集合
在Java中,如果一个Java对象可以在内部持有若干其他Java对象,并对外提供访问接口,把这种Java对象称为集合。
Java标准库自带的java.util包提供了集合类:Collection,它是除Map外所有其他集合类的根接口。Java的java.util包主要提供了以下三种类型的集合:
- List:一种有序列表的集合,例如,按索引排列的Student的List;
- Set:一种保证没有重复元素的集合,例如,所有无重复名称的Student的Set;
- Map:一种通过键值(key-value)查找的映射表集合,例如,根据Student的name查找对应Student的Map。
Java集合的设计有几个特点:一是实现了接口和实现类相分离,例如,有序表的接口是List,具体的实现类有ArrayList,LinkedList等,二是支持泛型,我们可以限制在一个集合中只能放入同一种数据类型的元素,例如:
List<String> list = new ArrayList<>(); // 只能放入String类型
Java访问集合总是通过统一的方式——迭代器(Iterator)来实现,它最明显的好处在于无需知道集合内部元素是按什么方式存储的。
由于Java的集合设计非常久远,中间经历过大规模改进,我们要注意到有一小部分集合类是遗留类,不应该继续使用:
- Hashtable:一种线程安全的Map实现;
- Vector:一种线程安全的List实现;
- Stack:基于Vector实现的LIFO的栈。
还有一小部分接口是遗留接口,也不应该继续使用: - Enumeration:已被Iterator取代。
集合框架
集合框架被设计成要满足以下几个目标。
该框架必须是高性能的。基本集合(动态数组,链表,树,哈希表)的实现也必须是高效的。
该框架允许不同类型的集合,以类似的方式工作,具有高度的互操作性。
对一个集合的扩展和适应必须是简单的。
为此,整个集合框架就围绕一组标准接口而设计。可以直接使用这些接口的标准实现,诸如: LinkedList, HashSet, 和 TreeSet 等,也可以通过这些接口实现自己的集合。
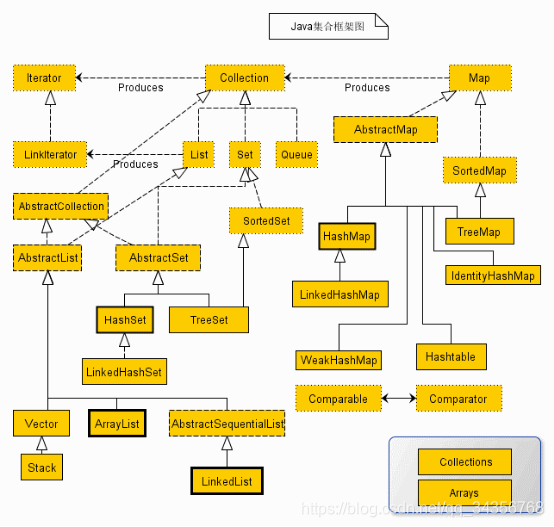
从上面的集合框架图可以看到,Java 集合框架主要包括两种类型的容器,一种是集合(Collection),存储一个元素集合,另一种是图(Map),存储键/值对映射。Collection 接口又有 3 种子类型,List、Set 和 Queue,再下面是一些抽象类,最后是具体实现类,常用的有 ArrayList、LinkedList、HashSet、LinkedHashSet、HashMap、LinkedHashMap 等等。
集合框架是一个用来代表和操纵集合的统一架构。所有的集合框架都包含如下内容:
- 接口:是代表集合的抽象数据类型。例如 Collection、List、Set、Map 等。之所以定义多个接口,是为了以不同的方式操作集合对象
- 实现(类):是集合接口的具体实现。从本质上讲,它们是可重复使用的数据结构,例如:ArrayList、LinkedList、HashSet、HashMap。
- 算法:是实现集合接口的对象里的方法执行的一些有用的计算,例如:搜索和排序。这些算法被称为多态,那是因为相同的方法可以在相似的接口上有着不同的实现。
除了集合,该框架也定义了几个 Map 接口和类。Map 里存储的是键/值对。尽管 Map 不是集合,但是它们完全整合在集合中。
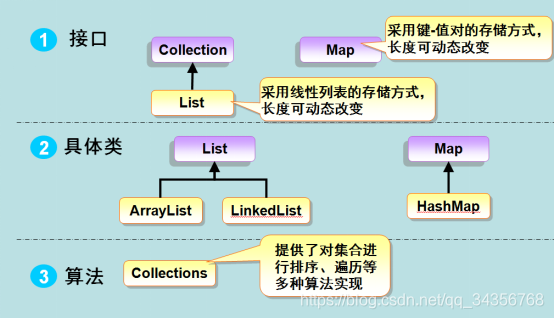
Java 集合框架提供了一套性能优良,使用方便的接口和类,java集合框架位于java.util包中, 所以当使用集合框架的时候需要进行导包。
集合接口


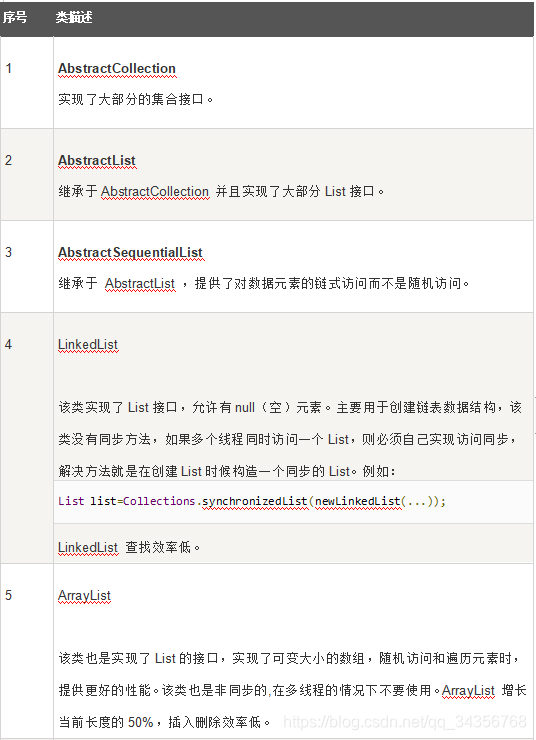
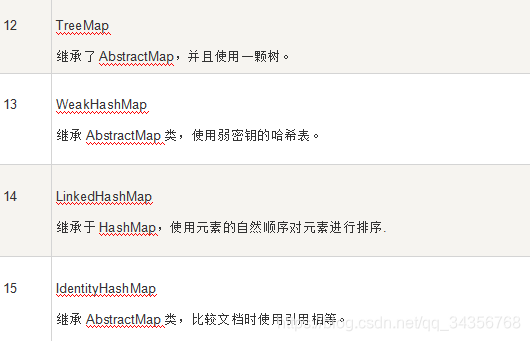
Java提供了一套实现了Collection接口的标准集合类。其中一些是具体类,这些类可以直接拿来使用,而另外一些是抽象类,提供了接口的部分实现。
标准集合类汇总于下表:

使用List
在集合类中,List是最基础的一种集合:它是一种有序链表。
List的行为和数组几乎完全相同:List内部按照放入元素的先后顺序存放,每个元素都可以通过索引确定自己的位置,List的索引和数组一样,从0开始。
数组和List类似,也是有序结构,如果我们使用数组,在添加和删除元素的时候,会非常不方便。例如,从一个已有的数组{‘A’, ‘B’, ‘C’, ‘D’, ‘E’}中删除索引为2的元素:
List接口,可以看到几个主要的接口方法:
- 在末尾添加一个元素:void add(E e)
- 在指定索引添加一个元素:void add(int index, E e)
- 删除指定索引的元素:int remove(int index)
- 删除某个元素:int remove(Object e)
- 获取指定索引的元素:E get(int index)
- 获取链表大小(包含元素的个数):int size()

通常情况下,优先使用ArrayList。
List接口允许我们添加重复的元素,即List内部的元素可以重复:
import java.util.ArrayList;
import java.util.List;
