文章目录
集合框架
为什么要用它?
- 以前用数组存储数据,因为创建数组的时候就要初始化数组的长度,由于这个长度是不可变的,这就导致两个问题:定义数组长度值太大,实际用不了那么多,就会造成内存的浪费,那定义的太小了,不够用了又得扩容,这就得不偿失了,所以这个时候,集合横空出世,相当于一个没有上限的盒子,数据直接丢进去。
它有什么好处?
- 集合包括了各种常用的数据结构:List表,Set集合,Map映射等等。
- 封装成了一个工具类,使用者不必了解底层实现,方便使用。
- 从JavaSE5.0,使用了泛型,这样集合中对象的数据类型就可以被记住,使用者不用担心,把对象丢进集合中,就丢失了他的数据类型。
特点在哪里?
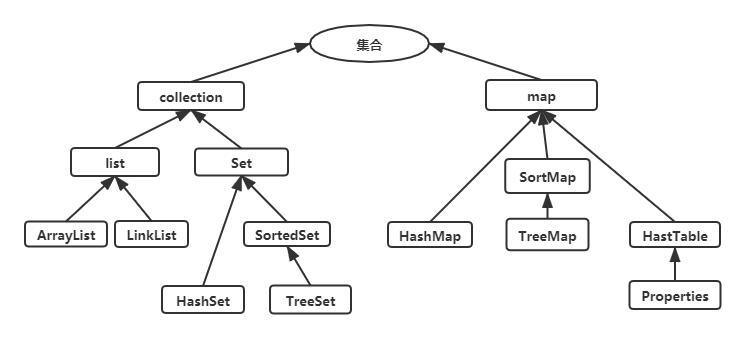
- java集合框架采用接口与实现相分离(就是面向接口编程的理念)。图中最底层的都是实现类,其他的都是接口,实现了接口中的方法,可以直接拿来用
- java的集合中只能存储对象,而不能存储基本数据类型。
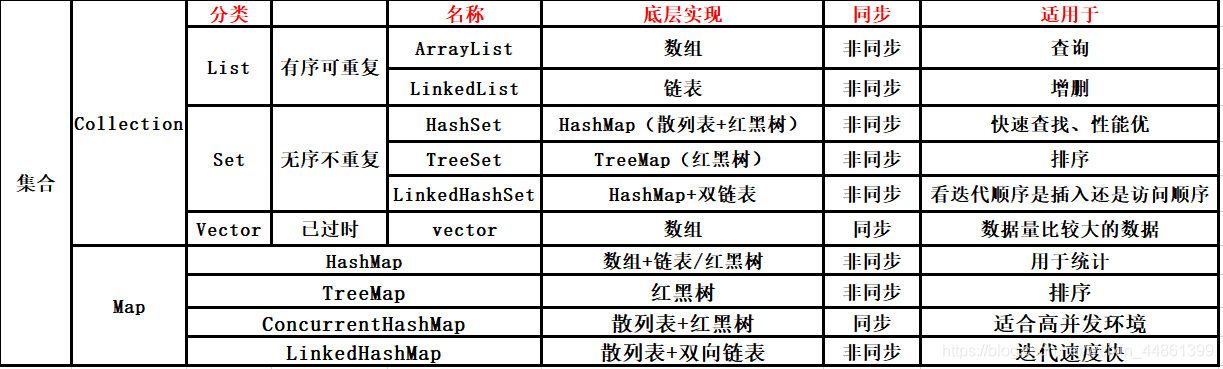
- 根据Colletion和Map框架,可以将集合分为三大类:
| list集合 | 有序集合 | 元素可以重复 |
| set集合 | 无序集合 | 元素不可以重复 |
| Map集合 | 键值对集合 | key是无序集合Set,value是有序集合List |
Collection集合
- 通过分析源码,可以看到collection集合继承了Iterable接口,这里注意是Iterable而不是Iterator。
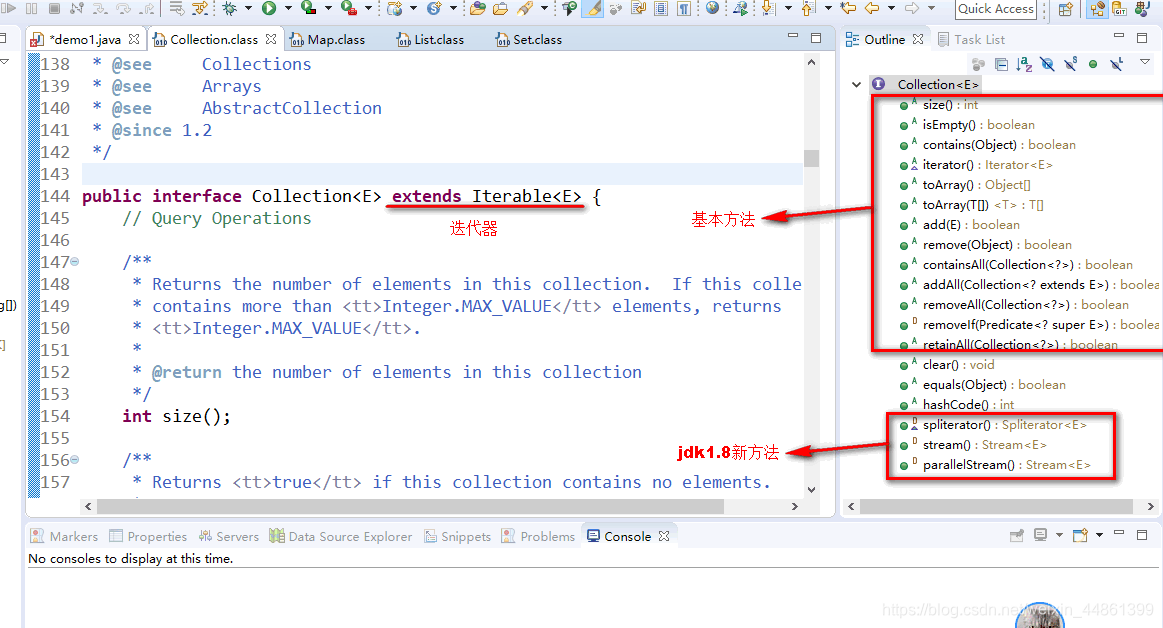
迭代器iterator
- 查看Iterable接口源码:可以看到有iterator这个方法,还有一个forEach()方法,也就是我们所说的增强for循环,这也是javaSE5.0以后,for循环一种优雅的写法。
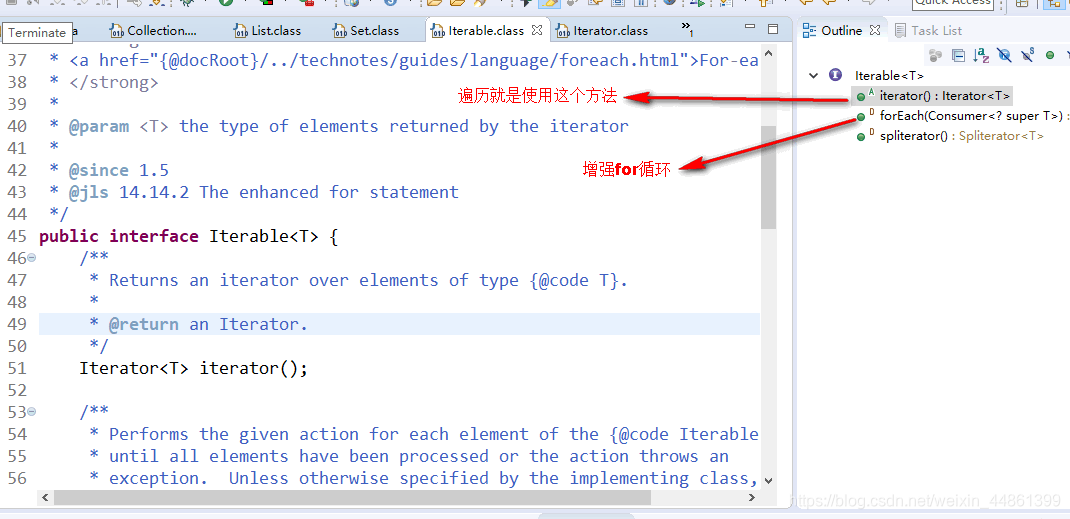
- 如上面所看到的,iterable接口里面,还有一个Iterator接口,点进去是这样的:这里面的方法就是日常所用到的:hasNext(),next(),remove()方法。
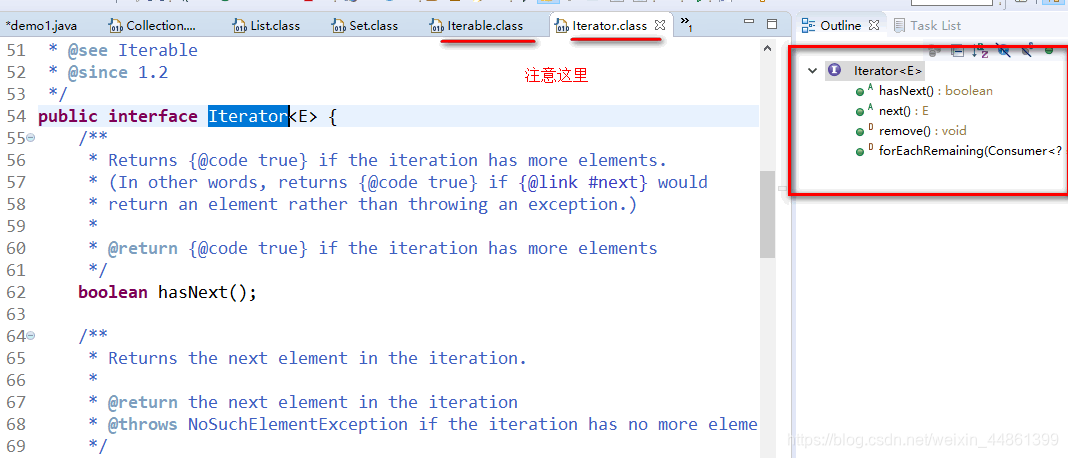
- iterator迭代器怎么用?
