今天这个我就直接用CSDN的表格了,因为在PPT做,实在有点麻烦。
| time.time() | 获取当前时间戳(现在时间与1970年1月1日0时0分0秒的时间差(单位:秒)) |
|---|---|
| time.gmtime(secs) | 获取当前时间戳对应的struct_time对象 |
| time.localtime(secs) | 获取当前时间戳对应的本地时间的struct_time对象。结果与gmtime不同,UTC时间已自动转换为北京时间。 |
| time.ctime(secs) | 获取当前时间戳对应字符串的,内部会调用time.localtime()函数,返回的是当地时间。 |
| time.sleep(secs) | 强制等待secs秒。 |
| time.perf_counter() | 返回一个性能计数器的值(在分秒内),即一个具有最高可用分辨率的时钟,以测量短时间。它包括了在睡眠期间的时间,并且是系统范围的。返回值的引用点是未定义的,因此只有连续调用的结果之间的差异是有效的。 |
就是这么多,还有一个叫做时间格式化的东西,我待会儿再说。
这个time.perf_counter()的解释大家看着肯定很吃力,现在我来举个例子:
import time
start = time.perf_counter()
time.sleep(2)
end = time.perf_counter()
print(end-start)
说到底,就是一个计算时间的东西,但是非常精确。
因为内存以及一些其它的因素,所以每次执行的结果几乎都不同。
首先定义start为time.perf_counter()。这个函数如果就这么用是不能计时的,start的值是赋值的时候用的时间,并不是动态计时。因此在强制等待两秒后,需要再赋值一个变量,然后相减,得到运行的时间。
有些朋友会问,它不是只等待了2秒吗?怎么是1.999几,或者是2.00001之类与2及其接近的数?
这是个好问题,需要有两个解答。
大于2的结果:我刚刚也说了,有可能执行的时候内存或者什么问题。但这不是必然的,必然的是,变量赋值,解包之类的一系列动作,都是需要时间的,只不过计算机运行的很快,我们感觉不到。
小于2的结果:人有误差,计算机也有可能有。所以这是误差造成的,不过因为这个误差极小,所以对普通的计时没什么大影响。
现在说说时间格式化。
time.strftime()
该方法利用一个格式字符串,对时间格式进行表达。
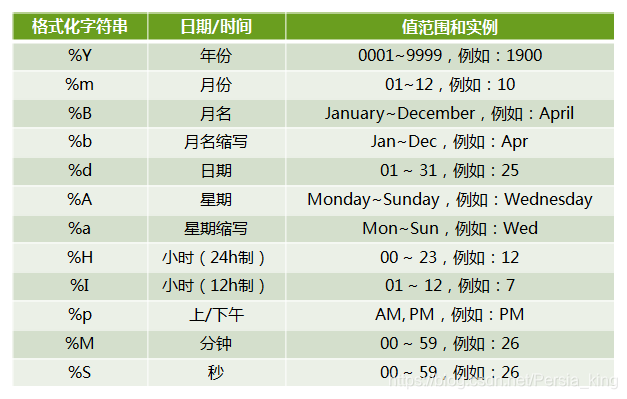
例:
import time
a = time.strftime('%Y-%m-%d %H:%M:%S')
print(a)
懂怎么用了吧。
time.strptime()
与strftime()方法相反,这个函数用于提取字符串中时间来生成strut_time对象,可以灵活地作为time模块的输入接口。
import time
times=time.strptime('19 April 2020','%d %B %Y')
print(times)
简单吧?
今天的标准库知识分享就到这了,有疑问的可以加我QQ:3418772261。喜欢的不妨点个赞,再加个关注,我们下一章再见!