public class Main {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("apple"); // size=1
list.add("pear"); // size=2
list.add("apple"); // 允许重复添加元素,size=3
System.out.println(list.size());
}
}
List还允许添加null:
import java.util.ArrayList;
import java.util.List;
public class Main {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("apple"); // size=1
list.add(null); // size=2
list.add("pear"); // size=3
String second = list.get(1); // null
System.out.println(second);
}
}
创建list
除了使用ArrayList和LinkedList,还可以通过List接口提供的of()方法,根据给定元素快速创建List:
List<Integer> list = List.of(1, 2, 5);
但是List.of()方法不接受null值,如果传入null,会抛NullPointerException异常。
遍历List
要遍历一个List,可以用for循环根据索引配合get(int)方法遍历:
import java.util.List;
public class Main {
public static void main(String[] args) {
List<String> list = List.of("apple", "pear", "banana");
for (int i=0; i<list.size(); i++) {
String s = list.get(i);
System.out.println(s);
}
}
}
但这种方式并不推荐,一是代码复杂,二是因为get(int)方法只有ArrayList的实现是高效的,
换成LinkedList后,索引越大,访问速度越慢。
要始终坚持使用迭代器Iterator来访问List。Iterator本身也是一个对象,但它是由List的实例调用iterator()方法的时候创建的。Iterator对象知道如何遍历一个List,并且不同的List类型,返回的Iterator对象实现也是不同的,但总是具有最高的访问效率。
Iterator对象有两个方法:boolean hasNext()判断是否有下一个元素,E next()返回下一个元素。因此,使用Iterator遍历List代码如下:
import java.util.Iterator;
import java.util.List;
public class Main {
public static void main(String[] args) {
List<String> list = List.of("apple", "pear", "banana");
for (Iterator<String> it = list.iterator(); it.hasNext(); ) {
String s = it.next();
System.out.println(s);
}
}
}
Java的for each循环本身就可以帮我们使用Iterator遍历。把上面的代码再改写如下:
import java.util.List;
public class Main {
public static void main(String[] args) {
List<String> list = List.of("apple", "pear", "banana");
for (String s : list) {
System.out.println(s);
}
}
}
只要实现了Iterable接口的集合类都可以直接用for each循环来遍历,Java编译器本身并不知道如何遍历集合对象,但它会自动把for each循环变成Iterator的调用,原因就在于Iterable接口定义了一个Iterator iterator()方法,强迫集合类必须返回一个Iterator实例。
使用Map
Map这种键值(key-value)映射表的数据结构,作用就是能高效通过key快速查找value(元素)。
用Map来实现根据name查询某个Student的代码如下:
import java.util.HashMap;
import java.util.Map;
public class Main {
public static void main(String[] args) {
Student s = new Student("Xiao Ming", 99);
Map<String, Student> map = new HashMap<>();
map.put("Xiao Ming", s); // 将"Xiao Ming"和Student实例映射并关联
Student target = map.get("Xiao Ming"); // 通过key查找并返回映射的Student实例
System.out.println(target == s); // true,同一个实例
System.out.println(target.score); // 99