说到底,迭代器的作用就是遍历集合而已。
Collection c = new ArrayList();
//向ArrayList中添加元素
c.add("DAQ");
c.add("LOVE");
c.add("WT");
//获取到迭代器
Iterator it = c.iterator();
//遍历集合
while(it.hasNext()){
String element=(String)it.next();
System.Out.Println(element);
}
List集合
- List是线性表结构,包括顺序表Arraylist和链表LinkedList两种实现方式
Arraylist
- 底层数据结构是数组,线程不安全可以存放null值。因为它有扩容这一概念,可以实现动态增长,就不像原本的数组那样,长度固定不变了。
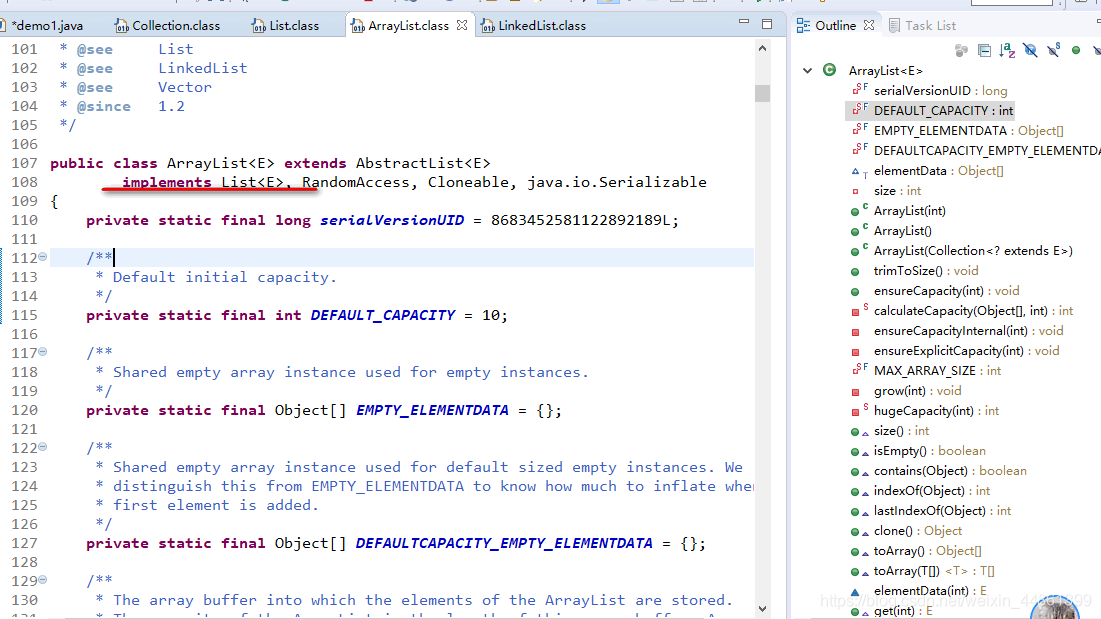
