5.决策树的划分依据三——基尼值和基尼指数
5.1概念
CART 决策树 [Breiman et al., 1984] 使用"基尼指数" (Gini index)来选择划分属性.
CART 是Classification and Regression Tree的简称,这是一种著名的决策树学习算法,分类和回归任务都可用
**基尼值Gini(D):**从数据集D中随机抽取两个样本,其类别标记不一致的概率。所以,Gini(D)值越小,数据集D的纯度越高。
数据集D的纯度可用基尼值来度量:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-sPQWNZqH-1578897140365)(file:///C:/Users/%E6%B8%85%E9%A3%8E/Desktop/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%E8%AF%BE%E4%BB%B6/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%E8%AE%B2%E4%B9%89/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%EF%BC%88%E7%AE%97%E6%B3%95%E7%AF%87%EF%BC%89/%E5%86%B3%E7%AD%96%E6%A0%91%E7%AE%97%E6%B3%95/images/%E5%85%AC%E5%BC%8F9.png)]](https://img-blog.csdnimg.cn/20200113143240138.png)
p**k=DCk, D为样本的所有数量,C^kC**k为第k类样本的数量。
**基尼指数Gini_index(D):**一般,选择使划分后基尼系数最小的属性作为最优化分属性。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-sBrVFW9u-1578897140372)(file:///C:/Users/%E6%B8%85%E9%A3%8E/Desktop/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%E8%AF%BE%E4%BB%B6/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%E8%AE%B2%E4%B9%89/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%EF%BC%88%E7%AE%97%E6%B3%95%E7%AF%87%EF%BC%89/%E5%86%B3%E7%AD%96%E6%A0%91%E7%AE%97%E6%B3%95/images/%E5%85%AC%E5%BC%8F11.png)]](https://img-blog.csdnimg.cn/20200113143244538.png)
现在我们来总结一下CART的算法流程
while (当前节点"不纯"):
1.遍历每个变量的每一种分割方式,找到最好的分割点
2.分割成两个节点N1和N2
end while
每个节点足够"纯"为止
6.内容有点复杂,做个小总结吧!
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DRBfAa2x-1578897140373)(file:///C:/Users/%E6%B8%85%E9%A3%8E/Desktop/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%E8%AF%BE%E4%BB%B6/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%E8%AE%B2%E4%B9%89/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%EF%BC%88%E7%AE%97%E6%B3%95%E7%AF%87%EF%BC%89/%E5%86%B3%E7%AD%96%E6%A0%91%E7%AE%97%E6%B3%95/images/%E5%85%AC%E5%BC%8F17.png)]](https://img-blog.csdnimg.cn/20200113143351889.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L1dhbmdUYW9UYW9f,size_16,color_FFFFFF,t_70)
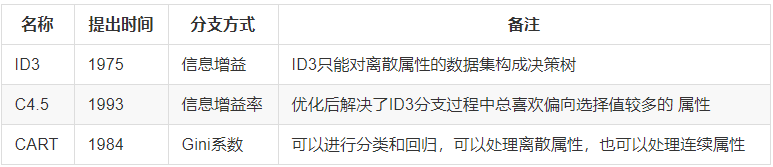
6.1 ID3算法
存在的缺点
- ID3算法在选择根节点和各内部节点中的分支属性时,采用信息增益作为评价标准。信息增益的缺点是倾向于选择取值较多的属性,但在有些情况这些属性不会提供太多有价值的信息。
- ID3算法只能对描述属性为离散型的数据集构造决策树。
6.2 C4.5算法
做出的改进
- 用信息增益率来选择属性
- 可以处理连续数值型属性
- 采用了后剪枝方法
- 缺失值的处理
C4.5算法的优点:
- 产生的分类规则容易理解,准确率较高。
C4.5算法的缺点:
- 在构造树的过程中,需要对数据集进行多次的顺序扫描和排序,因而导数效率低。
- C4.5只适合能够驻留与内存的数据集,当数据集太大无法在内存容纳的时候无法运行。
6.3 CART算法
CART算法相比C4.5算法的分类方法,采用了简化的二叉树模型,同时特征选择了采用近似的基尼指数来简化计算。
C4.5不一定是二叉树,但CART一定是二叉树。
扩展几个知识点:
1)**多变量决策树:**无论是ID3,C4.5还是CART,在做特征选择的时候都是选择最优的一个特征来做分类决策,但是大多数,分类决策不应该是由某一个特征决定的,而应该是由一组特征决定的。这样决策得到的决策树更加准确。这个决策树叫做多变量决策树。在选择最优特征的时候,多变量决策树不是选择某一个最优特征,而是选择最优的特征的一个特征线性组合来做决策。这个算法的代表是OC1。
如果样本发生一点点的改动,就会导致树的结构的剧烈改变,这个可以通过集成学习里面的随机森林方法解决。
2)决策树变量的两种类型:
- 数字型(Numeric):变量类型是整数或浮点数,如前面例子中的“年收入”。用“>=”,“>”,“<”或“<=”作为分割条件(排序后,利用已有的分割情况,可以优化分割算法的时间复杂度)。
- 名称型(Nominal):类似编程语言中的枚举类型,变量只能从有限的选项中选取,比如前面例子中的“婚姻情况”,只能是“单身”,“已婚”或“离婚”,使用“=”来分割。
3)如果评估分割点的好坏?
如果一个分割点可以将当前是所有节点分为两类,使得每一类都很”纯“,也就是同一类的记录比较多,那么就是一个好分割点。
构建决策树采用贪心算法,只考虑当前纯度差最大的情况作为分割点。
7.cart剪枝
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-exHxFWC6-1578897140374)(file:///C:/Users/%E6%B8%85%E9%A3%8E/Desktop/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%E8%AF%BE%E4%BB%B6/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%E8%AE%B2%E4%B9%89/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%EF%BC%88%E7%AE%97%E6%B3%95%E7%AF%87%EF%BC%89/%E5%86%B3%E7%AD%96%E6%A0%91%E7%AE%97%E6%B3%95/images/cart.png)]](https://img-blog.csdnimg.cn/20200113143436144.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L1dhbmdUYW9UYW9f,size_16,color_FFFFFF,t_70)
-
图形描述
- 横轴表示在决策树创建过程中树的结点总数,纵轴表示决策树的预测精度。
- 实线显示的是决策树在训练集上的精度,虚线显示的则是在一个独立的测试集上测量出来的精度。
- 随着树的增长,在训练样集上的精度是单调上升的, 然而在独立的测试样例上测出的精度先上升后下降。
-
出现这种情况的原因:
- 原因1:噪声、样本冲突,即错误的样本数据。
- 原因2:特征即属性不能完全作为分类标准。
- 原因3:巧合的规律性,数据量不够大。
1.常用的剪枝方法
2.1 预剪枝
(1)每一个结点所包含的最小样本数目,例如10,则该结点总样本数小于10时,则不再分;
(2)指定树的高度或者深度,例如树的最大深度为4;
(3)指定结点的熵小于某个值,不再划分。随着树的增长, 在训练样集上的精度是单调上升的, 然而在独立的测试样例上测出的精度先上升后下降**。**
2.2 后剪枝:
后剪枝,在已生成过拟合决策树上进行剪枝,可以得到简化版的剪枝决策树。