Student another = map.get("Bob"); // 通过另一个key查找
System.out.println(another); // 未找到返回null
}
}
class Student {
public String name;
public int score;
public Student(String name, int score) {
this.name = name;
this.score = score;
}
}
通过上述代码可知:Map<K, V>是一种键-值映射表,当我们调用put(K key, V value)方法时,就把key和value做了映射并放入Map。当我们调用V get(K key)时,就可以通过key获取到对应的value。如果key不存在,则返回null。和List类似,Map也是一个接口,最常用的实现类是HashMap。
如果只是想查询某个key是否存在,可以调用boolean containsKey(K key)方法。
遍历Map
对Map来说,要遍历key可以使用for each循环遍历Map实例的keySet()方法返回的Set集合,它包含不重复的key的集合:
import java.util.HashMap;
import java.util.Map;
public class Main {
public static void main(String[] args) {
Map<String, Integer> map = new HashMap<>();
map.put("apple", 123);
map.put("pear", 456);
map.put("banana", 789);
for (String key : map.keySet()) {
Integer value = map.get(key);
System.out.println(key + " = " + value);
}
}
}
同时遍历key和value可以使用for each循环遍历Map对象的entrySet()集合,它包含每一个key-value映射:
import java.util.HashMap;
import java.util.Map;
public class Main {
public static void main(String[] args) {
Map<String, Integer> map = new HashMap<>();
map.put("apple", 123);
map.put("pear", 456);
map.put("banana", 789);
for (Map.Entry<String, Integer> entry : map.entrySet()) {
String key = entry.getKey();
Integer value = entry.getValue();
System.out.println(key + " = " + value);
}
}
}
Map和List不同的是,Map存储的是key-value的映射关系,并且,它不保证顺序。在遍历的时候,遍历的顺序既不一定是put()时放入的key的顺序,也不一定是key的排序顺序。使用Map时,任何依赖顺序的逻辑都是不可靠的。以HashMap为例,假设我们放入"A",“B”,"C"这3个key,遍历的时候,每个key会保证被遍历一次且仅遍历一次,但顺序完全没有保证,甚至对于不同的JDK版本,相同的代码遍历的输出顺序都是不同的。
使用EnumMap
HashMap是一种通过对key计算hashCode(),通过空间换时间的方式,直接定位到value所在的内部数组的索引,因此,查找效率非常高。
如果作为key的对象是enum类型,那么,还可以使用Java集合库提供的一种EnumMap,它在内部以一个非常紧凑的数组存储value,并且根据enum类型的key直接定位到内部数组的索引,并不需要计算hashCode(),不但效率最高,而且没有额外的空间浪费。
以DayOfWeek这个枚举类型为例,为它做一个“翻译”功能:
import java.time.DayOfWeek;
import java.util.*;
public class Main {
public static void main(String[] args) {
Map<DayOfWeek, String> map = new EnumMap<>(DayOfWeek.class);
map.put(DayOfWeek.MONDAY, "星期一");
map.put(DayOfWeek.TUESDAY, "星期二");
map.put(DayOfWeek.WEDNESDAY, "星期三");
map.put(DayOfWeek.THURSDAY, "星期四");
map.put(DayOfWeek.FRIDAY, "星期五");
map.put(DayOfWeek.SATURDAY, "星期六");
map.put(DayOfWeek.SUNDAY, "星期日");
System.out.println(map);
System.out.println(map.get(DayOfWeek.MONDAY));
}
}
使用EnumMap的时候,总是用Map接口来引用它,因此,实际上把HashMap和EnumMap互换,在客户端看来没有任何区别。
使用TreeMap