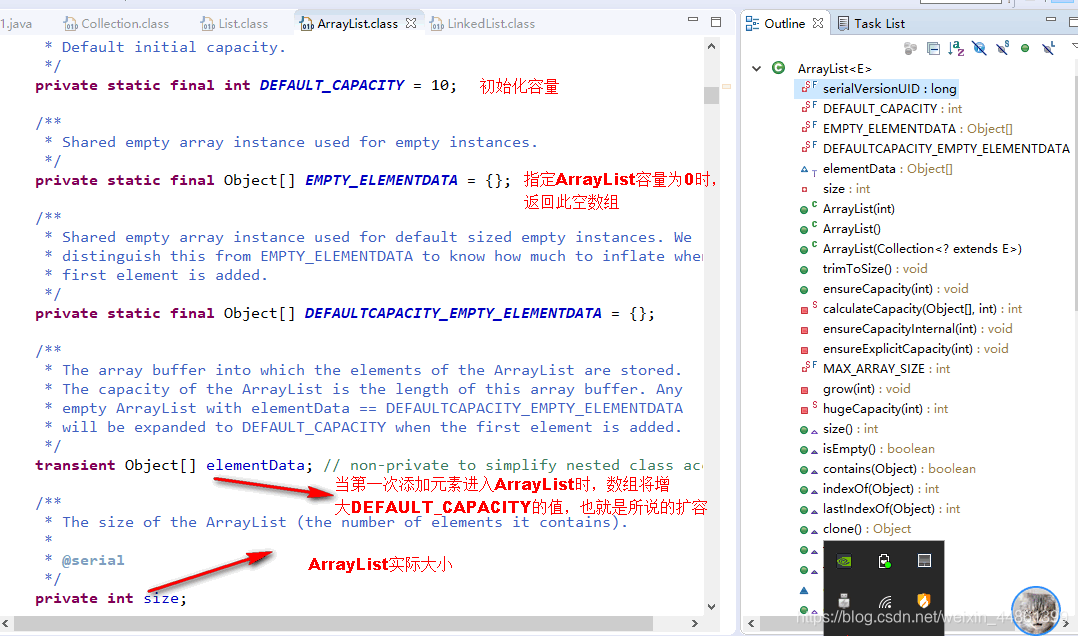
- ArrayList是基于动态数组实现的,在增删的时候,需要数组的拷贝复制。
- ArrayList的默认容量是10,每次扩容的时候,变为原来的1.5倍,也就是15
- 删除元素的时候,容量不会减少,需要减少容量的时候,要调用trimToSize()方法。
- 缺点:
- 从空间分配来看,除非预知数据的确切量或者近似值,否则频繁的扩容,或者大的容量初始值都会导致时间空间的浪费。
- 从运算时间来看,插入和删除的效率非常低。
LinkedList
- 底层数据结构是双向链表,采用**“按需分配”**的原则为每个对象分配独立的存储空间,但是线程不安全。
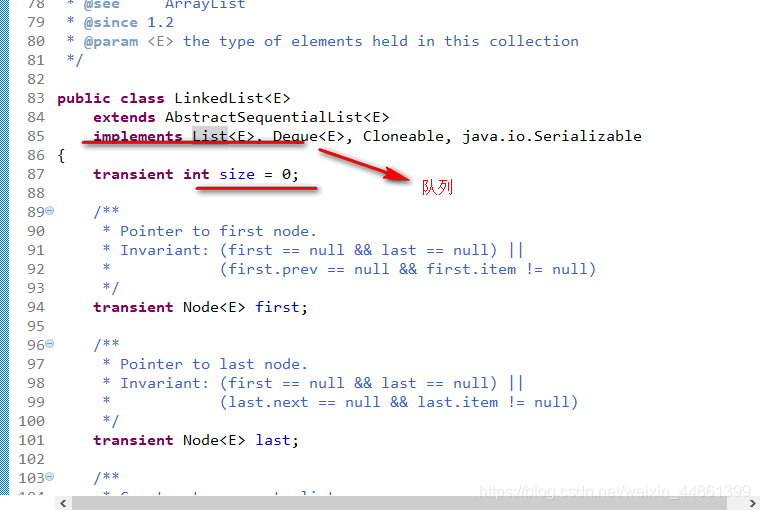
- LinkedList还实现了Deque接口,我们就可以像操作栈和队列一样操作LinkedList了。
