大送回给线性音圈电机,以改变小车的移动方向和速度,由此直到找到目标磁道为止。数据控制部分主要完成数据转换及读写控制操作。包括磁头、磁头选择电路、读写电路和索引区标电路等。在写操作时,首先接受选头选址信号,用以确定道地址和扇段地址。再根据写命令和写数据选定的磁记录方式,并将其转化为按一定变化规律的驱动电流注入磁头的写线圈中。读操作时,首先接受选头选址信号,然后通过读放大器以及译码电路,将数据脉冲分离出来。
磁盘控制器:接收由主机发来的命令,将它转换成磁盘驱动器的控制命令,实现主机和驱动器之间的数据格式转换和数据传送,控制驱动器的读写。一台磁盘控制器可以控制一台或几台驱动器。是主机与磁盘驱动器之间的接口,与主机的界面清晰,只与主机的总线系统打交道,数据的发送或接收都是通过总线完成。对主机的接口,称为系统级接口,通过系统总线与主机交换信息。对硬盘的接口,称为设备级接口,接收主机的命令以控制设备的各种操作。它通常制作成一块电路板,插在主机总线插槽中。
-
发展方向
半导体磁盘:以半导体芯片为核心,加上接口电路和其他控制电路,在功能上模拟硬盘,按硬盘的工作方式存取数据。提高磁盘记录密度。
提高磁盘的数据传输速率和缩短平均存取时间。
采用磁盘阵列RAID。
-
硬磁盘的磁道记录格式
盘面的信息串行排列在磁道上,以字节为单位,若干相关的字节组成记录块,一系列的记录块构成一个记录,一批相关的记录组成文件。定长记录格式:在移动磁头组合盘中,磁头定位机构一次定位的磁道集合正好是一个柱面。信息的交换通常在圆柱面上进行,柱面个数正好等于磁道数,故柱面号就是磁道号,磁头号则是磁盘面。盘面又分为若干个扇区,每条磁道被分割成若干个扇段,扇段是磁盘寻址的最小单位。当台号确定后,首先确定柱面,再选定磁头,最后找到扇段。磁盘地址应由台号,磁道号,盘面号,扇段号等字段组成。每个扇段的头部都是空白段,起到隧道清除作用。记录格式简单,记录区的利用率不高。
不定长记录格式:可以根据需要来决定记录块的长度。ID:起始标志,磁道的起点。间隙G:空白区,占36-72个字节长度,使连续的磁道分成不同的区,以利于磁盘控制器与磁盘机之间的同步和定位。HA:磁道地址块,标识地址,专用地址,占七个字节,又来表明磁道是否完好,柱面逻辑地址号,磁头逻辑地址号和校验码。间隙G2:8-32个字节。R0:磁道标识块,用来说明本磁道的状况,不作为用户数据区。间隙G3:包含一个以专用字符表示的地址标志,指明后面都是数据块。数据记录块R1:由计数区,关键字区和数据区三段组成,都有循环校验码。
一般要求一个记录限于同一磁道内,若设有专门的磁道溢出手段,则允许记录到同一柱面的另一磁道内。
数据区长度不定,实际长度由计数区的DL给定。从主存调出数据时,常常带有奇偶校验位,在写入磁盘时,则由磁盘控制器删去奇偶校验位,并在数据区结束时加上循环校验位。当从磁盘读出数据时,需进行一次校验操作,并恢复原来的奇偶校验位。即在磁盘数据区中,数据是串行的,字节之间没有间隙,字节后面没有校验位。 -
硬盘的 6 个主要技术指标:
磁头:硬盘存储数据的主要部件,好的磁头可以提高硬盘的整体性能。硬盘一般采用两种磁头:磁阻磁头(Magneto Resistive heads,MR)和巨磁组磁头( GiantMagneto Resistive heads,GMR)。MR 和 GMR 磁头通过阻值的变化去感应信号的幅度,比以前通过电流变化感应的磁头,极大地提高了对信号的灵敏性,增强了可靠性。由于灵敏性的提高,使得硬盘磁道可以做得很窄,从而提高了单盘容量。
单盘片容量:硬盘一般可由四到五张盘片组成部分,单张盘片的容量越大,硬盘的总容量越大。随着单盘容量的增大,磁盘密度随之增大,磁头在相同时间内,可以扫过的磁盘内所包含的信息量也越多,相应地降低了硬盘的平均寻道时间。
转速:转速是指硬盘工作时主轴和盘片在工作时的转速。通常,转速越高,硬盘的传输速率越快,综合性能也越佳,但是也由此带来价格的提高,发热量增大和噪声增大等问题。
