原文地址:https://zhuanlan.zhihu.com/p/65436463
一、前言
数学是科学的基础,一般涉及算法的项目拆分到底层也都是基本的科学计算:单个数字、数组、各种维度矩阵之间的操作。BLAS 是一个数学计算库的标准,定义了一套矩阵数组操作的API,例如: sgemm float矩阵乘法、sgemv float矩阵乘以数组… 诸如此类。
OpenBLAS 是BLAS标准的一种具体实现,起源于GotoBLAS。考虑到项目较复杂,本文主要讲清楚以下几件事:
-
从blis实践开始一步步自己优化矩阵乘;
-
有了基础后再从gemm论文看BLAS矩阵优化;
-
OpenBLAS Makefile 和代码结构,主要理清模板函数如何兼容各种 case,如行列主序、trans、notrans;
-
OpenBLAS arm64 sgemm kernel,只说明 kernel4x4这种类型,别的kernel可以类推
假设读者已经具备以下能力: -
了解C和makefile
-
理解《线性代数》矩阵乘法的数学过程
-
CET6 左右词汇量以阅读相关论文
-
了解计算机体系结构,计算机专业本科或同等能力,以理解加速原理。《深入理解计算机体系结构》前三章和《计算机组成原理》都是挺好的前置技能教材
我业余时间有限,尽量在每周末晚上更新。算法有点像“祖传代码”,得先知道“为什么”才能看懂“是什么”。速成是不可能速成的,但可以跟刷漫画一样慢慢看。点赞、关注、打赏甚至催更都是我更新的动力,没人看的话更了也是 Internet noise。
二、BLIS
blis-lab 是一个开源教学项目,提供了完整的代码范例和测试脚本教人如何一步步优化矩阵乘法(像优化YUV2BGR那样一步一步做)。因为此项目git代码和文档并不是完全吻合,又是列主序实现的,所以还是参照文档一步步自己来做吧。虽说看论文是必不可缺的工作内容,但深度学习工程化经验都是实践得来的,“纸上得来终觉浅,绝知此事要躬行”。我将参照文档方法,实现对应的行主序矩阵乘法优化。
我的硬件环境是 nvidia tx1,A57架构。指令优化部分用neon intrinsic实现,兼容armv7和arm64。
小科普:
1)neon 是 armv7 arm64 芯片上特有的 SIMD(单指令多数据)指令集名称,SIMD 能一条指令完成多数据的并行计算。例如同时对 4 个float做标量乘法。大部分手机和比较流行的 rk、qcom 系列嵌入式开发板是支持 neon 的。armv7 和 arm64 指令是不同的,A57在汇编层使用 arm64 指令。
2)PC 常用的芯片是 x86 架构,对应的 SIMD 指令集名叫 SSE;
因为都是做 SIMD,软件层也有一些 sse2neon 代码屏蔽掉这些差异,对外保持同一套接口;
初始测试环境
- 先从git拉取项目
- src/HowToOptimizeGemm即为源码路径,make run即可编译并执行测试用例(目前代码进度兼容x86)。makefile包含以下流程:
- a. 代码内会初始化不同尺寸的矩阵,配置在parameters.h
- b. 矩阵初始化后会用 naive 版的结果做正确性判断
- c. 在OLD和NEW上设置使用的gemm代码文件名,用于后续性能对比。项目里用了MMult0
- d. make run之后会把多次运行的gflops结果分别保存到output_new.m和output_old.m
- e. 根据两个结果文件用octave:1> PloatAll绘制成对比图。这步是可选的,如果octave安装困难,可以写个python脚本,读取文件自己绘制
- f. 代码已改为RowMajor,有疑问请留言沟通
小科普:
gflops是优化效果的指标。矩阵乘的计算量是2 * M * N * K,拿计算量除以耗时即为当前gemm版本的gflops。如何评估当前还有多大优化空间呢?如果我们能测出芯片的极限gflops,拿芯片的极限和代码的效果做比较,二者接近就说明没有什么提升空间了。如何测试芯片的极限,后续会提供样例。
naive 版矩阵乘
