本文章案例:将从用户表(sys_user)查出的用户名(name)作为新的列名,创建一个全新的表minfo。
了解完需求,开始编写存储过程。
第一步:打开PL/SQL可视化工具,从左下侧找到“Procedures”,右键“Procedures”文件夹,点击“New...”,出现以下弹窗

第二步:写入存储过程名字(驼峰命名规则)和所需参数(可有可无)

编写完信息后点击“OK”便会出现一个新的存储过程,如下图

第三步:编写存储过程(代码后面含有注释,方便理解)
create or replace procedure testFunction(officeId VARCHAR2) is
str1 varchar2(4000); --用于存放 获取原数据的SQL语句
str2 varchar2(200); --用于存放 原数据中的单个元素
ds sys_refcursor; --游标,指针用于循环【相当于for循环中的下标】
createsql varchar2(4000); --用于存放 创建新表的SQL语句
a number; --用于 计数某表是否存在于数据库中
dl varchar2(4000); --用于存放 删除的SQL语句
dorpsql varchar2(4000); --用于存放 查询表是否存在的SQL语句
begin
DBMS_OUTPUT.ENABLE(buffer_size => null);
str1:='SELECT DISTINCT name from sys_user where office_id ='''||officeId||'''';
dl:='drop table minfo';
createsql:='create table minfo(合计 varchar2(4000)';
open ds for str1; --将获取到的原数据进行循环,ds作为过渡元素使用
LOOP
FETCH ds INTO str2; --将ds中的结果依次插入到str2中
EXIT WHEN ds%NOTFOUND; --没有数据的时候,循环结束
createsql:=createsql||','||str2||' varchar2(4000)'; --拼接字符串【原数据中的元素】
END LOOP;
CLOSE ds;
createsql:=createsql||')';
dorpsql:='select count(*) from user_tables where TABLE_NAME =upper(''minfo'')'; --查询表是否存在
execute immediate dorpsql into a; --将查询是否存在的结果赋值给计数变量a
if a = 1 then --表 minfo 存在
execute immediate dl; --执行删除语句
end if;
dbms_output.put_line(createsql); --打印 创建表结构 的语句
execute immediate createsql; --执行创建新表的语句
end testFunction;
第四步:编写完成后,执行存储过程:点击图中红色标识的按钮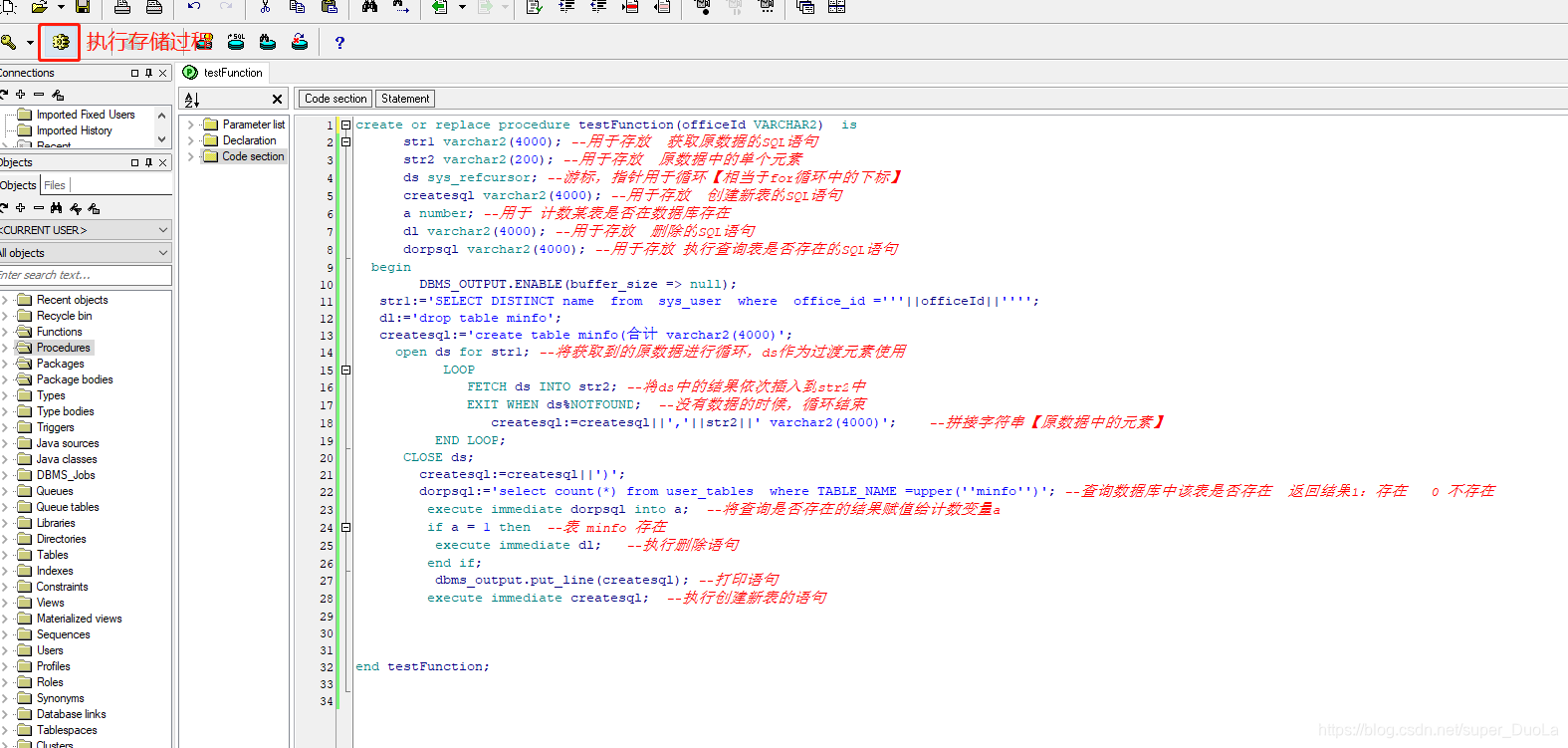
第五步:调用存储过程
(1)数据库中调用
--语法 call 方法名称(参数)
call testFunction('dea06cee037844cb8ccc1a5a2d29fb92')
(2)XML文件中调用
<select id="mysql" statementType="CALLABLE" parameterType="map" resultType="java.util.Map">
{call testFunction(#{officeId,jdbcType=VARCHAR,mode=IN})}
</select>第六步:查看最终结果,用户名作为列创建新表minfo成功