接口技术:硬盘的接口技术决定了理论上硬盘的最大外部传输速率。
Cache:这里的 Cache 指硬盘中的高速缓存,Cache 的容量越大,硬盘的外部传输率就越大。
传输速率:硬盘的传输速率有最大内部传输速率、最大外部传输速率等。
-
硬盘的工作过程是从查找开始,磁头定位在目标磁道上,等待目标段转到磁头下,然后进行读/写操作。
写入时,将计算机送来的数据处理后取至并-串变换寄存器,变为串行数据,然后一位一位地由写电流驱动器作功率放大并加到写磁头线圈上产生电流,从而在盘片磁层上形成按位的磁化存储元;读出时,当存储介质相对磁头运动时,位磁化存储元形成的空间磁场在读磁头线圈中产生感应电势,读出信息经放大检测就可还原成原来存入的数据。由于数据是一位一位串行读出的,故要送至串-并变换寄存器变换为并行数据,经处理后送至计算机。
当硬盘接到一个读取数据指令后,磁头根据给出的地址,首先按磁道号产生驱动信号进行定位,找到具体的磁道,所耗费的时间即为寻道时间;然后再通过盘片的转动找到具体的扇区,所耗费的时间即为等待时间,最后由磁头读取指定位置的信息并传送到硬盘 Cache 中。此过程的数据量传输速度即为硬盘的内部传输速度。
在 Cache 中的数据可以通过硬盘接口与外界进行数据交换。 硬盘的性能主要由它的技术参数决定,如数据传输率、平均寻道时间、硬盘接口类型等,最能说明硬盘速度的两个参数是数据传输率和平均寻道时间,而真正影响硬盘速度的是主轴电机转速和 Cache 容量。高的主轴电机转速意味着高的数据传输率和短的平均寻道时间。通常硬盘的速度越快,其硬盘驱动器板上的 Cache 容量也就越大,有些硬盘还提供了 Cache 的预取功能,在将系统需要的数据从硬盘取到 Cache 时,可以把其后的一些数据预取出来, 这样可加快读取数据的时间。
软磁盘
-
转速低,存取速度慢,都是活动头,可换盘片结构。与磁盘存储器的存储原理和记录方式相同。软盘磁头直接接触盘片进行读写,价格便宜,盘片保存方便,使用灵活,具有互换性,对环境要求不太严格。软盘尺寸越小,记录密度就越高,驱动器也越小。软盘除了可以用作外存设备还可以和键盘一起构成脱机输入装置,给程序员提供输入程序和数据,然后再输入到主机上运行,这样使输入操作不占用主机工作时间。
-
软盘是一种廉价的小容量外存,由软盘驱动器、软盘控制器、软磁盘片三大部分组成。
软盘盘片是一种圆形盘片,以软质的聚酯塑料薄片为载体,涂敷氧化铁磁性材料作为存储介质。磁盘装在塑料封套内套内有一层无纺布,用来防尘,清除静电。盘片连封套一起插入软盘机中,盘片在封套内旋转,磁头通过槽孔和盘片上的记录区接触。塑料封套为正方形,上面有许多孔(装卡盘片的中心孔。用于定位的索引孔。用于磁头读写磁盘的读写孔)。软盘盘面划分为若干个扇区,每条磁道上扇区数相同。一个盘面分成几个扇区取决于它的记录方式,区段的划分一般采用软分段方式,由软件写上的标志实现。
软盘驱动器:主要由驱动机构、磁头及定位机构、读写电路组成。驱动器提供给控制器的信号:读出数据信号,写保护信号(表示盘片套上是否贴有写保护标志),索引信号(表示盘片旋转到索引孔位置,表明一个磁道的开始),0磁道信号。
软盘控制器
解释来自主机的命令并向软盘驱动器发出各种控制信号,同时还要检测驱动器的状态,按规定的数据格式向驱动器发出读写数据命令。具体操作为:寻道操作:将磁头定位在目标磁道上。地址检测操作:主机将目标地址送往软磁盘控制器,控制器从驱动器上按记录格式读取地址信息,并与目标地址进行比较,找到预读写信息的磁盘地址。数据操作:首先检测数据标志是否正确,然后将数据字段的内容送入主存,最后用CRC校验。写数据操作:不仅要将原始信息经编码后写入磁盘,同时要写上数据区标志和CRC校验码以及间隙。初始化:写格式化信息,对每个磁道划分区段。控制器发给驱动器的信号:驱动器选择信号(表示某台驱动器与控制器接通),马达允许信号(标曲驱动器的主轴电机旋转或停止),步进信号(磁头移动的方向),写数据与写允许信号,选头信号(选择0/1面的磁头)。 -
