正则表达式中零宽字符、正向预查、反向预查(自己总结)
前言
刷HackerRank的Python题目时遇到一道与正则表达式有关的,发现涉及到自己不太了解的知识点,特此记录一下。
题目
Validating Postal Codes
https://www.hackerrank.com/challenges/validating-postalcode/problem
A valid postal code P have to fullfil both below requirements:
P must be a number in the range from 100000 to 999999 inclusive.
P must not contain more than one alternating repetitive digit pair.
Alternating repetitive digits are digits which repeat immediately after the next digit. In other words, an alternating repetitive digit pair is formed by two equal digits that have just a single digit between them.For example:
121426 # Here, 1 is an alternating repetitive digit.
523563 # Here, NO digit is an alternating repetitive digit.
552523 # Here, both 2 and 5 are alternating repetitive digits.Your task is to provide two regular expressions regex_integer_in_range and >regex_alternating_repetitive_digit_pair. Where:
regex_integer_in_range should match only integers range from 100000 to 999999 inclusive
regex_alternating_repetitive_digit_pair should find alternating repetitive digits pairs in a given string.Both these regular expressions will be used by the provided code template to check if the input string P is a >valid postal code using the following expression:
(bool(re.match(regex_integer_in_range, P))
and len(re.findall(regex_alternating_repetitive_digit_pair, P)) < 2)Input Format
Locked stub code in the editor reads a single string denoting P from stdin and uses provided expression and >your regular expressions to validate if P is a valid postal code.Output Format
You are not responsible for printing anything to stdout. Locked stub code in the editor does that.Sample Input 0
110000Sample Output 0
FalseExplanation 0
1 1 0000 : (0, 0) and (0, 0) are two alternating digit pairs. Hence, it is an invalid postal code.Note:
A score of 0 will be awarded for using ‘if’ conditions in your code.
You have to pass all the testcases to get a positive score.regex_integer_in_range = r"_________" # Do not delete 'r'. regex_alternating_repetitive_digit_pair = r"_________" # Do not delete 'r'. # 以下代码是不能修改的,能输入的只有上面两条正则表达式 import re P = input() print (bool(re.match(regex_integer_in_range, P)) and len(re.findall(regex_alternating_repetitive_digit_pair, P)) < 2)
简单来说就是输入一个六位数字,使用正则表达式判读其是否符合以下规则:
- 数字的范围在100000 到999999 以内;
- 六位数中不能有两组
交替重复的数字。交替重复的意思是,相同数字之间隔着一个数字,即505 中0 前后的5 就是一组交替重复的数字。
过程
# 字符串前面的r 表示原样输出,不做任何转义
# 第一个正则表达式比较简单,判断数字的范围从100000 到999999
regex_integer_in_range = r"^[1-9][0-9]{5}$" # Do not delete 'r'.
# 第二个非常tricky
regex_alternating_repetitive_digit_pair = r"(\d)\d\1" # Do not delete 'r'.
# \d 表示任何数字,
# \1 引用前面第一个括号的内容,这里是(\d)
# (\d)\d\1 即任何数字(\d) 在某个数字\d 后再同样地出现一次\1,符合交替重复的定义
# 但是,r'(\d)\d\1' 遇到1010 只能匹配到第一组交替重复的数字101 而不能匹配第二组010,所以失败了
# 以下代码是不能修改的,能输入的只有上面两条正则表达式
import re
P = input()
print (bool(re.match(regex_integer_in_range, P))
and len(re.findall(regex_alternating_repetitive_digit_pair, P)) < 2)
答案
https://www.hackerrank.com/challenges/validating-postalcode/editorial
Validating Postal Codes
Editorial by DOSHI
Approach is:a) (?=(\d)\d\1) using this regex findall how many alternating repetitive digits are there. b) ^[1-9][0-9]{5}$ using this regex check that postal code is in the range 100000 - 999999Add the boolean obtained from these to checks and print the result.