项目中OLD和NEW都设置为MMult0即使用原始的矩阵乘法。实现过程和数学课本一致:A 的一行乘以 B 的一列得到 C 的一个元素。
make run 后使用 PlotAll 可以得到类似gflops结果:
 横轴是矩阵尺寸,简单起见我们假设MNK值相同;纵轴是gflops。原始版矩阵乘只有1gflops不到,且会随着矩阵尺寸的增大而衰减。
横轴是矩阵尺寸,简单起见我们假设MNK值相同;纵轴是gflops。原始版矩阵乘只有1gflops不到,且会随着矩阵尺寸的增大而衰减。
C 代码级优化技巧
代码优化技巧很多,但是读到这里只需要记住三条:
- 避免乘法
- 简化循环
- 内存对齐
避免乘法
这条很容易理解,《计算机组成原理》说过,乘法可以用多条加法实现;乘除法都是开销较大的计算。
以 how-to-optimize-gemm 的部分代码为例:
for ( p=0; p<k; p++ )
{
a_0p_reg = A( 0, p );
c_00_reg += a_0p_reg * B( p, 0 );
c_01_reg += a_0p_reg * B( p, 1 );
c_02_reg += a_0p_reg * B( p, 2 );
c_03_reg += a_0p_reg * B( p, 3 );
}
每次计算B(p, 0)都需要做乘法,完全可以用指针保存B(p, 0)的地址,需要B(p, 1)时做一下偏移即可。原文是列主序的,修改后的代码片段如下:
for ( p=0; p<k; p++ )
{
a_0p_reg = A( 0, p );
c_00_reg += a_0p_reg * *bp0_pntr++;
c_01_reg += a_0p_reg * *bp1_pntr++;
c_02_reg += a_0p_reg * *bp2_pntr++;
c_03_reg += a_0p_reg * *bp3_pntr++;
}
简化循环
arm64环境里,编译选项只要加了-O2就会使能编译器的SIMD化,不像armv7里要写-ftree-vectorize或-O3告诉编译器启用neon。简单的循环结构对编译器优化更有利。例如下面的代码,手动写的neon intrinsic版未必快过编译器自己优化的结果。
for(int i = 0; i < 100000; ++i)
{
a[i] = a[i] + 1;
}
内存对齐
假设 cache line 为 32B。待访问数据大小为 64B,地址在 0x80000001,则需要占用 3 条 cache 映射表项;若地址在 0x80000000 只需要 2 条。内存对齐变相地提高了 cache 命中率。
《计算机组成原理》也提到过,访问 Cache 比访存快 1~2 个数量级。Cache 命中率在优化里绝对是中后期英雄。
经过优化的版本是MMult_4x4_8,和上一版(MMult0)速度差距较明显。
 MMult_4x4_8 每次循环都计算 4x4 的小块,也就是每次取 4 行 A 和对应的 4 列 B 做运算。矩阵尺寸较小时有 3 倍加速效果,如此高的收益得益于两点:
MMult_4x4_8 每次循环都计算 4x4 的小块,也就是每次取 4 行 A 和对应的 4 列 B 做运算。矩阵尺寸较小时有 3 倍加速效果,如此高的收益得益于两点:
上文提到的小技巧
每次计算 4x4 个结果,这种计算方法有利于arm64编译器隐式优化出neon指令.
显式SIMD
单核 CPU 在做多线程调度时,会不停地保存上下文留作切换用。 同样的道理,arm芯片上能执行neon指令的寄存器也是有限的(tx1上是 2 个),编译器在处理连续的、前后关联的计算代码时,为了把数据换入换出到 neon 寄存器,也会生成一些多余的 load/save 指令。
因此编译器自动生成的neon指令并不总好过手写的代码。恰当的计算顺序重排也能提高速度。示例可以看之前写的YUV2BGR重排指令顺序。
neon sgemm版本名是MMult_4x4_9,有 10% 左右的加速效果。

分块
之前的优化都是对小矩阵效果明显,为什么矩阵变大后gflops会快速衰减?
还记得课本里经常出现的计算机存储结构图么?
