一、无序关联容器
说到无序关联容器他是关联容器中的一种,其底层使用链式哈希表来加以实现的,关于链式哈希表在后序的博文中,我会持续更新,请各位读者敬请期待。
关于链式哈希表他有一个非常重要的特点,就是他的增删查的效率是O(1)。
在关联容器中,我们总体上分为了set和map.set表示集合,存放关键字。map表示映射表,存放键值对[key,value]。
在无序关联容器中
set又分了unordered_set ——无序的单重集合,unordered_multiset——无序的多重集合。
map又分了unordered_map ——无序的单重映射,unordered_multimap——无序的多重映射。

1、unordered_set 详解
(1)insert插入
首先我们定义一个无序单重集合。他存储key值不会重复的元素
unordered_set<int> set1;
然后循环插入元素
for (int i = 0; i < 50; i++)
{
set1.insert(rand() % 20 + 1);
}
对于关联容器的insert只需要给入插入元素的值即可,不需要像vector/deque/list还要给出迭代器。因为其底层是哈希表对于该插入的位置有相应的函数计算
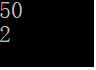
这时,我们来查看此容器的大小和key为15的元素个数
cout << set1.size() << endl;
cout << set1.count(15) << endl;
结果如下:

虽然我们输入了50个数,因为是单重集合,所以其自动去除了重复的元素,且key为15的元素个数肯定也是1.
但是同样是上述代码的插入,如果我们将其改成了无序多重集合,定义如下:
unordered_multiset<int> set1;
输出结果如下:
因为其存储key值是会重复的元素。所以50个元素全部都存储进去了,且key为15的元素个数就是相应重复的个数了。
(2)遍历集合容器
方式一:采用迭代器遍历
auto it1 = set1.begin();
for (; it1 != set1.end(); ++it1)
{
cout << *it1 << " ";
}
方式二:采用for each遍历
for (int v : set1)
{
cout << v << " ";
}
(3)查找、删除元素
方式一:用迭代器遍历去找元素,找到了删除
for (it1 = set1.begin(); it1 != set1.end(); )
{
if (*it1 == 30)
{
it1 = set1.erase(it1);//调用erase,it1迭代器就失效了,所以要对迭代器更新
}
else
{
++it1;
}
}
方式二:使用函数find
find如果找不到元素会返回end迭代器
it1 = set1.find(20);
if (it1 != set1.end())
{
set1.erase(it1);
}
(4)应用
题目要求:在10万整数中,在海量数据中查找重复的元素
分析:因为在此要求我们在海量数据中只是找到重复的元素值即可,所以采用set是一个非常好的方法,具体代码实现如下:
int main()
{
const int ARR_LEN = 100000;
int arr[ARR_LEN] = { 0 };
for (int i = 0; i < ARR_LEN; ++i)
{
arr[i] = rand() % 10000 + 1;
}
unordered_set<int> set;
for (int v : arr)//O(n)
{
set.insert(v);//O(1)
}
for (int v : set)
{
cout << v << " ";
}
cout << endl;
return 0;
}
2、unordered_map详解
首先,我们来了解一下map的性质,与set不同的是map存放的是键值对[key,value]所以把其打包成一个类型,才能插入到map表中
其类型定义如下:
struct pqir
{
first;
second;
}
其中的first就表示的是key,second表示的是value
(1)insert插入
首先,我们还是来定义一个无序单映射map1.
unordered_map<int, string> map1;
方式一:使用make_pair
map1.insert(make_pair(1000, "张三"));
方式二:因为插入的为一个结构体,所以可以用以下方式
map1.insert({ 1010,"李四" });
map1.insert({ 1020,"王五" });
注意!单重映射表不允许键重复,但是多重映射表可以
所以,因为之前已经有了一个key为1000的张三存在。所以在key为1000的位置插入元素是无效的,如下
map1.insert({ 1000,"王凯" });
方式三:使用中括号
其中中括号运算符重载函数 如下:
V& operator[](const K &key)
{
insert({key,V()});
}
仔细观察上述函数,如果key不存你在,他会插入一对数据[key,string()]
例如:
map1[2000] = "刘硕";
相当于语句map1.insert({ 2000,“刘硕” });
还有修改的作用,map1[1000] = “张三2”;
(2)查找
方式一:使用迭代器查找
auto it1 = map1.find(1030);
if (it1 != map1.end())
{
cout << "key:" << it1->first << "value:" << it1->second << endl;
}
方式二:map提供了中括号运算符重载函数 可以查找
cout << map1[1000] << endl;
(3)应用
题目要求:10万整数中,统计哪些数字重复了,并且统计数字重复的次数
分析:这不止是要查找数字,还要统计哪些数字重复了,所以要用到多重映射表map
代码如下:
int main()
{
const int ARR_LEN = 100000;
int arr[ARR_LEN] = { 0 };
for (int i = 0; i < ARR_LEN; ++i)
{
arr[i] = rand() % 10000 + 1;
}
unordered_map<int, int>map1;//分别代表值和重复次数
for (int k : arr)
{
auto it = map1.find(k);
if (it == map1.end())//表示这个数字就没出现过
{
map1.insert({ k,1 });
}
else
{
it->second++;
}
}
//打印
for (const pair<int, int>&p : map1)//定义常引用通过for each来遍历容器而不是修改容器
{
if (p.second > 1)
{
cout << "key:" << p.first << "count:" << p.second << endl;
}
}
return 0;
}
上述代码还有改进的地方
放进一:
在for each寻找重复值的代码中,我们可以用map1[k]++; 一句代码实现
改进二:
打印函数还有如下的迭代器实现方法
auto it = map1.begin();
for (; it != map1.end(); ++it)
{
if (it->second > 1)
{
cout << "key:" << it->first << "count:" << it->second << endl;
}
}
二、有序关联容器
说到有序关联容器他是关联容器中的一种,其底层使用红黑树来加以实现的,关于红黑树在后序的博文中,我会持续更新,请各位读者敬请期待~
关于红黑树,他的增删查的时间复杂度是O(log2n),表示的是树的高度。
在有序关联容器中,set又分为set和multiset,map分为map和multimap
1、set详解
(1)元素为普通类型
关于他的增删查改和无序单重集合差不多,首先,他的定义为
set<int> set1;
for (int i = 0; i < 20; ++i)
{
set1.insert(rand() % 20 + 1);
}
因为红黑树有其自己的性质,只需要给其要插入的元素即可
他的遍历就是对底层红黑树的一个中序遍历结果
for (int v : set1)
{
cout << v << " ";
}
(2)元素是自定义类型
上面的讲解是对于普通类型的操作方式,和无序的差不多,不在赘诉。下面,我们来讲解一下在有序集合里面存放自定义 Sdudent类型 。
首先,我们定义一个Student的类
class Student
{
public:
Student(int id,string name):_id(id),_name(name){}
private:
int _id;
string _name;
friend ostream& operator<<(ostream& out, const Student& stu);
};
ostream& operator<<(ostream& out, const Student& stu)
{
out << "id" << stu._id << "name:" << stu._name << endl;
return out;
}
在主函数的定义为
int main()
{
set<Student> set1;
set1.insert(Student(1000, "张雯"));
set1.insert(Student(1001, "李广"));
return 0;
}
但是此时的运行结果如下:

因为是一个自定义的类型,在进行比较的时候要提供一个默认的小于运算符重载函数
bool operator<(const Student& stu)const//按id进行排序
{
return _id < stu._id;
}
这时遍历
for (auto it = set1.begin(); it != set1.end(); ++it)
{
cout << *it << endl;
}
运行结果如下:

2、map详解
还是刚才的Student自定义类型,在map中他的定义如下:
int main()
{
map<int, Student> stuMap;
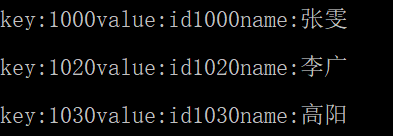
stuMap.insert({ 1000,Student(1000,"张雯") });
stuMap.insert({ 1030,Student(1030,"高阳") });
stuMap.insert({ 1020,Student(1020,"李广") });
return 0;
}
(1)删除
stuMap.erase(it) stuMap.erase(1020)
(2)查询
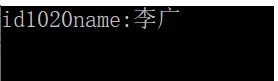
方法一:stuMap.find(key)
方法二:使用中括号
cout << stuMap[1020] << endl;
但是基于上面的代码,这样运行结果如下:

因为,对于map表如果值我自定义类型,则需要提供一个默认的构造函数 如下:
Student(int id=0, string name="") :_id(id), _name(name) {}
这里也就不需要写小于运算符重载了,因为其是按照key来排序的,知道如何给整数来进行排序
调整后运行结果如下:
(3)遍历输出
auto it = stuMap.begin();
for (; it != stuMap.end();++it)
{
cout << "key:" << it->first << "value:" << it->second << endl;
}
运行结果