作者:tuyunshan
RAMCloud技术交流QQ群:295905581
RAMCloud源码分析(三)
1. 概述
这一部分主要是针对RAMCloud系统中Server进行分析,而本节的侧重点是内存管理,对应其FAST’14上Log-structured Memory for DRAM-based Storage的那篇论文。首先,基于日志结构的内存管理属于copying allocators。主要是为了实现两个方面的需求:第一,通过copy object能够消除碎片;第二,不需要全局的扫描,就可以实现垃圾回收。第一个需求,很容实现,仅仅通过copy就可以实现,而第二需求的实现,则需要利用到index structure来快速定位segment(在RAMCloud有天然的index,那就是HashTable)。因此,接下的将从HashTable与Segment两方面阐述一下内存管理机制。
2. mmap系统调用
在讲HashTable与Segment之前想先说一下mmap函数,因为在RAMCloud系统中所有的内存申请,都是通过它来实现的。
2.1 mmap原理
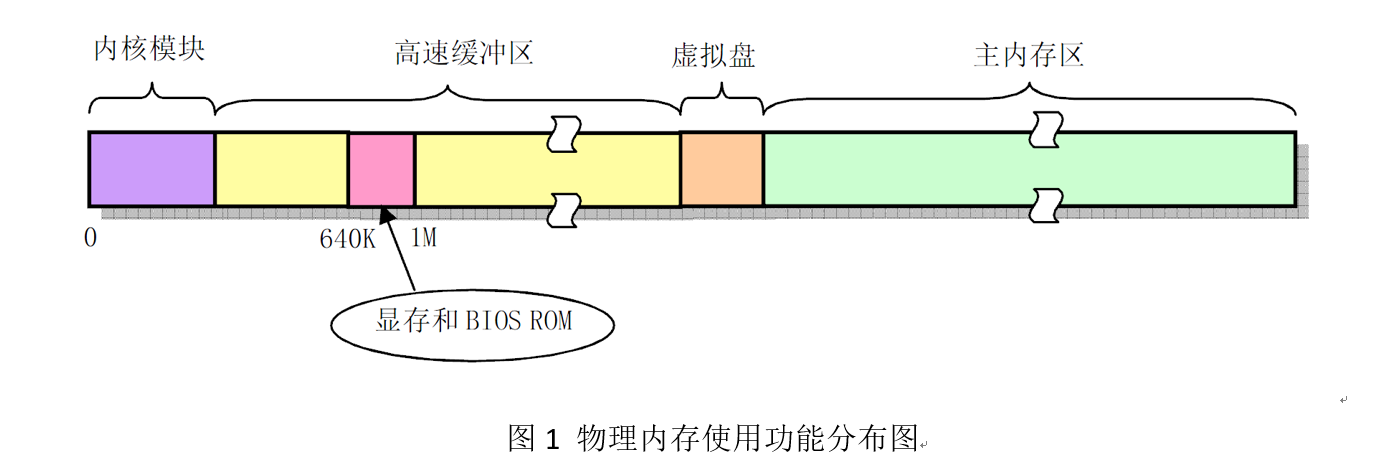
首先,为了有效地使用机器中的物理内存,在系统初始化阶段内存被划分为几个功能区域,如图1所示。其中,Linux内核程序占据在物理内存的开始部分,接下来是供硬盘或软盘等块设备使用的高速缓冲区部分(其中要扣除显示卡内存和ROM BIOS所占用的内存地址范围640K—1MB)。当一个进程需要读取块设备中的数据时,系统会首先把数据读到高速缓冲区中;当有数据需要写到块设备上去时,系统也是先将数据放到高速缓冲区中,然后由块设备驱动程序程序写到相应的设备上。内存的最后部分是供所有程序可以随时申请和使用的主内存区。内核程序在使用主内存区时,也同样首先要向内核内存管理模块提出申请,并在申请成功后方能使用。对于含有RAM虚拟盘的系统,主内存头部还要划去一部分,供虚拟盘存放数据。
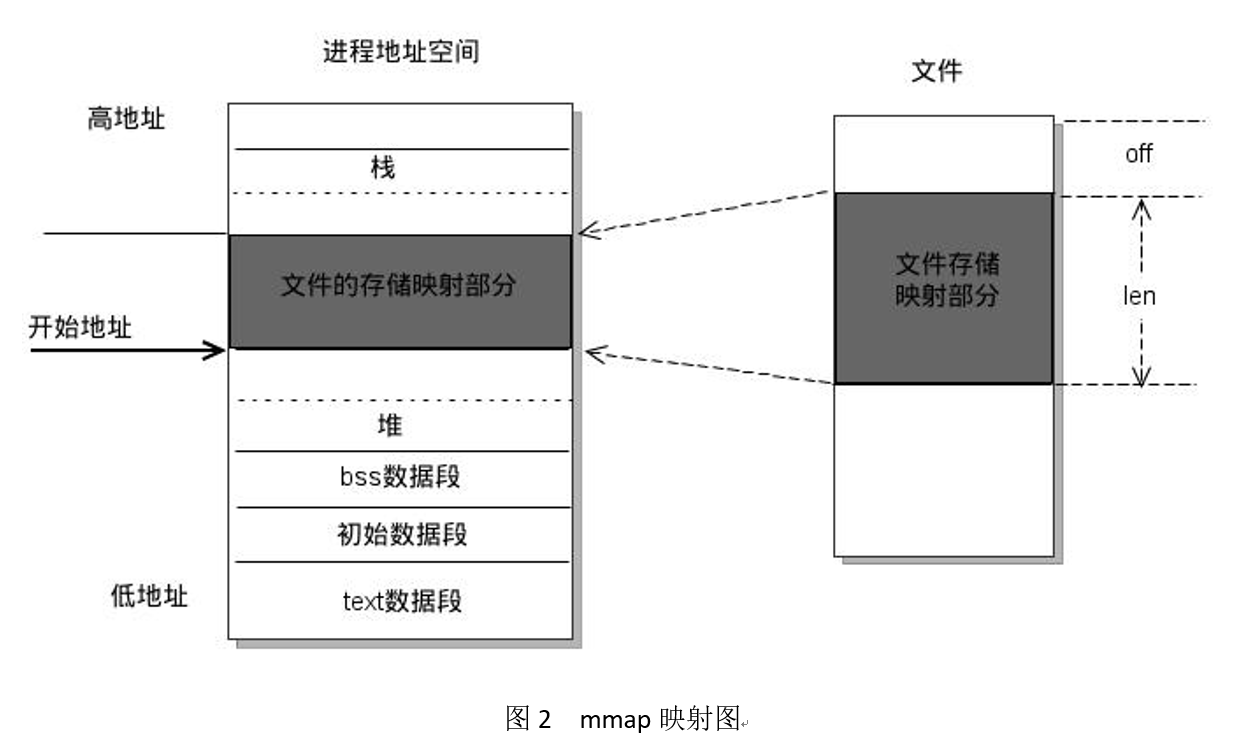
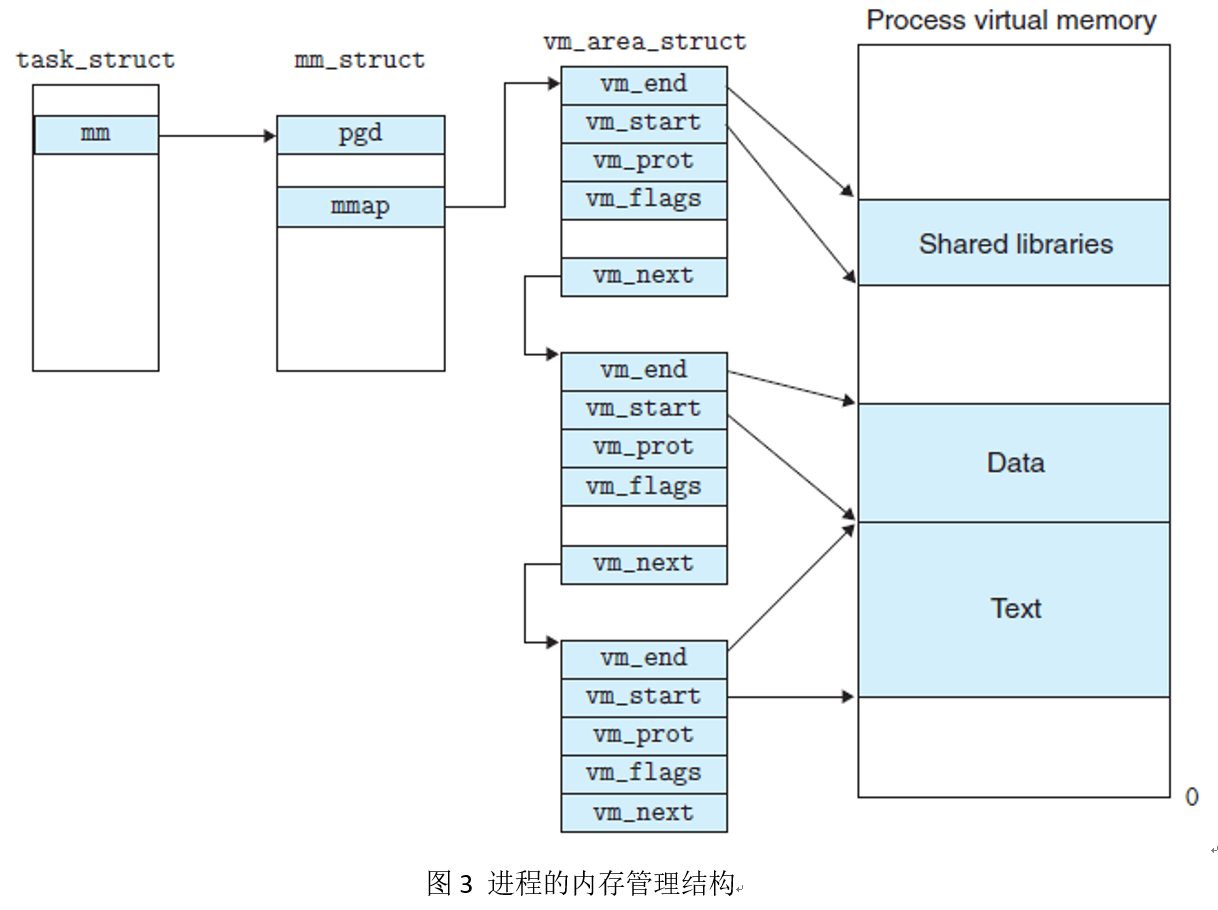
