urllib能用的无非就是请求,请求方法,urlopen

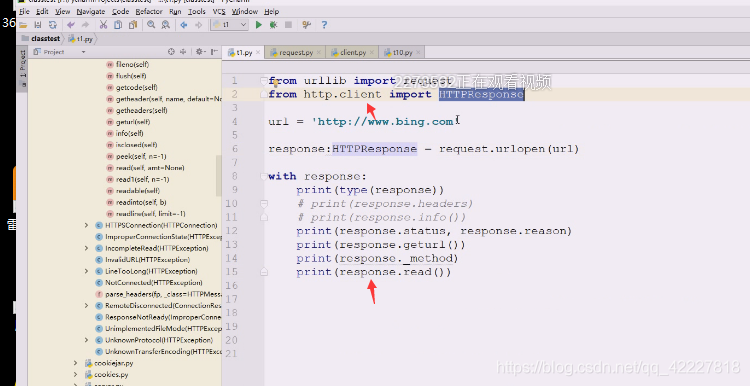
urlopen打开一个网站,看到返回的response,实际上是httpresponse,本质是个类文件对象,fileno,支持上下文
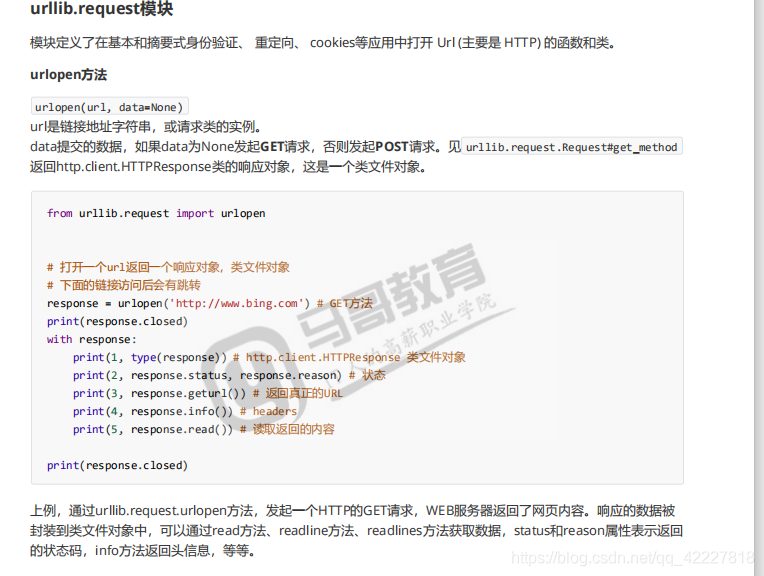
仔细看看这个类
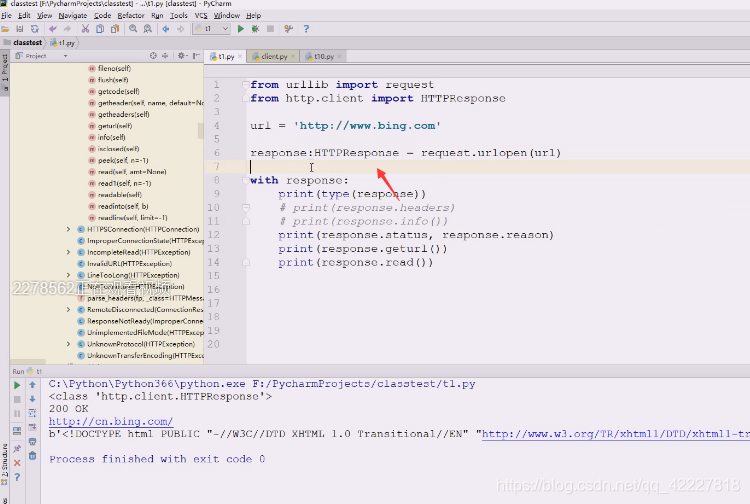
不管怎么访问,http是基于tcp协议的,底层一定会有socket通信,不然不能连接到url对应的网站建立通信,
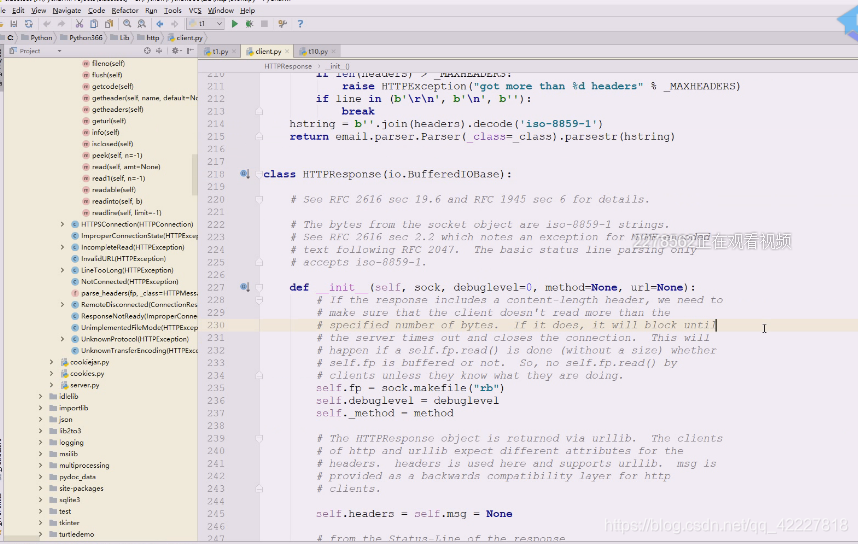
类文件对象是看到它了,带个b是二进制的,read出来的都是二进制的,因为它返回的数据不知道按什么编码,这个数据究竟用什么编码自己来解决。
但是我们浏览器收到的response header是要带编码,不带就自动选择,按照一种默认的规则,默认规则是当前操作系统编码,现在中国网站基本基于utf-8,如果不带header,windows基本都是gbk的
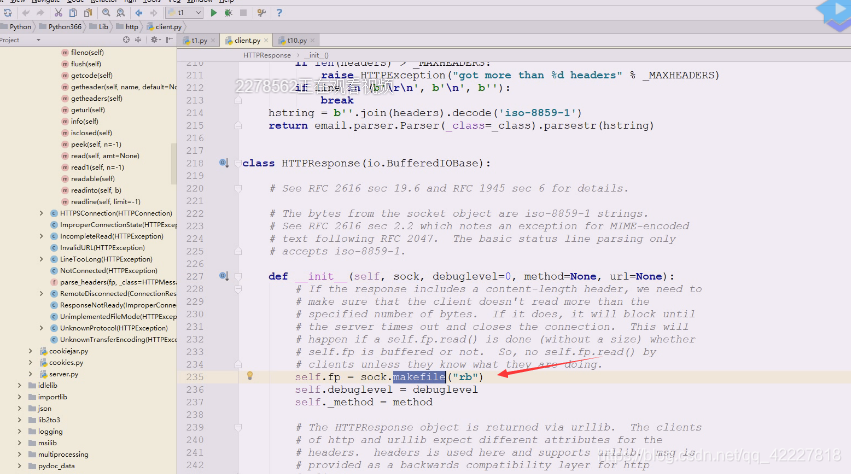
这里内部还有一个保护成员,告诉我们用什么方法
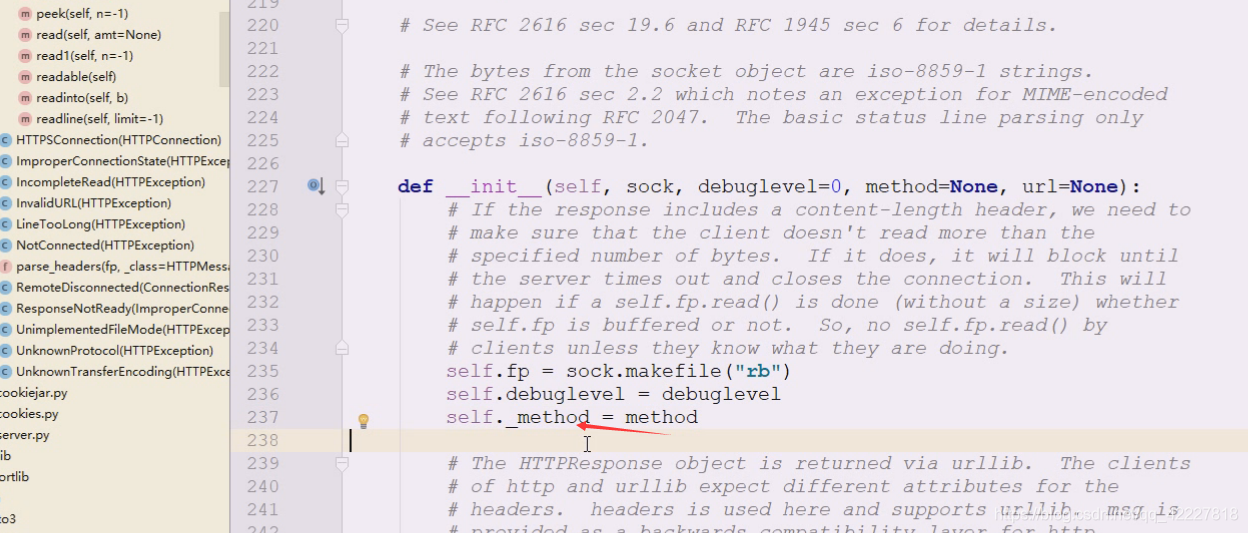
在urlopen不加数据就是get方法,如果有数据就默认post方法

*urlopen,url首先给一个字符串,data就是用这个数据来决定是什么方法,socket._global_detail_timeout,全局的超时时间。星号后面是keywordonly,给你的参数做一个分界。
ca开头个证书相关,因为我们还有一套HTTPS协议,cafile证书文件,capath证书路径,cadefault,context上下文,这几个参数全部跟证书验证相关
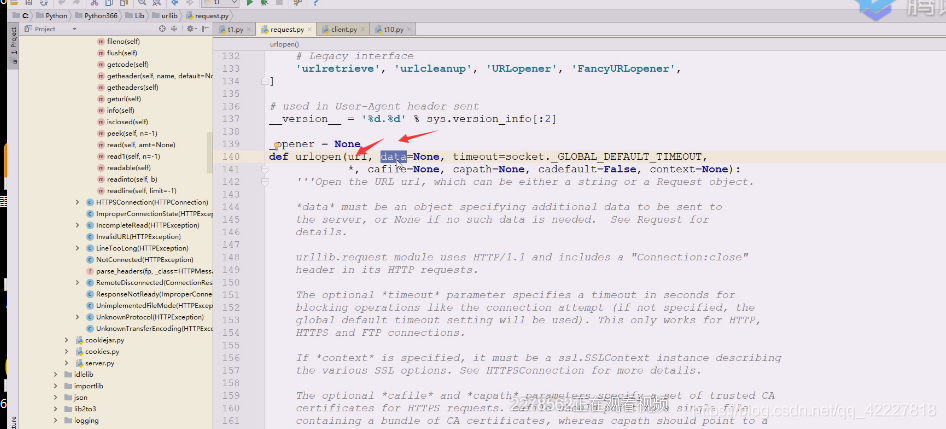
这里还说还能geturl,info,getcode拿到一些信息

