基于python语音控制大疆创新EP机器人并进行对话——第一步学会录音
hello,大家好,想必大家都知道S1机器人吧,拥有麦克纳姆轮,能够任意旋转,拥有发射器,可以
发射子弹,但是S1的缺点就是没有开发SDK,新出的EP机器人就开放了SDK,满足了我们可以任意开发的需求,下面我们就学习怎么样通过python语音控制机器人吧!
自己的一点点想法
自己的想法,认为是对的就采取,不对的就不看进行啦,第一次写,希望多多包涵,学习编程,我觉得不用把每一行代码弄清楚,只需要知道这一块代码是干什么用的就OK了,还有就是学习编程语言的基础,那么写一般的程序就小意思啦,用到代码基本上网上都有,一查一大片,不说了,开始学习吧
编程思维很重要,我们想想怎么样去完成,分步骤
完成python语音控制 录音——百度AI识别并转化成文本——发送给机器人——机器人执行 这就是主要的步骤,但是这样显的太枯燥了,所以我打算加入图灵对话,使得语音控制更加有趣,下面开始手把手教你们怎么样录音。
第一步安装python
python在任何平台都能使用,我的是win10 64位
步骤一 下载安装包
我们从Python官方网站:http://www.Python.org下载Python的安装包


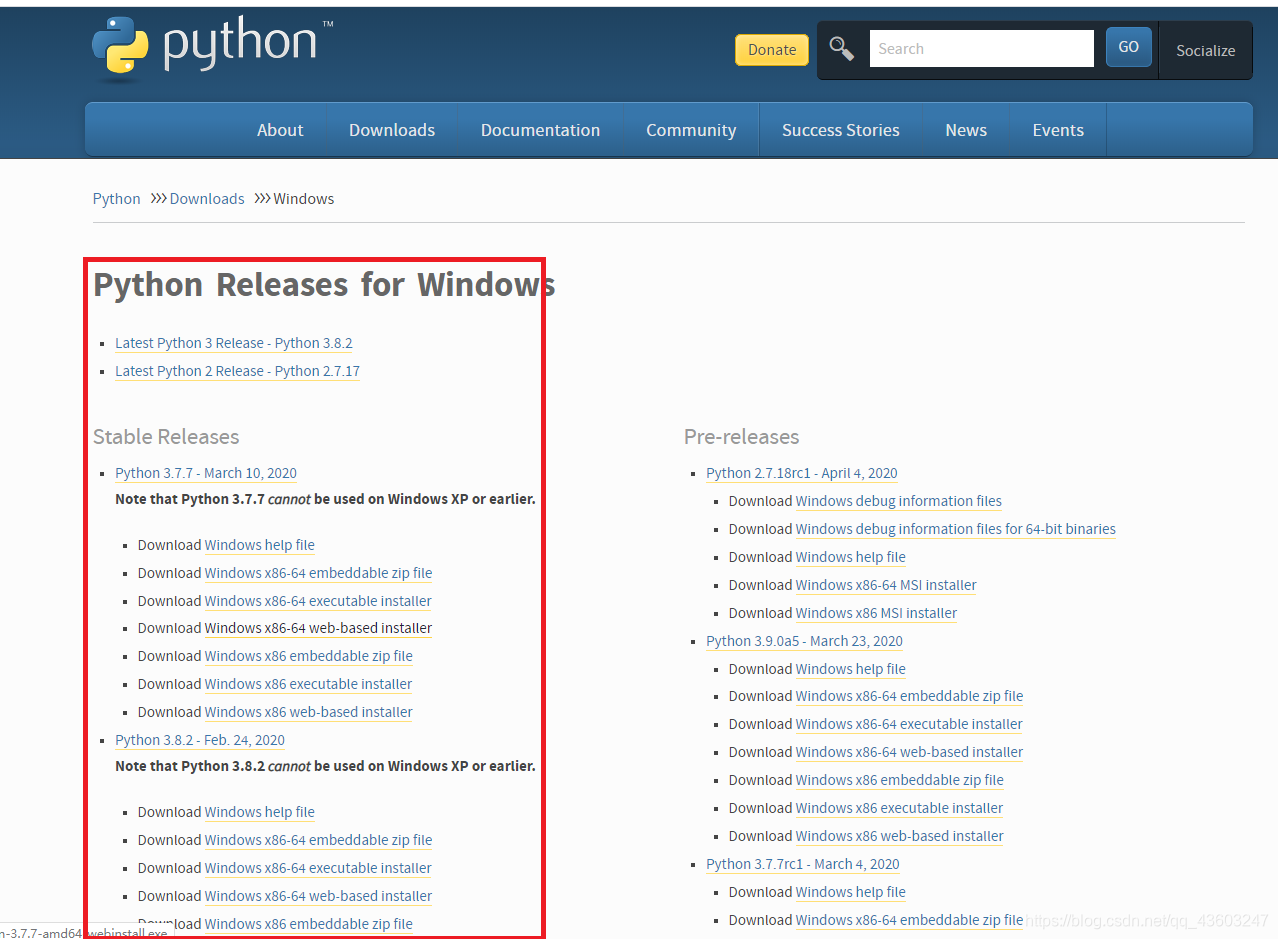
我下载的是Windows x86-64 embeddable zip file,实在下的太慢了,如果等不了的朋友,可以到百度网盘下载,推荐微信上搜索软件安装管家里面的软件目录就有很多很多软件,下面我直接给出链接吧
名称]:Python3.8.2
[大小]:51 MB
[语言]:英文
[安装环境]:Win7/Win8/Win10
[32/64位下载链接]:
pan.baidu.com/s/1NW6x_61vDRrUU2y4sPCqGA
[提取码]: 8i72
下载完以后减压就可以得到安装包啦
我一开始想在官网下载,但是实在是太慢,所以我选择百度网盘下载的安装,安装的是python-3.8.2-amd64.exe,因为我是64位的电脑,所以安装64位的python。
步骤二 安装






