在上一篇文章《Hadoop-源码分析--FileSystem的创建过程》中我们分析了HDFS的DistributedFileSystem对象的创建过程,之后就可以按照HDFS的API对HDFS中的文件和目录进行操作了,如列出某个目录中的文件和子目录、读取文件、写入文件等。与使用Java IO读取本地文件类似,读取HDFS文件其实就是创建一个文件输入流,在Hadoop中使用FileSystem.open()方法来创建输入流。
由下面的下例子入手。
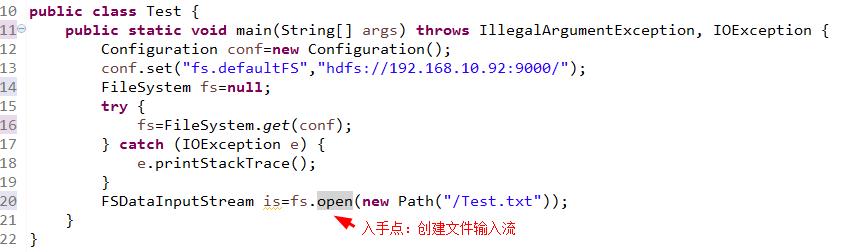
进入open(Path f)方法,该方法返回的是一个FSDataInputStream对象。

进入open(Path f, final int bufferSize)方法,该方法隶属于DistributedFileSystem类,在该方法中,statistics是一个org.apache.hadoop.fs.FileSystem.Statistics类型,它实现了文件系统读写过程中的一些统计,例如自从该HDFS对象建立以来,读了多少字节、写了多少字节等。在返回结果的时候,创建了一个FileSystemLinkResolver对象,并实现了此类的两个抽象方法, 最后调用了resolve()方法,其中doCall()方法和next()方法都在resolve()方法里用到了,只是next()方法只是在resolve()方法异常捕获时才调用。所以跟踪doCall()方法,doCall()方法里的open()方法有3个参数其中src表示要打开的文件路径,buffersize表示缓冲大小,verifyChecksum表示是否校验和。
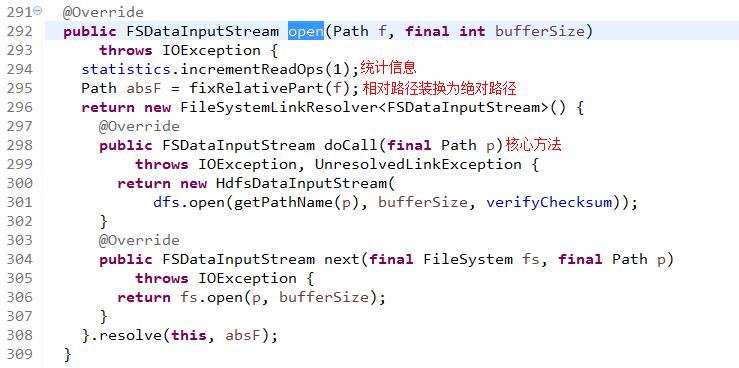
进入到DFSClient.open(String src, int buffersize, boolean verifyChecksum)方法,checkOpen()方法表示检查文件系统是否已经打开,如果没有打开,则抛出异常--FileSystem closed。最后,在这个方法中调用了DFSClient.DFSInputStream()的构造方法,创建DFSInputStream输入流对象并返回(DFSInputStream是对客户端读取的输入流的抽象)。

进入该构造方法,该方法先是做了一些准备工作,然后调用openInfo()方法,openInfo()方法是一个线程安全的方法,作用是从namenode获取要打开的文件的数据块信息。也就是说主要是为locatedBlocks对象赋值。

