find函数
find(beg, end, val) 返回一个迭代器,指向输入序列中第一个等于val的元素。未找到返回end。
find_if(beg, end, unaryPred): 返回一个迭代器,指向输入序列中第一个满足unaryPred的元素。未找到返回end。
find_if_not(beg, end, unaryPred): 返回一个迭代器,指向第一个令unaryPred不成立的元素。未找到返回end。
代码:
int ia[] = { 27, 210, 12, 47, 109, 83 };
int *result = find(begin(ia), end(ia), 12);
int *rsult = find(ai + 1, ai + 4, 47); //从ai[1]开始, 直至(但不包括)ia[4]的范围内查找元素
count函数
count(beg, end, val) // 返回一个计数器,指出val出现的次数。 count_if(beg, end, unaryPred): // 返回一个计数器,指出令unaryPred成立的次数。
【例题】:统计1-10奇数的个数(我的代码):
1 #include <iostream> 2 #include <algorithm> 3 #include <vector> 4 using namespace std; 5 6 bool comp(int num) 7 { 8 return num % 2; 9 } 10 int main() 11 { 12 vector <int> vec; 13 for (int i = 1; i <= 10; i++) 14 vec.push_back(i); 15 cout << count_if(vec.begin(), vec.end(), comp) << endl; 16 return 0; 17 }
输出结果:5
【例题】输入一串学生的信息,统计出成绩大于90分的同学个数(我的代码):
1 #include <iostream> 2 #include <vector> 3 #include <algorithm> 4 using namespace std; 5 6 struct student 7 { 8 string name; 9 int score; 10 }; 11 12 bool compare(student a) 13 { 14 return 90 < a.score; 15 } 16 17 int main() 18 { 19 int n; 20 cin >> n; 21 vector<student> V; 22 for(int i=0; i<n; i++) 23 { 24 student temp; 25 cin >> temp.name >> temp.score; 26 V.push_back(temp); 27 } 28 cout << count_if(V.begin(),V.end(),compare) <<endl; 29 return 0; 30 }
fill函数
fill(beg, end, val) //在(beg,end)中全部重置为val fill_n(dest, cnt, val) //在迭代器dest开始的n个元素置为val
1 fill_n(vec.begin(), vec.size(), 0); //将所有元素重置为0 2 fill_n(dest,n,val); //函数fill_n假定dest指向一个元素,而dest开始的序列至少包含n个元素。 3 4 一个初学者非常容易犯的错误是在一个空容器上调用fill_n(或类似的写元素的算法): 5 vector<int> vec; 6 fill_n(vec.begin(),10,0); //灾难:修改vec中10个(不存在)元素 7 //这个调用是一场灾难,我们指定了要写入10个元素,但vec中并没有元素——它是空的,这条语句的结果是未定义的。
STL底层源码实现:
1 template <class ForwardIterator, class T> 2 void fill(ForwardIterator first, ForwardIterator last, const T &value) 3 { 4 for(; first != last; ++first) 5 *first = value; 6 } 7 8 template <class OutputIterator, class Size, class T> 9 OutputIterator fill_n(OutputIterator first, Size n, const T &value) 10 { 11 for(; n > 0; --n, ++first) 12 *first = value; 13 return first; 14 }
accumulate函数
// 返回输入序列所有值的和。和的初始值由init指定。返回类型和init的类型相同。第一个版本使用+,第二个版本使用binaryOp。 // binaryOp是可调用对象,使用来自输入序列的两个实参调用。 accumulate(beg, end, init) accumulate(beg, end, init, binaryOp)
STL底层源码实现:
1 template <class InputIterator, class T> 2 T accumulate (InputIterator first, InputIterator last, T init) 3 { 4 while (first != last) 5 { 6 init = init + *first; 7 ++first; 8 } 9 return init; 10 }
equal函数
equal(roster1.cbegin(), roster1.cend(), roster2.cbegin()) //roster2中的元素数目应该至少与roster1一样多
由于equal利用迭代器完成操作,因此我们可以通过调用equal来比较两个不同类型的容器中的元素。而且,元素类型也不必一样,只要我们能用==来比较两个元素类型即可。例如,在此例中,roster1可以是vector<string>,而roster2是list<const char*>。
【注意】:它假定第二个序列至少与第一个序列一样长。此算法要处理第一个序列中的每个元素,它假定每个元素在第二个序列中都有一个与之对应的元素。
unique函数
unique(beg, end): 功能是去除相邻的重复元素(只保留一个), 其实它并不真正把重复的元素删除,是把重复的元素移到后面去了,然后依然保存到了原数组中,然后 返回去重后最后一个元素的尾后地址,因为unique去除的是相邻的重复元素,所以一般用之前都会要排一下序。