 AB 矩阵小于 L2 cache 时,gemm只需要从 RAM 读取 AB 大小的内存,不需要做其他的读 RAM 操作;但是当 AB 大于 L2 cache 时,由于行主序的 B 或者列主序的 A 不是内存连续的,gemm 从 RAM 读取的内存数超过 AB 的大小。
AB 矩阵小于 L2 cache 时,gemm只需要从 RAM 读取 AB 大小的内存,不需要做其他的读 RAM 操作;但是当 AB 大于 L2 cache 时,由于行主序的 B 或者列主序的 A 不是内存连续的,gemm 从 RAM 读取的内存数超过 AB 的大小。
为了解决上述问题,避免多余的 cache 换入换出,MMult_4x4_10 调整了计算方法。
这里也是 gemm 论文的核心思想:
假设行主序 A 矩阵大小为 mk;B 矩阵大小是 kn;AB=C;C 矩阵大小是 mn。
一般线性代数的教法是 A 的一行点乘 B 的一列再累加得出 C 的一个元素,即累加 A(0, i) * B(i, 0) 得到 C(0, 0)。
其实也可以:A 的一列和 B 的一行操作得到 m*n 大小的一个 C 的“扇面”,多个“扇面”叠加就是完整的 C。
本节说的“分块”不是像切纸一样在 xy 轴上分开计算小块的 C 矩阵,而是像千层饼一样在 z 轴上切分 C。
分块后的代码对较大的矩阵也起到了加速效果:
 建议翻下代码一起看看,这里也是理解OpenBLAS level3.c的关键,不理解就继续看下去也是浪费时间,不如打农药。
建议翻下代码一起看看,这里也是理解OpenBLAS level3.c的关键,不理解就继续看下去也是浪费时间,不如打农药。
重排
分块后 microkernel 里的 AB 仍然是内存不连续的,为了提高内存的连续性,在做乘法运算前对 AB 做了重排:把第二行要操作的数据放到第一行要操作的数据的尾部。这样一来,AddDot4x4里数据预取指令就会生效。
对 B 做重排的gemm是MMult_4x4_11,效果立竿见影:
 对 A 做重排的版本是MMult_4x4_12:
对 A 做重排的版本是MMult_4x4_12:

总结:
我们一步步写了自己的 sgemm,效果远好于 naive 版本。如果真的按 git 上的代码跟着做完的话,其实已经掌握了 OpenBLAS sgemm 的核心知识点。当然这只是个 demo,要做好还有很多细活,接下来我们进入论文部分。
三、gemm 论文解析
如果上一章git项目里的“千层饼分块”的计算思路还不理解,请回头看项目源码,不要继续看下去。因为论文是建立在这个知识点之上的,并且这篇论文不阐述分块原理。
也可从github 项目中下载
第一遍看不懂很正常,反复多看几遍,把握文章脉络。通常一篇文章核心思想就一个点,其他都是铺垫和吹牛用的。
文章脉络
论文枚举了分块矩阵乘法的所有拆分方法,从 cache 角度分析这 6 种方法里哪个最优。
直接翻第 5 页所有拆分方法:

Fig.8和Fig.10的含义:
第一列是 Matrix += Matrix * Matrix,就是矩阵乘加C += A * B
第二列是 把 A 拆成多列、B 拆成多行,每次得到 C 的“一层皮”,多层叠加得到完整的 C
第三列是 更细致的拆分选择,A 的一列乘以 B 的一行。Fig.8是把 A 的一列拆成block依次和 B 行相乘;Fig.10是把 B 行拆成多个 block再被 A 乘
第四列和第三列的含义类似,Fig.8一个block乘以一行,由于要放到register里,必然行切成更小的slice;Fig.10含义类似。
其他四行含义可使用类似的理解方法,有疑问请评论。
论文的5.6 Discussion选择最优解:
- 倒数第二、第三两种拆法直接被淘汰,因为需要完整的一行乘以一列,MNK值较大时需要很大的 cache,CPU cache并不大;
- 因Fig.8和Fig.9在第四列都拆成了GEBP形式,所以拿它俩比较。由于在循环外 l1cache 级别 unpack C 远复杂于在循环内 register 级别 unpack C,所以Fig.9被淘汰;
- Fig.11劣于Fig.10的理由也是外层 unpack C更复杂;
- 最终剩下Fig.8和Fig.10。Fig.8在第四列处理竖着的小slice时,列主序是内存连续的,行主序不连续。Fig.8更适合列主序。
