在实际的软件开发过程中,“生产者/消费者模式”有着非常多的应用场景(GOF 那经典的23种模式主要是基于 OO 的)如:某个模块负责产生数据,这些数据由另一个模块来负责处理(此处的模块是广义的,可以是类、函数、线程、进程等)。产生数据的模块,就形象地称为【生产者】;而处理数据的模块,就称为【消费者】。
单单抽象出生产者和消费者,还够不上是生产者/消费者模式。该模式还需要有一个缓冲区处于生产者和消费者之间,作为一个中介。生产者把数据放入缓冲区,而消费者从缓冲区取出数据。大概的结构如下图。

什么不让生产者直接调用消费者的某个函数,引入缓冲区好处是:
- 解耦;
- 支持并发;(生产者不用等待消费者完成)
- 支持忙闲不均;
不同的缓冲区类型、不同的并发场景对于具体的技术实现有较大的影响。最传统、最常见的方式是单个生产者对应单个消费者,当中用【队列】(FIFO)作缓冲。
1、队列缓冲区:
在线程方式下,生产者和消费者各自是一个线程。生产者把数据写入队列头(以下简称 push),消费者从队列尾部读出数据(以下简称 pop)。当队列为空,消费者就稍息(稍事休息);当队列满(达到最大长度),生产者就稍息。整个流程并不复杂。
1)内存分配性能:
对于常见的队列实现:在每次 push 时,可能涉及到【堆内存】的分配;在每次 pop 时,可能涉及【堆内存】的释放。假如流量很大,频繁地 push、pop,那内存分配的开销就有可能很大。
2)线程同步性能:
由于多个线程共用一个队列,自然就会涉及到线程间诸如同步啊、互斥啊、死锁啊等等劳心费神的事情。同样,假如流量很大,线程同步的开销也会很大。
尽管队列有很多缺点,但由于队列是很常见的数据结构,大部分编程语言都内置了队列的支持、有些甚至提供了线程安全的队列(比如JDK 1.5引入的 ArrayBlockingQueue)。因此,假如你的数据流量不是很大,采用队列缓冲区的好处还是很明显的:逻辑清晰、代码简单、维护方便。比较符合 KISS 原则。
2、环型队列缓冲区:
当存储空间的分配/释放非常【频繁】并且确实产生了【明显】的影响,你才应该考虑环形缓冲区的使用。环形缓冲区 vs 队列缓冲区
1)外部接口相似
在介绍环形缓冲区之前,咱们先来回顾一下普通的队列。普通的队列有一个写入端和一个读出端。队列为空的时候,读出端无法读取数据;当队列满(达到最大尺寸)时,写入端无法写入数据。
对于使用者来讲,环形缓冲区和队列缓冲区是一样的。它也有一个写入端(用于 push)和一个读出端(用于 pop),也有缓冲区“满”和“空”的状态。所以,从队列缓冲区切换到环形缓冲区,对于使用者来说能比较平滑地过渡。
2)内部结构迥异
虽然两者的对外接口差不多,但是内部结构和运作机制有很大差别。队列的内部结构此处就不多啰嗦了。重点介绍一下环形缓冲区的内部结构。
大伙儿可以把环形缓冲区的读出端(以下简称 R)和写入端(以下简称 W)想象成是两个人在体育场跑道上追逐。当 R 追上 W 的时候,就是缓冲区为空;当 W 追上 R 的时候(W 比 R 多跑一圈),就是缓冲区满。为了形象起见,去找来一张图并略作修改,如下:
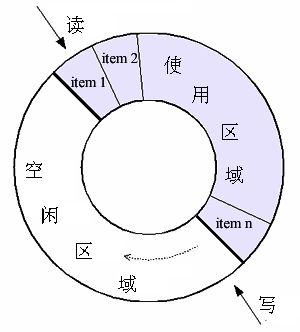
