Hello,我是 Alex 007,为啥是007呢?因为叫 Alex 的人太多了,再加上每天007的生活,Alex 007就诞生了。
今天呢,主要是跟大家分享一下花了两天整理的爬虫面试题,欢迎三连哦。
一. Requests模块
1. 简述爬虫的概念
爬虫,即网络机器人,如果把互联网理解为一张巨大的蜘蛛网,那么爬虫就是在这张网上捕猎的蜘蛛,它会根据你给定的目标将资源保存下来,也就是持久化存储。
这个过程其实就类似于我们浏览器上网,只不过将这个繁琐的过程通过编写程序模拟的形式,让爬虫去互联网上抓取数据。
2. 爬虫有几种分类,使用场景是什么?
通用爬虫:通用爬虫是搜索引擎爬虫的重要组成部分,主要是将互联网上的网页下载到本地,再对这些网页做相关处理(提取关键字、去掉广告),最后提供一个用户检索接口。
聚焦爬虫:聚焦爬虫是根据指定的需求在通用爬虫抓取到的网络上提取目标数据。
增量式爬虫:增量式爬虫是用来检测网站数据更新的情况,且可以将网站更新的数据进行爬取。
3. 简述robots协议的概念与作用
robots协议是一种存放于网站根目录下的ASCII编码的文本文件,它通常告诉网络蜘蛛,此网站中的哪些内容是不应被搜索引擎的漫游器获取的,哪些是可以被漫游器获取的。
因为一些系统中的URL是大小写敏感的,所以robots.txt的文件名应统一为小写。
如果想单独定义搜索引擎的漫游器访问子目录时的行为,那么可以将自定的设置合并到根目录下的robots.txt,或者使用robots元数据(Metadata,又称元数据)。
当一个搜索蜘蛛访问一个站点时,它会首先检查该站点根目录下是否存在robots.txt,如果存在,搜索机器人就会按照该文件中的内容来确定访问的范围;如果该文件不存在,所有的搜索蜘蛛将能够访问网站上所有没有被口令保护的页面。
如果将网站视为酒店里的一个房间,robots.txt就是主人在房间门口悬挂的“请勿打扰”或“欢迎打扫”的提示牌。这个文件告诉来访的搜索引擎哪些房间可以进入和参观,哪些房间因为存放贵重物品,或可能涉及住户及访客的隐私而不对搜索引擎开放。
但robots.txt是一个协议,而不是一个命令,也不是防火墙,如同守门人无法阻止窃贼等恶意闯入者。
4. 什么是反爬机制和反反爬机制
反爬机制:门户网站通过相应的策略和技术手段,防止爬虫程序进行网站数据的爬取。
1. U-A 校验
2. 限制访问频率
3. 验证码
4. 登录验证
反反爬机制:爬虫程序通过相应的策略和技术手段,破解门户网站的反爬虫手段,从而爬取到相应的数据。
5. 简述使用requests模块进行数据爬取的大致流程
(1)指定url
(2)基于requests模块发起请求
(3)获取响应对象中的数据
(4)数据解析
(5)持久化存储
6. 简述使用requests模块爬取ajax加载数据爬取的大致流程
(1)指定动态加载数据的url
(2)基于requests模块发起请求
(3)获取响应对象中的数据
(4)数据解析
(5)持久化存储
7. 简述User-Agent参数的作用
User Agent中文名为用户代理,是Http协议中的一部分,属于请求头的组成部分,User Agent也简称UA。
User Agent向访问网站提供发起请求的浏览器类型及版本、操作系统及版本、浏览器内核、等信息的标识。
通过这个标识,用户所访问的网站可以显示不同的排版从而为用户提供更好的体验或者进行信息统计。
在使用爬虫获取数据的时候,主要是想要获取网站的数据,而有些网站则是不想让我们的爬虫进行获取,所以我们会对爬虫进行各种各样的伪装,UA伪装就是其中一种收单,让对方识别我们为爬虫的概率更小,这样爬取到想要的数据的概率就越大。
8. 在requests模块中接触过哪些反爬机制
(1)验证码
爬虫采集器优化方案:使用打码平台识别验证码。
(2)限制IP访问频率
分析:没有哪个正常人可以在一秒钟内能访问相同网站数十次次,除非是程序访问,也就是搜索引擎爬虫和爬虫采集器。
弊端:一刀切,这同样会阻止搜索引擎对网站的收录
适用网站:不太依靠搜索引擎的网站
爬虫采集器优化方案:减少单位时间的访问次数,减低采集效率
(3)UA校验
分析:服务器端通过检验请求的User-Agent来判断是浏览器还是爬虫程序。
爬虫采集器优化方案:制作UA伪装
(4)登录校验
分析:搜索引擎爬虫不会对每个需要登录的网站设计登录程序,但爬虫采集器可以针对某个网站设计模拟用户登录提交表单行为。
适用网站:极度讨厌搜索引擎,且想阻止大部分采集器的网站
爬虫采集器优化方案:制作拟用户登录提交表单行为的模块
(5)动态加载页面
分析:有一部分网站,需要爬取的数据是通过Ajax请求得到的,根据不同的情况动态加载数据。
爬虫采集器优化方案:基于Selenium+PhantomJS模拟浏览器请求。
(6)数据加密