索引孔作为旋转一圈开始或结束的标志,通常在盘片和保护套上各打有小孔。当盘片上的小孔转到与保护套上的小孔位置重合时,通过光电检测元件测出信号,标志磁道已到起点或以为结束点。
-
在使用软盘时要注意保护,存放时不可重压,应远离磁场, 避免热源,避免潮湿,以免影响软盘的正常工作和使用寿命甚至导致磁盘被损坏。
-
按使用的磁记录面不同和记录密度不同
单面单密度
单面双密度
双面双密度按软盘驱动器的性能
单面盘:只有一个磁头,盘面还有一个记录面。
双面盘:两个磁头,盘面有两个记录面。按记录密度划分
单密度:FM记录方式
双密度:MFM记录方式按盘面的尺寸结构划分
-
软盘的主要技术指标
面数:只能用一面存储信息的软盘为单面盘,或称该面为第 0 面。可以用两面存储信息的软盘为双面盘,分别称为第 0 面和第 1 面。磁道:磁道是以盘片为中心的一组同心圆。其编号自外向内依次递增。
扇区:每个磁道可以分成若干个区域,一个区域称为一个扇区或称为一个记录, 扇区是软盘的基本存储单位。每个扇区存放 512 个字节数据。
存储密度
容量:存储容量是指软盘所能存储的数据字节总数。一张双面高密度软盘存储容量为:容量=面数×磁道数×扇区数×扇区字节数。
-
记录格式
IBM软分段
磁道由首部,扇区部和尾部组成。当磁盘驱动器检查到索引孔时,标志磁道的起始位置已经找到。首部是一段空隙,是为避免由于不同软盘驱动器的索引检测器和磁头机械尺寸误差引起读写错误而设置的。尾部是依次设置在首部和各扇区后所剩下的间隙,起到转速变化缓冲的作用。首部和尾部之间的弧被划分成若干扇区,又称为扇段。扇区内的划分
地址区:指明磁道号,磁头号,区段号,记录长度和CRC循环冗余校验码。
数据区:数据标志,数据,CRC校验码。
地址区和数据区后各有一段间隙。对于单面单密度的软盘而言,其格式化容量为:磁道数/盘片x扇区数/磁道x数据字节数/扇区。出厂后未使用过的盘片称为白盘,需要格式化后才能使用。
RAID(磁盘冗余阵列)
-
RAID(Redundant Array of Independent Disks,磁盘冗余阵列)是一种技术,即由一个 RAID控制器来控制多个硬盘相互连接,这些硬盘可以按不同的方式组合起来形成一个磁盘阵列,在用户看来,对这个磁盘阵列的操作就象是对单个硬盘操作一样,但磁盘阵列具有比单个硬盘更高的存储性能和数据备份能力。
-
RAID 级别(RAID Levels)指多个硬盘组成磁盘阵列的方式。不同的 RAID级别代表着不同的存储性能、数据安全性和存储成本。还有一些基本 RAID 级别的组合形式,如 RAID 10(RAID 0 与 RAID 1 的组 合),RAID50(RAID 0 与 RAID 5 的组合)等。
-
无冗余(RAID 0)
RAID 0 又称为条带化(Striping),其原理是把连续的数据分散到多个磁盘上,系统存取数据的工作被多个磁盘并行的执行,每个磁盘执行属于它自己的那部分数据请求。这种数据上的并行操作可以充分利用总线的带宽,显著提高磁盘整体存取性能。RAID 0 在所有 RAID 级别中具有最高的存储性能。理论上,n个磁盘的并行操作使同一时间内磁盘读写速度提升n倍,但由于总线带宽等多种因素的影响,实际提升的速度低于理论值。RAID 0 是无冗余的磁盘阵列,因此一旦数据损坏,将无法恢复。RAID0 适用于对存储性能要求较高,对数据安全性要求不高的领域。 -
镜像(RAID 1)
RAID 1 又称为镜像(Mirroring),能最大限度的保证数据的可用性和可修复性。RAID 1 将写入一个磁盘的数据全部自动复制到另一个磁盘上。 当读数时,系统先从 RAID 1的源盘读取数据,若成功,则系统不再读备份盘上的数据;若读取源盘数据失败,则系统自动转去读备份盘上的数据。 RAID 1 在所有 RAID级别中具有最高的数据安全保障。但百分之百的数据备份使得磁盘空间利用率低,从而增加了存储成本。RAID 1适用于需要存放重要数据的领域。 -