urlopen是打开一个链接,建立链接,用什么打开,这里代表有个东西叫opener,也就是我们要去拿东西的时候有一个打开器
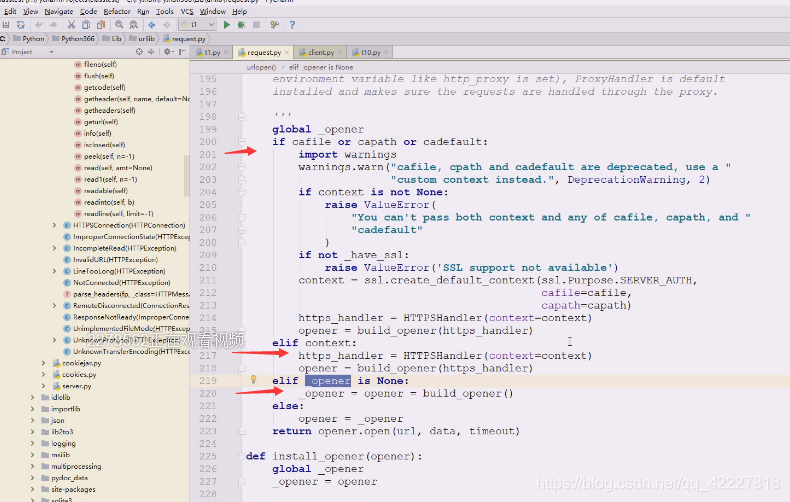
这个全局是超不了这个模块的,一开始定义的是none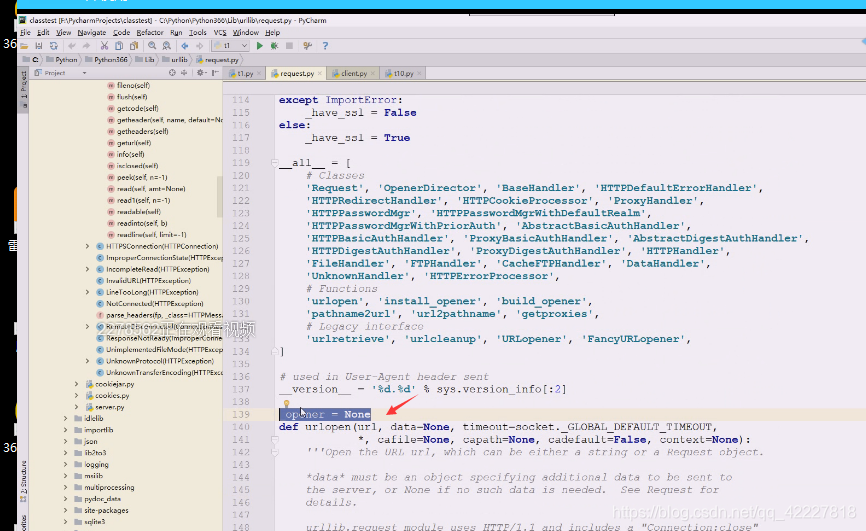
urlopen一开始的时候就是none,这个东西就是none,下面就是连等,看最后一个函数
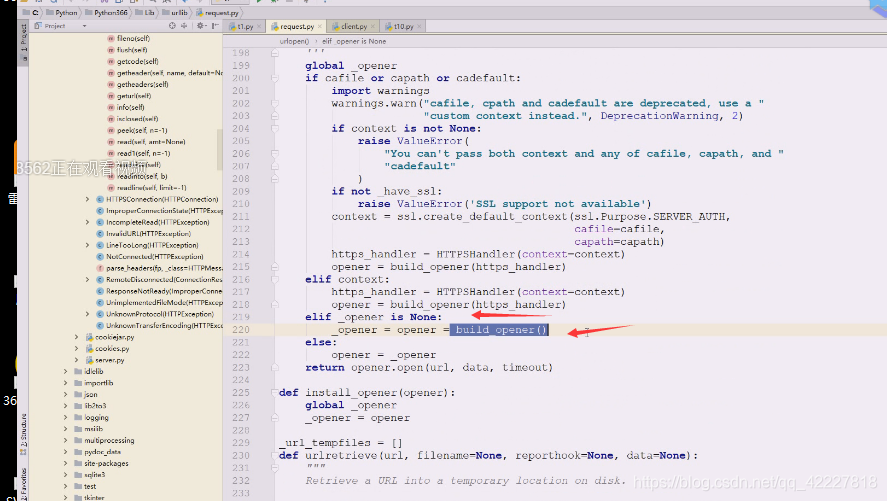
这个build_opener函数就要创建一个,下次过来就不是none了,下一次直接变成opener
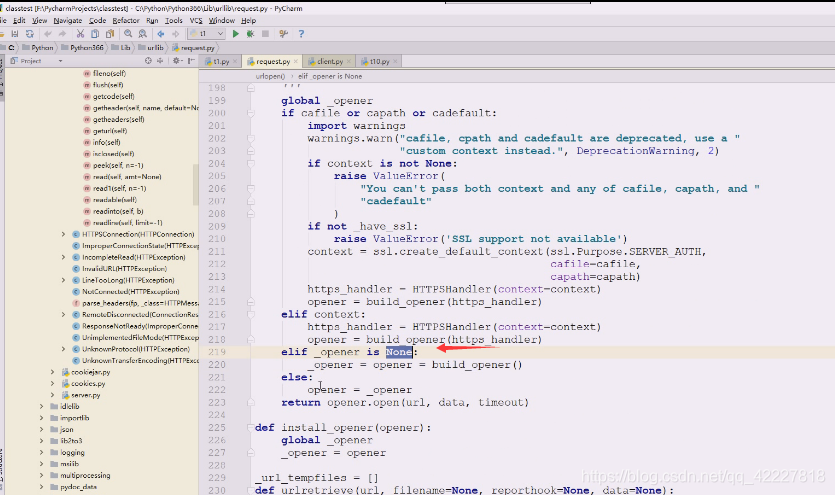
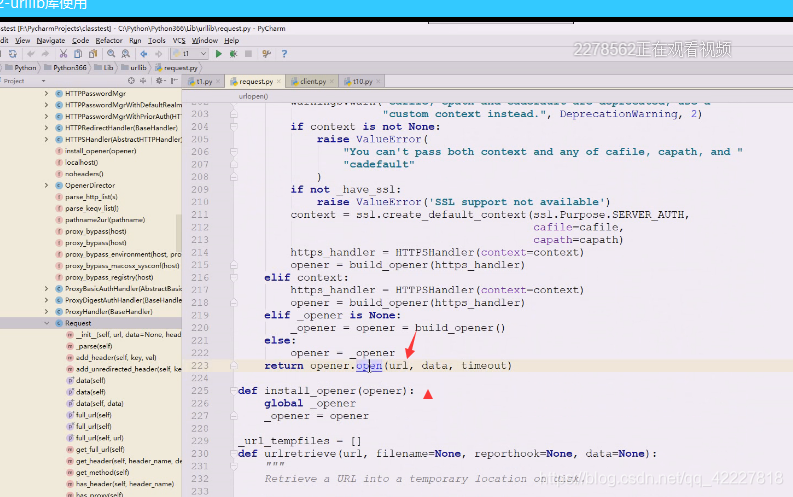
opener到最后用open方法,再打开url
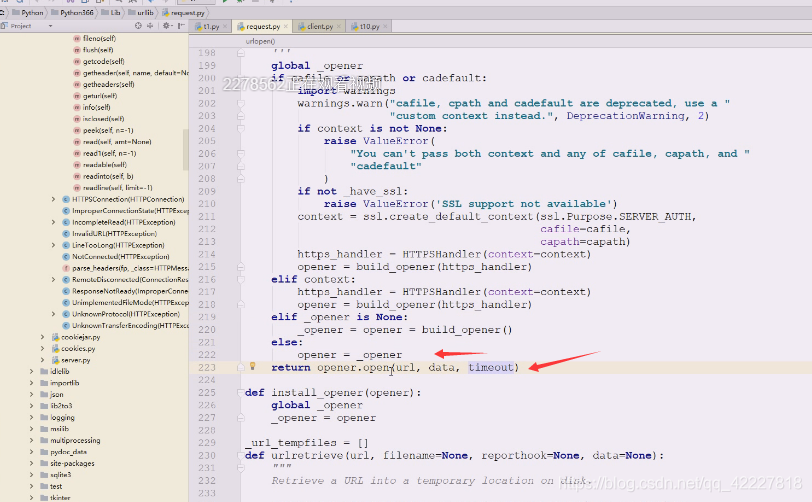
buid_opener

handler是在真正处理请求
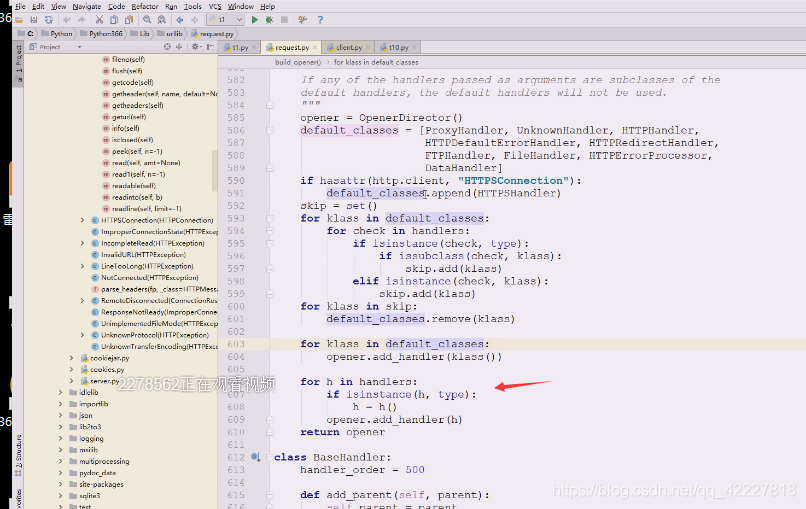
总之创建了一个opener,opener这个就用open打开,点进去看看

openerDirector里有个打开,把url和数据给它

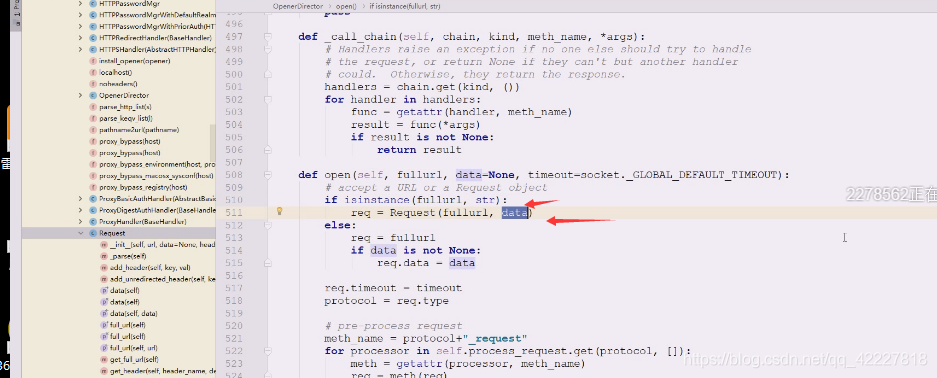
response就是里面的_open方法。_open方法可以调用里面的_call_chain,可以用这个调用链来处理
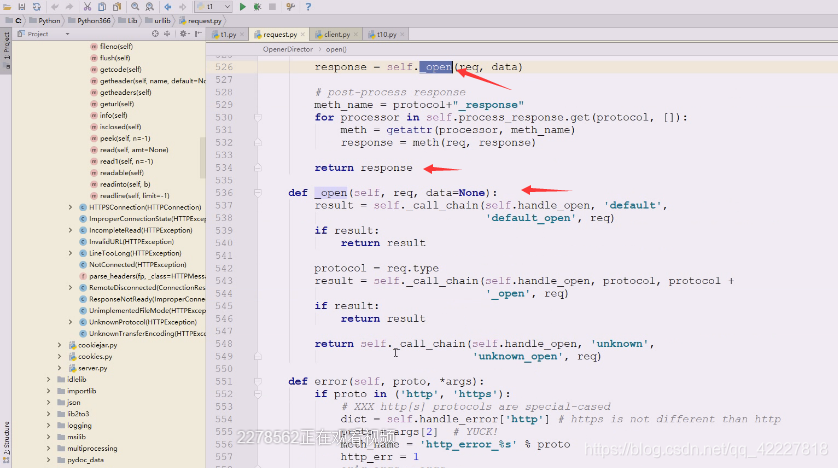
总之里面通信完成,将response对象拿到,open方法里有response,将这个response返回回来

最后返回的response,,另一个模块中定义一个这样的类,拿到这样的对象就可以分析里面的信息了,里面可能是二进制的,要对它做编码才可以拿到信息
在request还有get_method,它其实是要构建出一个request对象 的
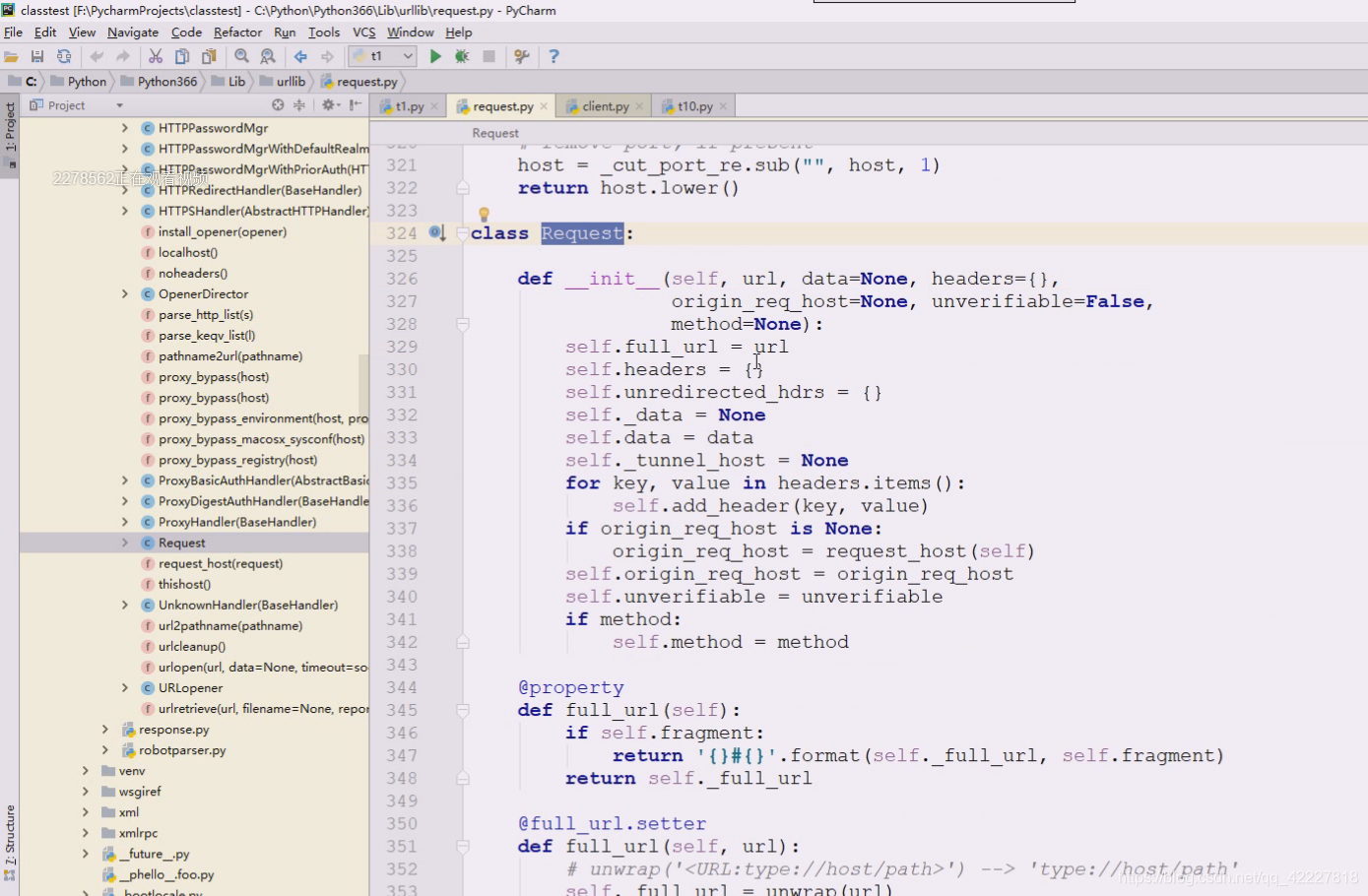
这个对象里有一个方法,get_method,如果送进来data则方法是post否则采用get方法

后面是基于它不断做演化
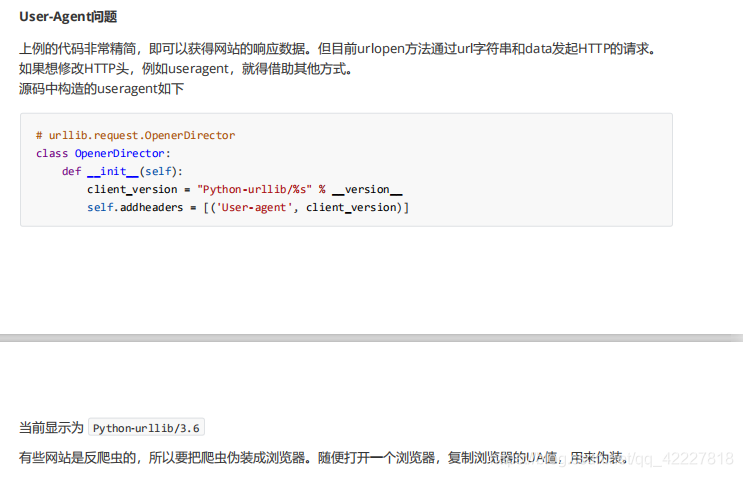
在openDirector里看到了init里有这句话,这个就告诉我们,现在的useragent叫什么名字

