py3的多线程(个人体会)
今天做了这道题 [强网杯 2019]高明的黑客。不看大佬们的脚本的话,我觉得我可能会跑到明天去。然后稍微学习了一下多线程,有一些思考体会写下来。个人笔记,轻喷。
我们要先弄清楚一个概念,CPU密集型和IO密集型。
CPU密集型:
我们知道CPU是处理指令和处理数据的,一个程序大量的时间都花在了计算和判断上,就算是CPU密集型了。这时候CPU一直在使用,效率高,没必要用多线程。IO密集型:
程序的大量时间都花在了读写上,比如爬虫。这时候大量的时间都花在了获取数据上,CPU一直空闲着在等待数据的到来,这时候用多线程就比较有用。把原本的程序改成多线程感觉很麻烦,就想知道它到底能不能提高效率,值不值得我花时间改。怎么把普通脚本改成多线程?直接看 菜鸟教程 python3多线程
我用几个以前写的脚本比较:
端口扫描:(经常执行建立连接的操作)
无线程情况:

有线程情况(加锁):

有线程情况(不加锁):

普通脚本和多线程脚本之间相差了几乎100倍,我想是因为tcp支持并发连接的原因,同时发送SYN包,所以多线程显得很有效。对于加锁这个操作,在这里对效率的影响不大,应该是没有争抢什么公共资源。
目录扫描脚本:(经常执行访问网页的操作)
无线程情况:
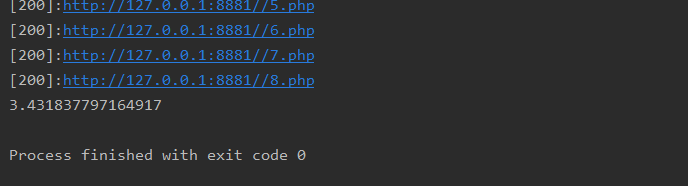
有线程情况(加锁):
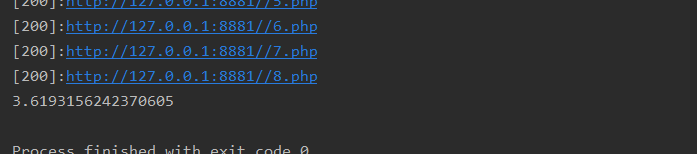
有线程情况(不加锁):

这里可以看到,虽然用了多线程,但是加锁操作之后对效率的影响很大,因为加锁时会多出一些指令,而且加锁后,当一个线程对公共资源访问时就会阻塞后面的线程,导致我们的多线程反而比普通的脚本效率低。我想这里的80端口就算是公共资源吧。
而不加锁的多线程,会发现快了很多。这里会出现200的url顺序乱序的问题,但是并不会出现404的页面显示200,也不会出现200的页面被忽略,所以我觉得这里可以不加锁,暂时还没发现问题。(这里可能和操作系统有关?)
我觉得是否用多线程要看是IO密集型还是CPU密集型,有时候我感觉真的不好判断= =我tcl 判断不准的话,就看自己是否能接受不使用多线程的速度,我写过一个字典处理的脚本,不用多线程也能1秒左右处理完上万行,所以没必要加多线程了= =
是否要加锁,就看不加锁的话会不会对结果产生影响,比如对数据的一些增删查改,就必须加锁。假如你想说的是 我 爱 喝 牛 奶。结果因为多线程不加锁,就变成了 奶 牛 爱 喝 我。hhh
——一个不是很懂编程的臭弟弟。