PS:示例的一些补充说明
1、查看数据库中是否存在某表【count(*)=1,存在;等于0:不存在】
select count(*) from user_tables where TABLE_NAME =upper(表名)2、upper()函数:将小写的字符转化成大写的字符
3、DISTINCT:返回唯一不同的值,相当于group by
4、不限制输出:当要输出的内容过大时会报错, 加上此语法可避免。buffer_size:缓冲器的处理元素的最大数。【大概意思,没深研究】
DBMS_OUTPUT.ENABLE(buffer_size => null); 5、打印信息,输出内容:等同于Java代码中的 System.out.println();
dbms_output.put_line(要输出的变量); --打印语句示例中的输出结果为‘创建表结构的SQL语句’:执行完SQL语句后点击“Output”查看

6、查询出的原数据

7、存储过程中只有单引号:如果出现多处需转义,即:两个''会转义成一个'。示例中有两处,同色标记为一对
(1)查询语句,“||”:拼接;红色标识:两个单引号会转义成一个
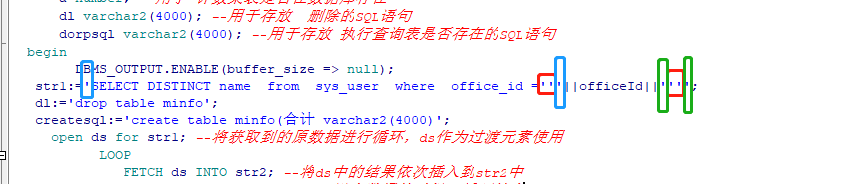
(2)在执行过程中绿色标识的两个单引号会转义成一个
到此:本案例已实现并结束,文章中的说明/注释,基于个人的理解,若有不妥之处,感谢指正!