因此最终结论是:列主序用Fig.8最优;行主序用Fig.10最优。
参数选择
好比细胞由分子构成,分子由原子构成,矩阵乘法拆分到底层必然有几种基础形态嘛。论文列举了这么三个:
- GEBP
- GEPB
- GEPDOT
然后提出了在 5 个前提都满足的情况下,理想的GEBP的计算过程和开销是怎么样的。
前 3 个前提不考虑 TLB,假设只有 内存、cache 和 ALU :
- mc * kc 要小,小到 『 A + B的 nr 列 + C 的 nr 列 』能够一起塞进 cache
- 如果 1. 被满足,CPU 计算时不再受内存速度的限制,即得到的gflops值就是真实的计算能力
- A 或 A 的分块只会被加载进 Cache 一次,gemm过程中不会被换入又换出
后 2 个要考虑 TLB,因为 TLB miss 会 stall CPU: - mc 和 kc 要小,小到 『 A + B的 nr 列 + C 的 nr 列 』能够被 TLB 索引,即一定是小于 L2 cache 的。
- A 或 A 的分块只被加载到 L2 cache 一次
因为Fig.8用的就是GEBP,所以想要高gflops就得满足上面 5 个条件。落到实处上就是一些参数限制,这些限制也是 OpenBLAS level3.c循环里写一堆if-else的理论根源:
- mc ≈ kc
- nr ≥ (Rcomp / 2 / Rload),其中 Rcomp 是算力、Rload 是 L2 cache 到 register 的带宽
- mc * kc ≤ K
- mc * kc 只能占 cache 的一半
论文一定要自个翻翻,没有理论基础的研发和咸鱼有什么区别?
四、OpenBLAS 代码结构
一点点分析代码如同嚼蜡,我们加个自己的函数cblas_mygemm,写过一次自然就懂了。
我把整个OpenBLAS 0.2.20拉下来加了cblas_mygemm函数。可以用Beyond Compare之类的代码比较工具和原始的版本对比,差异一目了然。修改后的代码在git项目。
 蓝色的是编译生成的文件,目前可忽略;红色的才是发生增改的文件。增加一个gemm函数其实只需要修改interface、driver/level3和相关的Makefile,熟悉的话十多分钟就好。下面我们细细的讲。
蓝色的是编译生成的文件,目前可忽略;红色的才是发生增改的文件。增加一个gemm函数其实只需要修改interface、driver/level3和相关的Makefile,熟悉的话十多分钟就好。下面我们细细的讲。
头文件和声明
cblas.h是OpenBLAS库的头文件,我们加个自己的函数声明。方便起见,直接拷贝cblas_sgemm的入参。

小技巧
之前有小朋友说弄了很久不知道怎么加函数,不知道怎么写的时候,搜索 cblas_sgemm 的实现照着改就行。Mac 和 Linux 系统可以用 find . -type f | xargs grep cblas_sgemm命令。
口函数
所有blas函数的入口都在interface目录,cblas_sgemm的入口是gemm.c。方便起见,我把gemm.c拷贝了一份,重命名为mygemm.c,作为cblas_mygemm的入口。

简单起见,我删掉了原gemm.c里的多线程,下面我们只看单线程时mygemm.c都有啥:
输入行列主序和转置的处理
我们直接从 179行 CNAME 开始看,忽略上面的 NAME 定义的函数头,二者功能完全一样,都是把输入调整为列主序方式,如下图:
 若为CblasRowMajor则交换 args.a 和args.b指针指向的数据和相关的 ldx,这样才能复用内部的 level3.c做一列乘以一行。
若为CblasRowMajor则交换 args.a 和args.b指针指向的数据和相关的 ldx,这样才能复用内部的 level3.c做一列乘以一行。
参数组装完毕后,真正的矩阵乘法实现在 338 行
(gemm[(transb << 2) | transa])(&args, NULL, NULL, sa, sb, 0);
这里用的是函数指针数组gemm,我们看一下它的定义:
 原始的interface/gemm.c里这个函数指针数组里有很多内容,其实真正有用的就 4 个: NN/NT/TN/TT,分别对应着 AB 是否已转置的 4 种情况。MYGEMM_NN 的意思是 AB 都不是转置矩阵,正常计算即可。