叫这个client的版本

也就是现在发起的所有请求,在对方那里就记录下你的useragent了,对方一看就是pythonn的 urllib,就明显知道你是非法的,然后它们要做的事情就是所有他们非写过的spider,底下就写一个,disallow /,拒绝你访问,这时候就需要把你排除在外,别人第一件做的事情就是封你*
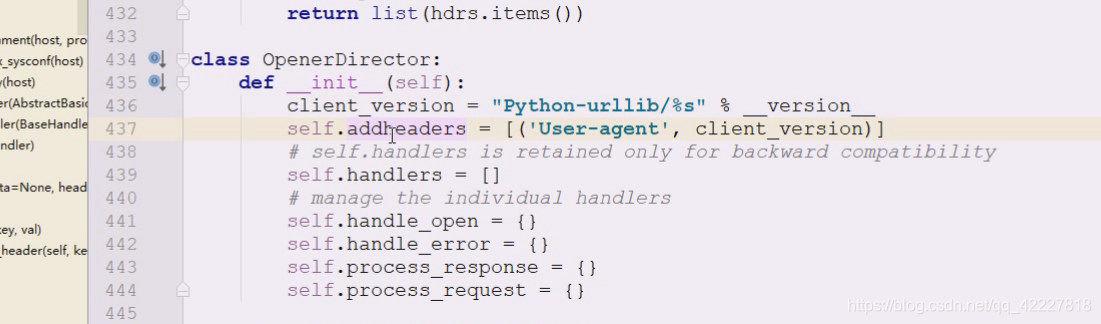
所以我们要伪造useragent,data是但凡不是none,就来判断是否是post方法,这里看起来好像没地方改

这时候就需要借助另一个东西,是构建一个类的实例的

第一个参数url,data跟刚才意思一样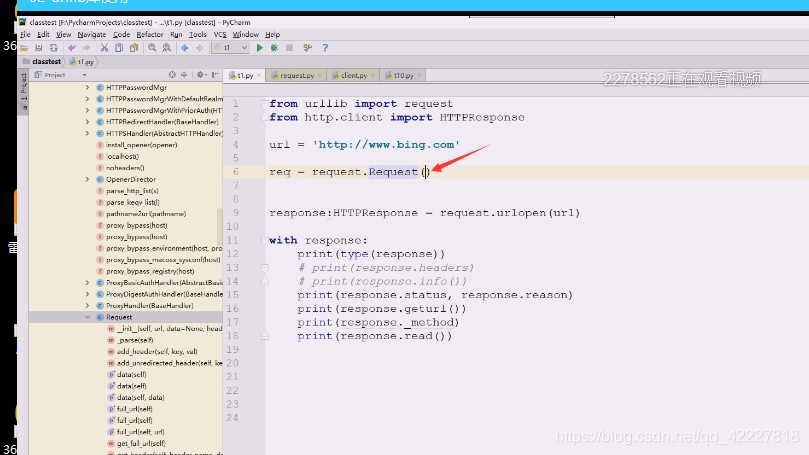
看一下参数
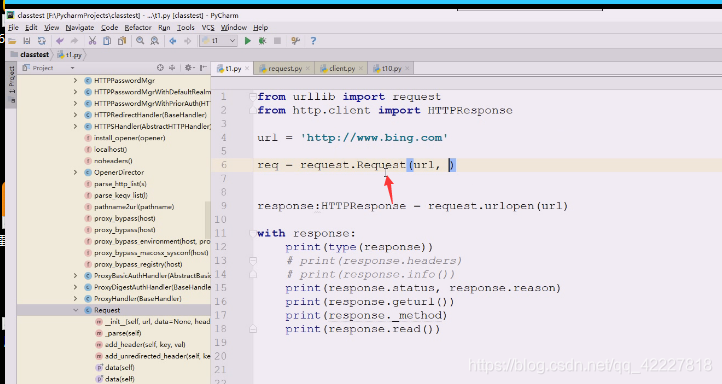
headers需要一个字典

把你送入的header遍历加进来,加到self的headers上去
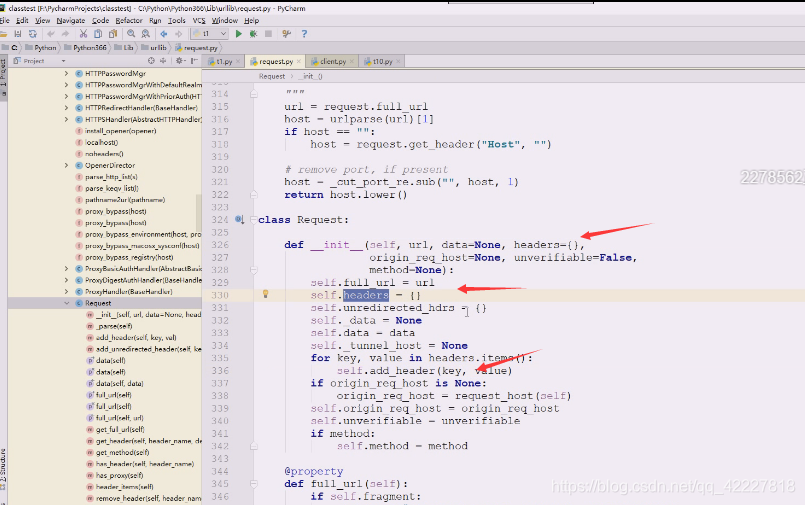
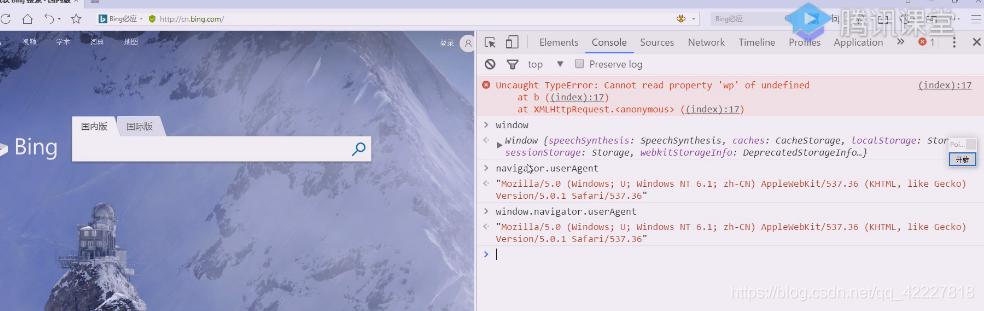
缺一个useragent,浏览器全局对象有个window,window可以省略不写,navigator,就有useragent
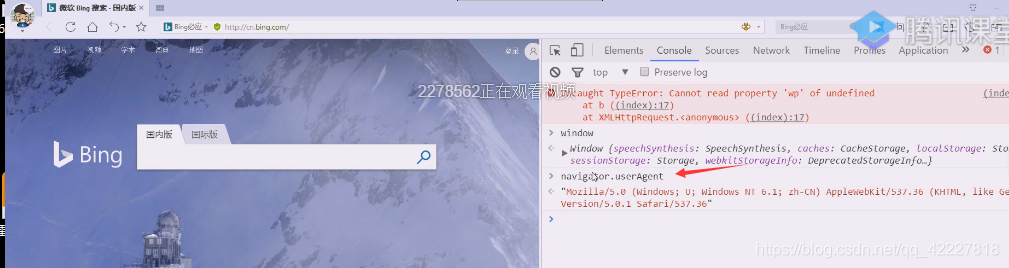
也可以写window全局对象下的useragent
复制过来就成了
第一种方法,在header里写user-agent。我们构建出了一个请求对象,把这个请求对象送给urlopen,拿到url其实也是要构建一个请求对象

url传进来还需要用open打开
这里开始用instance判断,如果是这个东西就用request一包,跟我们做的一样,我们是直接用request把url和data准备好,甚至连header都不要。
所以urlopen只是做了类型判断,如果传的仅仅是一个字符串url,最后还需要包装成reques对象
在真正打开链接前,还可以,把header里加个useragent
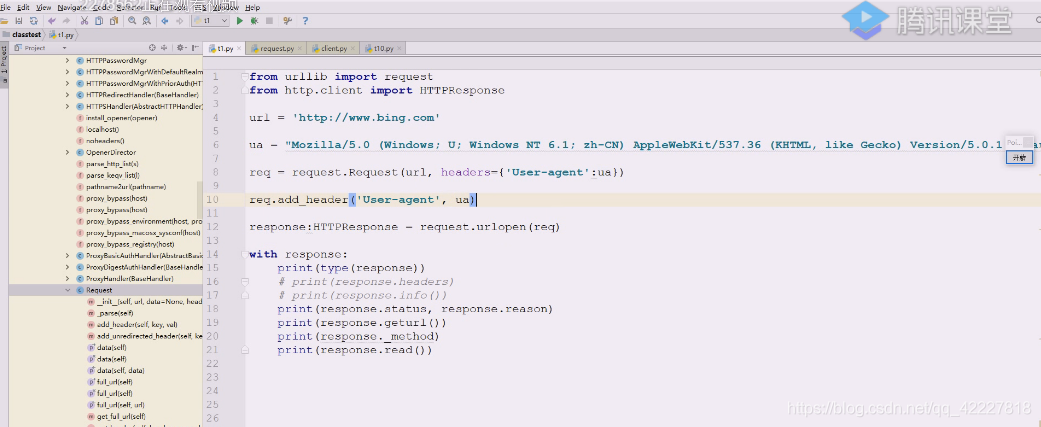
这两种方法都可以,用一种即可,这样对方看到的就是python urllib了,python的爬虫了,这时候就伪装成浏览器了,它就只能判断行为来决定是人为操作还是程序
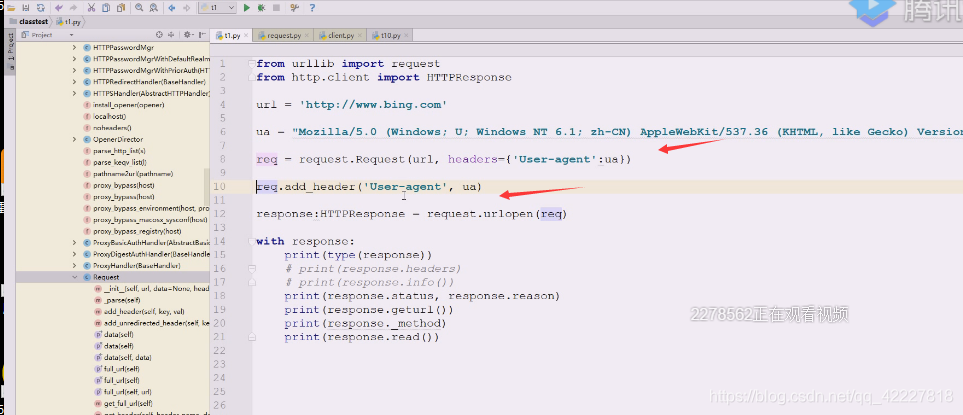
浏览器也可以想改哪个就哪个
改useragent相对来说比较简单
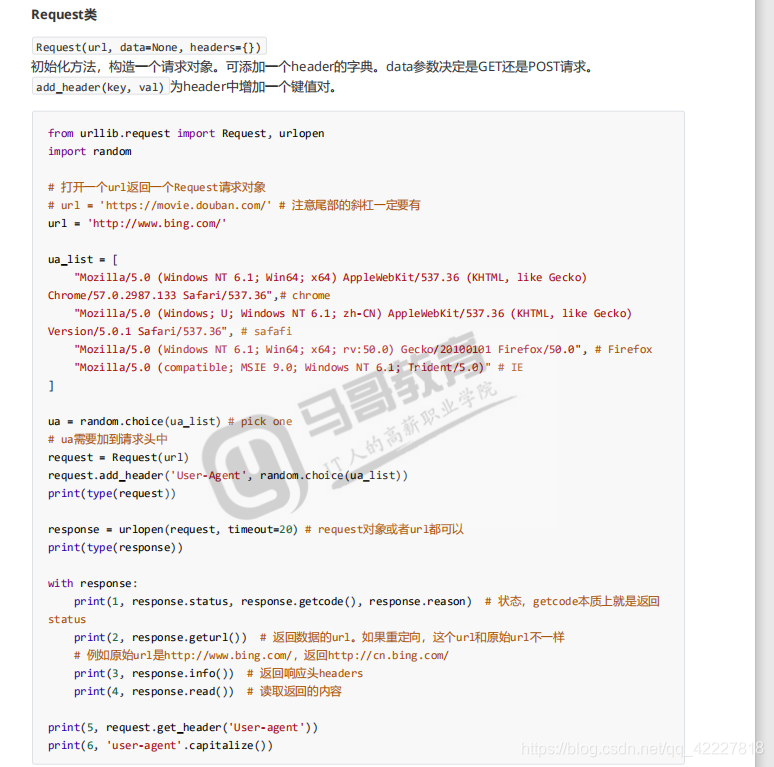
如何伪装就是要看useragent,useragent可以从网站收集,可以在这里不停的换

在这里随机挑选头部,就把useragent改了

拿到一个useragent替换掉就行了,拿到request对象,就放到下面即可,还哭修改全局的超时时间,一般不用改,会有个合理时间

**response对象返回的,你是用urlopen方法返回,返回信息就不会有太多变化,还是这样,
**

用info和header就可以拿到头部信息

read读过来是bytes

request对象用get_header取user-agent,注意大小写问题,去了后端,跑到server端,useragent被收到后会转换大小写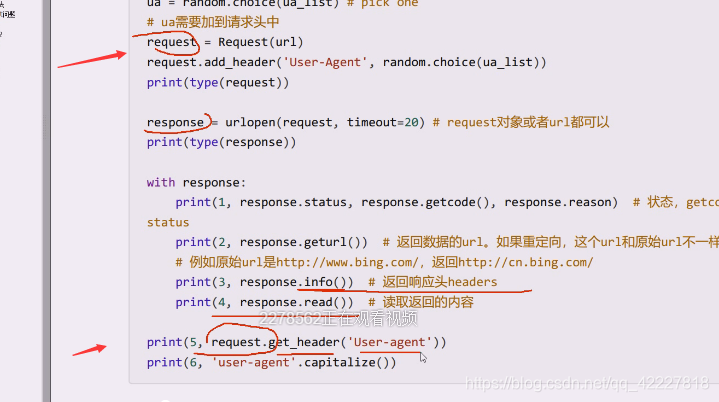
其实做的事情相当于取大写,captialize首字母大写