其次,mmap是一种内存映射文件的方法,即将一个文件或者其它对象映射到进程的地址空间,实现文件磁盘地址和进程虚拟地址空间中一段虚拟地址的一一对映关系。相反,内核空间对这段区域的修改也直接反映用户空间,从而可以实现不同进程间的文件共享。如图2所示,可以看出,进程的虚拟地址空间,由多个虚拟内存区域构成。图中所示的text数据段(代码段)、初始数据段、BSS数据段、堆、栈和内存映射,都是一个独立的虚拟内存区域。而为内存映射服务的地址空间处在堆栈之间的空余部分。如图3所示,linux内核使用vm_area_struct结构来表示一个独立的虚拟内存区域,由于每个不同质的虚拟内存区域功能和内部机制都不同,因此一个进程使用多个vm_area_struct结构来分别表示不同类型的虚拟内存区域。各个vm_area_struct结构使用链表或者树形结构链接,方便进程快速访问。vm_area_struct结构中包含区域起始和终止地址以及其他相关信息,同时也包含一个vm_ops指针,其内部可引出所有针对这个区域可以使用的系统调用函数。这样,进程对某一虚拟内存区域的任何操作需要用要的信息,都可以从vm_area_struct中获得。mmap函数就是要创建一个新的vm_area_struct结构,并将其与文件的物理磁盘地址相连。
函数原型: void *mmap(void *start, size_t length, int prot, int flags, int fd, off_t offset);

最后,函数中文件描述符fd,如果设置为-1,可以实现不与具体的文件映射,从而可以用于进程间内存共享。在RAMCloud系统同样使用此方法,申请大内存,用Segment和TableHash存储。
2.2 mmap使用
在RAMCloud中,对mmap进行了简单封装,详细可参见/src/ LargeBlockOfMemory.h中源码。
3. HashTable
HashTable存储key到object的映射,用于快速确定object的位置。一个大HashTable被分成了若干Hash Table Buckets。每个bucket中含有一个或多个CacheLine(64bytes),对于CacheLine含有8条entry,每个entry占8bytes。entry的前16bits存储secondary hash,1bit标明最后一个entry是否是一个指向下一个CacheLine的指针,最后47bits用于存储指针。这个值得一提的是,CacheLine大小是为了匹配CPU中单个L2 cache line而设计的。
此外,HashTable中的CacheLine也是采用上述的mmap系统调用分配的。首先Server会根据参数申请一定数量的CacheLine,构成CacheLine池,当需要使用的时候,从池中分配CacheLine给具体的bucket,不用的时候需要返回到CacheLine池中。当Server宕机或是进程结束的时候释放CacheLine池。
