一、同一进程下的服务通讯和跨网络的通讯到底有什么不同
进程内的内存是共享的,skynet 是用 lua 沙盒来隔离服务状态,但是可以通过 C 库来绕过沙盒直接沟通。如果一个服务生产了大量数据,想传给您一个服务消费,在同一进程下,是不必经过序列化过程,而只需要通过消息传递内存地址指针即可。这个优化存在 O(1) 和 O(n) 的性能差别,不可以无视。
同一进程内的服务从底层角度来说,是同生共死的。Lua 的沙盒可以确保业务错误能够被正确捕获,而非常规代码不可控的错误,比如断电、网络中断,不会破坏掉系统的一部分而另一部分正常工作。所以,如果两个 actor 你确定在同一进程内,那么你可以像写常规程序那样有一个共识:如果我这个 actor 可以正常工作,那么对端协作的另一个 actor 也一样在正常工作。就等同于,我这个函数在运行,我当然可以放心的调用进程内的另一个函数,你不会担心调用函数不存在,也不会担心它永远不返回或是收不到你的调用。这也是为什么我们不必为同一进程内的服务间 RPC 设计超时的机制。不用考虑对方不相应你的情况,可以极大的简化编写程序的人的心智负担。比如,常规程序中,就没有(非 IO 处理的)程序库的 API 会在调用接口上提供一个超时参数。
同一进程内所有服务间的通讯公平共享了同一内存总线的带宽。这个带宽很大,和 CPU 的处理速度是匹配的。可以基本不考虑正常业务下的服务过载问题。也就是说,大部分情况下,一个服务能生产数据的速度不太会超过另一个服务能消费数据的速度。这种情况会造成消费数据的服务过载,是我们使用 skynet 框架这几年来 bug 出现最多的类型。而跨越网络时,不仅会因为生产速度和消费速度不匹配造成过载,更会因为传递数据的带宽和生产速度不匹配而过载。如果让开发者时刻去考虑,这些数据是投递到本地、那些数据是投递到网络,那么已经违背了抹平本地和网络差异这点设计初衷。
二、 harbor 模块
利用 4 个字节表示 actor 的地址,其高 8 位是节点编号,低 24 位是进程(节点)内的 id 。这样,在同一个系统中,不管处于哪个进程下,每个 actor (在 skynet 中被成为服务)都有唯一的地址。在投递消息时,无需关心目的地是在同一个进程内,还是通过网络来投递消息。
1、 master/slave 模式
不同的 skynet 节点的 harbor 间是如何建立起网络的呢?这依赖一个叫做 master 的服务。这个 master 服务可以单独为一个进程,也可以附属在某一个 skynet 节点内部(默认配置)。
master 会监听一个端口(在 config 里配置为 standalone 项),每个 skynet 节点都会根据 config 中的 master 项去连接 master 。master 再安排不同的 harbor 服务间相互建立连接。
最终一个有 5 个节点的 skynet 网络大致是这样的:
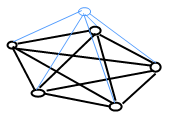
上面蓝色的是 master 服务,下面 5 个 harbor 服务间是互连的。master 又和所有的 harbor 相连。
节点间不再需要两条连接,而只用一条。每个节点加入网络(首先接入 master)后,由 master 通知它网络中已有几个节点,他会等待所有现存节点连接过来。所以连接建立后,就关闭监听端口。
如果再有新节点加入网络,老节点主动去连接新节点。这样做的好处是,已经在工作的节点不需要打开端口等待。
这套代码实现在 cmaster.lua 和 cslave.lua 中,取代原来的 service_master.c 和 service_harbor.c ,用 lua 编写有更大的弹性。这两个服务还负责同步 skynet 网络中的全局可见的服务名字,
2、服务ID skynet_handle.c
ID
- ID的定义是一个
uint32_t。 - ID在一个独立的进程中是唯一的。
- ID在多个Harbor组成的Skynet网中是唯一的。
- ID的高8位是harbor ID 。
- ID的底24为是此服务模块在这个进程中的唯一id。
- 每个ID对应一个独立的服务模块,拥有在此进程中唯一的服务名字。
服务ID管理者
handle_storage 源码
struct handle_name {
char * name;
uint32_t handle;
};
struct handle_storage {
struct rwlock lock;
uint32_t harbor;
uint32_t handle_index;
int slot_size;
struct skynet_context ** slot;
int name_cap;
int name_count;
struct handle_name *name;
};
static struct handle_storage *H = NULL;
结构体解说
- slot缓存
- slot成员指向一个保存服务上下文指针的缓存。实际上是一个数组,代码实现了数组大小不足的时候的自动扩容(X2)。
- slot_size 保存了slot缓存的当前大小。
- handle_index保存了slot数组的使用大小,slot中的每个服务按照他们install的顺序存放,如果有服务退出,后面的所有服务上下文自动前移。