**useragent只能在请求头中看到,useragent是请求的时候发过去告诉服务器端,我是什么样的浏览器,应该采用适合我们浏览器的技术来返回响应的内容,浏览器的信息告诉你,我只支持html4,非要发个html5,别人怎么知道html4,就是靠useragent,告诉对方你当前浏览器支持i什么样的技术
**
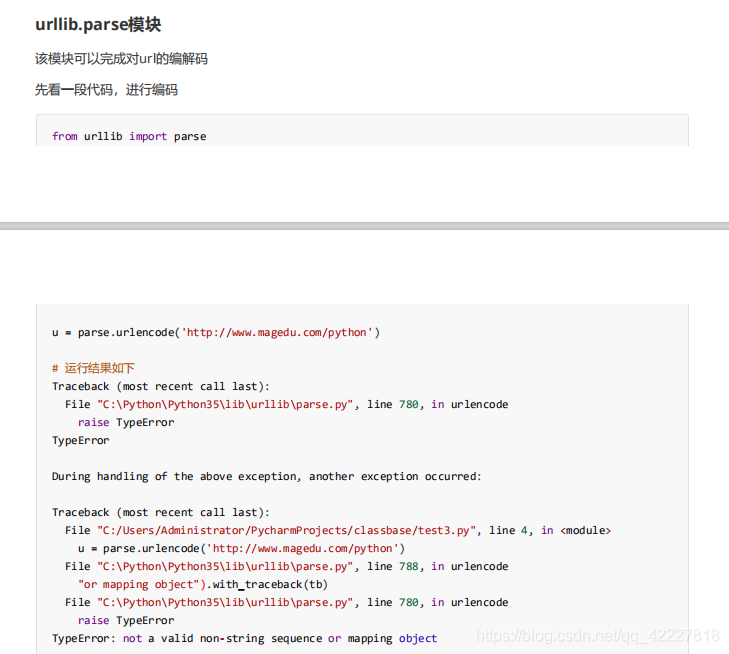
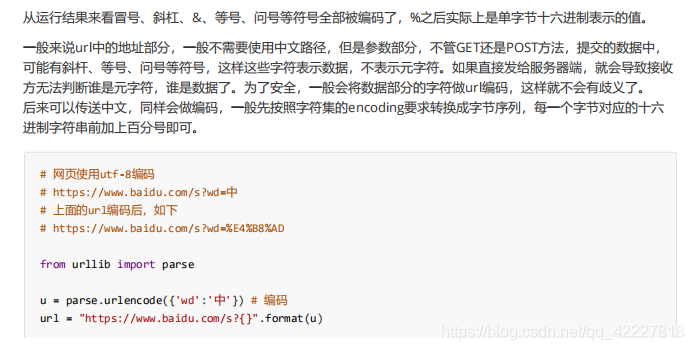
另外一个重要库
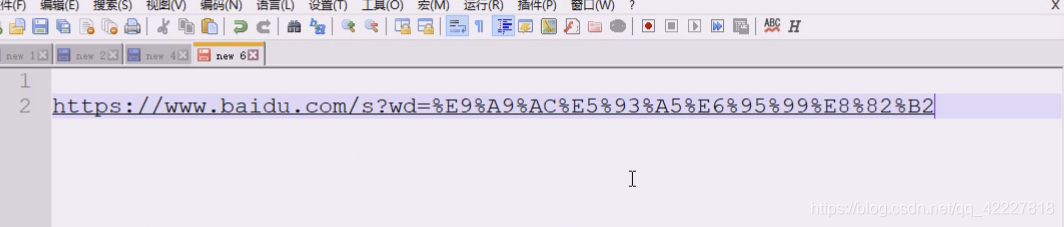
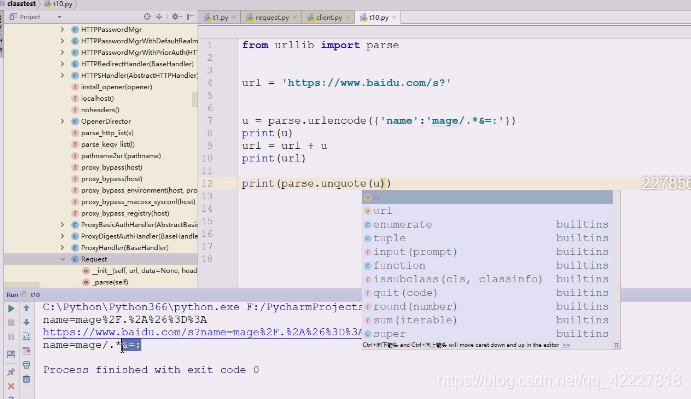
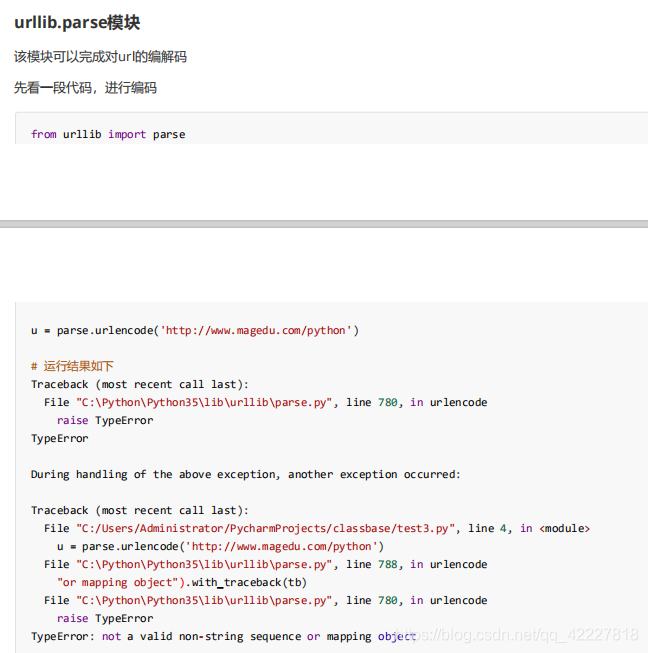
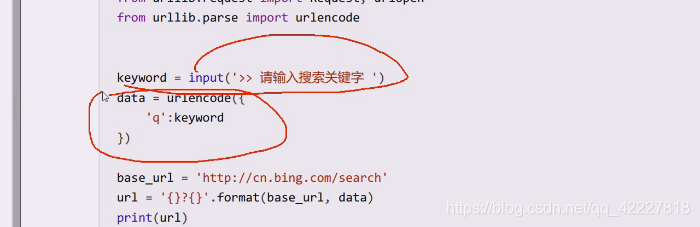
urlencode,url编码,看看编码之后返回的是什么,告诉你不是有效字符串的sequence或者mapping对象,告诉你连个序列都不是
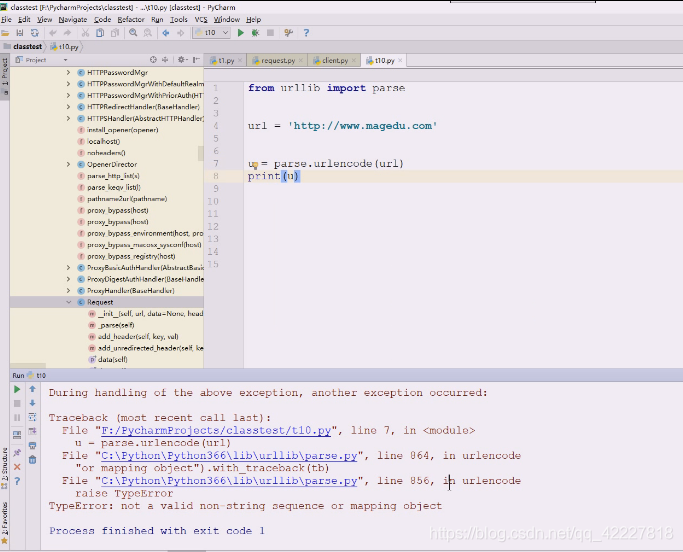
放个序列,返回的u是个字符串,写的是谁等于谁,将一些符号全部转了
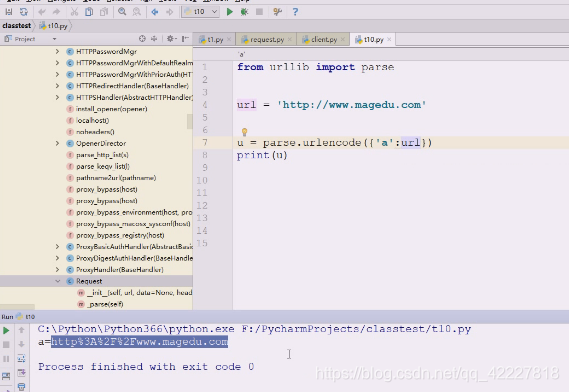
全部编码了,这就是url编码,url编码就是对url一些特殊字符进行转码,转成安全的字符
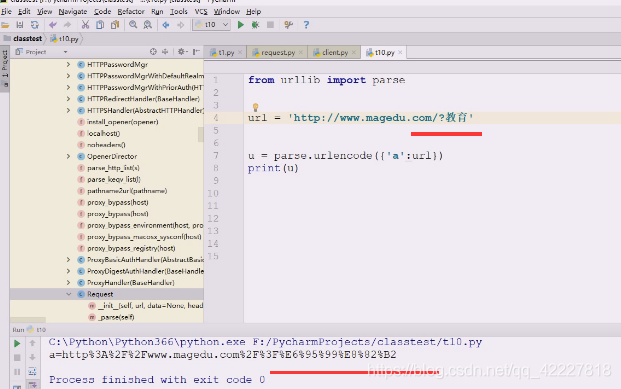
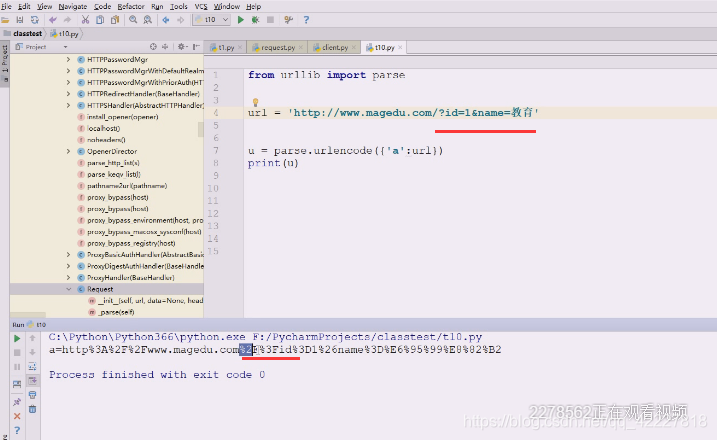
一个是/斜杠一个是id,等号%3D也被转了
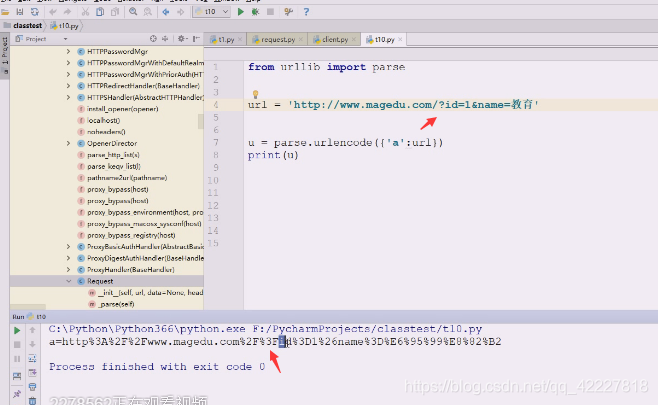
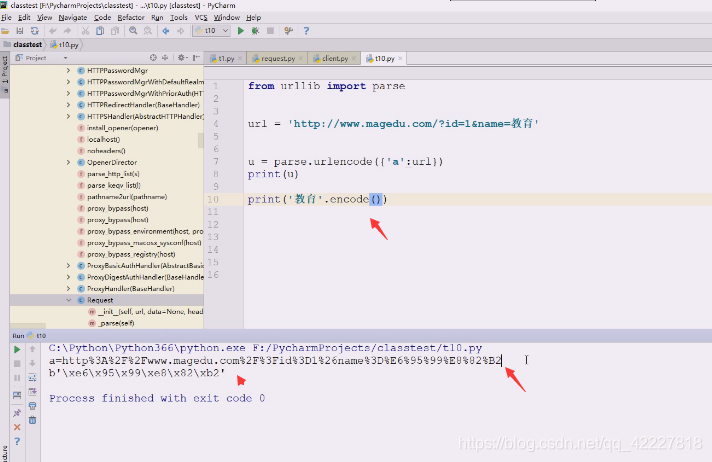
教育被转换成了6个数据,说明是utf-8的,现在默认编码要求都是utf-8

这就是uft-8的编码
整个url部分到这里为止都是安全的,这就是url定义的一部分,刚才当数据,当然会把冒号斜杠,全部转换掉了

真正要转换的是这部分

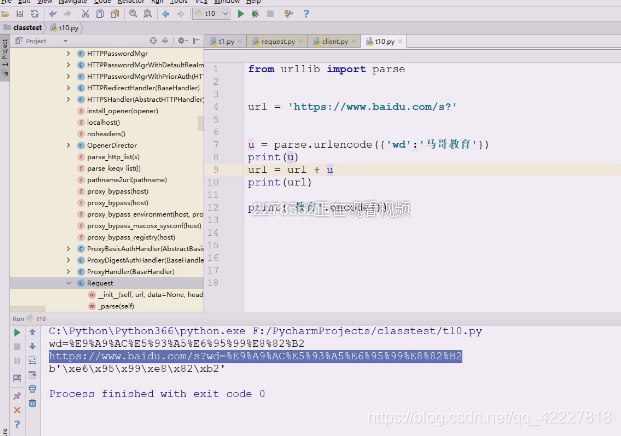
这才是我们需要做的事情,字典是谁等于谁的形式
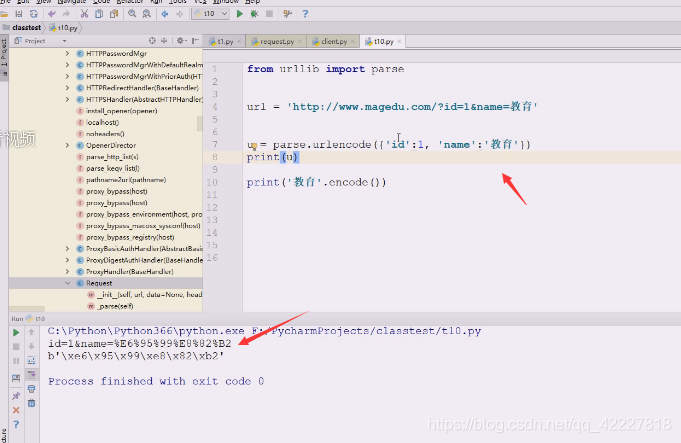
就希望得到查询字符串,或者是在post里body里的东西,得到谁等于谁这样的形式,就准备传上去了。真正访问的url实际上是等于url+u这部分
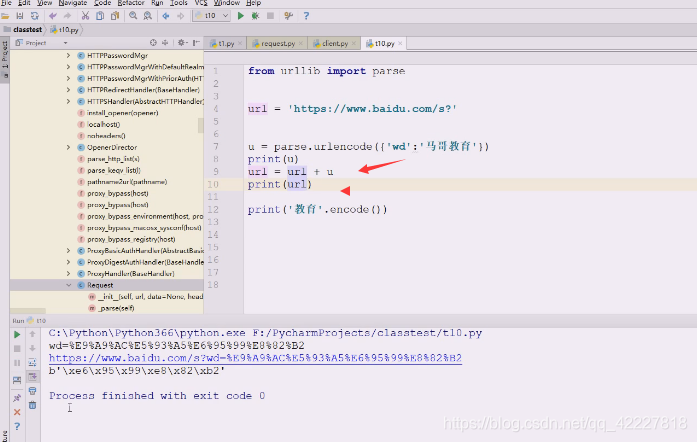
有时候浏览器就直接帮我们把转换做了,复制这个链接