错误检测和纠错码(RAID 2)
RAID 2 借用了主存常用的错误检查和恢复技术,但是已经不再使用了。 -
位交叉奇偶校验(RAID 3)
除了数据盘而外,RAID 3 只需要一个冗余盘。RAID 3 把数据分成多个 “条带”,将数据存放在N 个数据盘上,冗余盘上存储的则是对所有数据盘上同一位置的一组位的奇偶校验码。当一个数据盘发生故障时,根据奇偶校验盘和其他数据盘可以恢复数据;如果是奇偶校验盘发生故障,则不影响数据的使用。由于在磁盘阵列中,多个磁盘同时出现故障的机率很小,因此,RAID3的数据安全性是有保障的。由于数据分成非常小的“条带”,因此 RAID3 可获得非常高的数据传输率。 -
块交叉奇偶校验(RAID 4)
RAID4 类似于 RAID3,但 RAID 4的奇偶校验是以块为单位的。另外,在写更新上,RAID4 和 RAID3 也不同,对于小容量的数据访问,RAID 4 的开销更小。假设有 4块数据和 1 块校验码RAID 3 在写入新数据D0’之前要读数据 D1、D2 和 D3,才能计算新的校验码 P’;RAID 4 则将旧数据 D0 和新数据 D0’比较,看是否有改变,然后读旧校验码 P,形成新的校验码 P’。 -
分布式块交叉奇偶校验(RAID 5)
RAID 5 是一种存储性能、数据安全和存储成本兼顾的存储解决方案。以四个磁盘组成的 RAID5 为例,P0 为 D0,D1 和 D2 的奇偶校验码,其它以此类推。RAID 5 不对存储的数据进行备份,而是把数据和相对应的奇偶校验码存储到组成 RAID5阵列的各个磁盘上,并且奇偶校验码和相对应的数据分别存储于不同的磁盘 上。当 RAID5的一个磁盘数据发生损坏时,根据其余的数据和相应的奇偶校验码可以恢复被损坏的数据。 RAID 5 可以理解为是 RAID 0 和 RAID1 的折衷方案。RAID 5 可以为系统提供数据安全保障,但保障程度要比 RAID 1 低,而磁盘空间利用率要比 RAID 1高。RAID 5 具有和 RAID 0 相近似的数据读取速度,只是多了奇偶校验码,写入数据的速度比对单个磁盘的写入操作稍慢。同时由于多个数据对应一个奇偶校验码,RAID 5 的磁盘空间利用率要比 RAID 1 高,存储成本相对较低。 -
P+Q 冗余(RAID 6)
RAID 6 是对 RAID 5 的扩展,用于要求数据绝对不能出错的场合。当单个错误纠正机制不足以保护数据安全时,利用奇偶校验对数据和另一个奇偶校验盘的信息进行第二次计算,二次校验块机制可使系统从二次错误中恢复过来。由于引入了二次奇偶校验,所以 RAID 6 需要 N+2 个磁盘,而且对 RAID控制器的设计变得十分复杂,写入速度降低,用于计算奇偶校验码和验证数据正确性所花费的时间增加,因此,RAID 6 的开销是 RAID 5的两倍。RAID 6 很少使用。 -
其他
在实际应用中最常见的是 RAID 0、RAID 1、RAID 5 和 RAID 10。有时候人们会把几种 RAID技术结合起来使用,于是就形成了 RAID 10、RAID50、RAID51、RAID53 等。RAID 10 是 RAID 0 和 RAID 1 的组合形式,也称为高可靠性与高效磁盘结构。RAID 10 至少包含 4个磁盘,RAID 10 中数据分布在多个磁盘上,每个盘都有其物理镜像盘,提供全冗余能力,其磁盘空间利用率与 RAID 1 相同,RAID10 允许不多于一个磁盘故障,从而提高数据的可用性,并使磁盘阵列具有快速读/写的能力。RAID 10适用于有大容量数据存取、高数据安全性要求的领域。