4. Segment
在RAMCloud中,采用Log存储Object,每个Log又被划分为固定大小的Segment(这里的固定不是绝对的,在cleaning的compaction过程中,Segment大小会被该变,下面还会详细叙述)。为了实现Two-level Cleaning,又把Segment划分为多个固定大小的Seglet(默认是64KB)。在Seglet中有两类entry,一类是正常Object,另一个是Tombstones(用于标记被更新和删除的Object已失效),具体的存储格式,可以参考源码(/src/Object.h)。
此外,Segment中的Seglet也是采用上述的mmap系统调用分配的。首先Server根据命令行用户键入的参数申请一定数量的Seglet,构成Seglet池。为了防止死锁的发生把Seglet池划分为三部分,分别为emergency head pool、cleaner pool、default pool,分别用于不同的场景(详细可以参考论文或源码)。每个Segment从default pool中申请Seglet使用,当Segment被cleaning后,释放Seglet到default pool中。
5. 内存管理
5.1 Log Metadata
在基于日志的文件系统中,为了快速的访问日志数据,RAMCloud是使用了hash table来访问在memory中的数据。Log Metadata分为三种:
object元数据
包含了存储基本单元object的table id,key,version,value。在数据恢复时,将根据最新version的条目来重建hash table。
log digest
每一个新的segment都会有一个日志摘要,这个摘要包含了所有属于这个段的日志。在数据恢复时,将根据段的最新的日志摘要来加载所有的元数据。
tombstone
这个日志是比较特殊的。它代表了被删除的object。日志一旦写入就不可修改,那么如果一个object被删除怎么办?在日志中添加一条tombstone的记录。记录包含table id,key和version。在平时的操作中,tombstone是不会用到。但是在数据恢复时,它能保证被删除的object不会被重建。