复制到文本就这样了
编码是对查询字符串,或者posts提交的信息做编码,这样安全
现在特殊字符就安全了,往往是送的参数太有问题了,所以要进行编码,这些编码将一些不安全的字符,全部转换了
这些东西就是数据本身,所以一般我们对参数进行一些url的转换
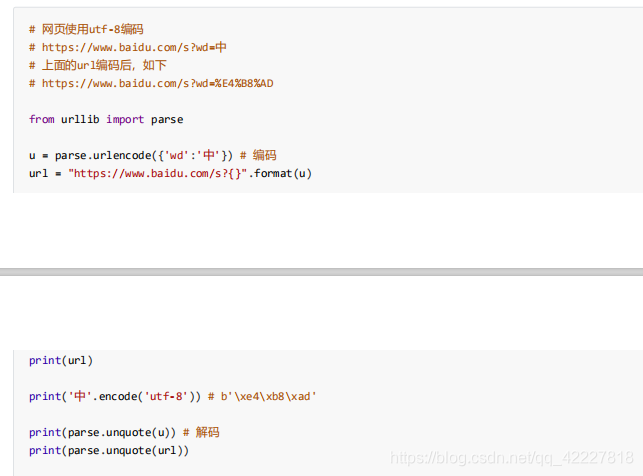
转换过去了能否转换回来,把u送进来就转回来了
用这些方式进行一些编码是比较安全的,建议编码,不编码在数据传输过程中,特殊字符存在可能不一定能解析正确,为了显示正常,要做一些编码
js本身也可以做url编码
用urllib.parse模块来进行编码
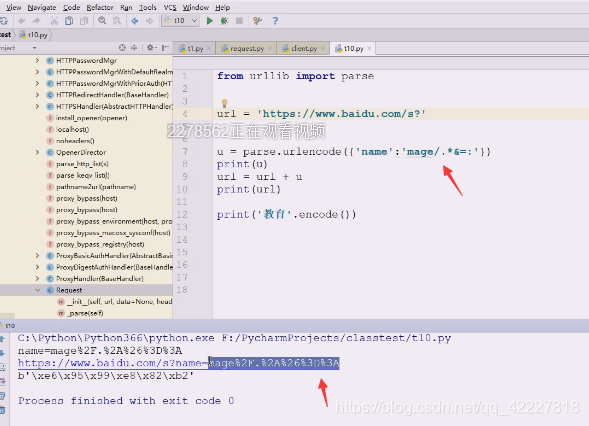
我们是想对里面的数据进行编码
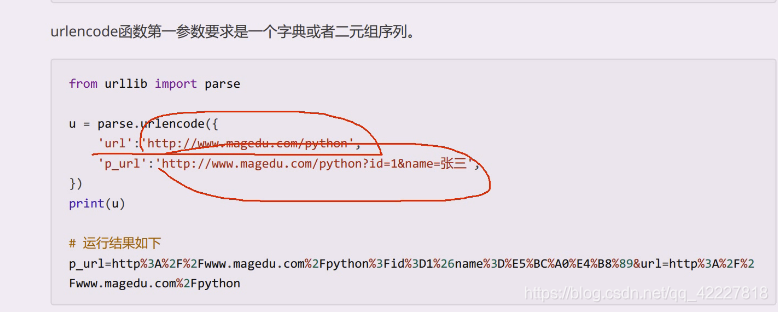
发现特殊符号都被编码了,所以为了安全起见,保证不跟url定义的元字符冲突将数据部分进行编码,是比较推荐的做法,所以编码之后得到我们想要的,一般按照字符集的默认编码进行编码
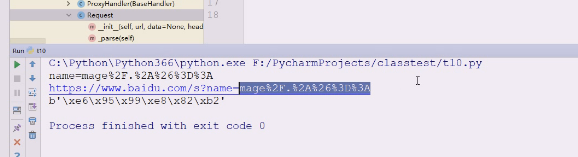
还可以转回来
试试可不可以改方法,只要里面加数据,data加进去就可以变成post方法

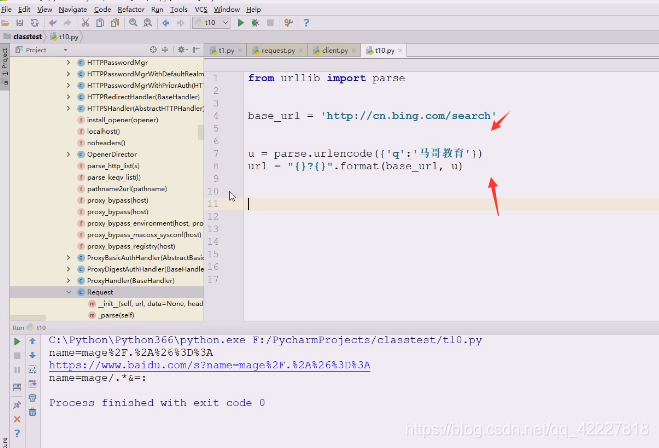
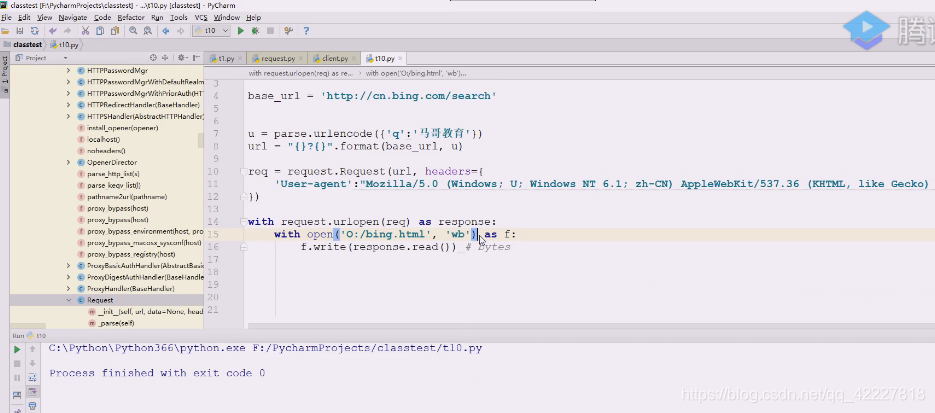
写个程序对关键字,用bing搜索,将返回的结果保存到文件里
如果在提交请求用urlopen的时候,你不给它转入data数据,data是none的话就用data方法,get方法调用完就得到response,response回来就可以获取结果,然后将这个结果存成一个网页,然后打开看看能否看到中文信息
有了这样就可以加请求了
有个模版

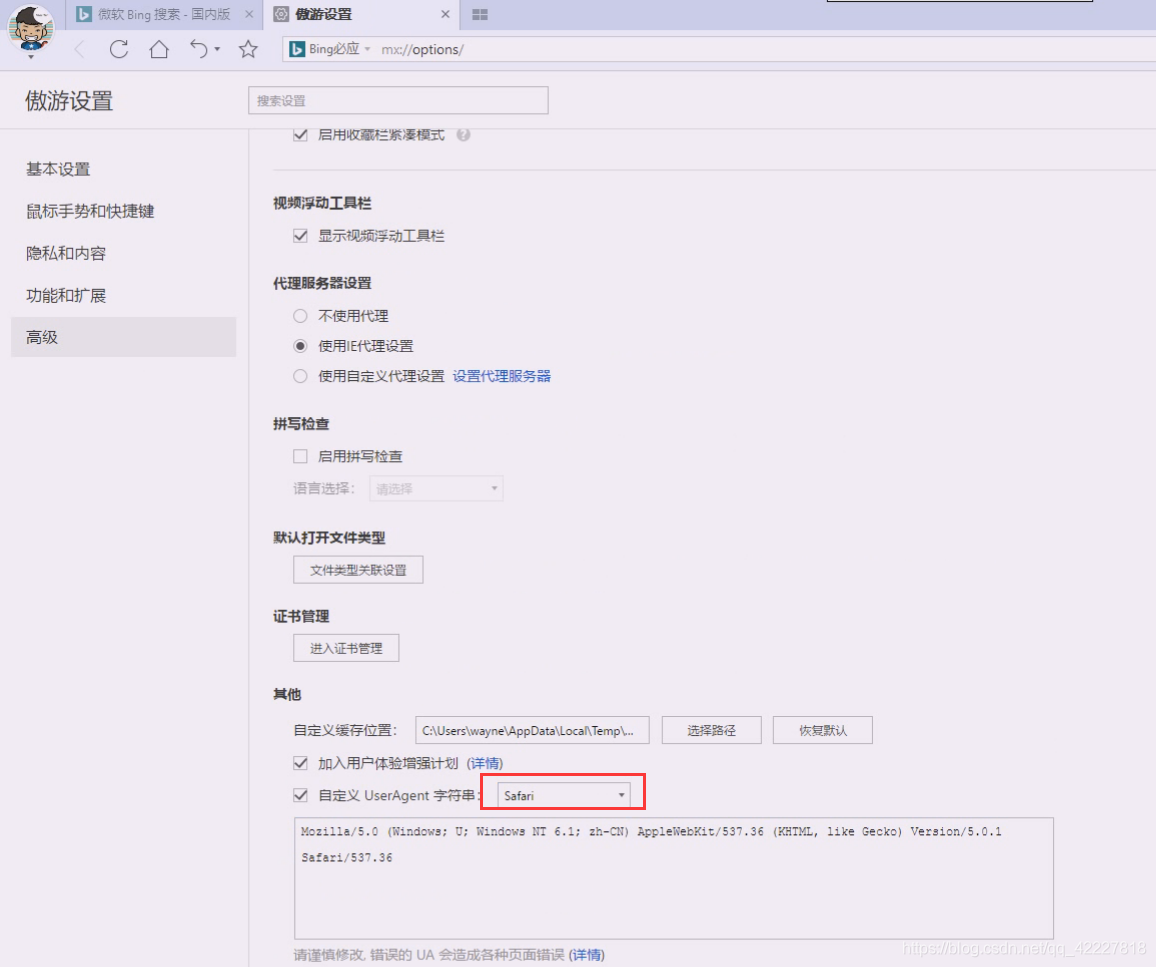
然后复制useragent,再次打开setting

apply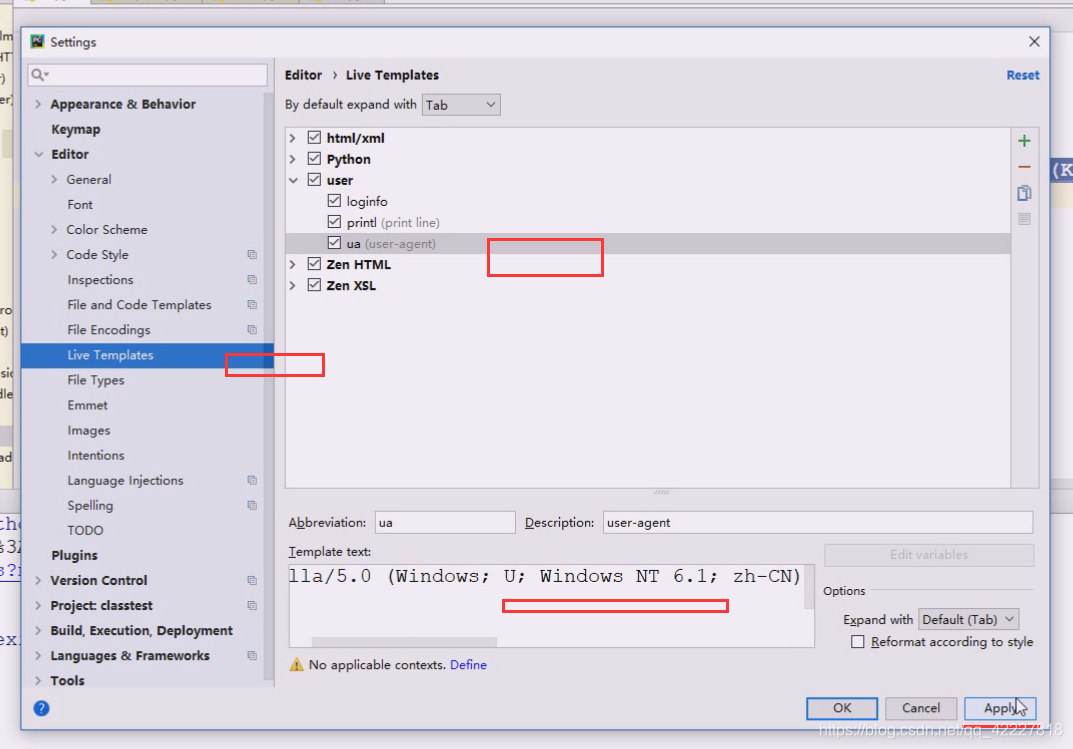
光apply还不行,还需要定义,定义在python里使用,再次apply,再OK


