一,介绍一下redis,说一下其优缺点
1,简介
redis是用于key-value数据,并将其在内存上进行存储;
2,优点
a,读写速度快:因为数据存储的位置在内存上,因此读写速度非常快,每秒钟可以处理10万次的读写操作;
b,丰富的功能:redis提供了数据库的持久化,主从复制,哨兵,集群,发布与订阅,事务等功能,提高了redis可以应用更加复杂的场景和redis的高可用性;
3,缺点
a,内存瓶颈:因为redis将数据是在内存上存储,因此存储内容的大小,受限于内存;
二,redis支持的数据库类型
1,String字符串
a,命令:set key value;get key;del key;
b,value的大小:一个值能最大存储512MB的内容;
c,特点:String类型是二进制安全的,也就说value可以是任何数据,如图片,序列化的对象;
2,hash
a,命令:hmset name key1 value1 key2 value2;hdel name key;hget name key;
b,hash介绍:是一个键值对的集合
3,list
a,lpush name value:在队列的头部添加元素
b,rpush name value:在队列的尾部条件元素
c,lrem name count value:在队列中删除count个和value相同的元素
d,llen name:返回key对应的列表长度
4,set
a,命令:sadd name value;scard name;srem name value1移出集合中一个或对个成员;
b,set介绍:无序集合,底层都过hashMap实现,因此增加,删除,查找的时间复杂度都是O(1)
5,sorted-set
a,命令:zadd name score value;
zscore name key;zincre name score key;zcard name;zrange name start end;
b,使用:会每一个值对关联一个score,通过score来进行排序
三,什么是持久化,redis有哪几种持久化机制,各自的优缺点
1,持久化的概念:就是将数据存储到永久性存储介质上;
2,redis的持久化机制:RDB和AOF
RDB:就是将当前数据库含有的键值对全部存储进rdb文件中;
AOF:就是进入redis服务区执行的写命令存储到aof文件中;
3,两种持久化机制比较
a,aof更新频率更高,因此优先使用aof进行数据库的还原;
b,rdb性能好,因为rdb持久化使用的是bgsave,使用了另一个进程处理,但是aof直接使用的是主进程进行处理,因此rdb的性能好一点;
四,分布式锁
1,实现:使用setnx命令获取锁,为了防止忘记释放锁,使用expire设置一个过期时间,时间到之后,锁自动被释放
2,问题:如果setnx获取锁之后,设置expire之前,客户端挂掉了,那么锁就会永远不能进行释放;
3,解决办法:set key value NX EX max-lock-time,可以通过这样命令保证加锁和设置过期时间的原子性,也就是要门同时设置成功,要么同时失败;
五,redis和memcached的区别
1,数据类型:redis除了支持string类型,还支持set,list,hash等类型;memcached只支持String类型
2,持久化:redis可以对数据库进行持久化操作;memcached不能对数据进行持久化操作;
3,线程模型:redis使用的是单进程单线程;memcached使用的是
六,内存淘汰机制
a,volatile-lru:从设置了过期时间的数据中,删除那些最近最少使用到的key;
b,volatile-ttr:从设置了过期时间的数据中,删除那些挑选简要过期的数据删除;
c,volatile-random:从设置了过期时间的数据中,随机进行删除
e,allkeys-lru:从所有的数据中,挑选最近最少使用的数据;
f,allkeys-random:从所有的数据中,随机进行挑选进行删除;
g,noenviction:禁止淘汰数据;
七,bgsave的面试题
bgsave的原理:通过创建一个子进程,使用子进程将所有的数据进行保存;
该种方式的优点就是:相对于save操作,在执行持久化的过程中,服务器是不会被阻塞的,是可以继续处理客户端发来的命令的;
问题:那么bgsave期间,数据库中的数据改动,那怎么办?
解答:因为bgsave操作知识保存一个时间节点上数据库中的数据,因此对于后续新加入或者删除的数据是不进行保存的,这也是rdb持久化的一个劣势,不能像aof持久化那样,更新频率比较高,实时性好;
八,redis集群的原理
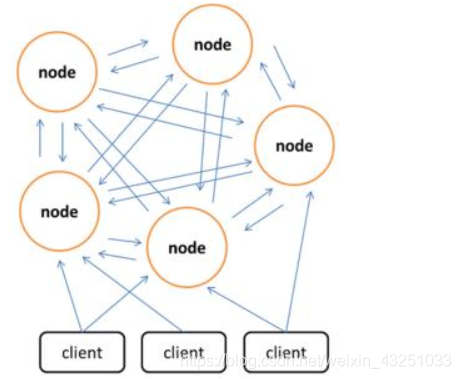
如下图所示,redis使用槽的概念,每一个节点都可以有一个或多个槽,用来存储数据,总共有16384个槽,必须每个槽都必须被分配到某个节点上,要不然集群启动不起来;
redis集群的特点:客户端在从redis集群中获取数据的时候,可以发给任意一个节点,如果该节点上存有该数据,那么返回,若果不存在,那么该节点就会告诉客户端那个节点上有,让客户端请求指定节点;
九,redis的同步机制
Redis的同步机制也就是主从复制;主从复制的操作过程可以分为两步:第一步是复制,第二是命令传播;
那么第一步先获取主服务器上的rdb文件,然后将其传送给从服务器,从服务器获取到rdb文件之后,进行恢复;在此主服务器还可以继续执行写命令,那么也会讲这些写命令使用一个缓存存储下来,等到从服务器加载完rdb文件之后,然后将缓存中的命令在发给从服务器,这样主服务器和从服务器的数据将达到一致;
那么第二步就是主服务器将后续执行的写命令,交给从服务器,使得主从服务器的数据在后续还是保持一致;
十,redis如何做异步队列
我们可以使用redis中支持的数据类型list来做异步队列,当产生消息,我们使用命令lpush将其加入到list中,然后消费者在消费的时候使用rpop进行消息的消费,如果队列中没有消息的话,那么也可以使用sleep(),等待一会再去消费;
如果不使用sleep()的话,那么也可以使用brpop命令,该命令的作用就是当队列中没有消息的时候,那么就会被阻塞住,直至队列中有消息;
问题:如果想要实现1对多的消息发送,应该怎么实现?