原始的interface/gemm.c里这个函数指针数组里有很多内容,其实真正有用的就 4 个: NN/NT/TN/TT,分别对应着 AB 是否已转置的 4 种情况。MYGEMM_NN 的意思是 AB 都不是转置矩阵,正常计算即可。
MYGEMM_NN 只是一个宏定义,具体对应着哪个函数是条件编译决定的,可能是sgemm_nn,也可能是cgemm_nn。配置MYGEMM_NN的.h文件搜索一下就能找到:

 先是在common_macro.h里把 MYGEMM_NN映射为MYSGEMM_NN,然后又映射为mysgemm_nn。
先是在common_macro.h里把 MYGEMM_NN映射为MYSGEMM_NN,然后又映射为mysgemm_nn。
mysgemm_nn这个函数又是在哪儿实现的的?有 NN/NT/TN/TT,岂不是要写 4 个几乎一样的函数?
模板实现
我们打开/driver/level3/Makefile,看一下主要差异:
 可以看到真正的代码文件只有一个level3_mygemm.c,用-DNN -DNT -DTN -DTT产生了不同的函数,分别对应
可以看到真正的代码文件只有一个level3_mygemm.c,用-DNN -DNT -DTN -DTT产生了不同的函数,分别对应
mysgemm_nn/mysgemm_nt/mysgemm_tn/mysgemm_tt
我们再打开driver/level3/level3_mygemm.c,看-DNN之类的宏是怎么产生作用的:
 仍然是宏定义的玩法:既然这里写了这个宏,可以推测出来level3_mygemm.c里用到了OCOPY_OPERATION,如果定义了-DNN -DTN,OCOPY_OPERATION的实现就是GEMM_OTCOPY;否则就是GEMM_ONCOPY。这个文件还用了ICOPY_OPERATION,套路是一样的。
仍然是宏定义的玩法:既然这里写了这个宏,可以推测出来level3_mygemm.c里用到了OCOPY_OPERATION,如果定义了-DNN -DTN,OCOPY_OPERATION的实现就是GEMM_OTCOPY;否则就是GEMM_ONCOPY。这个文件还用了ICOPY_OPERATION,套路是一样的。
如果刷过上文git或者论文原文,应该知道所谓ICOPY OCOPY就是PackA PackB的作用。
矩阵乘法核心实现在 driver/level3/level3_mygemm.c 287~389 行,简单起见可以注释掉复数、double 和 FUSED 相关代码,只保留单精度实数计算。
看懂它需要先看懂上文的论文和git项目,思路几乎一样:先取内存不连续的一小块 A 做 pack,长驻 Cache 直到不再被需要;再对 B 做 pack; 再做和 AddDot4x4效果类似的KERNEL_OPERATION。
编译测试
自己的函数写完之后,可以在OpenBLAS-0.2.20/ctest增加一个测试用例,示例Makefile已经提供:

 ctest和项目本身是分开编译的,测试函数的Makefile文件只是依赖…/Makefile.system,完全可以自己大改。以arm64为例,完整的编译命令为:
ctest和项目本身是分开编译的,测试函数的Makefile文件只是依赖…/Makefile.system,完全可以自己大改。以arm64为例,完整的编译命令为:
cd $OPENBLAS_DIR
make TARGET=ARMV8 HOSTCC=gcc CC=aarch64-linux-gnu-gcc NOFORTRAN=1 NUM_THREADS=40 #编译OpenBLAS库
cd ctest
make TARGET=ARMV8 HOSTCC=gcc CC=aarch64-linux-gnu-gcc NOFORTRAN=1 NUM_THREADS=40 #编译测试用例
如果需要单步调试看运行过程,可以加DEBUG=1。其他平台的编译命令可以翻阅OpenBLAS官方文档。
提示
本来担心分析代码的文字太枯燥,真正写出来发现只看文章还是很虚。要真正理解还是得把项目拉下来,自己模仿着加个函数跑一遍,文章只是无足轻重的参考资料。
五、OpenBLAS gemm 分析
大神用的OCOPY ICOPY KERNEL_OPERTION具体干了些啥?