对部分数据进行加密的,可以使用selenium进行截图,使用python自带的pytesseract库进行识别,但是比较慢,最直接的方法是找到加密的方法进行逆向推理。
9. 介绍下requests模块中get和post方法常用参数的作用
GET:
# 封装get请求参数
prams = {
'query':word,
'ie':'utf-8'
}
# 定制请求头信息,相关的头信息必须封装在字典结构中
headers = {
# 定制请求头中的User-Agent参数,当然也可以定制请求头中其他的参数
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36',
}
response = requests.get(url=url,headers=headers,params=param)
POST:
# 定制post请求携带的参数(从抓包工具中获取)
data = {
'cname':'',
'pid':'',
'keyword':'北京',
'pageIndex': '1',
'pageSize': '10'
}
# 定制请求头信息,相关的头信息必须封装在字典结构中
headers = {
# 定制请求头中的User-Agent参数,当然也可以定制请求头中其他的参数
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36',
}
# 发起post请求,获取响应对象
response = requests.get(url=url,headers=headers,data=data)
10. 简述session的创建流程及其该对象的作用
# 创建一个session对象,该对象会自动将请求中的cookie进行存储和携带
session = requests.session()
# cookie由服务器创建并交给客户端浏览器保存,会话跟踪技术,再次访问时,服务器就可以区分客户端浏览器
# 使用session发送请求,目的是为了将session保存该次请求中的cookie
session.post(url=post_url,data=formdata,headers=headers)
get_url = 'http://www.renren.com/960481378/profile'
# 再次使用session进行请求的发送,该次请求中已经携带了cookie
response = session.get(url=get_url,headers=headers)
11. 简述如何使用requests模块进行模拟登录,并抓取登录成功后的某个二级页面数据。
结合session = requests.post.session(),先登陆成功
在浏览器获取post请求的参数response = requests.post(url=url,data=data,headers=headers)
然后获取个人页面url,params = {},获取get请求参数response = requests.get(url=url,params=params,headers=headers)。
最后获取响应对象的页面数据page_text = response.text。
12. 简述如何使用requests模块设置代理IP
1、在使用requests模块–get post —proxy
#不同的代理IP
proxy_list = [
{"http": "112.115.57.20:3128"},
{'http': '121.41.171.223:3128'}
]
# 随机获取UA和代理IP
header = random.choice(header_list)
proxy = random.choice(proxy_list)
# 设置代理
response = requests.get(url=url,headers=header,proxies=proxy)
2、在scrapy框架下使用下载中间件
1.在下载中间件中拦截请求
2.将拦截到的请求的IP修改成某一代理IP
3.在配置文件(settings.py)中开启下载中间件
二. 数据解析
1. 简述使用在使用正则进行解析时用到的re.S和re.M的作用和区别
re.I: 忽略大小写
re.M :多行匹配
re.S :单行匹配
2. 简述如何使用xpath进行数据解析
(1)一般情况下
- 导入:
from lxml import etree - 实例化一个
etree对象并将浏览器网页数据注册到对象中,本地数据使用etree.parse,网络数据使用etree.HTML - 编写
xpath表达式
(2)Scrapy框架中response对象已经封装好了xpath方法
3. 简述如何使用bs4进行数据解析
bs4里面有一个类BeautifulSoup,通过这个类将网页html格式字符串实例化一个对象,然后通过对象的方法来进行查找指定元素。