HashMap是一种以空间换时间的映射表,它的实现原理决定了内部的Key是无序的,即遍历HashMap的Key时,其顺序是不可预测的(但每个Key都会遍历一次且仅遍历一次)。
还有一种Map,它在内部会对Key进行排序,这种Map就是SortedMap。注意到SortedMap是接口,它的实现类是TreeMap。
SortedMap保证遍历时以Key的顺序来进行排序。例如,放入的Key是"apple"、“pear”、“orange”,遍历的顺序一定是"apple"、“orange”、“pear”,因为String默认按字母排序:
SortedMap保证遍历时以Key的顺序来进行排序。例如,放入的Key是"apple"、“pear”、“orange”,遍历的顺序一定是"apple"、“orange”、“pear”,因为String默认按字母排序:
import java.util.*;
public class Main {
public static void main(String[] args) {
Map<String, Integer> map = new TreeMap<>();
map.put("orange", 1);
map.put("apple", 2);
map.put("pear", 3);
for (String key : map.keySet()) {
System.out.println(key);
}
// apple, orange, pear
}
}
使用Properties
用Properties读取配置文件非常简单。Java默认配置文件以.properties为扩展名,每行以key=value表示,以#课开头的是注释。以下是一个典型的配置文件:
# setting.properties
last_open_file=/data/hello.txt
auto_save_interval=60
可以从文件系统读取这个.properties文件:
String f = "setting.properties";
Properties props = new Properties();
props.load(new java.io.FileInputStream(f));
String filepath = props.getProperty("last_open_file");
String interval = props.getProperty("auto_save_interval", "120");
可见,用Properties读取配置文件,一共有三步:
1.创建Properties实例;
2.调用load()读取文件;
3.调用getProperty()获取配置。
调用getProperty()获取配置时,如果key不存在,将返回null。我们还可以提供一个默认值,这样,当key不存在的时候,就返回默认值。
也可以从classpath读取.properties文件,因为load(InputStream)方法接收一个InputStream实例,表示一个字节流,它不一定是文件流,也可以是从jar包中读取的资源流:
Properties props = new Properties();
props.load(getClass().getResourceAsStream("/common/setting.properties"));
试试从内存读取一个字节流:
import java.io.*;
import java.util.Properties;
public class Main {
public static void main(String[] args) throws IOException {
String settings = "# test" + "\n" + "course=Java" + "\n" + "last_open_date=2019-08-07T12:35:01";
ByteArrayInputStream input = new ByteArrayInputStream(settings.getBytes("UTF-8"));
Properties props = new Properties();
props.load(input);
System.out.println("course: " + props.getProperty("course"));
System.out.println("last_open_date: " + props.getProperty("last_open_date"));
System.out.println("last_open_file: " + props.getProperty("last_open_file"));
System.out.println("auto_save: " + props.getProperty("auto_save", "60"));
}
}
写入配置文件
如果通过setProperty()修改了Properties实例,可以把配置写入文件,以便下次启动时获得最新配置。写入配置文件使用store()方法:
Properties props = new Properties();
props.setProperty("url", "http://www.liaoxuefeng.com");
props.setProperty("language", "Java");
props.store(new FileOutputStream("C:\\conf\\setting.properties"), "这是写入的properties注释");
