1 .MapReduce on yarn 流程
MapReduce
Map 映射 Reduce 聚合
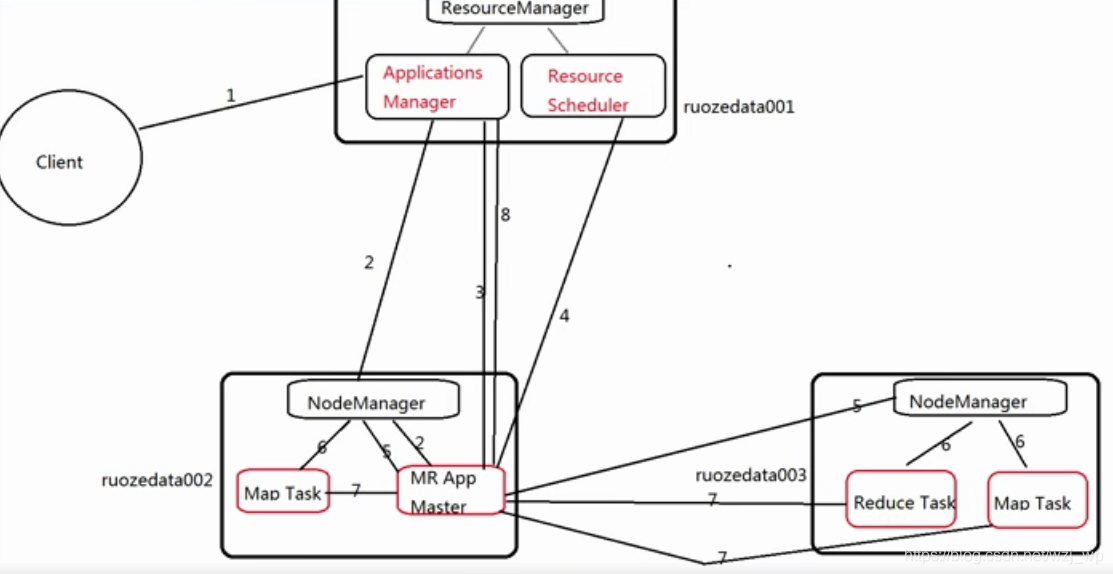
mr on yarn的工作流程分为两步:
1.启动应用程序管理器,申请资源。
2.运行任务,直到任务运行完成。
mr on yarn的工作流程详细分为八步:
1.用户向Yarn提交应用程序(job app application),jar文件、sql;
其中包裹ApplicationMaster程序、启动ApplicationMaster的命令等等
2.资源管理器为该应用程序分配一个容器(Container),运行job的ApplicationMaster,并与对应的节点管理器(NodeManager)通信,要求它在这个容器中启动MapReduce应用程序管理器。
3.App Master向applications Manager注册,这样就可以在RM WEB界面查询这个job的运行状态
4.App Master采用轮询的方式通过RPC协议向RM申请和领取资源
5.App Master应用程序管理器申请到资源后,便与对应的节点管理器通信,要求启动任务。
6.节点管理器为任务设置好运行环境,包括环境变量、Jar包、二进制程序等,然后将任务启动命令写到另外一个脚本中,并通过该脚本启动任务(task)。
7.各个任务(task)通过RPC协议向App Master应用程序管理器汇报自己的状态和进度,App Master应用程序随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务。在应用程序运行过程中,用户可以随时通过RPC协议向MapReduce应用程序管理器查询应用程序当前的运行状态。
8.应用程序运行完成后,App Master应用程序管理器向资源管理器注销并关闭自己。
2. spilt -->map task /reduce task
[wzj@hadoop001 ~]$ hadoop fs -ls /wordcount/input/
19/12/20 13:41:01 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Found 1 items
-rw-r--r-- 1 wzj supergroup 93 2019-12-02 18:04 /wordcount/input/name.log
[wzj@hadoop001 mapreduce2]$ hadoop jar ./hadoop-mapreduce-examples-2.6.0-cdh5.16.2.jar wordcount /wordcount/input /wordcount/output1
19/12/20 13:44:52 INFO input.FileInputFormat: Total input paths to process : 1
19/12/20 13:44:52 INFO mapreduce.JobSubmitter: number of splits:1
19/12/20 13:44:53 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1576802596314_0001
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
hadoop2.0默认block为128m,此文件不到128M,所以切割也只有一个块,产生map task 1
了解block可以参考我的另外一篇博客:https://blog.csdn.net/wzj_wp/article/details/103459638
[wzj@hadoop001 ~]$ hadoop fs -put name2.log /wordcount/input/
19/12/20 13:49:04 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
[wzj@hadoop001 ~]$ hadoop fs -ls /wordcount/input/