RAID 53,是 RAID 3 与 RAID 0 的组合,也称为高效数据传输磁盘结构。 RAID 53 以 RAID 0为执行阵列,以 RAID 3 为数据保护阵列,因此 RAID 53有很高的读写传输率和较高的I/O带宽。在进行大数据量吞吐时,由于冗余备份的时间缩短和传输率高的缘故,RAID 53 的性能好于 RAID10,但是 RAID 53 的存储空间利用率要比 RAID 10 低。
磁带存储器
-
也属于磁表面存储器。必须按顺序进行存取,容量大,价格低,格式统一,便于互换
-
磁带
按长度划分
按宽度划分
按记录密度分
按磁表面记录信息的道数分
按外形:开盒式,盒式 -
磁带机
按规模:标准半英寸磁带机,海量带宽磁带机,盒式磁带机。
按走带速度:高速磁带机,中速磁带机,低速磁带机。
按装卸磁带机构:手动装卸式,自动装卸式。
按磁带的传动缓冲机构:摆杆式,真空式。
按记录格式:启停式,数据流式。 -
传输率取决于记录密度和走带速度。
-
数据流磁带机:将数据连续的写到磁带上,每个数据块后有一个记录间隙,使磁带在数据块间不启停,简化了磁带机的结构,用电子控制代替了机械启停式控制,降低了成本,提高了可靠性。采用类似磁盘中的串行读写方式,记录格式与软盘类似。盒式数据流磁带机与主机的接口是标准的通用接口,可用小型计算机系统接口SCSI与主机相连,也可以通过磁带控制器(控制主机与磁带之间进行数据交换)与主机相连。
-
磁带的记录格式
磁带上的信息可以按文件形式存储,也可以按数据块存储。磁带可以在数据块之间启停,进行数据传输。按数据块存储的磁带互换性更好。磁带机与主机之间进行信息传送的最小单位是数据块(记录块block),记录块的长度可以是固定的,也可以是变化的,由OS决定。记录块之间有空白间隙,作为磁头停靠的地方,并保证磁带机停止或启动时有足够的惯性缓冲。记录块尾部有几行特殊的标记,表示数据块结束。 -
磁带信息的校验属于多重校验,由奇偶校验,CRC校验和纵向冗余校验共同完成。横向奇偶校验,每个数据块内,延走带方向配有CRC校验,对每一磁道上的信息包括CRC有一个纵向奇偶校验。纠错原理:利用CRC的规律和专门线路,指出出错的磁道,纵横交错后,指明哪一道磁道有错。
光盘存储器
光盘:利用光学方式进行读/写信息的大容量圆盘形外存储器。应用激光在某种介质上写入信息,然后再利用激光读出信息,这种技术称为光存储技术。若光存储使用的介质是磁性材料,即利用激光在磁记录介质上存储信息,就称为磁光存储。通常把采用非磁性介质进行光存储的技术称为第一代光存储技术,不能把内容抹掉重写新内容。磁光存储技术是在光存储技术上发展起来的,成为第二代光存储技术,可擦除重写。
-
光盘的分类
只读型光盘(CD-ROM )
它使用得最普遍,但不能对其内容写入、删除或修改。光盘上的内容是由厂家预先刻录好的,用户只能根据自己的需求来选购已经刻录好的光盘。优点在于容量大,便于批量生产,价格低廉。只写一次型光盘(WORM)
它提供给用户写入一次的机会,信息一旦写入光盘,其用法便同只读光盘一样。使用的是只写一次性介质,这种介质一般是光刻胶,其记录方式是用氩离子激光器等对其进行灼烧记录。记录密度高,信息保存时间长,稳定可靠。 存取时间长,数据传输速率不高。可擦式光盘。
它支持反复的读写操作,其读写记录方式可分为磁光式、相变式等。可擦式介质的材料则多种多样。 -
光盘存储器的组成
光盘存储器由盘片、驱动器和控制器组成。


光盘驱动器有读/写头、寻道定位机构和主轴驱动机构等。
光盘是非接触型读写存储器,光学头与盘面互不摩擦,介质不会被破坏。
盘片由基片和涂敷在基盘表面上的存储介质构成。基片的质量对光盘系统的最终性能有着重要的影响。选择基片材料的主要依据是宏观的和微观的平直度、厚度的均匀性、机械强度、光学特性、耐热性和记录灵敏性等。目前光盘的基片材料一般都采用聚甲基-丙烯酸甲脂, 这是一种有机玻璃,它具有极好的光学、机械性能和较强的耐热性。存储介质涂敷在基片的表面 上。