- 只要有了头结点,其他的数据都可以轻松获取。
总结: 增删多用LinkedList,查询多用ArrayList。
Set集合
-
相比list集合而言,Set看起来清爽多了。
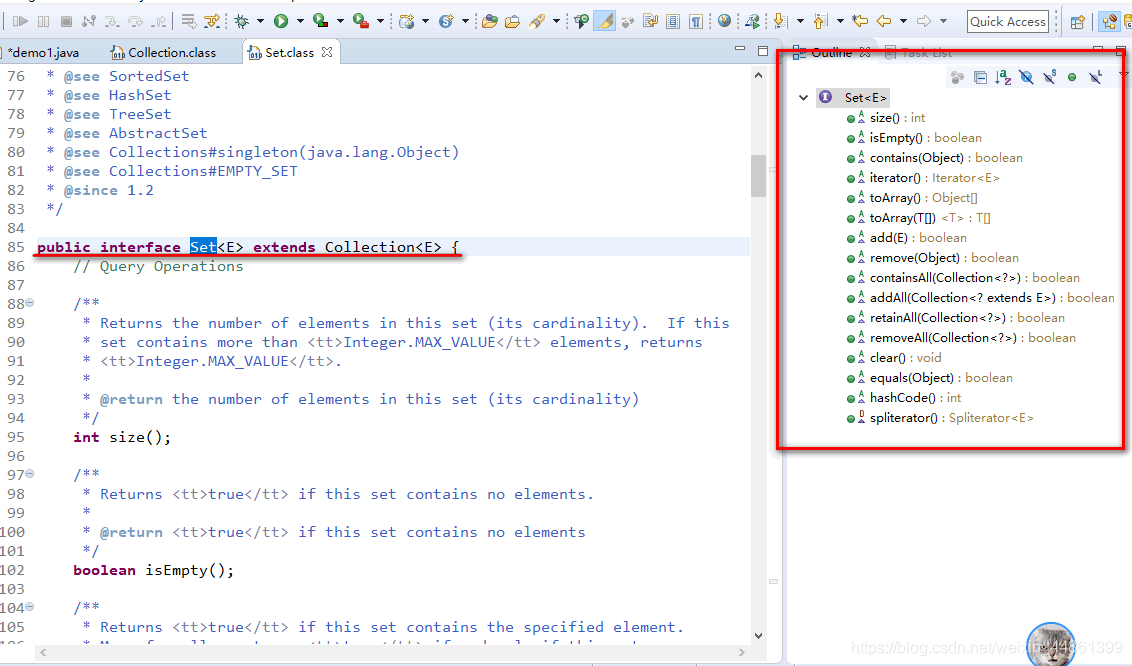
-
Set实现类依赖添加对象的equals()方法检查对象的唯一性,只要两个对象使用equals比较结果为true,set就会拒绝加入此对象(哪怕他们是不同的对象),只要两个对象使用equals比较结果为false,set就会接受加入此对象(哪怕他们是相同的对象),所以在使用set时,重点就要重写equals()方法,制定正规的比较规则。
HsahSet
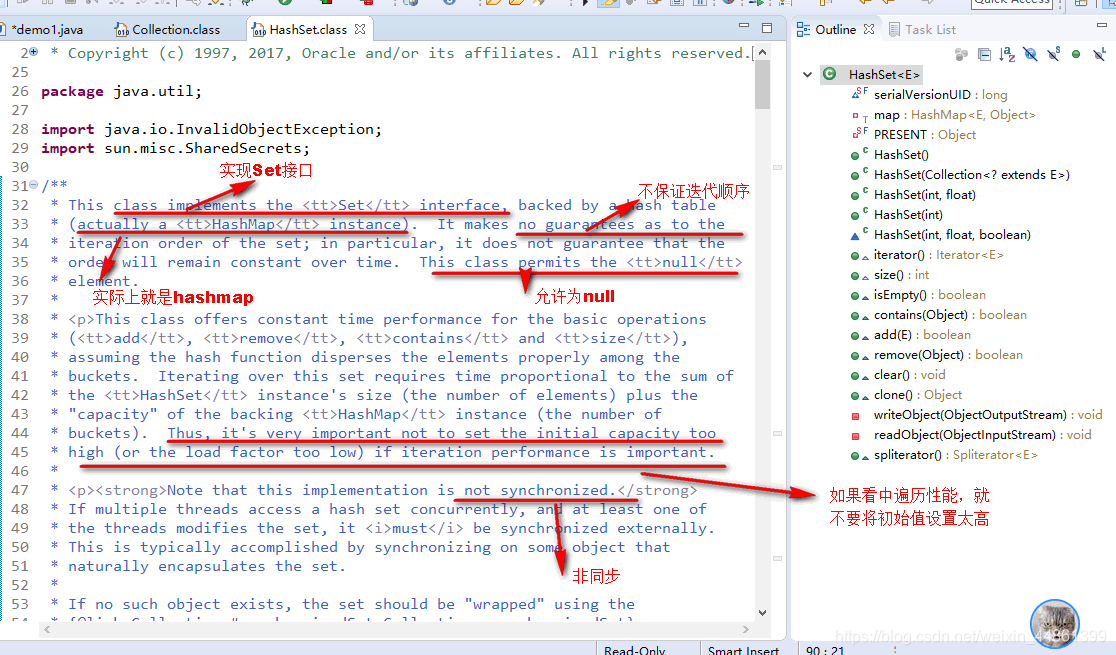
-
可以看出HashSet就是封装了HashMap,操作HashSet实际上就是在操作HashMap
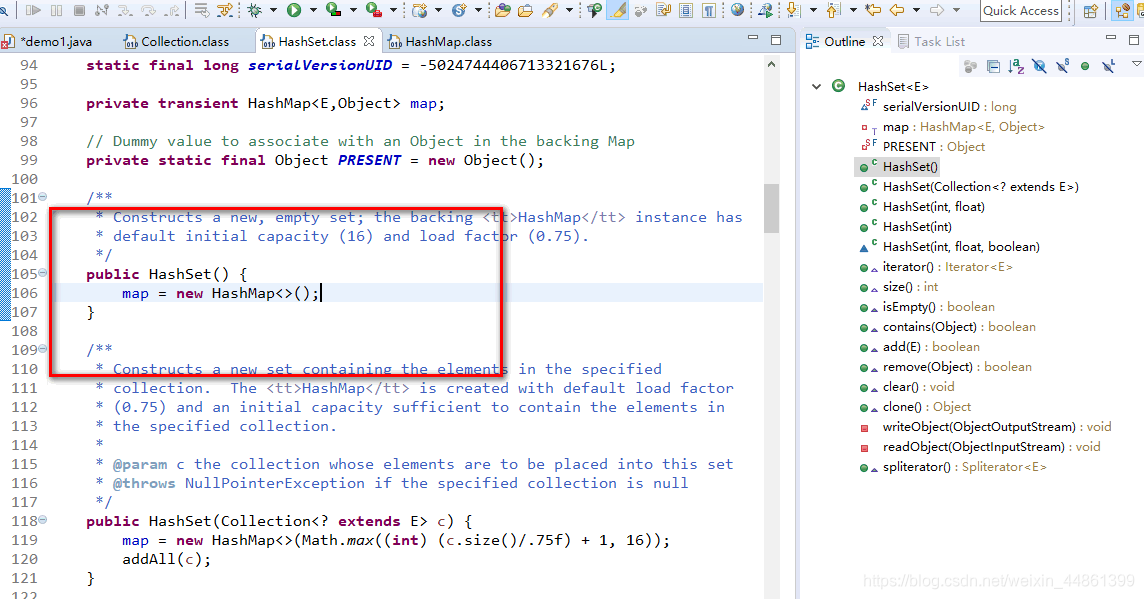