tombstone的机制很简单但是也有很多问题。其中一个问题就是它的GC,毕竟它最终要在log中删除。只有在object被删除后,tombstone才能被删除。否则也就违背了引入tombstone的初衷了:通过它来防止被删除的object的重建。在cleaner处理tombstone的log时,它会检查tombstone所指定的segment是否还在任何的log中。如果不在,那么说明object已经被删除,否则说明该segment还有有效数据,该tombstone不能被删除。
5.2 Two-level Cleaning
对于基于日志的内存分配,主要的瓶颈就在于log cleaner。碎片管理,或者说内存回收是非常昂贵的,这就需要巧妙的设计。特别是随着内存利用率的上升,回收的成本也越来越大。
对于Memory来说,带宽不是问题,我们关注的是空间的利用率,毕竟相对来说DRAM还是比较贵的。对于硬盘来说,带宽是昂贵的,可以说很多系统的瓶颈都是在硬盘的IO读写速度上,这也催生了很多基于memory的各种解决方案,当然也是RAMCloud需要解决的问题。因此,RAMCloud对于memory和disk采取了两种不同的回收策略。
两个阶段的cleaning,使得memory的cleaning可以不影响Backup,这个结果就是一般来说memory的利用率要高于disk。memory的利用率可以达到90%,disk的要低得多。当然因为disk的cleaning的频率更低,这也就可以理解了。
the first level of cleaning,称为segment compaction,仅仅是处理了in-memory的segment,并没有消耗网络或者disk的IO。它每次压缩一个segment,将它上面的数据拷贝到更小的segment,这样空出来的空间可以为其它所用。segment compaction在memory和disk中都维持了相同的逻辑log。由于被删除的object和废弃的tombstone都已经被彻底去除了,因此它实际上占用了更少的空间。
the second level of cleaning,称为combined cleaning。顾名思义,这个level的cleaning不单单会cleaning disk的,同样也会cleaning memory的。因为已经有segment compaction了,因此这层level的cleaning也是很有效率的。而且因为这一阶段被延后进行了,可以合并更多的删除操作了。
5.3 Parallel Cleaning