编码
早期版本的Java规定.properties文件编码是ASCII编码(ISO8859-1),如果涉及到中文就必须用name=\u4e2d\u6587来表示,非常别扭。从JDK9开始,Java的.properties文件可以使用UTF-8编码了。
不过,需要注意的是,由于load(InputStream)默认总是以ASCII编码读取字节流,所以会导致读到乱码。需要用另一个重载方法load(Reader)读取:
Properties props = new Properties();
props.load(new FileReader("settings.properties", StandardCharsets.UTF_8));
就可以正常读取中文。InputStream和Reader的区别是一个是字节流,一个是字符流。字符流在内存中已经以char类型表示了,不涉及编码问题。
使用Set
Set用于存储不重复的元素集合,它主要提供以下几个方法:
- 将元素添加进Set:boolean add(E e)
- 将元素从Set删除:boolean remove(Object e)
- 判断是否包含元素:boolean contains(Object e)
import java.util.*;
public class Main {
public static void main(String[] args) {
Set<String> set = new HashSet<>();
System.out.println(set.add("abc")); // true
System.out.println(set.add("xyz")); // true
System.out.println(set.add("xyz")); // false,添加失败,因为元素已存在
System.out.println(set.contains("xyz")); // true,元素存在
System.out.println(set.contains("XYZ")); // false,元素不存在
System.out.println(set.remove("hello")); // false,删除失败,因为元素不存在
System.out.println(set.size()); // 2,一共两个元素
}
}
Set实际上相当于只存储key、不存储value的Map。我们经常用Set用于去除重复元素。
因为放入Set的元素和Map的key类似,都要正确实现equals()和hashCode()方法,否则该元素无法正确地放入Set。
最常用的Set实现类是HashSet,实际上,HashSet仅仅是对HashMap的一个简单封装,它的核心代码如下:
public class HashSet<E> implements Set<E> {
// 持有一个HashMap:
private HashMap<E, Object> map = new HashMap<>();
// 放入HashMap的value:
private static final Object PRESENT = new Object();
public boolean add(E e) {
return map.put(e, PRESENT) == null;
}
public boolean contains(Object o) {
return map.containsKey(o);
}
public boolean remove(Object o) {
return map.remove(o) == PRESENT;
}
}
Set接口并不保证有序,而SortedSet接口则保证元素是有序的:
- HashSet是无序的,因为它实现了Set接口,并没有实现SortedSet接口;
- TreeSet是有序的,因为它实现了SortedSet接口。
import java.util.*;
public class Main {
public static void main(String[] args) {
Set<String> set = new HashSet<>();
set.add("apple");
set.add("banana");
set.add("pear");
set.add("orange");
for (String s : set) {
System.out.println(s);
}
}
}
import java.util.*;
public class Main {
public static void main(String[] args) {
Set<String> set = new TreeSet<>();
set.add("apple");
set.add("banana");
set.add("pear");
set.add("orange");
for (String s : set) {
System.out.println(s);
}
}
}
把HashSet换成TreeSet,在遍历TreeSet时,输出就是有序的,这个顺序是元素的排序顺序
使用TreeSet和使用TreeMap的要求一样,添加的元素必须正确实现Comparable接口,如果没有实现Comparable接口,那么创建TreeSet时必须传入一个Comparator对象。
使用Queue