将本地html文件转化为对象:
soup = BeautifulSoup(open('soup.html', encoding='utf8'), 'lxml')
**根据标签名查找:**只能查找得到第一个符合要求的节点,是一个bs4自己封装类的对象
soup.a
获取属性
soup.a.attrs 获取得到所有属性和值,是一个字典
soup.a.attrs['href'] 获取指定的属性值
soup.a['href'] 简写形式
获取文本:
soup.a.string
soup.a.text
soup.a.get_text()
如果标签里面还有标签,那么string获取就是空,而后两个获取的是纯文本内容。
find_all方法
返回的是一个列表,列表里面都是节点对象。
soup.find_all('a') 找到所有a
soup.find_all('a', limit=2) 提取符合要求的前两个a
soup.find_all(['a', 'li']) 查找得到所有的a和li
soup.find_all('a', class_='xxx')查找得到所有class是xxx的a
soup.find_all('li', class_=re.compile(r'^xiao'))查找所有的class以xiao开头的li标签
select方法
id选择器 #dudu
类选择器 .xixi
标签选择器 div a h1
4. xpath方法返回值类型是什么
xpath函数返回的总是一个列表----列表里面是选择器对象。
可以用索引、和切片进行处理。
5. 在xpath中如何/text()和//text()的区别是什么
(1)/text()表示获取某个标签下的文本内容
(2)//text()表示获取某个标签下的文本内容和所有子标签下的文本内容
6. id为su的div标签有一个子标签ul,ul下有十个li标签,每一个li标签下都有一个a标签,如何编写xpath表达式可以解析到a标签的href属性值
li = response.xpath('//div[@id="su"]/ul/li')
for i in li:
i.xpath('./a/@href').extract_first()
7. class为wd的div标签有一个子标签ul,ul下有十个li标签,每一个li标签下都有一个a标签,如何编写xpath表达式可以解析到a标签中的文本内容
lis=response.xpath('//div[@class="wd"]/ul/li')
for li in lis:
a=li.xpath('./a/text()').extract_first()
8. 简述extract()和extract_first()的区别
首先,只有在在Scrapy中才有extract_first()和extract(),然后extract()方法返回的是一个数组List,里面包含了多个string,就算只有一个string返回的也是列表的形式,而extract_first()方法返回的是List数组里面的第一个string字符串。
9. 简述BeautifulSoup模块中find和findall方法的区别
find:找到第一个符合要求的标签
find_all:找到所有符合要求的标签
10. 简述BeautifulSoup模块中select方法的使用
bs4里面有一个类BeautifulSoup,通过这个类将网页html格式字符串实例化一个对象,然后通过对象的方法来进行查找指定元素。
select方法
id选择器 #dudu
类选择器 .xixi
标签选择器 div a h1
11. 简述xpath插件的作用
就可以直接将xpath表达式作用到浏览器的网页当中 ,进行验证。
三. Scrapy 框架
1. 简述scrapy框架的安装流程
pip install -i http://mirrors.aliyun.com/pypi/simple --trusted-host mirrors.aliyun.com twisted
pip install -i http://mirrors.aliyun.com/pypi/simple --trusted-host mirrors.aliyun.com pywin32
pip install -i http://mirrors.aliyun.com/pypi/simple --trusted-host mirrors.aliyun.com scrapy
-
twisted
Twisted 是用 Python 实现的基于事件驱动的网络引擎框架,提供了允许阻塞行为但不会阻塞代码执行的方法,比较适合异步的程序。 -
pywin32
pywin32 主要的作用是方便 Python 开发者快速调用 Windows API的一个模块库。
1.1. 为什么要使用scrapy框架?