现在ua就可以直接用了
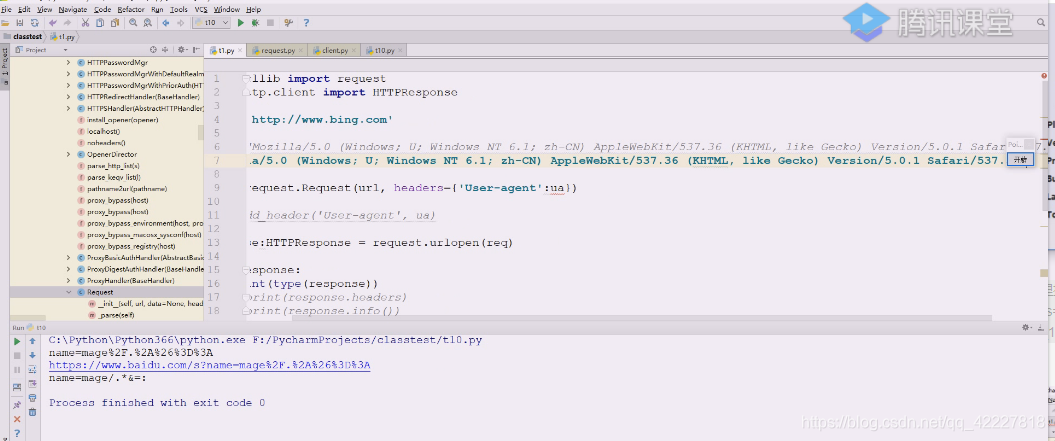
先构建一个对象来,request对象,把url塞进去,然后data不管,header需要改一下,加个续行符换行
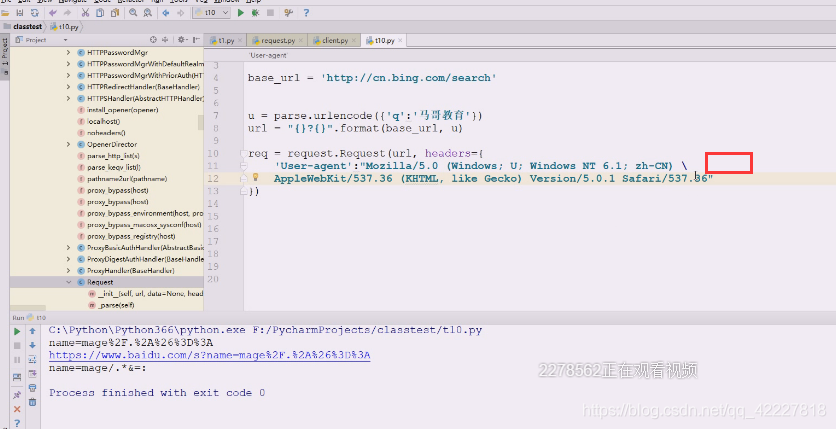
urlopen返回一个response对象,用response对象支持上下文,response是个类文件对象,支持上下文,这里读出来是个bytes
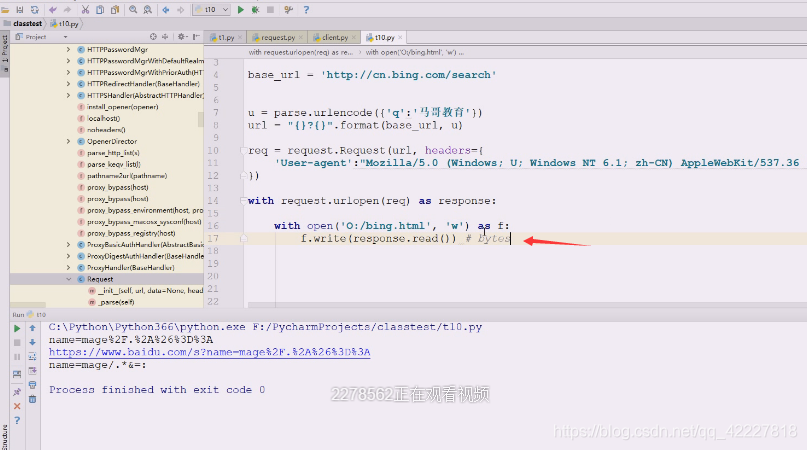
所以要加个b

这样就做到了持久化,运行一下
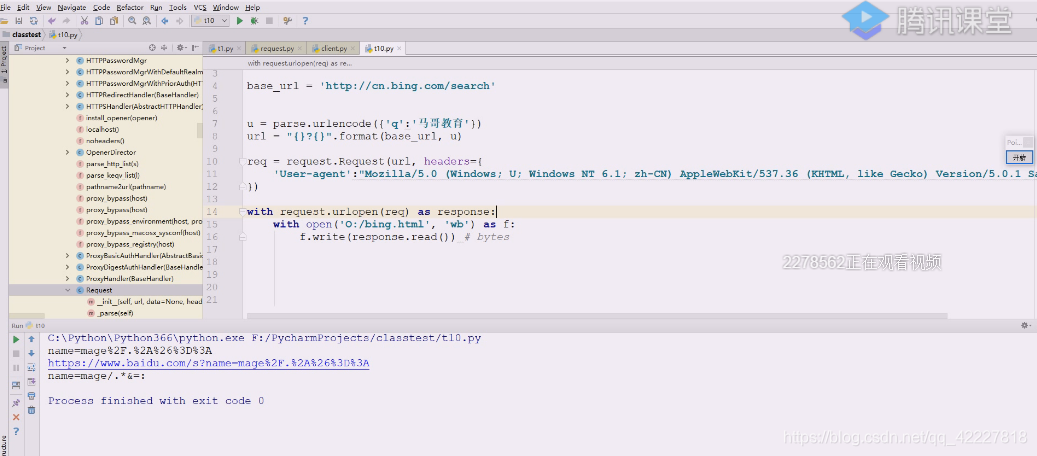
这里得到的数据就需要解析
就用这种方式即可
注意编码,使用二进制写数据的
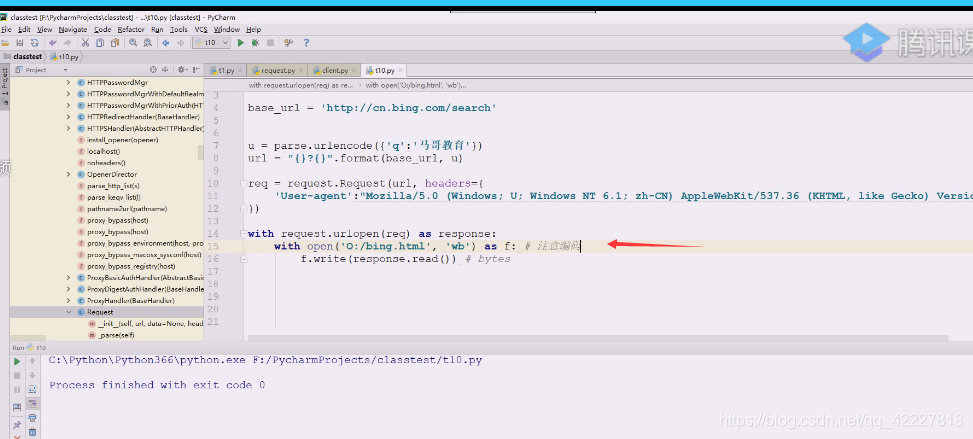
打开文件

用文本方式要特别小心,二进制写数据,用 二进制序列写到文件里去了,这里没牵扯到任何编码解码的过程

可以输入关键字,等于自己写了个跟搜索引擎相关的东西
再来看POST方法,用一个著名的网站,httpbin.org,测试web的,

这个网站可以完成get,post方法测试
准备把post数据发给它

这是一个接口手册,也就是你访问它的网站,在网站根目录下,访问get是有响应的,访问post也会有回应,也就是可以测接口函数

有点像echoserver,发什么回你什么
现在改造改造,改成 post请求,现在url改成这个网站,get发送过去,response可以回来
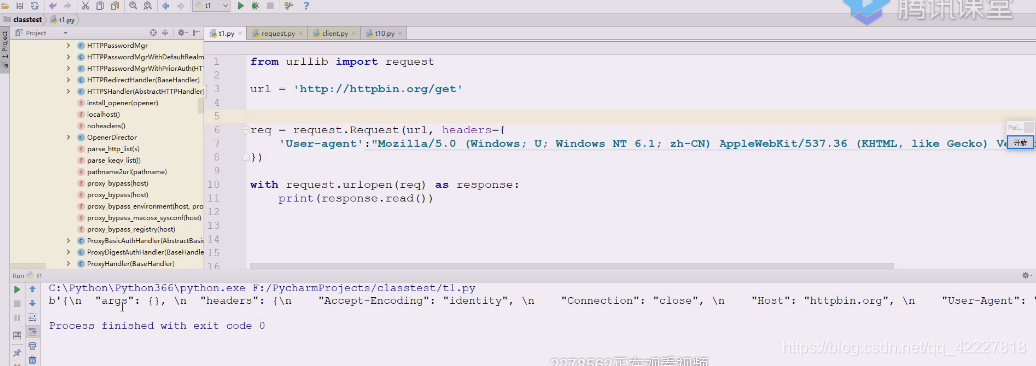
其实是将你提交的头返回来,类似echo server,把你返回的信息返回来
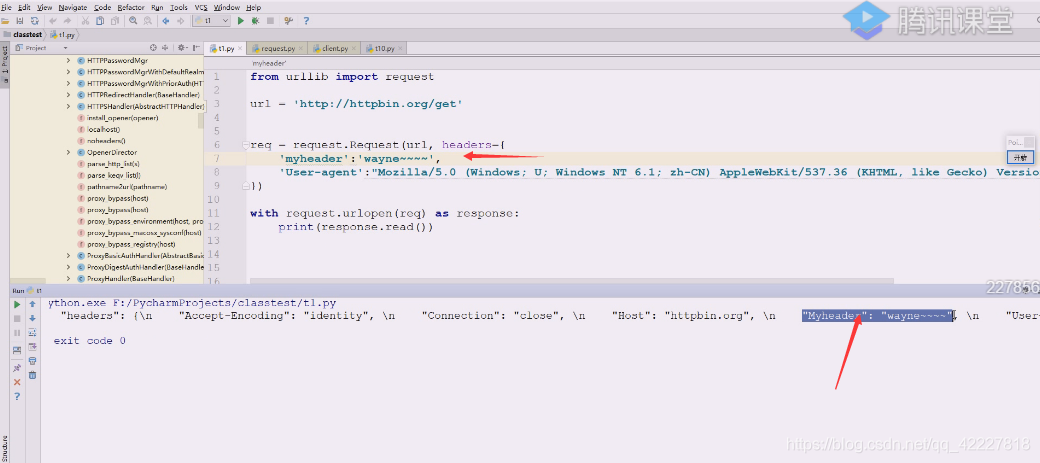
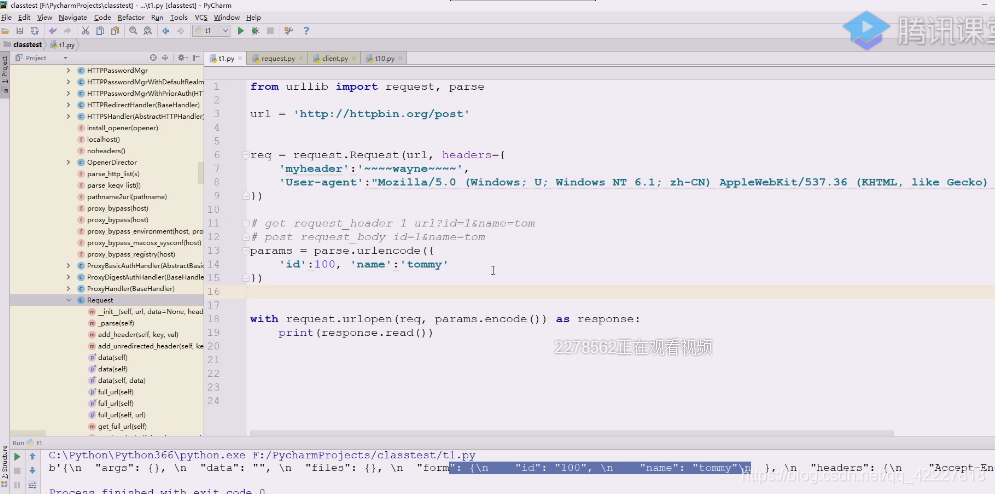
现在用post请求,看看request的data该怎么写数据
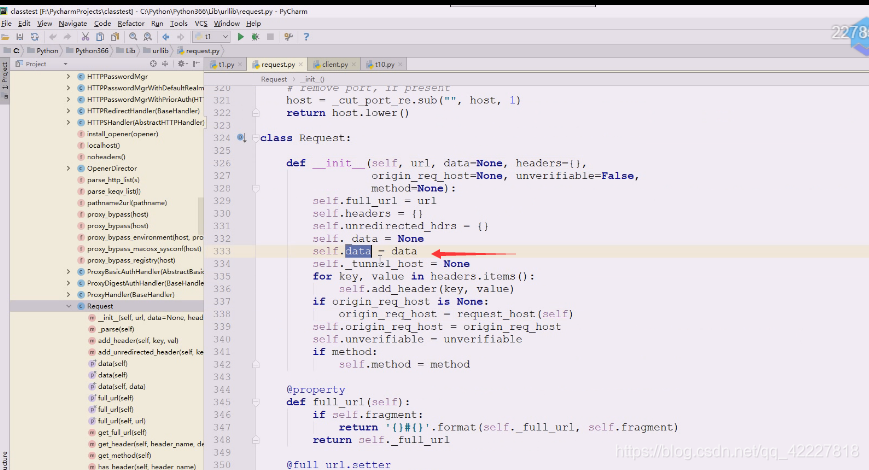
用试错的方式看看data应该是什么类型的数据,有了数据就变成 post请求过去了,提示你data应该是一个可迭代的bytes或是一个文件对象,不能是个string

其实它要的就是刚才那些参数,类似id=1,name=2,放在request_body里,get方法是将查询字符串放在request中的第一行。
post方法是指在请求体内,写这样的数据。
你发过去的数据不是kv对就没办法解析,它这里其实就是要的kv对

