

soup.div深度优先找第一个div

soup.div深度优先找第一个div,在它下面找深度优先第一个p标签
深度优先

它是要把你的整个结构解析了才开始找的,不是按照读取的顺序来的,是有顺序的
遍历直接节点需要一些东西

现在玩的是标签element,标签就是元素

这里有一个contents

attrs用字典包了下,说明是字典

告诉你是个标签,来源页面中的类,来自于页面中的元素的类

数逗号就是三个元素

应该是5个元素

找div下面的子把这个包含进来了

所以现在就被几个换行符断开了,所以这里面元素比我们想象的要多

打印孩子节点看看有没有什么区别

看看写成一个对象,是在bs4的element下

把div叫tag,下面写起来就方便了,写成对象的方式

看看这两个有什么区别

看一下contents

拿contents包了一下

contents应告诉我们是个列表,children,iter一包立马告诉我们是个生成器了
所以我们要用的时候就需要进行迭代,外面套个list,套了list就完全一样了

这里是一个子节点的迭代器,看到children下次访问的时候,里面是对contents的包装

遍历所有子孙节点,descendants后代,往下走,去看他的子子孙孙,告诉我们又是一个迭代器

看到yield了,又是遍历contents

contents去找,下面的一个个元素找,找完之后

找完之后把当前元素改改,我们再递归的时候也这么做,每次都把当前节点迭代出来

把子子孙孙全部打印出来

所以子孙,h3打印完,把h3内部的也打印了,递归将里面的文本类型的标签还有type类型的标签,以及字标签,和文本内容全部作为子孙打印


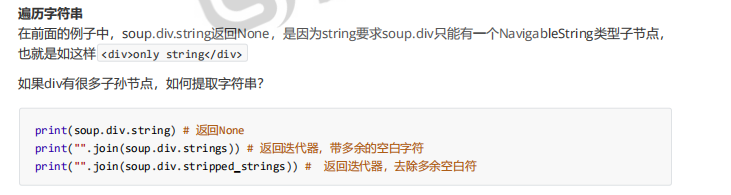
soup.div.string,这种方式是取里面的内容的,如果div有很多子孙节点,该如何提取内容
现在这样取是none

