刚才是如何去搜索文档树,主要用的find系列方法可以让你去定位要找的元素们,find找一个,find_all找一批,find_all立即返回一个列表。
所有find系列参数都是一个原则,第一个叫name,官方称为过滤器filter,过滤器可以写5种形式:
1.标签,
2.正则
3.列表,
4.true或者none
5.函数


函数可以做增强功能,这个函数比较简单,经过测试,函数可以接收标签对象,可以对标签对象进行判断做相应的处理,最后返回true和false即可,有点像filter
如果用find系列函数定位的话可以像上面这么做
其实find_all函数内部还提供了很多参数
name已经测试过了


只要不是前面的关键字都被它收集,收集之后就会做为标签的属性


这个意思是只要不是前面的关键字都到kwargs,找id属性为main的标签

找bg1也是一个元素

现在是可以通过名称,现在试试正则表达式

找带id属性的标签,这样就找到所有的id,意思就是拥有id属性的标签有哪些

还有就是列表方式,套路都一样

可以通过谁是谁的方式来指定是什么样子,正则表达式还可以里面写或什么,列表也是或的意思

但是不支持函数,属性不支持函数,但是正则表达式引用就够了

id是个单值的

这是把id值取出来


这就是要求这两个属性都有,and关系

试试class属性,classs是python的keyword,keyword是不允许冲突,关键字是不允许冲突的。所以需要价格下划线

还有一个这个,也有class

找到class没有问题,但是现在想要精确匹配下

写成title是拿到了

highlight也拿到了

故意少个e看是什么方式匹配

用正则表达式,包含一下

这里要用class_因为class是keyword


如果真的写在一起,按顺序写的一样是没问题的,不一样就匹配不了,或者用正则表达式来解决,另外三个中的任何一个也可以

class是多值的,多值的任何一个都可以匹配,多值要全长匹配就要写的一模一样

另一个参数attrs,属性

这样也拿到了,要求属性里有id,id=first

这次写class就没有问题了,是个字符串


跟刚才用class方式的要一致

顺序不对也匹配不上,跟class一致


这样可以


说明是1个and条件
事实上attrs这样的写法也是很强大的,不用XPath也可以快速定位到元素


text指的是文本,一般结合字符串,正则表达式,列表,true可以完成很多功能

里面返回文本


返回文本\w+,,返回了所有标签,是从跟 /开始的

在p标签找文本符合指定的正则表达式

p标签有没有内容需要过滤下,或者链接过滤下有没有内容,或者span标签有没有文字,都可以通过这个方式去找,还可以把属性attrs加进去就变成了and条件,可以组合起来,所以查询能力很强

要求h开头或者p开头的,要求里面必须是英文的

这里很特别返回的是tag对象

一个所有元素返回的是tag对象,另一个返回的是文本

这是文档类型

返回的类型要关注下是否符合要求

还提供了一个limit,相当于给查询结构做一个限定


默认是递归的,false的话就直接找自己当前的了,不会再递归进去了,一般不会修改这个

soup.p深度优先搜索到第一个,返回一个tag对象,soup(‘p’)返回一个list,这是他们的差别

find-all可以简写成第二个的样子


第一个相当于find_all,第二个soup.img

这两个等价

这三个是一个意思,上面两个找到一个a,第三个是找所有的

第一个find_all省略就是第二个

这些就是各种参数,参数配合在一起可以查找我们要的元素,这就是提供的搜索文档树
搜索文档树还提供 了find方法,参数几乎和find_all一模一样

find_all返回一个列表,找不到空列表,find找到是一个元素对象,找不到就是none

有可能需要加try,找不到是none,none就不能get,注意抛出异常

CSS选择器
css选择器和xpath一样必须会上面的可以不会,只是通过上面的更加理解了元素包含什么东西,可以用可以不用,css和xpath是用beautifulsoup4最常用的来搜索我们要的数据的
css选择器和jQuery一样,用另一个方法,没有提供css方法,提供select方法,选择器选择,把css大多数用的选择器,往这里生搬一套就可以直接用了。。
标签名直接用,类名前加.点好,id名前加#,还有什么直接子,相邻兄弟选择器


