pandas读取文件时,不去掉前面的0(前面的0出现数据丢失,保留原有数据格式)
第一种方法:使用converters
源文件:
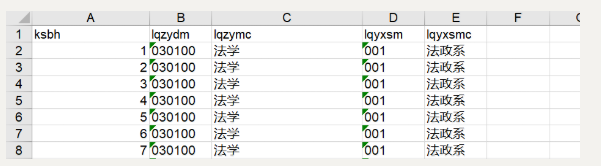
data_child2 = pd.DataFrame(pd.read_excel('F:\\dong\\2019程序测试.xls',converters = {u'lqzydm':str,u'lqyxsm':str}))#使用converters进行转换
department_all = data_child2['lqzydm']
department_al = data_child2['lqyxsm']
print(department_all)
print(department_al)
结果:
可以看出使用converters可以很好的读取还有0的数据,但是当还有0较多时,可能较麻烦,为此推荐使用第二种方法。
第二种方法:不使用DataFrame,指定dtype=object即可
源文件:
![[外链图片转存失败(img-OqQLT81z-1563597513950)(C:\Users\innduce\AppData\Roaming\Typora\typora-user-images\1563597381039.png)]](https://img-blog.csdnimg.cn/20190720123913810.?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80MzI0NTQ1Mw==,size_16,color_FFFFFF,t_70)
代码:
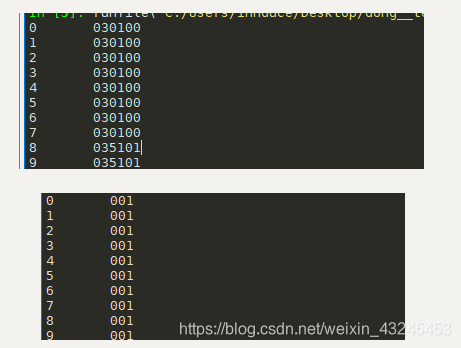
import pandas as pd
data1 = pd.read_excel(r"F:\AAlianxi\AAAAAAAAAAAA.xlsx",dtype=object)
data_dty = data1['lqzydm']
data2 = pd.DataFrame(pd.read_excel(r"F:\AAlianxi\AAAAAAAAAAAA.xlsx"))
data_nodty = data2['lqzydm']
print(data1)
print(data2)
print(data_row)
print(data_nodty)
结果:
ksbh lqzydm lqzymc lqyxsm lqyxsmc
0 1 030100 法学 001 法政系
1 2 030100 法学 001 法政系
2 3 030100 法学 001 法政系
3 4 030100 法学 001 法政系
4 5 030100 法学 001 法政系
5 6 030100 法学 001 法政系
6 7 030100 法学 001 法政系
7 8 030100 法学 001 法政系
8 9 035101 法律(非法学) 001 法政系
9 10 035101 法律(非法学) 001 法政系
10 11 035101 法律(非法学) 001 法政系
11 12 035101 法律(非法学) 001 法政系
12 13 035101 法律(非法学) 001 法政系
13 14 035101 法律(非法学) 001 法政系
14 15 035101 法律(非法学) 001 法政系
15 16 035101 法律(非法学) 001 法政系
ksbh lqzydm lqzymc lqyxsm lqyxsmc
0 1 30100 法学 1 法政系
1 2 30100 法学 1 法政系
2 3 30100 法学 1 法政系
3 4 30100 法学 1 法政系
4 5 30100 法学 1 法政系
5 6 30100 法学 1 法政系
6 7 30100 法学 1 法政系
7 8 30100 法学 1 法政系
8 9 35101 法律(非法学) 1 法政系
9 10 35101 法律(非法学) 1 法政系
10 11 35101 法律(非法学) 1 法政系
11 12 35101 法律(非法学) 1 法政系
12 13 35101 法律(非法学) 1 法政系
13 14 35101 法律(非法学) 1 法政系
14 15 35101 法律(非法学) 1 法政系
15 16 35101 法律(非法学) 1 法政系
0 030100
1 030100
2 030100
3 030100
4 030100
5 030100
6 030100
7 030100
8 035101
9 035101
10 035101
11 035101
12 035101
13 035101
14 035101
15 035101
Name: lqzydm, dtype: object
0 30100
1 30100
2 30100
3 30100
4 30100
5 30100
6 30100
7 30100
8 35101
9 35101
10 35101
11 35101
12 35101
13 35101
14 35101
15 35101
Name: lqzydm, dtype: int64
35101
10 35101
11 35101
12 35101
13 35101
14 35101
15 35101
Name: lqzydm, dtype: int64