-
总结下来就是:
- 实现了Set接口,底层实际是一个HashMap实例
- 不保证迭代顺序,允许元素为null
- 非同步
- 初始容量影响迭代性能
TreeSet
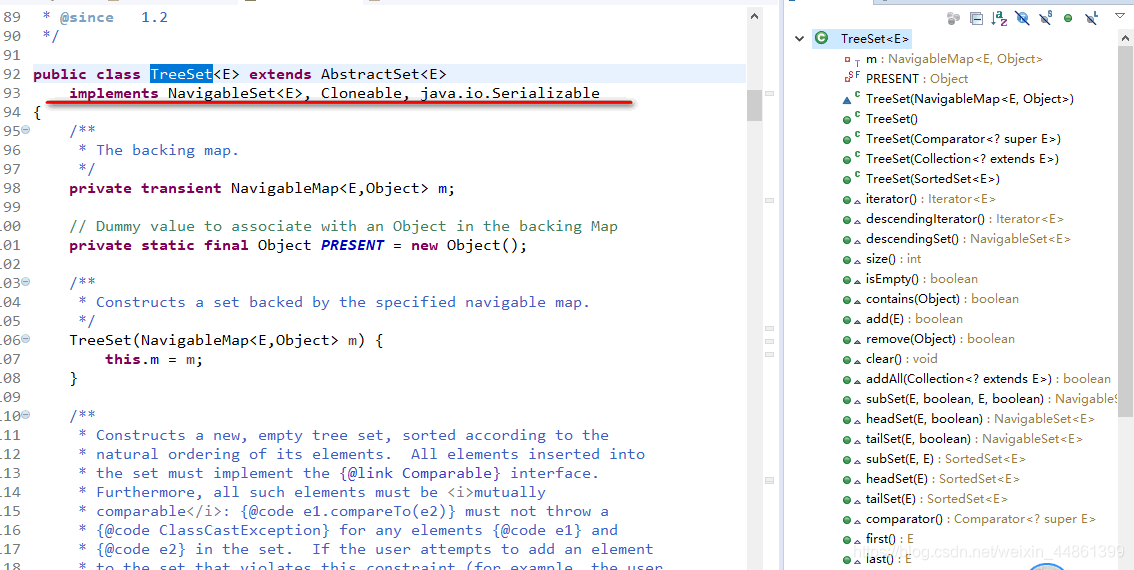
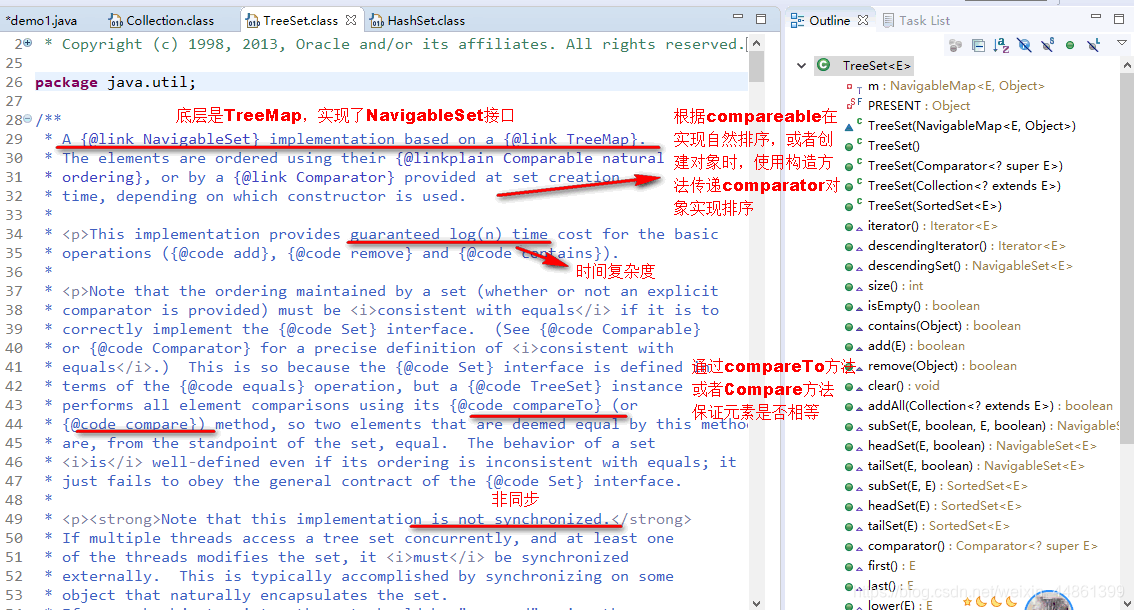
- 总结:
- 实现了NavigableSet接口,底层实际是一个TreeMap实例
- 可以实现排序功能
- 非同步
LinkedHashSet
- 归纳:
- 迭代是有序的
- 允许为null
- 底层实际上是一个HashMap+双链表实例
- 非同步
- 与hashset相比,性能稍微差一点,因为要维护双链表
- 初始容量与迭代无关,LinkedHashSet迭代的是双链表
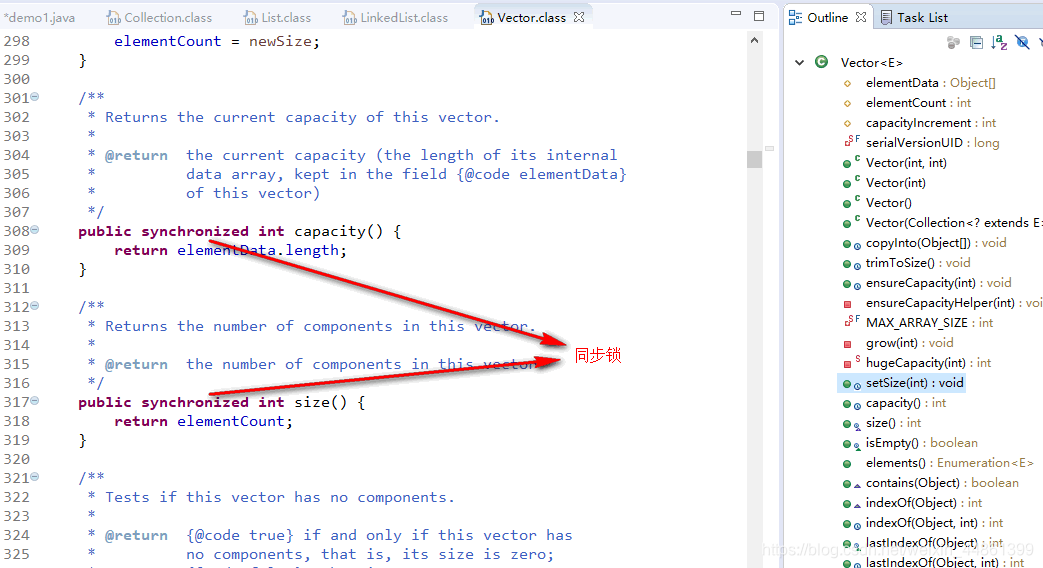
Vector集合
