1.安装
用python 模仿http请求 我是利用python中的requests 模块
1)首先 安装 requests
打开(cmd) 输入 pip install request
然后会自动下载安装 如果在下载过程中提示 超时 多试几次就可以
完成后 再次输入 pip install request //注意 这里我用的是 request 不是 requests
如果显示为下图 说明 安装完成
C:\Users\23501>pip install request
Requirement already satisfied: request in c:\users\23501\appdata\local\programs\python\python38\lib\site-packages (2019.4.13)
Requirement already satisfied: get in c:\users\23501\appdata\local\programs\python\python38\lib\site-packages (from request) (2019.4.13)
Requirement already satisfied: post in c:\users\23501\appdata\local\programs\python\python38\lib\site-packages (from request) (2019.4.13)
Requirement already satisfied: setuptools in c:\users\23501\appdata\local\programs\python\python38\lib\site-packages (from request) (41.2.0)
Requirement already satisfied: query_string in c:\users\23501\appdata\local\programs\python\python38\lib\site-packages (from get->request) (2019.4.13)
Requirement already satisfied: public in c:\users\23501\appdata\local\programs\python\python38\lib\site-packages (from query_string->get->request) (2019.4.13)
2)在python中 导入 requests
在(cmd)中输入python
然后 导入 requests
如下
C:\Users\23501>python
Python 3.8.1 (tags/v3.8.1:1b293b6, Dec 18 2019, 23:11:46) [MSC v.1916 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import requests
>>>
2.利用requests的方法
1)补充一下requests 方法
response.text 该方式往往出现乱码,出现乱码使用 response.encoding='utf-8'
response.content.decode()把响应的二进制字节流转化为str类型
response.request.url 发送请求的url地址
response.url #respons响应的url
response.request.headers #请求头
response.headers #响应请求
2)获取网站信息
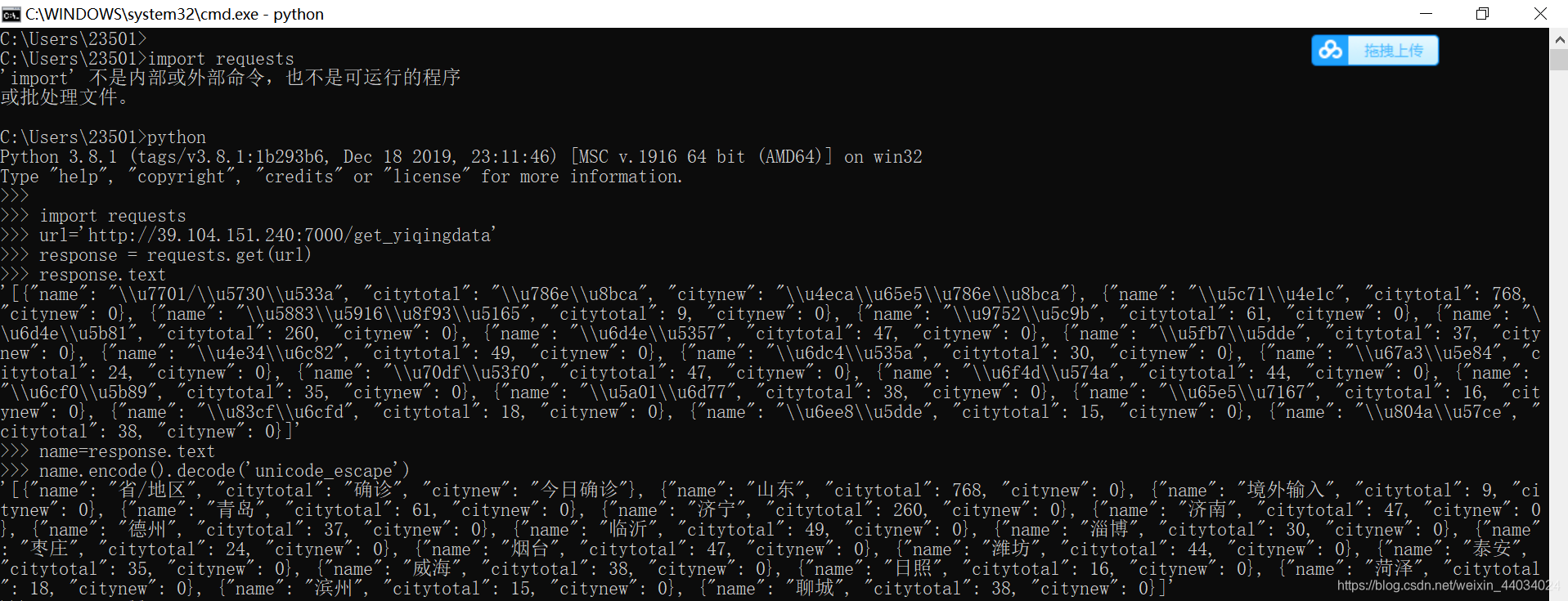
C:\Users\23501>python
Python 3.8.1 (tags/v3.8.1:1b293b6, Dec 18 2019, 23:11:46) [MSC v.1916 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import requests
>>> url='http://39.104.151.240:7000/get_yiqingdata'
>>> response = requests.get(url)requests.get(url) #发送get请求,请求url对应的响应
>>> response.text
'[{"name": "\\u7701/\\u5730\\u533a", "citytotal": "\\u786e\\u8bca", "citynew": "\\u4eca\\u65e5\\u786e\\u8bca"}, {"name": "\\u5c71\\u4e1c", "citytotal": 768, "citynew": 0}, {"name": "\\u5883\\u5916\\u8f93\\u5165", "citytotal": 9, "citynew": 0}, {"name": "\\u70df\\u53f0", "citytotal": 47, "citynew": 0}, {"name": "\\u9752\\u5c9b", "citytotal": 61, "citynew": 0}, {"name": "\\u6d4e\\u5357", "citytotal": 47, "citynew": 0}, {"name": "\\u5fb7\\u5dde", "citytotal": 37, "citynew": 0}, {"name": "\\u4e34\\u6c82", "citytotal": 49, "citynew": 0}, {"name": "\\u6dc4\\u535a", "citytotal": 30, "citynew": 0}, {"name": "\\u67a3\\u5e84", "citytotal": 24, "citynew": 0}, {"name": "\\u6d4e\\u5b81", "citytotal": 260, "citynew": 0}, {"name": "\\u6f4d\\u574a", "citytotal": 44, "citynew": 0}, {"name": "\\u6cf0\\u5b89", "citytotal": 35, "citynew": 0}, {"name": "\\u5a01\\u6d77", "citytotal": 38, "citynew": 0}, {"name": "\\u65e5\\u7167", "citytotal": 16, "citynew": 0}, {"name": "\\u83cf\\u6cfd", "citytotal": 18, "citynew": 0}, {"name": "\\u6ee8\\u5dde", "citytotal": 15, "citynew": 0}, {"name": "\\u804a\\u57ce", "citytotal": 38, "citynew": 0}]'
>>>
此时需要将ASCII的编码字符串转为中文
3)乱码转化为中文
利用python 的 encode().decode(‘unicode_escape’)方法将 乱码转化为中文
>>> name=response.text //将抓取的text 给name
//name 调用encode().decode('unicode_escape')方法
>>> name.encode().decode('unicode_escape')
最终结果如下
在下是一名小白 如果有不恰当的地方 欢迎指正