Set by DOSHI
Problem Setter’s code:import re P = raw_input() print len(re.findall(r'(?=(\d)\d\1)',P)) < 2 and bool(re.match(r'^[1-9][0-9]{5}$',P))
理解
# 相对我的表达式
re.findall(r'(\d)\d\1',P)
# 正确答案用了零宽式断言(zero-width assertion)
re.findall(r'(?=(\d)\d\1)',P)
按照我的理解,一个正则表达式就是一个断言(Assertion),只是处理的对象不同。
- 普通正则表达式,或者说
普通断言它匹配的是字符串; 零宽断言,它匹配的是字符串里每个字符间的位置。
用 https://regexr.com 的实验举个例子:
普通断言
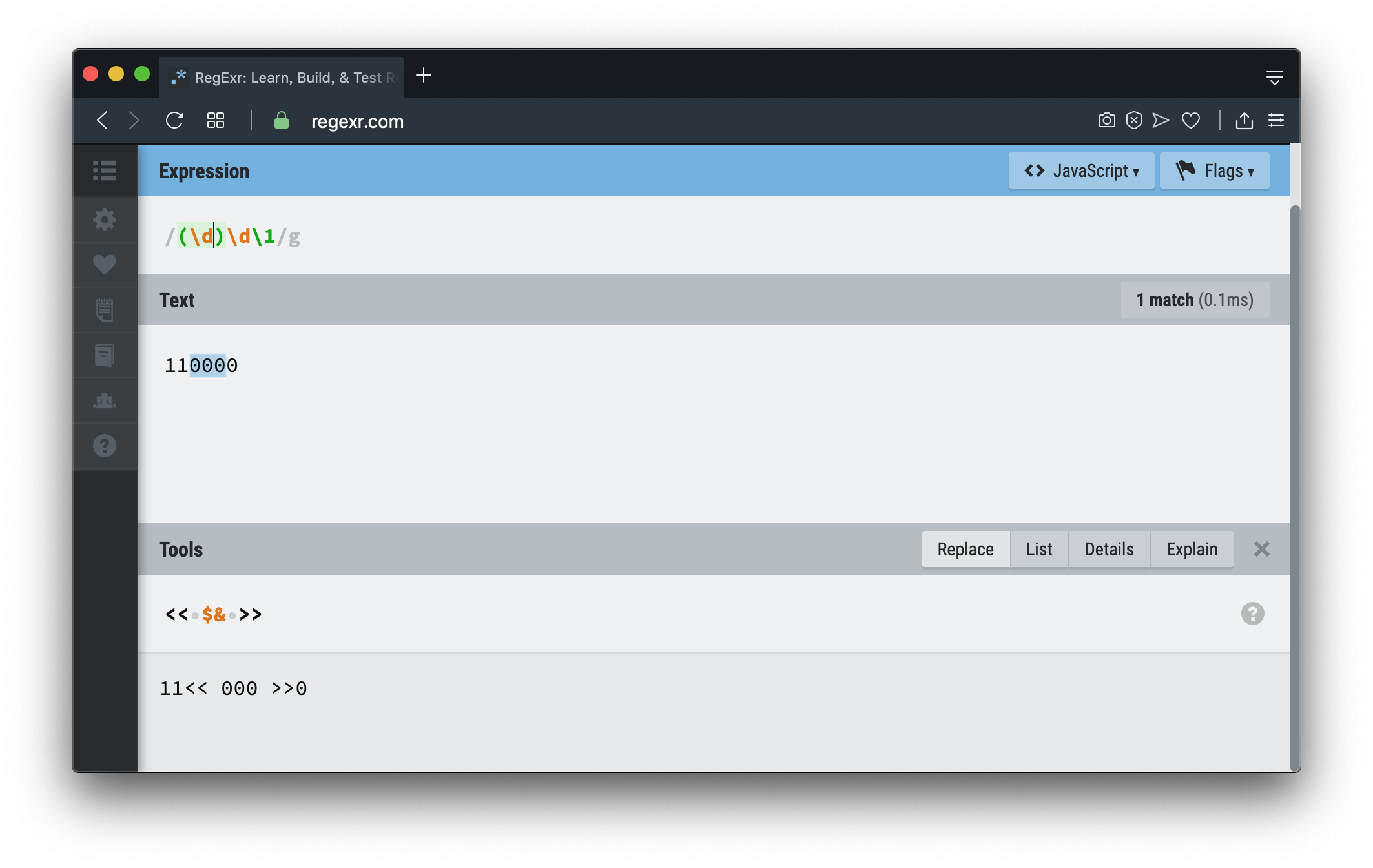
普通断言会逐个匹配字符串,查找过的字符串它不会回头再去匹配,也就是所谓的字符串消耗。
如图中110000,匹配到000后,整个字符串已被消耗掉11000,后面不再有能匹配的内容,然后整个过程停止。
零宽断言
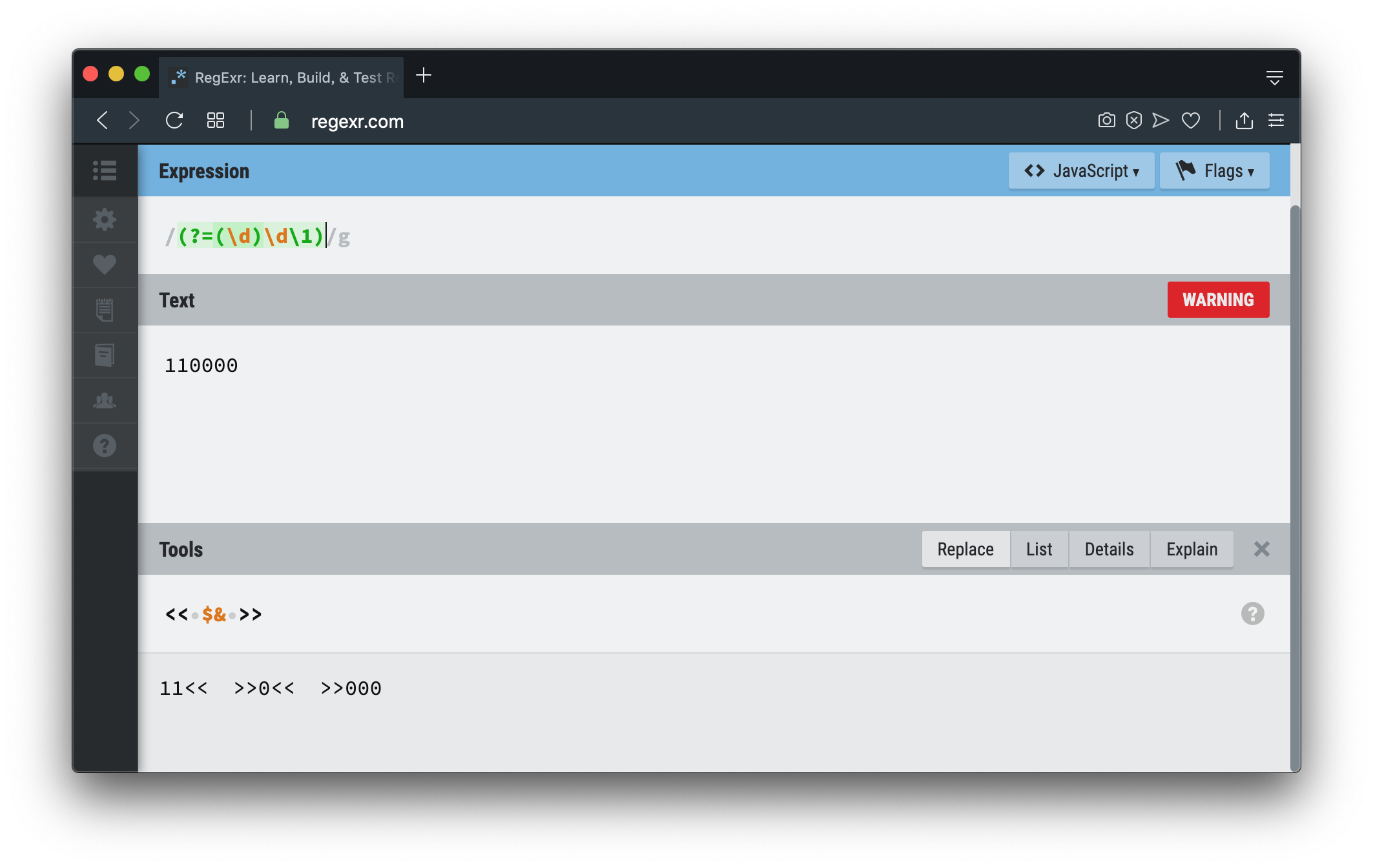