类选择器

伪类只支持一种,这是直接子的选择器,相当于子标签里的所有p标签

查找nth-of-type意思


虽然是伪类,但是用p来限定,要提取p的类型,类型相同的第几个由你数字提供,第二个就变颜色了

它的意思是参照p的类型,选第二个

css3提供了很多这样的伪类,但是beautifulsoup只实现了这个

这是找divcontent下的p标签,跟他同类型的第二个


id选择器

p标签同时id=second

不管标签,找id=bg1

后代选择器

div下不管多少层,找p 标签

找到div下div,不管多少层找p标签

转换成XPath就是//div//div//p


中括号属性选择器,这意思是div下的p标签里的第一个与它响铃的标签有没有src

同一级里有没有img,img里有src

也就是先找到div下的第一个p标签,问直接兄弟里有没有src属性的,其他兄弟里有两个

属性选择器

有没有src,src是不是等于/

完全匹配

前缀匹配

src是否符合后缀
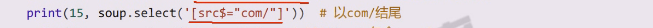
src是否包含

class是否等于它或者是其中某一个,波浪线~代表某一个

愿意用 soup提供的接口,或者css都可以


css选择器应该是重点,因为这里要用,jQuery也要用


这里用css选择器遍历整个树形结构找到想要的节点
这里伪类用的很少

这里叫直接子

子孙选择器,后代选择器,这里是任意层次的

属性比较多,前缀后缀,包含,这是img里的src,一般只关心图片的src

等于其中一个可以这么写

执行一下

最后一个也选择上了

写好一点就是加个引号

现在试过了两种方式,一种是文档的签后搜索,find和find_all,还有css选择器

string不能包含其他东西,只能是个文本

strings会迭代,将里面进行迭代,会保留空白字符

这里面会把空白字符删除
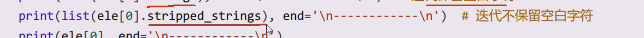
text本质上是get_text

看下text源码

all_strings 默认把空白字符也放进来,然后迭代以后拼接起来,里面什么都有,text代表这些文本的
单用text,跟直接调用get_text没什么区别

单独调用get_text等于getText

如果调用函数,还可以指定分隔符,指定要不要把这样的数据拿到,还可以提供types,不想要的内容

这是把文档第一行也进来了

去掉的话,我们放一个元素即可+个逗号


all_stirngs这边就要通过strip来决定要不要给你strip


如果text这个东西,直接用text是带空白字符的,如果要是不用就soup.div.get_text(strip=true)把空白字符去掉

用css选择器也好,还是现在提供的方式,还是find_all,总之只要找的是一个元素,我们要处理的都是一个个元素对象,我们一般都关心元素里的文本是什么,文本里有空白字符,如果要去掉就需要调用get也就是get_text,在这里传入strip=true


json解析
之前的豆瓣热门返回的是json,好歹需要把json.loads下变成一个字典,列表,一个json对应到列表和数组是没有问题的
拷贝链接地址

现在就需要import requests 链接到外面去了

response.text是连unicode编码都帮你做了,把text送进来,给soup处理,现在是把标签内容直接进来了,也可以放文件对象来读取

这个文本里就是html标签,这就是response的正文部分

然后下面进行处理

beautifulsoup还给我们套了个标签,所以这个时候用它分析不合适

可以用原生json来分析,simplejson也可以

这个是真正的json

把json。loads进来就变成字典了

找找评分大于8分的

用map和filter其实就可以,filter过滤顺便可以搞列表解析式,生成器,表达式都可以出来,有可以自己写for循环来判断

有个库叫jsonpath

就是把json类似于XPath一样来解析,但是不能用Xpath语法,重新定义了语法


*一切的根从$符号开始,类似jQuery,当前节点是@符号,是通配符

…相当于XPath的双斜杠


安装


官网

这里有一个XPath和jsonPAth的对比

他们两个的…表达意思完全不同


XPath不支持切片,jsnpath支持

谓语

jsonpath()是做计算的

xpath()是做分组

要看大于8分的有几个

套了一个大字典,里面是一个数组,数组里是一个对象,json格式的

装一下扩展,解析json的时候很多人喜欢用

现在拿到的数据有纯html和XML的,这种就用beautifulsoup和lxml来解析,但是现在遇到json,往往不能解析,都会转成python的数据结构来处理
直接访问是个包不能使用
需要包下的jsonpath

放入上面的subjects对象也就是loads后得到的,后面就是表达式,从/跟开始任意层次先找个title

$就是/根。根jQuery一样,…代表//双斜杠,任意层次下的title

rs就需要解决找到8分以上的
刚才打印的title,title和rate是兄弟关系

先转换下,找到分值大于8的对象出来

这是过滤器也就是条件

这是刚好需要的

官方的例子,book里面正好是个列表,到这里的子里面去找条件有这个情况的


要加字符串

现在已经找到大于8.0的分数,现在想要找到符合条件的title

找一下前10个到底有几个

试试切片

取两个

根XPath一样也是先锁定到要的数据附近,然后看如何处理
这些数据有些是异步的,拿不到的,ajax填充过来的

邪不压正怎么定位都在这里

查看源代码,邪不压中是找不到,也就是外面response回来的内容也是找不到的这四个字,因为邪不压中这些数据是发起了另外的请求,通过ajax来进行访问,访问到了通过js脚本动态加到DOM树里

这些数据是通过ajax动态增加到dom里的

all里面是通过同步请求返回的,异步的数据,直接用爬虫爬取是爬不到的

所以要分析异步链接,对它发起请求

现在是获得的数据正好是json了才装载起来,然后对里面数据进行分析




这里一开始写整数不行,加上字符串就行了

最后可以做个切片

XPath是掌握的重点

实例表需要熟悉


XPath的常用解析库就是lxml,可以解析html和xml,在其中使用XPath函数来进行对元素的定位和提取

但是这个lxml又被beautifulsoup包装了
beautifulsoup包装之后又提供一种很强大的访问方式,可以通过它的访问方式来访问,也可以通过提供的搜索功能find和find_all进行数据提取,


css选择器是非常重要的内容,把一些常用的选择器掌握即可


json解析作为了解,不强求

