首页
移动开发
物联网
服务端
编程语言
企业开发
数据库
业界资讯
其他
搜索
爬虫基础总结4
其他
2020-04-20 11:01:05
阅读次数: 0
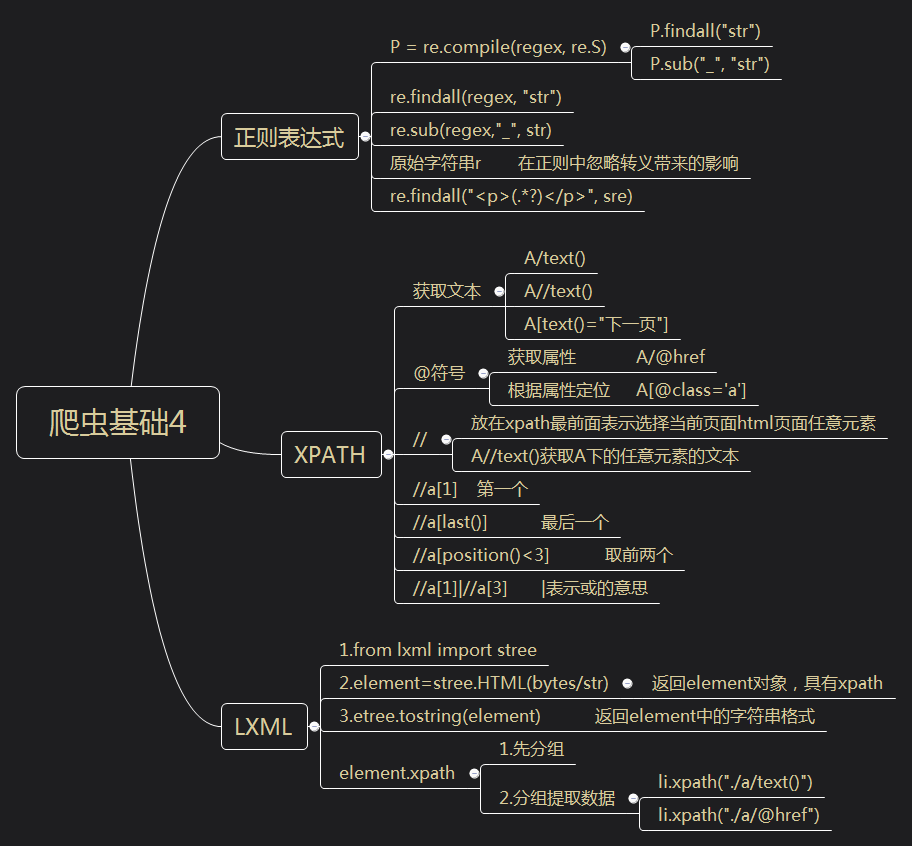
正则表达式
P = re.compile(regex, re.S)
P.findall("str")
P.sub("_", "str")
re.findall(regex, "str")
re.sub(regex,"_", str)
原始字符串r 在正则中忽略转义带来的影响
re.findall("<p>(.*?)</p>", sre)
xpath
获取文本
A/text()
A//text()
A[text()="下一页"]
@符号
获取属性 A/@href
根据属性定位 A[@class='a']
//
放在xpath最前面表示选择当前页面html页面任意元素
A//text()获取A下的任意元素的文本
//a[1] 第一个
//a[last()] 最后一个
//a[position()<3] 取前两个
//a[1]|//a[3] |表示或的意思
lxml
1.from lxml import stree
2.element=stree.HTML(bytes/str)
返回element对象,具有xpath
3.etree.tostring(element) 返回element中的字符串格式
element.xpath
1.先分组
2.分组提取数据
li.xpath("./a/text()")
li.xpath("./a/@href")
猜你喜欢
转载自
www.cnblogs.com/wsilj/p/12736407.html
爬虫基础总结4
爬虫总结4
爬虫基础总结3
【爬虫解析4】:requests总结
爬虫基础——BeautifulSoup4
爬虫基础教程 —— 4
python爬虫-基础用法总结
Python-爬虫基础总结
Java基础总结4
html基础总结4
JavaScript基础总结(4)
python爬虫基础(4:数据保存)
python爬虫实战:基础爬虫(使用BeautifulSoup4等) python爬虫实战:基础爬虫(使用BeautifulSoup4等)
完美Python爬虫入门基础总结
python爬虫基础知识的总结
4.Bootstrap基础总结
python基础总结4——文件
angular4 基础总结
UE4基础总结
JS基础总结(4)—— 异步
Python爬虫beautifulsoup4常用的解析方法总结
爬虫4
python爬虫基础知识——requests、bs4的使用
Python 爬虫之数据解析模块bs4基础
爬虫 之 BeautifulSoup4 基础教程
爬虫基础(4)发送请求之requests库的使用
python爬虫之BeautifulSoup4基础教程
Java基础知识总结(4)
学习总结——python的基础4(函数、模块)
JAVA基础知识总结4——IO
今日推荐
开源日报 | Chrome内置Gemini的意义不在于Gemini;中国AI追随之路的五大误区;ECharts创始人“下海”养鱼;谷歌I/O开发者大会什么都有,只是没有惊喜
微软回应中国区AI团队“打包赴美”传闻
基于大语言模型的开源知识库问答系统 MaxKB GitHub Star 数量突破 5,000 个!
美国拟限制 AI 大模型出口中国和俄罗斯
苹果将与 OpenAI 达成协议,将 ChatGPT 应用于 iPhone
openKylin 社区生态委员会第六次会议圆满召开
阿里云正式发布通义千问 2.5
Python 3.13 发布首个 Beta:实验性自由线程模式和 JIT、改进交互式解释器
Stack Overflow 拿我的代码去训练 AI 大模型,还封了我的账号
Pop!_OS 的 COSMIC 桌面完成 App Store 上架工作
《2024 年一季度互联网投融资运行情况》研究报告
报告:Django 仍然是 74% 开发者的首选
周排行
laravle中orm简单的增删改查
文本分类 特征选取之CHI开方检验
Spark核心编程-WordCount
大数据开发实战系列之电信客服(1)
读书笔记 - 把时间当作朋友 by 李笑来
python 笔记--if else
SpringBoot/Mybatis/Druid, 多数据源MultiDataSource配置思路
排序三个整数
redis集群搭建【2】-Windows中Redis集群搭建
STM32F030驱动TM1650点亮4联数码管
每日归档
更多
2024-05-16(6)
2024-05-15(24)
2024-05-14(0)
2024-05-13(18)
2024-05-12(0)
2024-05-11(38)
2024-05-10(38)
2024-05-09(35)
2024-05-08(42)
2024-05-07(14)