零宽断言也会逐个匹配字符串,但和普通断言不同的是,零宽断言关心的是位置,查找过的位置它也不会回头再去匹配。
如行首^,行尾$,字符间\b等这些就是位置。
宽度是针对字符的数量而言的,像a宽度就是1,ab宽度就是2,但位置不是字符所以它没有宽度,也就是0。
图中110000,匹配到000后,零宽断言保存的是000前面的位置,如果用|表示位置,即11|0000,
然后以该位置为起点继续向后查找,找到第二个000后,同样将位置,即110|000,保存起来,所以符合条件的位置有两个。
也就是说零宽断言用字符去匹配或者说侦测,然后保存相匹配的字符串的起始位置,再继续往后查找,
所谓不消耗字符串只是因为零宽断言记录的是位置而已。
明白了零宽断言的含义,正向预查、反向预查只是从某个位置向右(前)或向左(后)匹配而已,积极、消极也就是匹配或不匹配的意思。
具体正向预查、反向预查例子详见参考里的《RegExp 應用: lookahead , lookbehind》。
参考
正则表达式断言
RegExp 應用: lookahead , lookbehind
Python正则表达式之二:捕获
Python正则表达式之三:贪婪
正则表达式零宽断言、贪婪与懒惰
正则表达式在线测试
Python3.7 Doc - Lookahead Assertions