那么可以使用redis提供的发布与订阅功能,该功能主要的作用就是生产生会将消息发布到对应的频道上,那么只要订阅了该频道的消费者都会接收到该消息;因此通过这个功能可以实现发布与订阅的实现;
问题:如果消费者下线的情况下,消息就会丢失,这种情况怎样解决?
将消息发送给所有的订阅者,当消费者消费的话,那么就返回一个信息给服务器,服务器会统计返回的人数和发送的人数;如果两者一样的话,那么就将消息从队列中移除,如果不一样的话,找出没有返回消息的消费者,然后记录下来,然后当小费再次上线的时候,再次发送给消费者;
十二,假如redis里面有1亿个key,其中有10万个key是以某固定的已知的前缀开头的,怎样将这些key找出来?
使用keys命令,可以进行模式配置,将匹配到的key全部找出来;
其中?表示可以匹配任意一个,*表示可以匹配任意多个,[ ]表示必须匹配其中的1个或者多个元素;
问题:那么此时服务器还可以处理客户端的写命令吗?
答案:不能,因为redis是一个单进程单线程进行作业的,因此在执行keys命令的时候,不能处理其他的指令,需等待keys指令执行完毕之后,才能去处理其他指令;
十三,缓存击穿是什么?如何解决
1,缓存击穿的概念
这是因为一种恶意请求导致,用户恶意的去请求缓存中没有的数据,那么就会导致大量的请求落在数据库上,那么可能就会引发数据库异常;
2,解决办法
a,使用互斥锁排队
当用户请求的数据在缓存中不存在,那么执行一个加锁操作,然后去从数据库中获取数据,当获取数据之后,在释放锁;若其他线程获取所失败,那么可以等待一段时间之后重新尝试获取锁,直至获取锁;注意:在分布式环境下需要使用分布式锁,单机环境下使用jvm自带的锁就可以了;
b,布隆过滤器
布隆过滤器类似一个set,可以用于快速判断某个元素是否存在于集合中,如果在容器中存在,那么执行获取操作,如果不存在,那么直接返回空值;
c,使用队列就行泄洪
使用线程池来处理访问数据库的操作,其实也可以解决上述的问题;
十四,缓存雪崩是什么?如何解决?
1,缓存雪崩的概念
就是同一个使其大量的key过期了,那么此时来了大量的请求,那么就会导致请求都落在了数据库上,这就是缓存雪崩;
2,解决办法
a,在设置key过期时间的时候,在家一个随时时间长度,这样就可以防止大量的key在同一时间失效;
b,还可以使用互斥锁排队的方式,如上述缓存穿透方案中的解决办法;
十五,缓存和数据库间数据不一致性问题
1,如果必须保持强一致性,那么其实不适用缓存,直接操作数据库就可以了;
2,有时我们急需要保持一致性,还需要高性能,那么我们可以使用消息队列来实现缓存和数据的一致性问题;
十六,redis实现分布式锁
1.加锁
最简单的方法是使用setnx命令。key是锁的唯一标识,按业务来决定命名。比如想要给一种商品的秒杀活动加锁,可以给key命名为 “lock_sale_商品ID” 。而value设置成什么呢?锁的value值为一个随机生成的UUID。我们可以姑且设置成1。加锁的伪代码如下:
setnx(key,1)
当一个线程执行setnx返回1,说明key原本不存在,该线程成功得到了锁;当一个线程执行setnx返回0,说明key已经存在,该线程抢锁失败。
2.解锁
有加锁就得有解锁。当得到锁的线程执行完任务,需要释放锁,以便其他线程可以进入。释放锁的最简单方式是执行del指令,伪代码如下:
del(key)
释放锁之后,其他线程就可以继续执行setnx命令来获得锁。
3.锁超时
锁超时是什么意思呢?如果一个得到锁的线程在执行任务的过程中挂掉,来不及显式地释放锁,这块资源将会永远被锁住,别的线程再也别想进来。
所以,setnx的key必须设置一个超时时间,单位为second,以保证即使没有被显式释放,这把锁也要在一定时间后自动释放,避免死锁。setnx不支持超时参数,所以需要额外的指令,伪代码如下:
expire(key, 30)