矩阵乘法的极限是多少,还有多少提升空间?
硬件极限测速
可参照商汤高洋在知乎专栏写的浮点峰值那些事儿。
这里测试单核 gflops代码如下:
// func2.S 每次循环做 40 次乘法,每条指令处理 4 个 float,共 10 条。
.text
.align 5
.global func2
func2:
.loop2:
fmla v0.4s, v0.4s, v0.4s
fmla v1.4s, v1.4s, v1.4s
fmla v2.4s, v2.4s, v2.4s
fmla v3.4s, v3.4s, v3.4s
fmla v4.4s, v4.4s, v4.4s
fmla v5.4s, v5.4s, v5.4s
fmla v6.4s, v6.4s, v6.4s
fmla v7.4s, v7.4s, v7.4s
fmla v8.4s, v8.4s, v8.4s
fmla v9.4s, v9.4s, v9.4s
subs x0, x0, #1
bne .loop2
ret
由于A57架构指令延迟是10个cycle,吞吐是1(每条fmla都要用掉全部的NEON向量单元),因此每次loop2都做了 80 次乘加。
调用这个函数也很容易:
#include <time.h>
#include <stdio.h>
#define LOOP (1e9)
#define OP_FLOATS (80)
void func1(int);
void func2(int);
static double get_time(struct timespec *start,
struct timespec *end) {
return end->tv_sec - start->tv_sec + (end->tv_nsec - start->tv_nsec) * 1e-9;
}
int main() {
struct timespec start, end;
double time_used = 0.0;
clock_gettime(CLOCK_MONOTONIC_RAW, &start);
// func1(LOOP);
func2(LOOP);
clock_gettime(CLOCK_MONOTONIC_RAW, &end);
time_used = get_time(&start, &end);
printf("perf: %.6lf \r\n", LOOP * OP_FLOATS * 1.0 * 1e-9 / time_used);
}
ubuntu@tegra-ubuntu:~/Desktop/how-to-optimize-gemm/gflops_benchmark$ ./make.sh
ubuntu@tegra-ubuntu:~/Desktop/how-to-optimize-gemm/gflops_benchmark$ ./main
perf: 6.914745
在我的设备上的测试结果 14 gflops不到,对比目前实现的矩阵乘法版本4.8 gflops,还有很多提升空间。
tx1测试代码也在git项目。
OpenBLAS 细节
sgemm的接口原型参见blas官网,前文也说过OpenBLAS/MKL/cuBLAS等都是BLAS接口的一种实现,各种实现的函数名、功能和入参大体接近:
sgemm: C = alpha* A* B + beta*C
ABC均为矩阵,alpha/beta是系数
我们假设测试用的参数如下:
M=4 K=4 N=8 alpha=1 beta=0
则A是 4x4 矩阵,内容为

B是 4x8 的矩阵,也初始化为整数(实际存储是float32)

易知 C 是 4x8 的矩阵,C 初始化为空矩阵。
然后在{OpenBLAS_DIR}/ctest加个单测函数,gdb debug工作过程。如果加过自己的blas函数应该轻车熟路,这里不再给出代码。
交换AB
可能是历史或者LAPACK的原因,论文和OpenBLAS代码都更倾向于列主序。我们测试用的是行主序,在interface/gemm.c里如果发现是行主序则交换AB指针。
 交换完毕后,传给driver/level3.c的args的参数是这样
交换完毕后,传给driver/level3.c的args的参数是这样
(gdb) p args
$1 = {a = 0x425080, b = 0x425030, c = 0x425110, d = 0x4c5043006d6d6567,
alpha = 0x7fffffeec4, beta = 0x7fffffeeac, m = 8, n = 4, k = 4, lda = 8,
ldb = 4, ldc = 8, ldd = 0, option = 549755809760, common = 0x0, nthreads = 1}
(gdb) x/32fw args.a