不是kv对,就告诉你,id为空
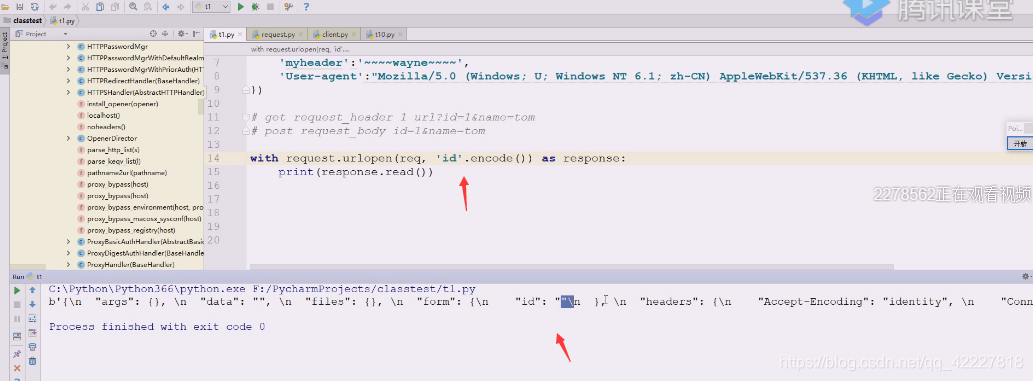
还是需要在后面加parse
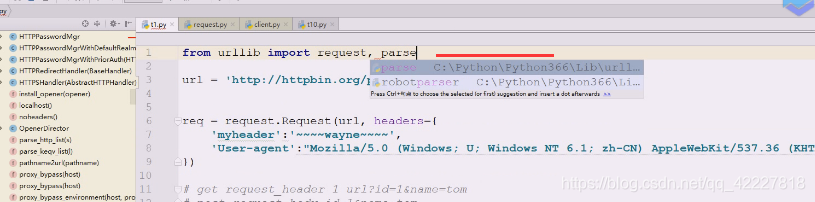
应该还等于parse.encode,,还是在里面写字典,把encode得到的值,这里得到的应该是string,所以下面也需要encode
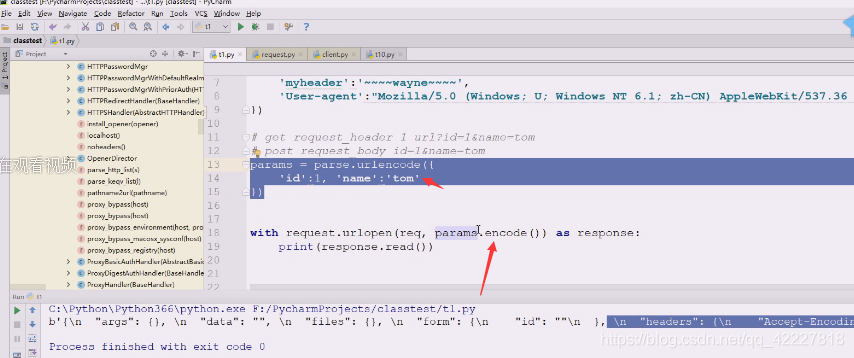
值就是变了,它相当于把表单数据放在body里传过去
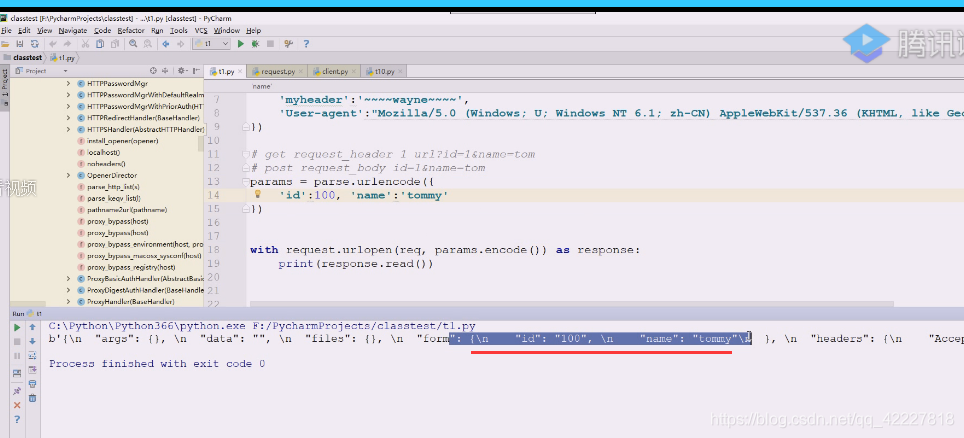
这就是最简单的请求发送,主要还是在于解析数据,爬取的数据就是为了规整的存起来,存起来在这个结果上进行分析的
这个网站没事可以过来测试测试

这种参数没有问题,直接一编码就安全了,中文和特殊符号都可以编

不能这么发,因为&符号没法处理,我们之前写的pathqs,要处理查询字符,也没有办法处理这种情况,最后我们是遇见&符号就切断,用split

如果这是你的数据一定要在url编码之后,再把它传走,是最安全的方式

如果不编码发过去,httpbin.org这个网站,最后给你返回的内容,可以看一下,跟你想的并不一样
处理json数据
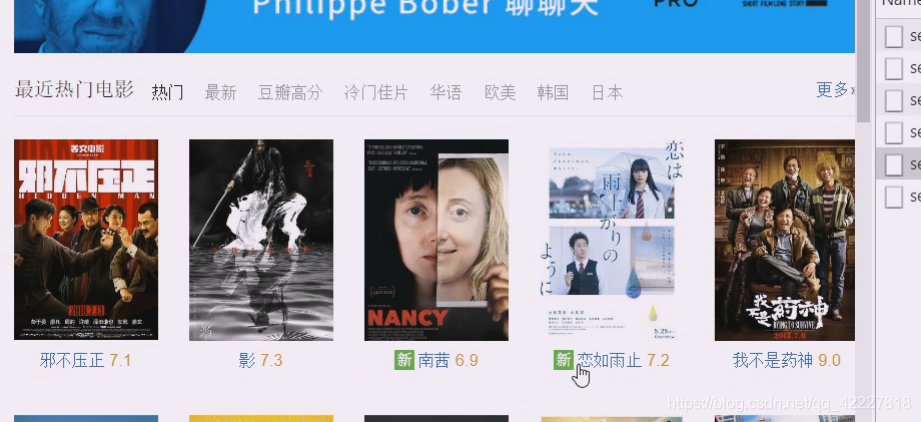
有热门电影,这个网站就复杂多了
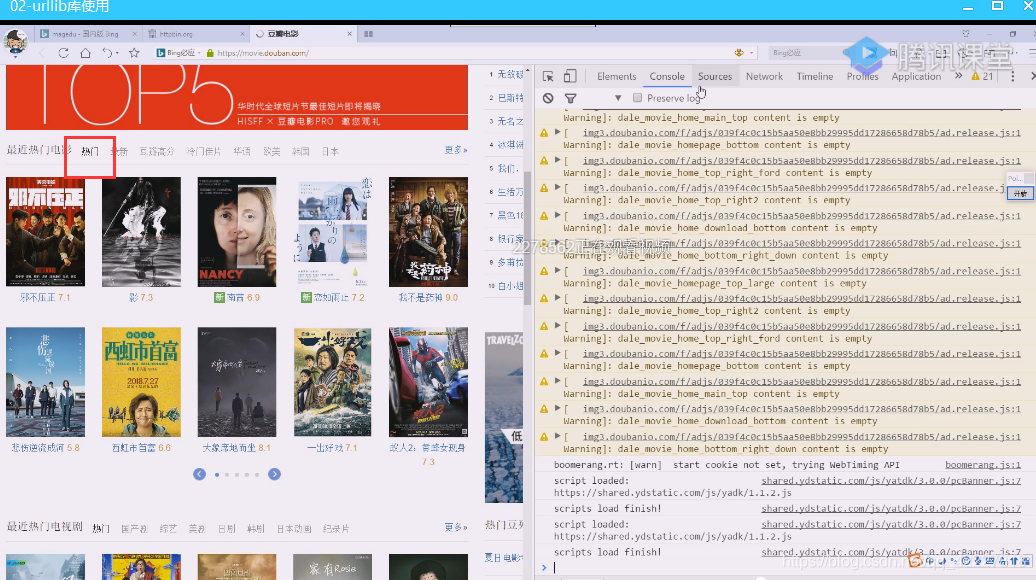
XHR就是xmlhttprequest,重新刷新一下
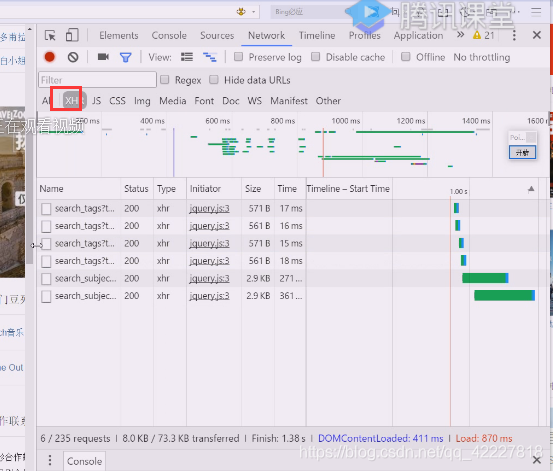
这里的数据就是我们想要的
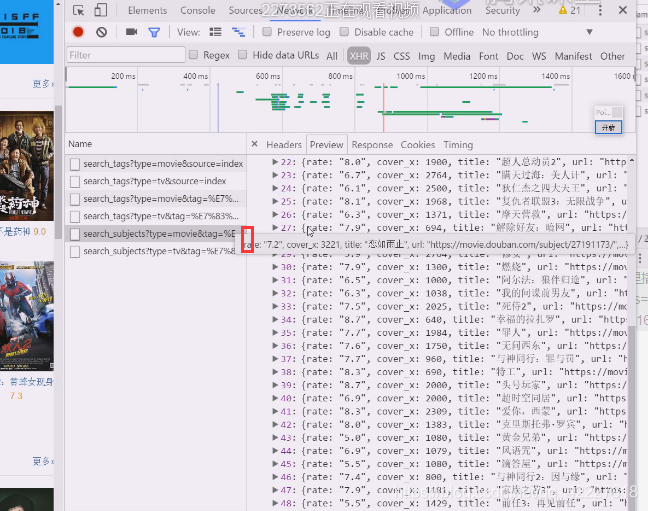
这几个都在这里
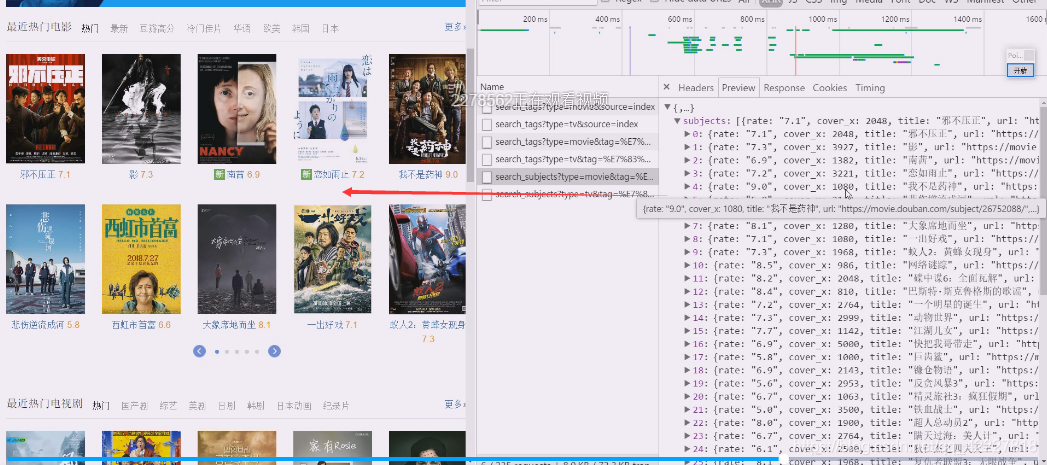
这应该是是jquery里的轮播组件
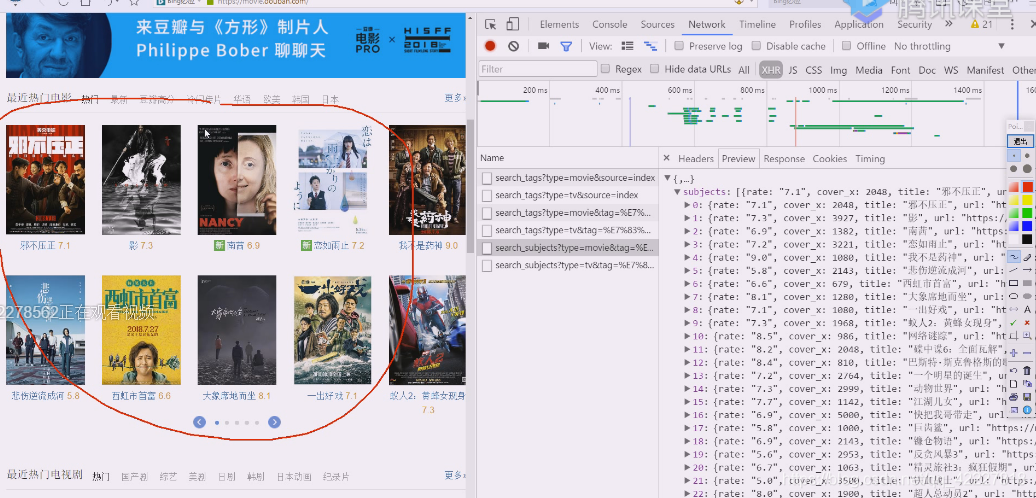
这些数据是通过ajax请求,通过xhr这个组件到后端服务器返回来,返回来的数据就是ajax异步请求