步骤三 路径设置
一般情况下,我们安装好Python之后便可以直接使用。可以在命令行下输入Python看是否可以进入Python的交互模式,(进入命令行win +R,输入cmd就可以了)
如果不能进入,则有可能是环境变量问题,需要做一些调整。
在Windows的路径添加Python的目录:
命令提示符 : 类似于环境变量路径 %path%;C:Python ,回车;
或者您可以在图形界面下操作设置环境变量,计算机->属性->高级系统设置->高级->环境变量

这样我们就安装完成了。
安装windows环境
我们将使用pip命令安装,就是在命令行输入pip install ----
用python录音的时候我们需要用到 wave库和PyAudio库
安装wave库,pip install wave 就OK了
在我们安装PyAudio库,因为Windows安装这个有点麻烦,我安装的时候就出现了错误,下面我就将一下我是怎么样安装的

去https://www.lfd.uci.edu/~gohlke/pythonlibs/找到对应版本的whl文件,我的话就是找wordcloud-1.5.0-cp37-cp37m-win32.whl这一个,其中cp37代表3.7版本,win32代表Windows系统32位机。
我刚刚安装的是CP38,64位,所以我下载的是PyAudio‑0.2.11‑cp38‑cp38‑win_amd64.whl

把刚刚下载的文件放在文件夹,我是在c盘创建了一个python文件夹

以前是在C:\Users\86135,下面通过cd C:\python命令把目录转移的C:python文件夹

下面我们通过pip命令安装PyAudio——pip install PyAudio-0.2.11-cp38-cp38-win_amd64.whl
出现下面这种情况就安装OK了

怎么样写代码
打开python 的IDLE


这样就可以开始写代码啦
录音代码
import pyaudio
import wave
def record():
CHUNK = 1024
FORMAT = pyaudio.paInt16
CHANNELS = 1
RATE = 16000
RECORD_SECONDS = 2
WAVE_OUTPUT_FILENAME = "output.wav"
p = pyaudio.PyAudio()
stream = p.open(format=FORMAT,
channels=CHANNELS,
rate=RATE,
input=True,
frames_per_buffer=CHUNK)
frames = []
print('* 开始录音 >>>')
for i in range(0, int(RATE / CHUNK * RECORD_SECONDS)):
data = stream.read(CHUNK)
frames.append(data)
print('* 结束录音 >>>')
stream.close()
p.terminate()
wf = wave.open(WAVE_OUTPUT_FILENAME, 'wb')
wf.setnchannels(CHANNELS)
wf.setsampwidth(p.get_sample_size(FORMAT))
wf.setframerate(RATE)
wf.writeframes(b''.join(frames))
wf.close()
record()
把代码copy下来
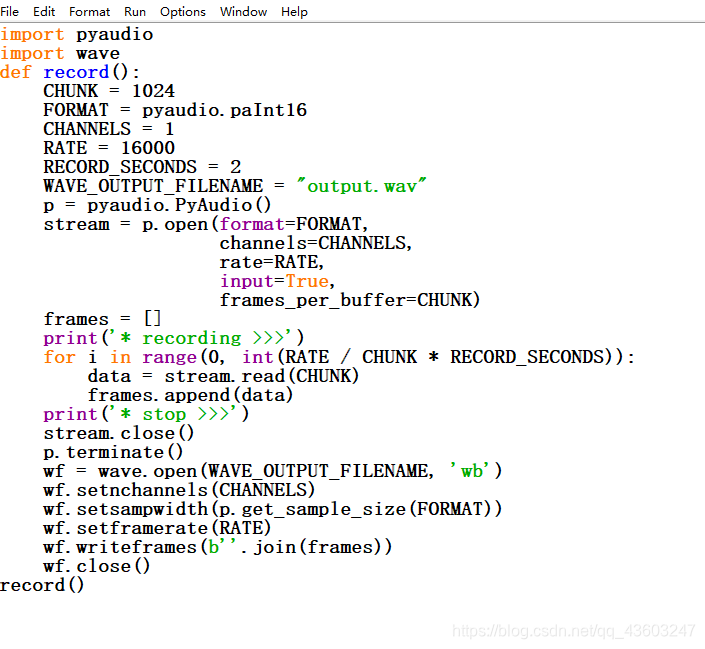
按住F5或者Ctrl+F5运行程序
运行完以后我们就在文件夹中找刚刚的录音文件啦

我们可以播放看是不是我们的声音!
第一步我们就先到这里啦,第一次写,如果有不对的地方,欢迎多多指教。
参考资料
wave库
pyAudio库
大疆公开代码