RAMCloud也充分利用了CPU的multi-core:同时以多线程执行cleaner。由于log的结构和简单的metadata的使用,使得cleaner的并行执行变得简单。此外,log是不可修改的,cleaner在复制移动object时就不必担心这些object会被修改。而且,HashTable存储的也是object的间接地址,因此更新HashTable中的object reference变得很简单。因此基本的clean机制也变得简单起来:cleaner 拷贝live data到新的segment,更新HashTable中的object reference,最后将cleaned segment释放。
在clean线程和service线程在处理读写请求时有三个地方可能会冲突:
a. 都需要在Log的head添加数据
b. 更新HashTable可能会有冲突
c. 当service线程正在使用某个segment时, cleaner不能释放它们。
日志并发更新
最简单的cleaning方法就是把需要移动的数据添加到Log的头部。但是这样话的会和service的写请求冲突。为了避免这种情况,RAMCloud是将这些需要移动的数据移动到新的segment,被称作SideLog。每个cleaner都会申请一组segment用于保存移动的数据,只有在申请segment的时候需要同步。在申请完成后,每个cleaner就可以操作自己所属的segment了而无需额外的同步操作。在移动完成后,cleaner会把这些segment放到下一个的Log digest中,同时被回收的segment也会从Log digest中删除。而且将这些segment同步到不同的backup上,不同于存储head segment的backup。这些segment可以备份到不同的disk中,可以提高Master的吞吐量。
HashTable冲突
由于HashTable同时被cleaner和service threads使用,因此会有冲突问题。由于HashTable标明了哪些object是可用的,以及他们的地址,因此cleaner可以使用HashTable确定某个object是否alive(通过判断指向的地址是否真的是该object)。同时,service线程可能会通过HashTable来读取或者删除某个object。RAMCloud在每个hash bucket上使用一个更小范围的锁来同步。
释放内存空间的时机