0x425080: 0 1 2 3
0x425090: 4 5 6 7
0x4250a0: 8 9 10 11
0x4250b0: 12 13 14 15
0x4250c0: 16 17 18 19
0x4250d0: 20 21 22 23
0x4250e0: 24 25 26 27
0x4250f0: 28 29 30 31
(gdb) x/32fw args.b
0x425030: 0 1 2 3
0x425040: 4 5 6 7
0x425050: 8 9 10 11
0x425060: 12 13 14 15
0x425070: 3.00134084e-11 0 2.03188277e-43 0
0x425080: 0 1 2 3
0x425090: 4 5 6 7
0x4250a0: 8 9 10 11
然后我们来到driver/level3.c,调用具体的sgemm_nn。
由于MNK值都很小,分块用的嵌套循环基本起不到分块的作用,ICOPY/OCOPY/KERNEL都只执行一次。
ICOPY_OPERATION
ICOPY的作用是重排args.a。由于要兼容armv7/arm64/x86各种硬件,它的实现是基于配置的。打开${OpenBLAS_DIR}/kernel/arm64/KERNEL.ARMV8查看arm64相关配置项。
SGEMMITCOPY = …/generic/gemm_tcopy_4.c
即ICOPY_OPERATION真正的实现是gemm_tcopy_4.c,具体做的事情是以最大 4x4 为单位,之字形展开矩阵。即:

跑完ICOPY,a会调整到sa:
0x7fb5dfb000: 0 1 2 3
0x7fb5dfb010: 8 9 10 11
0x7fb5dfb020: 16 17 18 19
0x7fb5dfb030: 24 25 26 27
0x7fb5dfb040: 4 5 6 7
0x7fb5dfb050: 12 13 14 15
0x7fb5dfb060: 20 21 22 23
0x7fb5dfb070: 28 29 30 31
OCOPY_OPERATION
同ICOPY类似,OCOPY的实现是gemm_ncopy_4.c。具体工作也是展开,不过是竖之字形 4x4 展开:
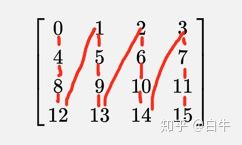
b将展开为sb:
0x7fb5e77000: 0 4 8 12
0x7fb5e77010: 1 5 9 13
0x7fb5e77020: 2 6 10 14
0x7fb5e77030: 3 7 11 15
KERNEL_OPERATION
我们不着急看具体KERNEL做了什么,先整理一下思路,已知整个计算结果和重排后的输入,推测KERENL将实现什么功能。
假设我们原本要计算

结果是一样的。
上文ICOPY和OCOPY操作要表达的意思就是横竖向分解,现在只缺乘法和累加。
KERNEL的实现是sgemm_kernel_4x4.S。我们看几个关键的位置:
- 压栈和初始化
PROLOGUE
.align 5
add sp, sp, #-(11 * 16)
stp d8, d9, [sp, #(0 * 16)]
stp d10, d11, [sp, #(1 * 16)]
stp d12, d13, [sp, #(2 * 16)]
stp d14, d15, [sp, #(3 * 16)]
stp d16, d17, [sp, #(4 * 16)]
stp x18, x19, [sp, #(5 * 16)]
stp x20, x21, [sp, #(6 * 16)]
stp x22, x23, [sp, #(7 * 16)]
stp x24, x25, [sp, #(8 * 16)]
stp x26, x27, [sp, #(9 * 16)]
str x28, [sp, #(10 * 16)]
fmov alpha0, s0
fmov alpha1, s0
fmov alpha2, s0
fmov alpha3, s0
主要是因为寄存器是有限的,写汇编的时候偶尔会出现寄存器不够导致无法暂存中间结果和控制变量的尴尬。对于简单的操作(例如上文的测速代码)可以不压。
.macro INIT8x4
fmov s16, wzr // 清零
fmov s17, s16
fmov s18, s17
fmov s19, s16
fmov s20, s17
fmov s21, s16
fmov s22, s17
fmov s23, s16
fmov s24, s17
fmov s25, s16
fmov s26, s17
fmov s27, s16
fmov s28, s17
fmov s29, s16
fmov s30, s17
fmov s31, s16
.endm
...