从上图可以看出,环形缓冲区所有的 push/pop 操作都是在一个【固定】的存储空间内进行。而队列缓冲区在 push 的时候,可能会分配存储空间用于存储新元素;在 pop 时,可能会释放废弃元素的存储空间。所以环形方式相比队列方式,少掉了对于缓冲区元素所用存储空间的分配、释放。这是环形缓冲区的一个主要优势。
和线程中的队列缓冲区类似,线程中的环形缓冲区也要考虑线程安全的问题。除非你使用的环形缓冲区的库已经帮你实现了线程安全,否则你还是得自己动手搞定。
3、双缓冲:
“双缓冲区”是一个应用很广的手法。该手法用得最多的地方想必是屏幕绘制相关的领域(主要是为了减少屏幕闪烁)。
1)为什么用双缓冲:
上面介绍的生产者-消费者模型中两个问题,其中“内存分配的开销”已经在介绍环形缓冲区的时候解决了,而今天要介绍的双缓冲区,就是冲着同步/互斥的开销来的。
2)双缓冲原理:
所谓“双缓冲区”,故名思义就是要有俩缓冲区(简称 A 和 B)。这俩缓冲区,总是一个用于生产者,另一个用于消费者。当俩缓冲区都操作完,再进行一次切换(先前被生产者写入的转为消费者读出,先前消费者读取的转为生产者写入)。由于生产者和消费者不会同时操作同一个缓冲区(不发生冲突),所以就不需要在读写每一个数据单元的时候都进行同步/互斥操作。(空间换时间的优化思路)
但是光有俩缓冲区还不够。为了真正做到“不冲突”,还得再搞两个互斥锁(简称 La 和 Lb),分别对应俩缓冲区。生产者或消费者如果要操作某个缓冲区,必须先拥有对应的互斥锁。
3)双缓冲区的几种状态:
A、俩缓冲区都在使用的状态(并发读写)
大多数情况下,生产者和消费者都处于并发读写状态。不妨设生产者写入 A,消费者读取 B。在这种状态下,生产者拥有锁 La;同样的,消费者拥有锁 Lb。
由于俩缓冲区都是处于独占状态,因此每次读写缓冲区中的元素(数据单元)都【不需要】再进行加锁、解锁操作。这是节约开销的主要来源。
B、单个缓冲区空闲的状态
由于两个并发实体的速度会有差异,必然会出现一个缓冲区已经操作完,而另一个尚未操作完。不妨假设生产者快于消费者。
在这种情况下,当生产者把 A 写满的时候,生产者要先释放 La(表示它已经不再操作 A),然后尝试获取 Lb。由于 B 还没有被读空,Lb 还被消费者持有,所以生产者进入发呆(Suspend)状态。
C、缓冲区的切换
接着上面的话题。过了若干时间,消费者终于把 B 读完。这时候,消费者也要先释放 Lb,然后尝试获取 La。由于 La 刚才已经被生产者释放,所以消费者能立即拥有 La 并开始读取 A 的数据。而由于 Lb 被消费者释放,所以刚才发呆的生产者会缓过神来(Resume)并拥有 Lb,然后生产者继续往 B 写入数据。
经过上述几个步骤,俩缓冲区完成了对调,变为:生产者写入 B,消费者读取 A。
4)潜在问题:
假如把前面介绍的操作步骤调换一下顺序:生产者或消费者在操作完当前的缓冲区之后,先去获取另一个缓冲区的锁,再来释放当前缓冲区的锁。那会咋样捏?一旦两个并发实体【同时】处理完各自缓冲区,然后【同时】去获取对方拥有的锁,那就会出现典型的死锁(死锁的详细解释参见“这里”)场景。它俩从此陷入万劫不复的境地。
5)应用:
某些编程语言或者程序库提供了的线程安全的缓冲区(比如 JDK 1.5 引入的 ArrayBlockingQueue)。由于这种缓冲区会自动为每次的读写进行同步/互斥,所以就把双缓冲的优势抵消掉了。因此,大伙儿在进行缓冲区选型的时候要避开这类缓冲区。