19/12/20 13:49:12 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Found 2 items
-rw-r--r-- 1 wzj supergroup 93 2019-12-02 18:04 /wordcount/input/name.log
-rw-r--r-- 1 wzj supergroup 34 2019-12-20 13:49 /wordcount/input/name2.log
[wzj@hadoop001 mapreduce2]$ hadoop jar ./hadoop-mapreduce-examples-2.6.0-cdh5.16.2.jar wordcount /wordcount/input /wordcount/output2
19/12/20 13:49:35 INFO input.FileInputFormat: Total input paths to process : 2
19/12/20 13:49:35 INFO mapreduce.JobSubmitter: number of splits:2
19/12/20 13:49:35 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1576802596314_0002
Job Counters
Launched map tasks=2
Launched reduce tasks=1
可以对比看到,input下面此时又两个不到128的文件,也就是两个块,产生map task 2,reduce 1
所以我们可以认为map task个数和文件的切片数有关,切片数和文件大小与blocksize设置有关,切片数有多少,产生map task就有多少
官网默认的map和reduce数如下:

mapreduce.job.maps 2
mapreduce.job.reduces 1
PS:尽量在生产上控制一个文件的大小稍微小于一个blocksize,这块也能考虑到为什么我们在生产上要尽量的合并小文件,当文件大小不均匀的时候,一个特别小的文件也会产生一个map task,浪费资源
比如128M 文件为120M
例:假如我们设定hdfs的块的大小是64mb,如果我们输入有三个文件,大小分别是3mb、65mb和127mb,那么mapreduce会把3mb文件分为一个输入分片(input split),65mb则是两个输入分片(input split)而127mb也是两个输入分片(input split),
换句话说我们如果在map计算前做输入分片调整,
例如合并小文件,那么就会有5个map任务将执行,
而且每个map执行的数据大小不均,这个也是mapreduce优化计算的一个关键点
wordcount流程
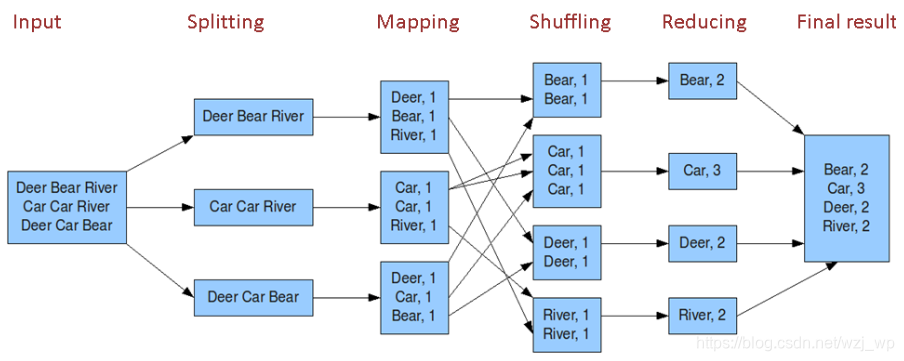
Map任务处理—做映射
读取HDFS中的文件,每一行解析成一个<K,V>值。每个键值对调用一次map函数。
重写map()方法,接收1产生的<K,V>值进行处理,转为新的<K,V>输出。
对2输出的<K,V>值进行分区,默认一盒分区。
对不同分区中的数据进行排序(按照K)、分组。分组指的是相同Key的Value放到一个集合中。
(可选)对分组后的数据进行合并。
Reduce任务处理–做聚合
多个Map任务的输出,按照不同的分区,通过网络copy到不同的Reduce节点上。
对多个map的输出进行合并、排序。重写reduce()方法,接收的是分组后的数据,实现自己的业务逻辑,处理后产生新的<K,V>值输出
对reduce输出的<K,V>写到HDFS中。
Shuffle理解
如上图,shuffle阶段位于map之后,reduce之前,实际上属于reduce阶段,为reduce做准备
shuffle,将具有相同key的值拉去到同一个分区中,为reduce做准备。数据在计算时,因为某些key是海量存在的,导致这些key需要汇集消耗网络IO开销,在计算时也会异常的慢