- harbor 保持次进程的harbor ID。
- name缓存
- name 指向一个服务名字–ID 组合的数组缓存。 同样具备自动扩容功能(X2)。按照name排序(利用strcmp作为排序函数)。
- name_cap 记录缓存大小
- name_count 记录当前缓存使用大小。
提供接口
// 注册一个服务,返回他的ID uint32_t skynet_handle_register(struct skynet_context *ctx); // 利用ID注销一个服务 int skynet_handle_retire(uint32_t handle); // 注销全部服务 void skynet_handle_retireall(); // 利于ID获取服务上下文指针 struct skynet_context * skynet_handle_grab(uint32_t handle); // 利用服务名字获取服务ID (二分法) uint32_t skynet_handle_findname(const char * name); // 赋予一个ID名字 const char * skynet_handle_namehandle(uint32_t handle, const char *name) ; // 利用给点harbor id初始化 void skynet_handle_init(int harbor);
二、skynet 的集群方案cluster
它的工作原理是这样的:
在每个 skynet 节点(单个进程)内,启动一个叫 clusterd 的服务。所有需要跨进程的消息投递都先把消息投递到这个服务上,再由它来转发到网络。
在 cluster 集群中的每个节点都使用一个字符串来命名,由一个配置表来把名字关联到 ip 地址和端口上。理论上同一个 skynet 进程可以监听多个消息入口,只要用名字区分开,绑定在不同的端口就可以了。
为了和本地消息做区分,cluster 提供了单独的库及一组新的 API ,这个库是对 clusterd 服务通讯的浅封装。当然,也允许建立一个代理服务,把代理服务它收到的消息,绑上指定名字,转发到 clusterd 。这样就和之前的 master/slave 模式几乎没有区别了。
在过去,skynet 的集群限制在 255 个节点,为每个服务的地址留出了 8bit 做节点号。消息传递根据节点号,通过节点间互联的 tcp 连接,被推送到那个 skynet 节点的 harbor 服务上,再进一步投递。
这个方案可以隐藏两个 skynet 服务的位置,无论是在同一进程内还是分属不同机器上,都可以用唯一地址投递消息。但其实现比较简单,没有去考虑节点间的连接不稳定的情况。通常仅用于单台物理机承载能力不够,希望用多台硬件扩展处理能力的情况。这些机器也最好部署在同一台交换机下。
之前这个方案弹性不够。如果一台机器挂掉,使用相同的节点 id 重新接入 skynet 的后果的不可预知的。因为之前在线的服务很难知道一个节点下的旧地址全部失效,新启动的进程的内部状态已经不可能和之前相同。
所以,我用更上层的 skynet api 重新实现了一套更具弹性的集群方案。
和之前的方案不同,这次我不打算让集群间的通讯透明。如果你有一个消息是发放到集群内另一台机器中的某个服务的,需要用特别的集群消息投递 api 。节点本身用字符串名字,而不是 id 区格。集群间的消息用统一的序列化协议(为了简化协议)。
这套新的方案,可以参考 examples 下的 config.c1 和 config.c2 分别启动两个节点相互通讯。
如果使用这套方案,就可以不用老的多节点机制了(当然也可以混用)。为了简化配置,你可以将 skynet 配置为 harbor = 0 ,关闭老的多节点方案。这样,address standalone master 等配置项都不需要填写。
取而代之的是,配置一个 cluster 项,指向一个 lua 文件,描述每个节点的名字和地址。
新的 cluster 目前只支持一个 rpc call 方法 。用来调用远程服务。api 和 skynet.call 类似,但需要给出远程节点的字符串名字,且通讯协议必须用 lua 类型。
这套新方案可以看成是对原有集群的一个补充。当你需要把多台机器部署到不同机房,节点间的关系比较弱,只是少部分具名服务间需要做 rpc 调用,那么新的方案可能更加合适一些。因为当远程节点断开联系后,发起 rpc 的一方会捕获到异常;且远程节点用名字索引,不受 255 个限制。断开连接后,也可以通过重连恢复服务。
这种做法要求明确本地服务的调用和远程调用的区别。虽然远程调用的性能可能略低,但由于不像底层 harbor 那样把本地、远程服务的区别透明化,反倒不容易出问题。且 tcp 连接使用了更健壮的 socketchannel ,一旦连接断开,发起 rpc 的一方会收到异常,也可以重试(自动重连)。
而底层的 harbor 假设机器间是可靠连接,不会断开。而一旦内部网络不健康,很可能会导致整个系统无法正常工作。它的设计目的并不是为了提供弹性扩展的分布式方案,而是为了突破单机性能上限的问题。
两个跨机方案各有利弊,所以还请设计系统的时候权衡。只使用其中一个方案或是两个同时用,应该都有适用的场合。