RCU(Read-Copy Update),顾名思义就是读-拷贝修改,它是基于其原理命名的。对于被RCU保护的共享数据结构,读者不需要获得任何锁就可以访问它,但写者在访问它时首先拷贝一个副本,然后对副本进行修改,最后使用一个回调(callback)机制在适当的时机把指向原来数据的指针重新指向新的被修改的数据。这个时机就是所有引用该数据的CPU都退出对共享数据的操作。
因此RCU实际上是一种改进的rwlock,读者几乎没有什么同步开销,它不需要锁,不使用原子指令,而且在除alpha的所有架构上也不需要内存栅(Memory Barrier),因此不会导致锁竞争,内存延迟以及流水线停滞。不需要锁也使得使用更容易,因为死锁问题就不需要考虑了。写者的同步开销比较大,它需要延迟数据结构的释放,复制被修改的数据结构,它也必须使用某种锁机制同步并行的其它写者的修改操作。读者必须提供一个信号给写者以便写者能够确定数据可以被安全地释放或修改的时机。有一个专门的垃圾收集器来探测读者的信号,一旦所有的读者都已经发送信号告知它们都不在使用被RCU保护的数据结构,垃圾收集器就调用回调函数完成最后的数据释放或修改操作。 RCU与rwlock的不同之处是:它既允许多个读者同时访问被保护的数据,又允许多个读者和多个写者同时访问被保护的数据(注意:是否可以有多个写者并行访问取决于写者之间使用的同步机制),读者没有任何同步开销,而写者的同步开销则取决于使用的写者间同步机制。但RCU不能替代rwlock,因为如果写比较多时,对读者的性能提高不能弥补写者导致的损失。
读者在访问被RCU保护的共享数据期间不能被阻塞,这是RCU机制得以实现的一个基本前提,也就说当读者在引用被RCU保护的共享数据期间,读者所在的CPU不能发生上下文切换,spinlock和rwlock都需要这样的前提。写者在访问被RCU保护的共享数据时不需要和读者竞争任何锁,只有在有多于一个写者的情况下需要获得某种锁以与其他写者同步。写者修改数据前首先拷贝一个被修改元素的副本,然后在副本上进行修改,修改完毕后它向垃圾回收器注册一个回调函数以便在适当的时机执行真正的修改操作。等待适当时机的这一时期称为grace period,而CPU发生了上下文切换称为经历一个quiescent state,grace period就是所有CPU都经历一次quiescent state所需要的等待的时间。垃圾收集器就是在grace period之后调用写者注册的回调函数来完成真正的数据修改或数据释放操作的。
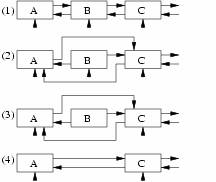
以下以链表元素删除为例详细说明这一过程。
写者要从链表中删除元素 B,它首先遍历该链表得到指向元素 B 的指针,然后修改元素 B 的前一个元素的 next 指针指向元素 B 的 next 指针指向的元素C,修改元素 B 的 next 指针指向的元素 C 的 prep 指针指向元素 B 的 prep指针指向的元素 A,在这期间可能有读者访问该链表,修改指针指向的操作是原子的,所以不需要同步,而元素 B 的指针并没有去修改,因为读者可能正在使用 B 元素来得到下一个或前一个元素。写者完成这些操作后注册一个回调函数以便在 grace period 之后删除元素 B,然后就认为已经完成删除操作。垃圾收集器在检测到所有的CPU不在引用该链表后,即所有的 CPU 已经经历了 quiescent state,grace period 已经过去后,就调用刚才写者注册的回调函数删除了元素 B。
使用 RCU 进行链表删除操作