.Lsgemm_kernel_L4_M8_20:
INIT8x4 // clear all reg
...
INIT8x4只是初始化操作用的寄存器,并且乱序增大并行度。
乘法和累加
设置控制变量后,将在.Lsgemm_kernel_L4_M8_42调用 4 次KERNEL8x4_SUB:
.Lsgemm_kernel_L4_M8_42:
KERNEL8x4_SUB
subs counterL, counterL, #1
bgt .Lsgemm_kernel_L4_M8_42
每次KERNEL8x4_SUB会取args.b的 4 个值和args.a的 2 x 4 个值,算成一个 4x8 的矩阵,累加进v16~v31里。
.macro KERNEL8x4_SUB
ld1 {v8.2s, v9.2s}, [pB]
add pB, pB, #16 //一次读args.b的4个float
ld1 {v0.2s, v1.2s}, [pA_0]
add pA_0, pA_0, #16 //第一次读args.a
fmla v16.2s, v0.2s, v8.s[0] //计算成小矩阵,然后在多次循环里累加
fmla v29.2s, v1.2s, v9.s[1]
fmla v20.2s, v0.2s, v8.s[1]
fmla v25.2s, v1.2s, v9.s[0]
ld1 {v2.2s, v3.2s}, [pA_1]
add pA_1, pA_1, #16
fmla v24.2s, v0.2s, v9.s[0]
fmla v21.2s, v1.2s, v8.s[1]
fmla v28.2s, v0.2s, v9.s[1]
fmla v17.2s, v1.2s, v8.s[0]
fmla v18.2s, v2.2s, v8.s[0]
fmla v31.2s, v3.2s, v9.s[1]
fmla v22.2s, v2.2s, v8.s[1]
fmla v27.2s, v3.2s, v9.s[0]
fmla v26.2s, v2.2s, v9.s[0]
fmla v23.2s, v3.2s, v8.s[1]
fmla v30.2s, v2.2s, v9.s[1]
fmla v19.2s, v3.2s, v8.s[0]
.endm
不妨在纸上画一下这个小的 4x8 矩阵,拆解成这种小规模的函数后很容易看懂。
写回结果
如果只算AB,写回就是直接用st指令就行。但BLAS的接口是C=alphaAB + betaC,写回的时候需要算alpha。至少卷积计算不需要关心alpha/beta。
.macro SAVE8x4
mov pCRow1, pCRow0
ld1 {v0.2s, v1.2s}, [pCRow1]
fmla v0.2s, v16.2s, alphaV0
fmla v1.2s, v17.2s, alphaV1
st1 {v0.2s, v1.2s}, [pCRow1]
…
退栈
最后就是恢复入参,返回结果。
.Lsgemm_kernel_L999:
mov x0, #0 // set return value
ldp d8, d9, [sp, #(0 * 16)]
ldp d10, d11, [sp, #(1 * 16)]
ldp d12, d13, [sp, #(2 * 16)]
ldp d14, d15, [sp, #(3 * 16)]
ldp d16, d17, [sp, #(4 * 16)]
ldp x18, x19, [sp, #(5 * 16)]
ldp x20, x21, [sp, #(6 * 16)]
ldp x22, x23, [sp, #(7 * 16)]
ldp x24, x25, [sp, #(8 * 16)]
ldp x26, x27, [sp, #(9 * 16)]
ldr x28, [sp, #(10 * 16)]
add sp, sp, #(11*16)
ret
EPILOGUE
其他
level3.c 里的大循环共一百多行C和二十多个字母变量,其实都是是分块方法,见下一篇 GEMM caching。