进入openInfo()方法,该方法中如果读取数据块信息失败,则会再次读取3次,主要调用了方法fetchLocatedBlocksAndGetLastBlockLength()方法来读取数据块的信息。该方法名字虽然长,但是说的很明白,即读取数据块信息并且获得最后一个数据块的长度。为什么偏偏要获取最后一个数据块的长度呢?因为之前的数据块大小固定嘛,如果是默认的,那就是128M,而最后一块大小就不一定了,有必要获取下。
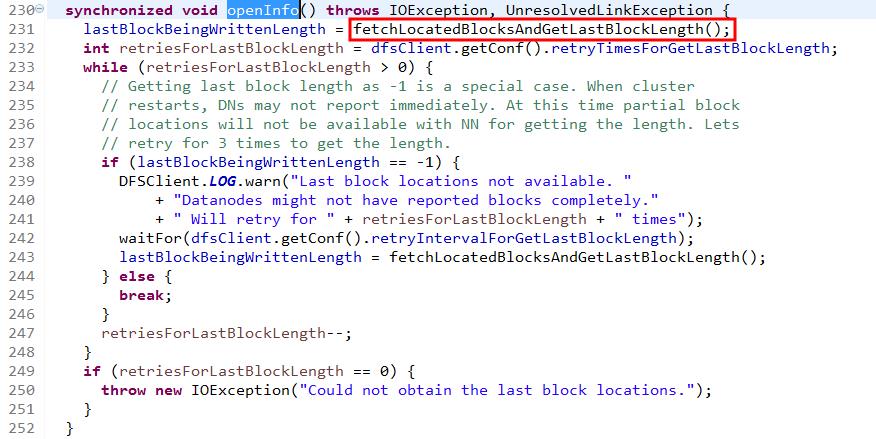
进入fetchLocatedBlocksAndGetLastBlockLength()方法。
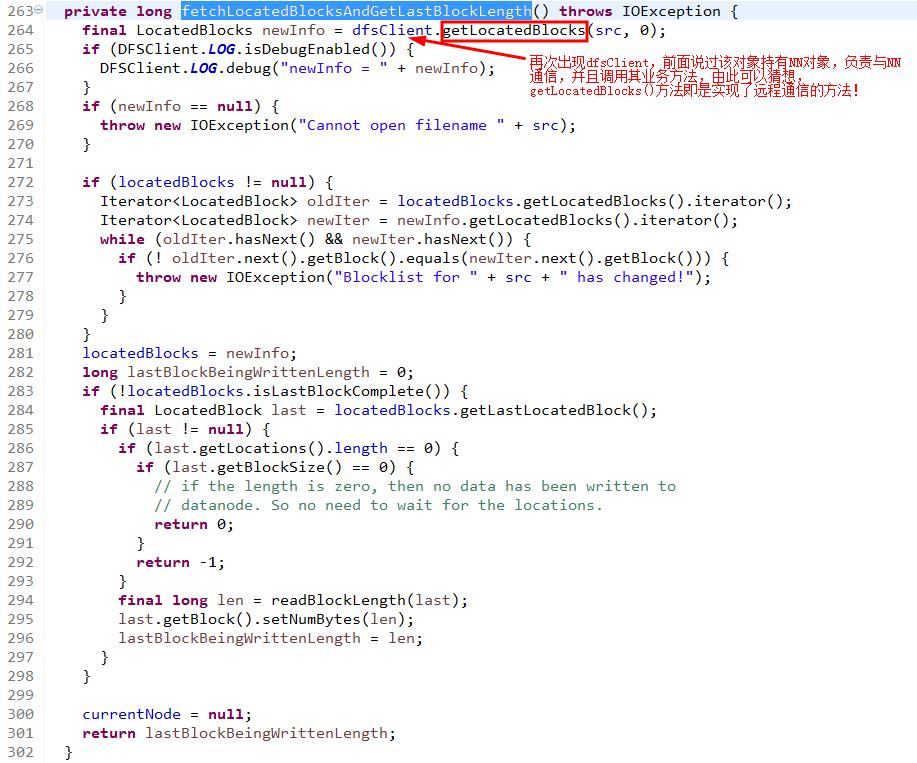
进入getLocatedBlocks(String src, long start)方法。

进入getLocatedBlocks(String src, long start, long length)方法。

进入callGetBlockLocations(ClientProtocol namenode,String src, long start, long length)方法。该方法涉及RPC的远程调用,原理见 http://blog.csdn.net/u010010428/article/details/51345693 这篇日志。