光盘上存储的“0/1”二进制数据对应在光盘上就是沿着盘面螺旋状轨道上的一系列凹点和平面。所有的凹点都具有相同的深度和长度,其深度约为 0.11 至 0.13μ m,宽度约为 0.4 到 0.5 μ m ,而激光光束能在 1μs 内从 1μm2的面积内获得清晰的反射信号。
-
工作原理
只写一次型光盘通过汇聚激光束的热能,使存储介质的形状发生永久性变化来实现写操作(即刻录)的。可擦写光盘利用激光在磁性薄膜上产生热磁效应来记录信息(称为磁光存储),在一定温度下,对磁介质表面加一个强度高于改介质矫顽力的磁场,就会发生磁通翻转,便可用以记录信息。矫顽力的大小是随温度而变的。倘若设法控制温度,降低介质的矫顽力,那么外加磁场的强度便很容易高于此矫顽力,使介质表面磁通发生偏转。擦除信息和记录信息的原理一样。
在读操作时,驱动器从光盘中把数据信息读出来,并传送给计算机内部的一个输入设备。驱动器的核心部分有一个激光头,产生一束毫瓦级的激光束,首先通过对准直透镜变成平行光束,再通过分光棱镜,经过反射后再由物镜将激光束准确地会聚在光盘上。当激光映射到盘片上时, 如果是照在平面上就会有 70%到80%的激光被反射回来;如果照在凹点上就无法反射回来。经由光盘上的凹点和平面的反射,不同强度的光束沿原来的光路返回,通过分光棱镜转向光电检测器,并转换为电信号输出。经过解调和纠错处理,即可获得从光盘上读出“0/1”的二进制数据了。在整个过程中,寻迹和聚焦是最为关键的两个技术,它们是影响光驱读取数据的准确性和稳定性的决定因素。所谓寻迹就是指保证激光头发射的激光一直能够正确的对准存放数据的螺旋形轨道,从而保证读操作的正确性。所谓聚焦,则是指保证激光束能够平行地以最高光强点射在盘面上并反射回来,从而能够使光电检测器得到清晰有效的信号。光盘驱动器中包含有控制器,其接口类型有 IDE,EIDE,SCSI, SCSI-2 等。目前普遍选用 IDE 或 EIDE 接口。
-
对比


存储保护
- 由于多用户共享主存,系统就应该提供存储保护。存储保护包括两方面:存储区域保护和访问方式保护。
存储区域保护
-
当多个用户共享主存时,应防止由于一个用户程序出错而破坏其他用户的程序和系统软件,以及一个用户程序不合法地访问不是分配给它的主存区域。在虚拟存储系统中,通常采用页表保护、段表保护、键式保护和环保护方法。
-
页表保护和段表保护
每个程序的段表和页表本身都有自己的保护功能。每个程序的虚页号是固定的,经过虚地址向实地址变换后的实存页号也就固定了,不论虚地址如何出错,也只能影响到相对的几个主存页面,不会侵犯其他程序空间。段表和页表的保护功能相同,但段表中还包括段长,可以越界保护。 段表、页表保护是在没有形成物理地址前的保护。若在虚拟地址向物理地址的转换过程中发生了错误,形成错误的物理地址,那么这种保护是无效的。因此,还需要其他保护方式。 -
键保护方式
这种方法的基本思想是为主存的每一页配一个键,称为存储键,是由操作系统赋予的。可以把存储键比喻为一把“锁”,每个用户的实存页面的键都相同。为了打开这个锁,必须有钥匙,称为访问键。访问键赋予每道程序,并保存在该道程序的状态寄存器中。当数据要写入主存的某一页时,访问键要与存储键相比较。若两键相符,则允许访问该页,否则拒绝访问。 -
环保护方式
环保护方式可以做到对正在执行的程序本身进行保护。它是按系统程序和用户程序的重要性及对整个系统的正常运行的影响程度进行分层,每一层叫做一个环。在现行程序运行前由操作系统定好程序各页的环号,并置入页表中。然后把该道程序的开始环号送入 CPU 的现行环号寄存器。环号大小表示保护的级别,环号越大,等级越低。程序可以访问任何外层空间;访问内层空间则需由操作系统的环控例行程序判断这个向内访问是否合法。
访问方式保护
- 对主存信息的使用可以有三种方式:读(R)、写(W)、执行(E)。“执行”指作为指令来用,相应的访问方式保护就有 R,W,E 三种方式形成的逻辑组合。这些访问方式保护通常作为程序状态寄存器的保护位,并且和区域保护结合起来实现。