现在拿不到div里的汉字

试试div下的h3里的string,还是没拿到

h3里有个a就拿到了

h3的a里就一个python所以就取到了

这是取到一个标签的文本,但是要求这个里面只剩文本,有其他任何东西都不显示,里面只能是文本

看一下源码

tag下的string

这是一个便利的属性去拿到一个在标签内单独的string,也就是这个标签要求是单独的string

如果这里面的内容不是1,直接return none,如果不是文本型的也就没什么可看的

这里是唯一的文本标签就可以拿到内容

有很多子孙节点就提供了strings
查看源码

strings是个属性,这就是调用一个get方法,property第一个是get方法

访问这个属性就访问上面的all_strings了

遍历子子孙孙,最后把子子孙孙一个个yield出来了,把一个个子子孙孙内容往外抛出,这相当于递归所有元素的内部当中去,然后把里面的内容提取出来

还提供了另一个方法stripped_strings,剥离掉什么东西

我们当时在写property属性装饰器的时候,发现自己要定义一个函数,反复使用,而且里面的参数可以变化,有的时候就写成这样来定义一个属性

调用这个方法把true传进去,相当于告诉你必须把某些内容剥离,tripped掉

string是把无用的空白字符去掉,这样得到又是个迭代器,是 yield出来的

第一个是将所有的文本都提取出来,包括换行符。
第二个是将所有的空白字符stripped掉,空字符串之后就不输出了

这样就连成一体了,这些都是从contents基础上迭代下来的


如果想要h3的所有文本

最后把迭代器一连接就可以了

孩子叫children,祖先就是parent,提供了parent和parents


第一个p标签的parent

看一下parents

parents又是yield了

把自己的parent变成i,下回迭代后,又找到它的parent,变成i,parents是离自己最近的父打印,是个由近及远的过程

这样去迭代就可以打印了,最后一层到了html

如果想打印他们标签的名字,list包一下,把里面的每一个元素拿出来把name拿一下,拿标签名称,它的父一定是个标签,文本不作数

这里可以看的清除是谁


遍历兄弟节点

这个是容易出问题的地方


第一个p 标签下一个兄弟

两次

其实i中间加了一些东西,打印name看看,一个文本标签\N,就是换行符,没有标签名就是none

再下一个就是p标签了

它的父标签是div,div下的div要知道它的children有哪些,contents立即给一个列表,看的清楚点

p标签的下一个兄弟是它

再下一个才是p标签


意思是兄弟们,还是个迭代器,想要看还得套一个list

它向后的兄弟们,指的是这个意思

容易混淆的,下一个元素 next_element


再打印一次看看

再打印一个看看

刚才是按子的意思来next_sibling,这就有点像按所有子孙后代来的


换一h3看的清楚点

如果是h3的话,下一个,应该是a标签,下一个的下一个应该是python,再下一个就是高级班,再下一个就没了

相当于子子孙孙的标签都走一遍

如果有换行符,第一个就要走换行符,没有就是a标签,a标签内又是深度优先,下一步就要指的是a标签内部的元素,a标签后就是高级班。
所以是深度优先在里面去搜索的

这个就是看子子孙孙,把所有的遍历出来

更多场景下使用的是next_sibling,看的是下一个子,更多是这个,但是问题在于经常带上换行符

一个是子子孙孙都出来,一个是出来子

遍历文档数,就是往下遍历所有子孙,父,兄弟节点

在python还是用下划线,看到小驼峰比较变扭

看一下find_all源码

name里直接写标签名即可

这就是三个p标签全部返回了,find_all是理解返回

返回的是列表,.点相当于对列表进行操作

深度优先,跟soup.p一个道理

找一个就等于一个元素,就可以找下一个

找下面的一批

如果是find_all,这是个列表就不能像之前那样操作,只能for循环一个个拿出来操作

现在返回了三个

这里可以放5个参数,1名称(就是标签),2。

把name称为过滤器,赛到这里就是想要定位出,过滤出想要的标签,可以写字符串,还可以写正则表达式对象

下一个正则表达式,re.compile,以h开头数字结尾看看,这样就可以把找到的对象用列表返回

这是find_all

find_all里面去调用了下划线find_all

这些属性整在一起做判断,不同的方式做不同的处理

主要它是解决了不同的问题,解决不同参数配合之后如何去替你去搜索你要的标签了。
里面还可以写列表

正好是按照你的要求来的

现在这么写,列表是个容器里面写元素,这里就是写了一堆的,前面只是写单个标签搜索方法

这样也是可以的,这一块p标签就打印出来了

这里可以把你想要的对象都放进来

还可以这么写,看不到\n

也就是到目前为止打印出来的都是所有的tag对象,去源码看看

很多地方做了判断,如果是它才可以,迭代要求元素是tag才可以,现在text,limit,attrs,kwargs都没有传进来

随意这里返回一个tag实例是很正常的

如果是true和none都进这个


写成false也一样
默认值是none,不要写false,在后面一些操作回阻止它

过滤器除了name还有一种,如果要返回的标签必须是多值的,要求必须class必须多值

如果要找class多值的,现有基础上是要把所有标签都拿一遍,拿完之后遍历,遍历之后每个都是元素对象,元素对象class就可以拿到,用attrs就可以拿到,attrs拿到之后就需要判断class是不是一个列表,长度是不是大于1 的。(要求是要多个值的)
需要写一个函数

缺一个参数

这个参数叫tag

打印name

这个类型在上面引入过了

现在已经拿到tag对象,get class,相当于attr.get(class),拿它的属性,len包一下,最后应该返回true和false。
字典的get方法不抛出异常,没有就拿到none,none取长度len(不会这么写)

所以现在get拿不到给个缺省值,给个空,有就取出来看谁打

这样就拿到了
 其他就返回false即可,就是所谓的增强功能
其他就返回false即可,就是所谓的增强功能

过滤器里面,5种类型,标签本身,正则表达式,列表(里面可以写正则表达式可以写标签),复杂的时候会提供一个函数,这个函数经过测试需要有一个参数,这个参数类型实际上可以变的,由于find_all并没有提供其他参数,目前迭代都是tag类型,如果写严格就要判断 类型,然后再进一步的判断,字典的操作和逻辑表达式的比较,谁通过谁不通过就用true和false进行判断

这里就对所有标签都开绿灯

many_class相当于有选择性的开绿灯

现在用beatifulsoup提供的方法在遍历的时候,也是比较方便的,用这种也是比较容易搜索的,最后获得的都是元素对象,对元素(tag)对象进行操作
这就是过滤器如何去使用