当cleaner thread clean完成一个segment后,这个segment的空间可以被释放或者被重用。在这个时候,所有service thread都不会看到这个segment的数据,因为没有HashTable的条目指向这个segment。但是有可能旧的service thread还在使用这个segment。所以free这个segment可能会导致非常严重的问题。
RAMCloud采用了一个非常简单的机制来处理这个问题:系统直到所有当前的service thead数据请求处理完成才会释放该segment。这个设计很简单,避免了使用锁来完成这个普通的读写操作。
释放disk空间的时机
当segment被clean后,在backup上的冗余备份也需要删除。然而,这个删除只能在被移动到的segment正确的写到disk中的日志之后。这需要两个步骤。合并后的segment需要在backup中完成冗余拷贝。因为所有的冗余拷贝都是异步进行传输的,因此只有cleaner在接收到所有的响应接到后。新的log digest必须包含新的合并的segment以及删除被clean的segment。只有数据被持久化后,这个冗余备份就可以被安全的删除了。
5.4 Avoiding Cleaner Deadlock
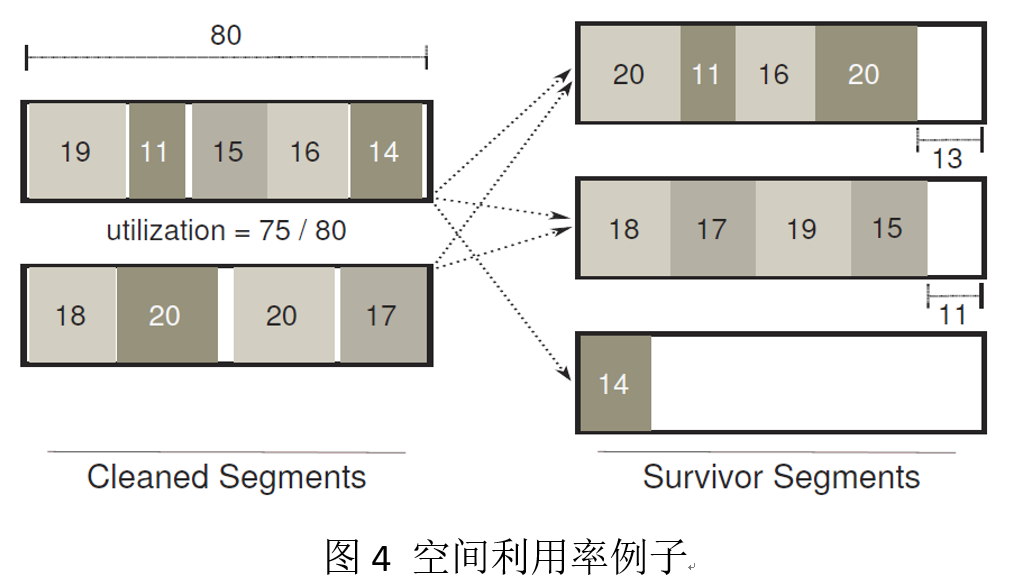
由于clean的过程中需要额外的内存,因此在内存利用率高的时候,clean的过程中有可能会耗掉最后的内存,run out-of-memory。因此形成了deadlock。RAMCould为了避免这种deadlock采取了多种技术,首先,它会为cleaner申请一个seglet的pool(前面提到的cleaner pool)。使得不会因为seglet的申请而导致死锁。而且,它在clean一个segment时,会计算是否这个clean会带来空间的利用率升高。如图4所示,这个例子的clean会导致碎片更大,反而导致了空间的浪费(解决措施的可参看论文)。在cleaning之后,释放segment之前,RAMCloud可能要为Sidelog写一个新的log digest,并去除旧segment的digest,这个时候可能资源耗尽导致死锁。为了解决这个问题,RAMCloud设置一个专用的emergency head pool。综合以上技术,RAMCloud的空间利用率可以达到98%,而不会产生deadlock。
6. 总结
通过上述的这些机制,RAMCloud的消除了内存碎片,并且没有全局的扫描,实现了垃圾回收,同时还充分利用了内存的带宽和磁盘容量,使内存的利用率提高了。
由于作者水平有限,欢迎指正。