- 底层是数组,线程安全
- 从源码中看出,他给每个方法都加上了synchronized锁,这样很消耗性能。
- 而且Vector初始长度是10,超过这个长度的时候,翻倍增长。这就比ArrayList更加消耗内存。
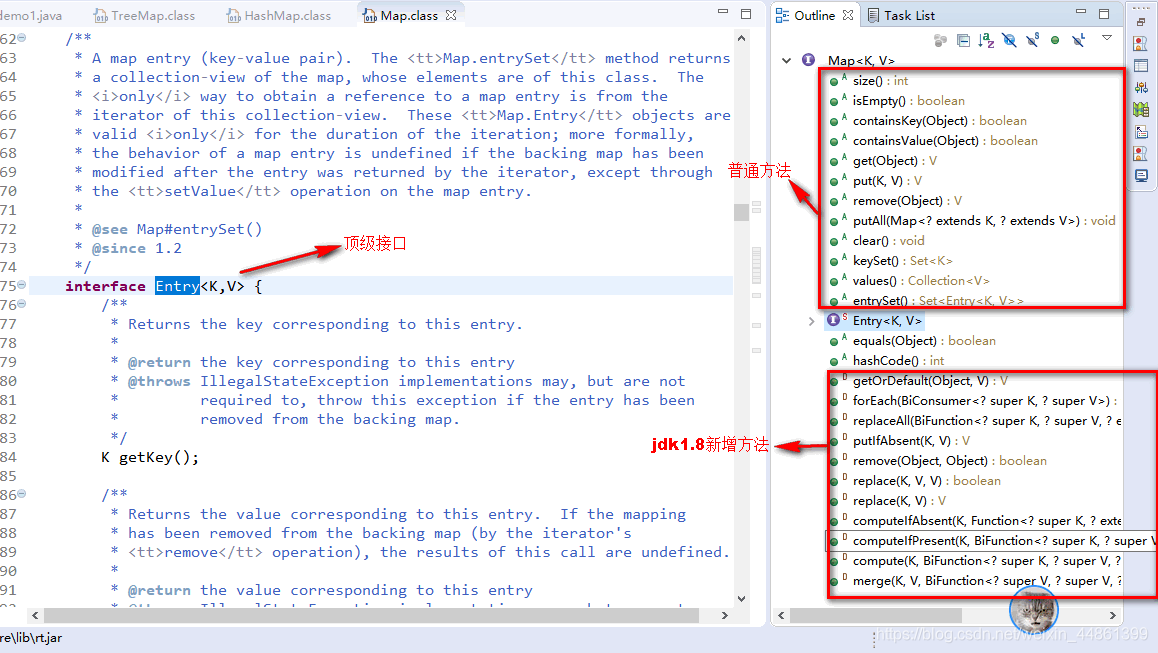
Map集合
- 为什么需要map?
map在java模型中称为映射,只要知道键值,就可以获取数据值。将键映射到值的对象,一个映射不能包含重复的键,每个键只能映射到一个值。 - Map与Collection的区别:
- Map集合存储元素是成对出现的,Map的键是唯一的,值是可以重复的。
- Collection集合存储元素是单独出现的,set是唯一,list是可重复的。
- Map数据结构针对键有效,跟值无关
- Collection数据结构针对元素有效
- Map的功能
- 散列表工作原理
- 散列表根据每个对象计算出一个整数,称之为散列码。根据计算出来的散列码,保存在对应的位置上。
- 在java中,散列表用链表数组实现,每个链表称为桶。
- 很可能有很多元素算出来的hash值(散列码)相同,这就会存储在同一个位置上,这种情况就叫做哈希冲突(散列冲突)。
- 但也不可能无限制装下去,在JDK1.8中,桶满时,链表会变成平衡二叉树,也就是所说的红黑树。
HashMap
- 在另一篇文章中我有单独将HashMap拿出来分析,并且分为了JDK1.7和JDK1.8时的HashMap的结构,HashMap源码分析
TreeMap
- 根据源码前的注释可以得出总结:
- TreeMap实现了NavigableMap接口,而NavigableMap接口继承SortedMap接口,这就导致TreeMap是有序的。
- TreeMap底层是红黑树,时间复杂度是
log(n) - 非同步的
- 使用Comparator和Comparable来比较Key是否相等,与排序的问题。