队列(Queue)是一种经常使用的集合。Queue实际上是实现了一个先进先出(FIFO:First In First Out)的有序表。它和List的区别在于,List可以在任意位置添加和删除元素,而Queue只有两个操作:
- 把元素添加到队列末尾;
- 从队列头部取出元素。
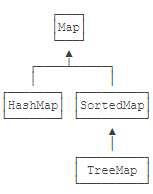
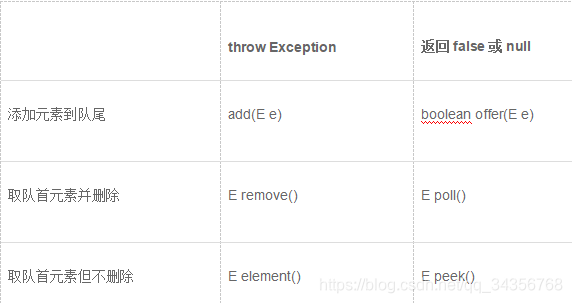
在Java的标准库中,队列接口Queue定义了以下几个方法: - int size():获取队列长度;
- boolean add(E)/boolean offer(E):添加元素到队尾;
- E remove()/E poll():获取队首元素并从队列中删除;
- E element()/E peek():获取队首元素但并不从队列中删除。
对于具体的实现类,有的Queue有最大队列长度限制,有的Queue没有。注意到添加、删除和获取队列元素总是有两个方法,这是因为在添加或获取元素失败时,这两个方法的行为是不同的。
LinkedList即实现了List接口,又实现了Queue接口,但是,在使用的时候,把它当作List,就获取List的引用,把它当作Queue,就获取Queue的引用:
// 这是一个List:
List<String> list = new LinkedList<>();
// 这是一个Queue:
Queue<String> queue = new LinkedList<>();
使用PriorityQueue
PriorityQueue和Queue的区别在于,它的出队顺序与元素的优先级有关,对PriorityQueue调用remove()或poll()方法,返回的总是优先级最高的元素。
使用Deque
Queue是队列,只能一头进,另一头出。
如果把条件放松一下,允许两头都进,两头都出,这种队列叫双端队列(Double Ended Queue),学名Deque。
Java集合提供了接口Deque来实现一个双端队列,它的功能是:
- 既可以添加到队尾,也可以添加到队首;
- 既可以从队首获取,又可以从队尾获取。
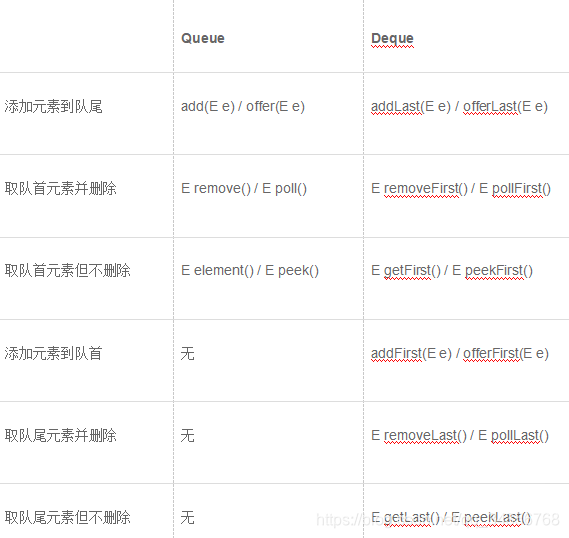
对于添加元素到队尾的操作,Queue提供了add()/offer()方法,而Deque提供了addLast()/offerLast()方法。添加元素到对首、取队尾元素的操作在Queue中不存在,在Deque中由addFirst()/removeLast()等方法提供。
import java.util.Deque;
import java.util.LinkedList;
public class Main {
public static void main(String[] args) {
Deque<String> deque = new LinkedList<>();
deque.offerLast("A"); // A
deque.offerLast("B"); // B -> A
deque.offerFirst("C"); // B -> A -> C
System.out.println(deque.pollFirst()); // C, 剩下B -> A
System.out.println(deque.pollLast()); // B
System.out.println(deque.pollFirst()); // A
System.out.println(deque.pollFirst()); // null
}
}
如果直接写deque.offer(),就需要思考,offer()实际上是offerLast(),我们明确地写上offerLast(),不需要思考就能一眼看出这是添加到队尾。
因此,使用Deque,推荐总是明确调用offerLast()/offerFirst()或者pollFirst()/pollLast()方法。
Deque是一个接口,它的实现类有ArrayDeque和LinkedList。
我们发现LinkedList真是一个全能选手,它即是List,又是Queue,还是Deque。但是在使用的时候,总是用特定的接口来引用它,这是因为持有接口说明代码的抽象层次更高,而且接口本身定义的方法代表了特定的用途。
// 不推荐的写法:
LinkedList<String> d1 = new LinkedList<>();
d1.offerLast("z");
// 推荐的写法:
Deque<String> d2 = new LinkedList<>();
d2.offerLast("z");
使用Stack
栈(Stack)是一种后进先出(LIFO:Last In First Out)的数据结构。
Stack只有入栈和出栈的操作:
- 把元素压栈:push(E);
- 把栈顶的元素“弹出”:pop(E);
- 取栈顶元素但不弹出:peek(E)。
在Java中,用Deque可以实现Stack的功能:
- 把元素压栈:push(E)/addFirst(E);
- 把栈顶的元素“弹出”:pop(E)/removeFirst();
- 取栈顶元素但不弹出:peek(E)/peekFirst()。
把Deque作为Stack使用时,注意只调用push()/pop()/peek()方法,不要调用addFirst()/removeFirst()/peekFirst()方法,这样代码更加清晰。
