最近项目开发需要学习到Altera的增量式编译,因此进行了一些学习,将个人的一些见解记录在此。下面的结论可能有错误或者偏驳之处,希望园友们看后多多讨论一起进步,还请各位多多指教。
Altera的增量式编译主要是设置partition和logicock两种区域规划进行协同工作。partition是逻辑区块划分,也就是将我们的整个工程从逻辑上划分成不同的模块,各个模块之间以接口进行连接,模块内部逻辑互相独立。logiclock是物理区块划分,也就是在我们工程的布局布线过程中对芯片实际资源区域使用的划分。两种区块划分独立来说,logiclock侧重于对布局布线阶段的规划,patition侧重于对逻辑综合的规划。因此两者结合来用效果会十分显著。
具体的协同使用基本的思路应该是差不多的:首先对整个工程进行逻辑上的划分,在quartus软件中我们可以通过Project Navigator>>Hierarchy内的工程层次来设置partition;然后我们可以根据引脚的分配情况,PLL的使用情况,对不同的模块在chip planner内划分不同的实际芯片区域进行布局布线;设置完成之后我们进行工程的全编译,这个时候我们就可以导出之前设置的partition,相当于是自己定制的IP核,只有接口没有内部逻辑,导出模式有多种,比较常用的就是post-fit,也就是将逻辑和布局布线完全固定,这样我们移植到大的项目去就能够完全保证时序优化结果。
个人认为在设计过程中,增量式编译的主要作用有以下几个:
- 工程较大时,各个模块独立设计,最后整合导入,各个独立的模块设置为增量式编译partition,结合LogicLock物理区域划分来进行系统设计,保证各个模块独立的优化结果;
- 工程编译时间较长时,将不需要改动的部分设置成增量式编译的partition,类型改成post-fit型,源码没有改动时,不会消耗时间重新编译布线,这样较大的工程就能够花费较短的时间综合和布局布线;
- 做时序优化时,结合增量式编译,有时可以加快时序优化的效率。
这里主要是简单的谈谈对增量式编译的理解,没有深入探讨软件的使用以及设置。
下面记录一下几个细节点,以待今后的使用:
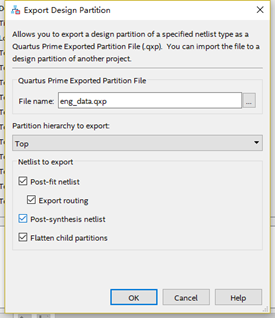
导出partition的选项设置。如下图所示,导出partition有以下几个选项,各个选项勾选与否的含义分别为:
- 只勾选post-synthesis,导出的模块就只有综合的结果,不包括布局布线结果;
- 只勾选post-fit,导出的模块就包含综合的结果以及仅仅布局的结果;
- 勾选post-fit,同时勾选ecxport routing,导出的模块就包含综合的结果以及布局和布线的结果;这里要注意的是post-fit包含的是fitter之后的结果,fitter包括placement(布局)和routing(布线)的结果。
在导入partition的过程中,需要选择冲突解决方式。
- 这里的冲突主要是针对导入的partition模块中包含的布局布线结果与要导入到的目的工程中可能存在的logiclock区域限制的冲突。也就是说我们工程中预留出规划的模块的物理区域与要导入的partition实际包含的布局布线的物理区域不匹配导致冲突。
在本工程中为了节省编译时间设置partition加上post-fit类型设置时,如果源码没有发生改变,则软件不会去编译和布线,但是源码一旦发生了改变,则仍然会进行重新的布局布线。