unique(beg, end) //beg和end是表示元素范围的迭代器。 unique(beg, end, binaryPred) //binaryPry是二元谓语 nique unique_copy(beg, end, dest)
代码1:
1 #include<iostream> 2 #include<algorithm> 3 #include<vector> 4 #include<string> 5 #include<iterator> 6 using namespace std; 7 int main() 8 { 9 const int N = 11; 10 int array[N] = { 1, 2, 0, 3, 3, 0, 7, 7, 7, 0, 8 }; 11 vector<int> vec; 12 for (int i = 0; i< N; ++i) 13 vec.push_back(array[i]); 14 vector<int>::iterator new_end; 15 new_end = unique(vec.begin(), vec.end()); //"删除"相邻的重复元素 16 vec.erase(new_end, vec.end()); //删除(真正的删除)重复的元素 17 copy(vec.begin(), vec.end(), ostream_iterator<int>(cout, " ")); 18 cout << endl; 19 return 0; 20 }
代码2:
1 #include<iostream> 2 #include<list> 3 #include<vector> 4 #include<algorithm> 5 using namespace std; 6 7 int main() 8 { 9 int ia[7] = { 5 , 2 , 2 , 2 , 100 , 5 , 2 }; 10 list<int> ilst(ia, ia + 7); 11 vector<int> ivec; 12 unique_copy(ilst.begin(), ilst.end(), back_inserter(ivec)); 13 14 cout << "vector: " << endl; 15 for (vector<int>::iterator iter = ivec.begin(); iter != ivec.end(); ++iter) 16 cout << *iter << " "; 17 cout << endl; 18 return 0; 19 }
输出结果:

sort函数
sort函数:对给定区间所有元素进行排序
// comp:是一个二元谓语,满足关联容器中对关键字序的要求(严格弱序)。注意点:当算法要求容器元素是有序的时候,一般当容器元素是升序排列时,comp功能必须类似于<,当容器元素是降序排列时,comp功能必须类似>,否则会出错。总结:comp的所确定的顺序符合容器前后元素的顺序。 sort(beg, end) sort(beg, end, comp)
代码 :
1 #include<iostream> 2 #include<fstream> 3 #include<vector> 4 #include<algorithm> 5 #include<string> 6 using namespace std; 7 8 int main() 9 { 10 ifstream in("test.txt"); 11 if (!in) 12 { 13 cerr << "打开文件失败" << endl; 14 exit(1); 15 } 16 vector<string> vec; 17 string word; 18 while (in >> word) 19 vec.push_back(word); 20 sort(vec.begin(), vec.end()); 21 auto unique_end = unique(vec.begin(), vec.end()); 22 vec.erase(unique_end, vec.end()); 23 24 for (auto c : vec) 25 cout << c << " "; 26 cout << endl; 27 return 0; 28 }
输出结果:

【分析】:
test.txt文件: the quick red fox jumps over the slow red turtle
使用sort: fox jumps over quick red red slow the the turtle
使用unqiue:(unqiue_end指向%) jumps over quick red slow the turtle % #
二分搜索算法
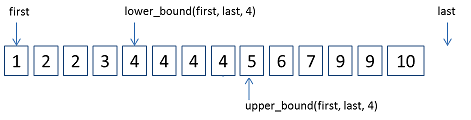
lower_bound(beg, end, val) // 返回一个迭代器,表示第一个小于等于val的元素,如果不存在这样的元素,则返回end。 upper_bound(beg, end, val) // 返回一个迭代器,表示第一个大于val的元素,如果不存在这样的元素,则返回end。 equal_bound(beg, end, val) // 返回一个pair, 其first成员是low_bond返回的迭代器,second成员是upper_bound返回的迭代器
repace函数
remove(beg, end, val) // remove_if(beg, end, unaryPred) // remove_copy(beg, end, dest, val) //
举例说明:
//replace算法读入一个序列,并将其中所有等于给定值的元素都改为另一个值。此算法接受4个参数:前两个是迭代器,表示输入序列,后两个一个是要搜索的值,另一个是新值。它将所有等于第一个值的元素替换为第二个值: replace(ilist.begin(), ilist.end(), 0, 42); //将序列中所有0都替换为42 如果我们希望保留原序列不变,可以调用replace_copy。此算法接受额外第三个迭代器参数,指出调整后序列的保存位置: replace_copy(ilist.begin(),ilist.end(), back_inserter(ivec), 0, 42); //此调用后,ilis并未改变,ivec包含与ilist的一份拷贝,不过原来在ilist中值为0的元素在ivec中都变为42