这个数据来了肯定通过js数插入到DOM树里
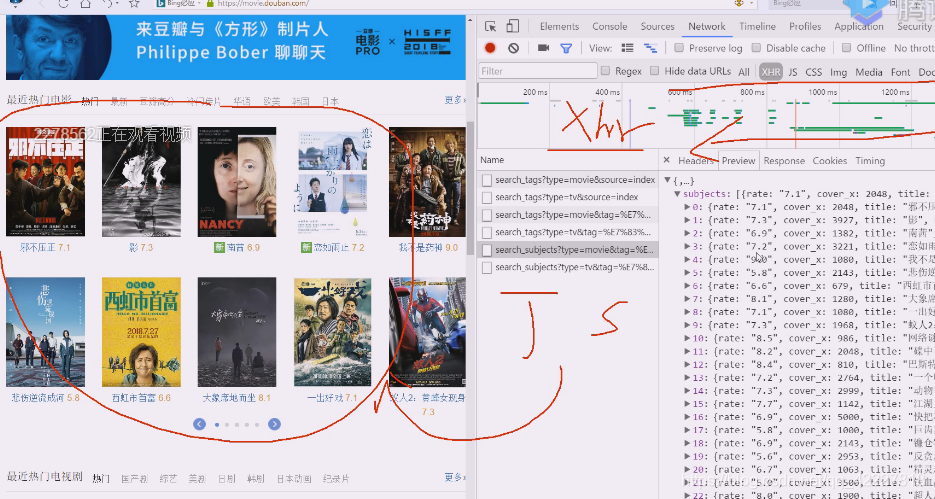
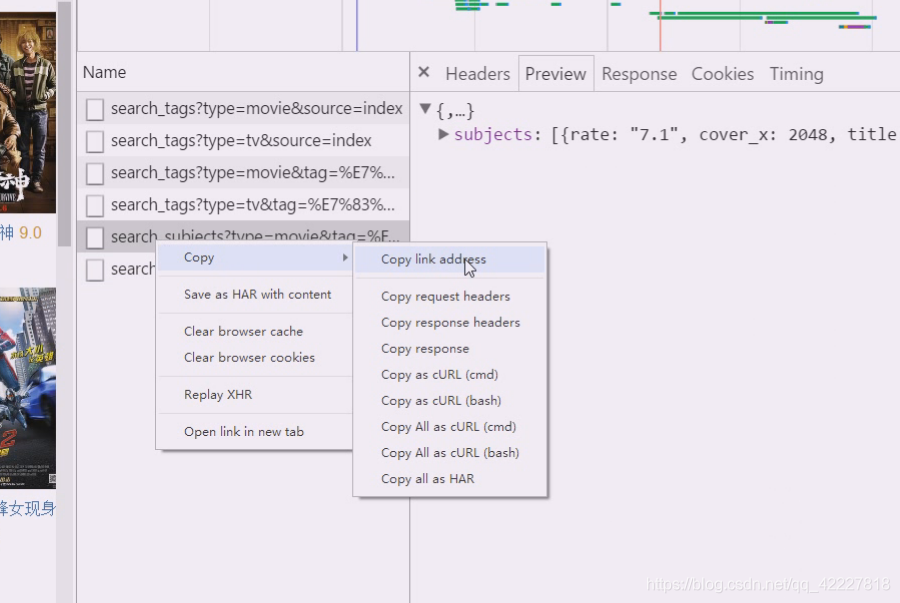
异步也是http请求,复制链接地址
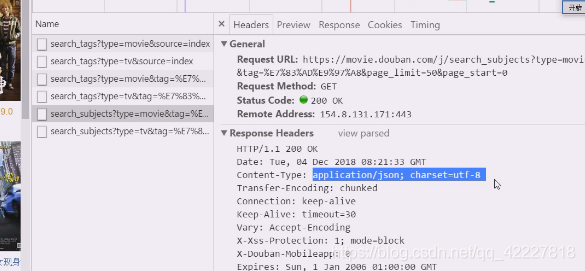
 这里把字符集,mime类型说清楚了,这是异步的http请求
这里把字符集,mime类型说清楚了,这是异步的http请求
那到链接写到这里来
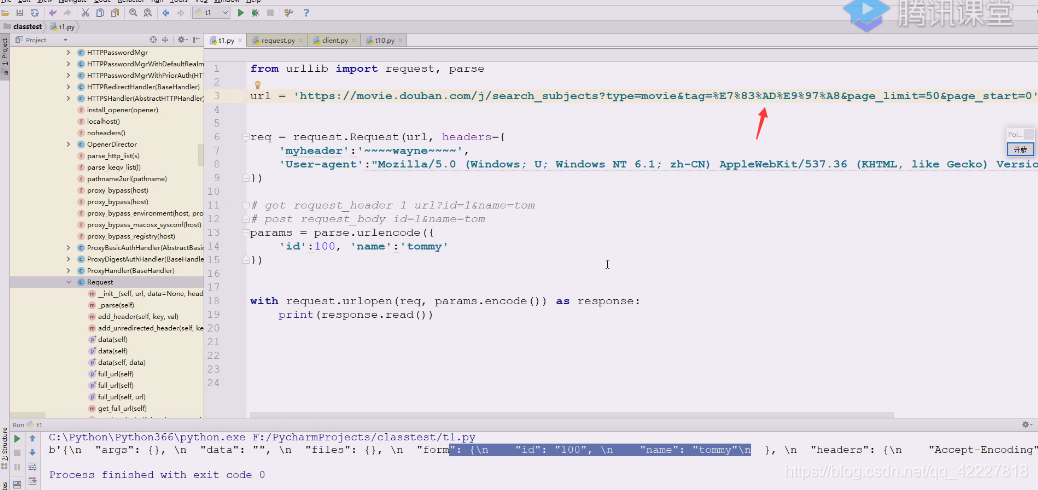
打开postman,测试一下,这里编码一下应该是热门

就要三条试试
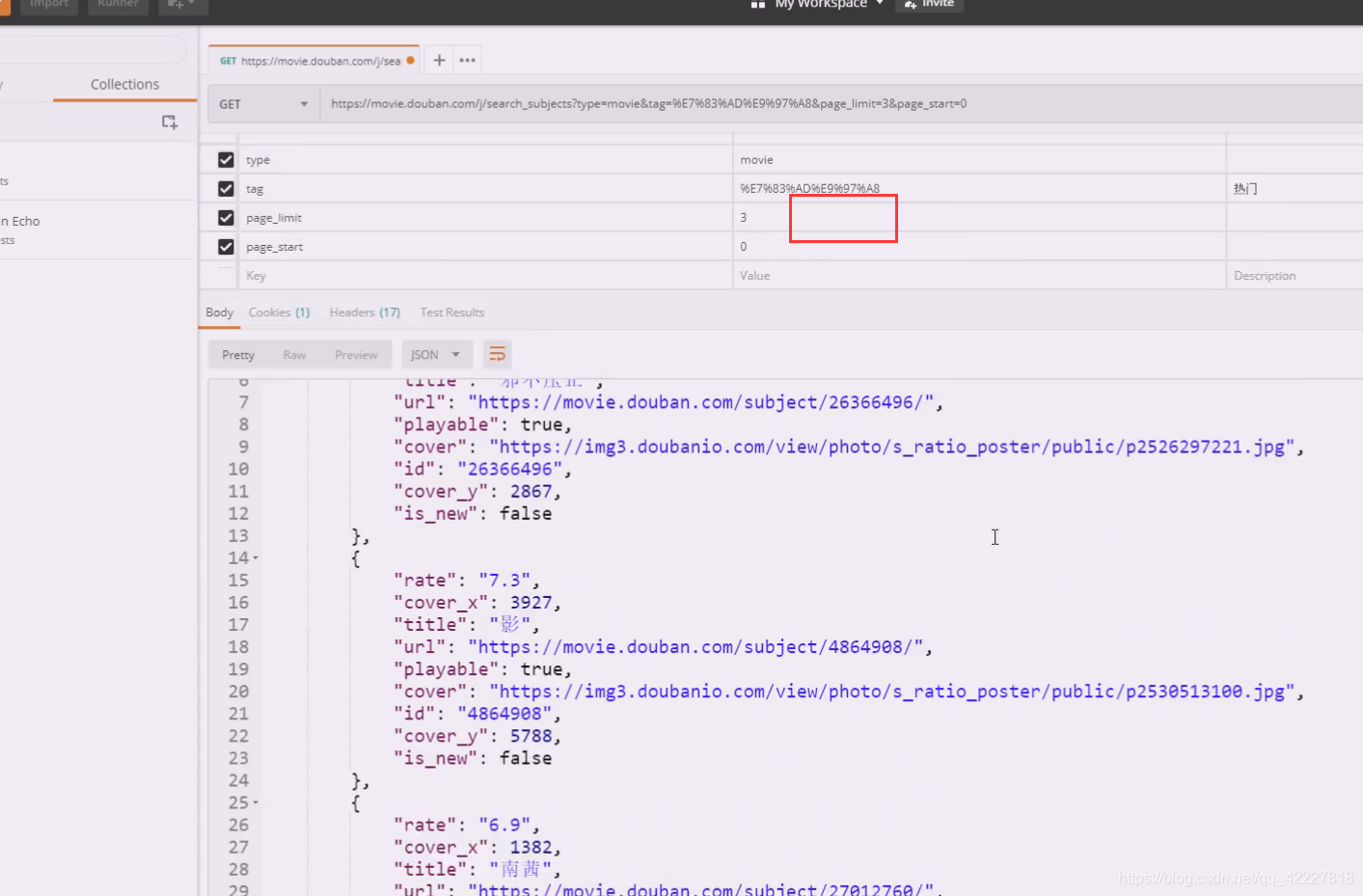
偏移三条试试

这数据拿来,下面就需要拼凑,page_start偏移,但是这样放在data就是post方法,所以还需要改成url。拼接起来,用这种方式来得到想要的数据
拿到这样基础的url
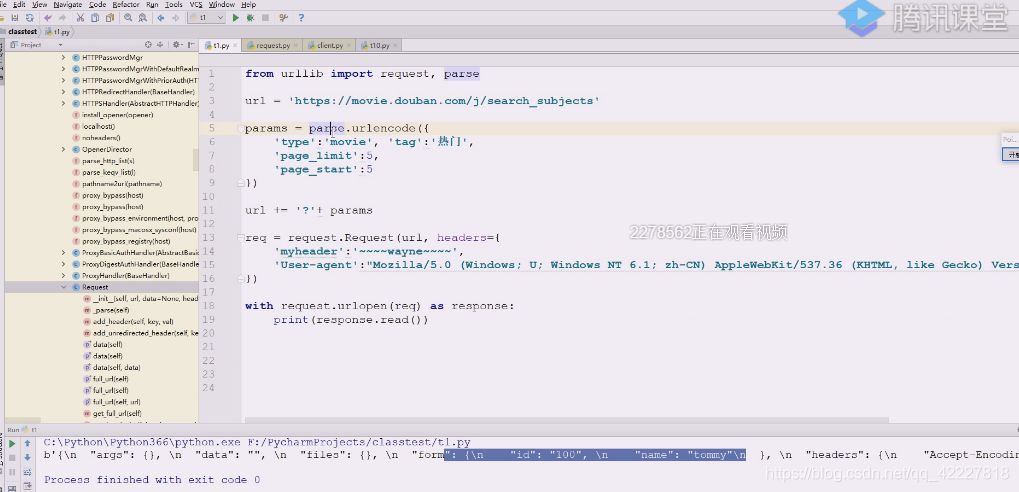
这样就得到数据了

可以比如今天爬取最近的喜剧电影看看,就当练个手

只要data写数据就是post方法

依然这些数据,我们在django里view只分析body里有没有我们喜欢的数据,根本没限制的方法,没限制方法其实是从总的获取了,有一些类似于django的框架,把post和查询字符串里提取出来,总称为*

总称为这样一个东西,在服务器端有request类,这个类型实例是从params里拿的,比如说这个属性里有查询字符串,通过post,body里的信息会合在一起,然后放在一个属性里和方法里,这个方法称为参数,根本不关心用get方法提交还是post方法,说到底还是不判断方法,get和post的数据放在不同的地方一个在body中,一个在url中,所以我们就从参数里取就行
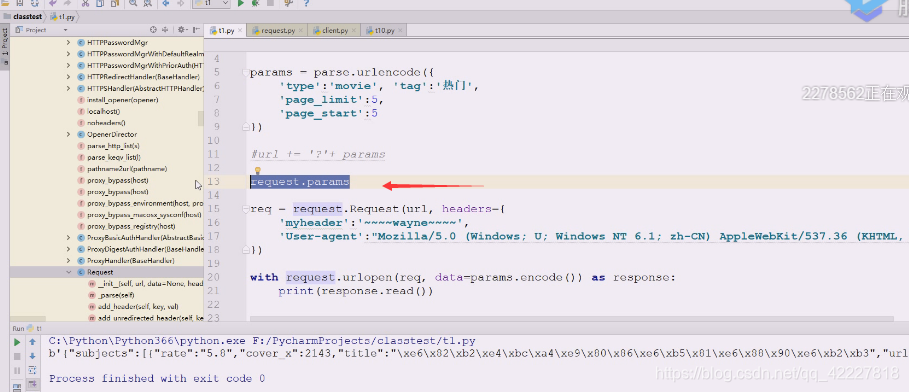
看到json应该可以用我们的simplejson转回来了,转换成字典想怎么遍历就怎么遍历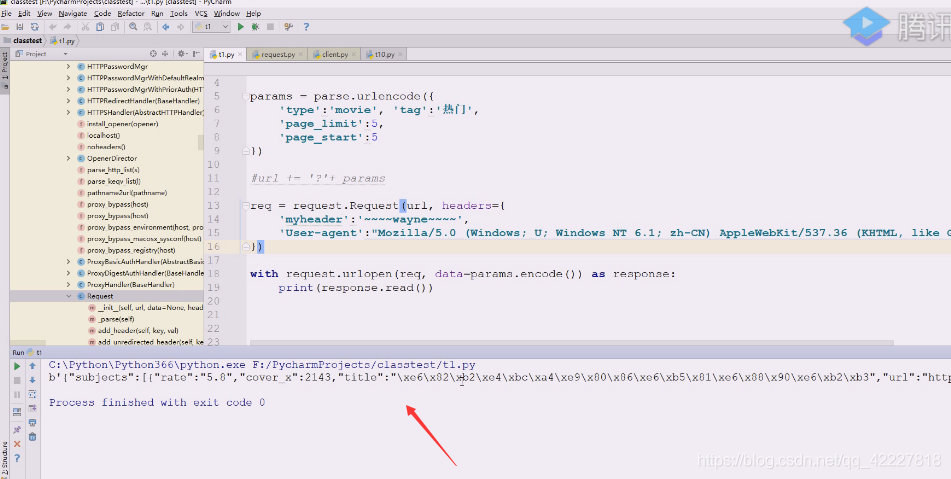


知乎号称是用python写的,但是整个程序并不是用几个程序就能撑起来的,是一整套架构
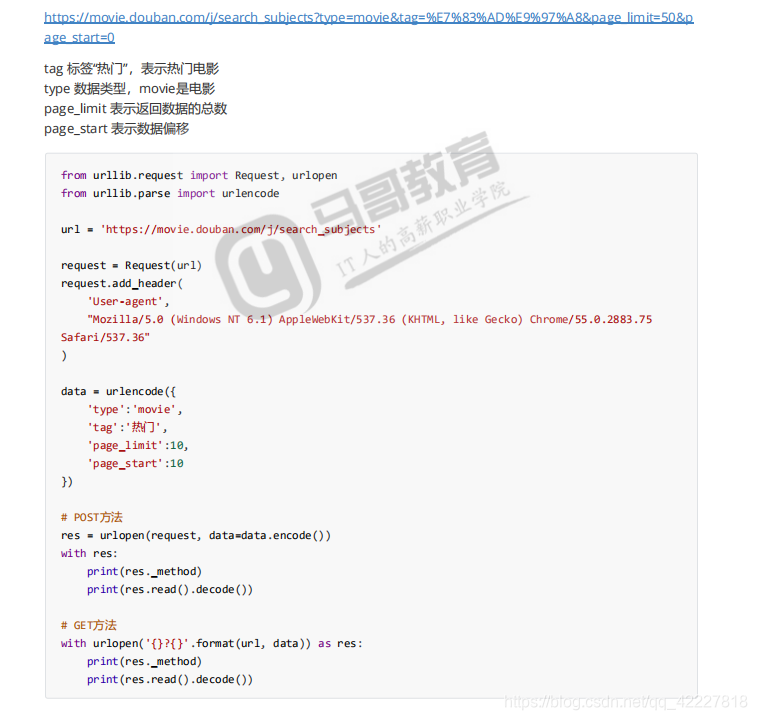
get和post方法都行,拿到数据就可以进行分析了,其实用日常用 标准库urllib就可以进行信息的爬取了,但是解析似乎做不了,解析要快还要兼容性好,这是个比较麻烦的东西