首先,Scrapy是基于twisted的异步IO框架,并且是纯Python实现的爬虫框架,在性能方面有很大的优势。
其次,在Scrapy中可以加入requests和BeautifulSoup,内置的cssselector和xpath使用非常方便,还提供了很多其它的内置功能。
最后,Scrapy是默认深度优先的,并且可以实现高并发的数据爬取,更加容易构建大规模的抓取项目。
2. scrapy中持久化操作有几种形式,分别如何实现?
(1)基于终端指令的持久化存储
首先要保证parse方法返回一个可迭代类型的对象,然后可以使用如下指令完成数据存储的功能:
scrapy crawl baiDu -o baidu.json
(2)基于管道的持久化存储
- 将爬虫文件爬取到的数据封装到
items对象中 - 使用
yield将items对象提交给pipelines管道持久化存储 - 管道文件中的
process_item方法接收并处理爬虫文件提交过来的item对象 - 配置文件
settings.py中开启管道
3. 简述start_requests方法的作用
源码:
def start_requests(self):
for url in self.start_urls:
yield self.make_requests_from_url(url)
首先由start_requests对start_urls中的每一个url发起请求(make_requests_from_url),这个请求会被parse接收。
4. 在scrapy中如何进行post请求发送
在scrapy中可以通过scrapy.FormRequest方法发送post请求,参数为formdata:
yield scrapy.FormRequest(url=url,formdata=data,callback=self.parse)
5. 在scrapy中如何手动进行一个get请求的发送
在scrapy中可以通过scrapy.Request方法发送get请求:
yield scrapy.Request(url=url,callback=self.parse)
6. 简述管道文件的作用
在Scrapy中,从每一个URL中爬取的数据封装成一个Response对象,作为参数返回给parse方法或自定义的回调函数,parse方法解析Response为item,然后传递给管道,在pipelines.py文件中提取item中的内容,进行数据的持久化处理。
7. 简述Request方法中callback参数的作用
为当次request方法指定回调函数,参数就是本次请求的返回结果。
8. 简述Request方法中meta参数的作用
在Scrapy中Request方法的meta参数要传入一个字典,主要是传递数据用,meta是随着Request产生时传递的吗,比如meta = {‘key1’:value1},如果想要在下一个函数中取出value1,只需要使用meta['key1']即可。
9. 简述下载中间件的作用
下载中间件是位于Scrapy引擎和下载器之间的一层组件,用于处理请求,可以对请求设置随机的User-Agent,设置随机的代理IP,目的就在于防止应对网站的反爬策略。
下载器完成下载任务之后,在将Response传递给引擎之前,下载中间件可以对Response进行一系列处理,比如进行解压等操作。
下载中间件需要注册才能使用,在settings.py文件中设置DOWNLOADER_MIDDLEWARES,设置为一个字典,键为中间件类的路径,值为其中间件的顺序。
9.1. 简述蜘蛛中间件的作用
蜘蛛中间件是介于Scrapy的Engine和Spider之间的钩子框架,主要工作是处理蜘蛛的响应输入和请求输出。
9.2. 简述调度中间件的作用
Scheduler Middlewares是介于Scrapy的Engine和Scheduler之间我的中间件,主要工作是处理从Scrapy的Engine发送到Scheduler的请求和响应。
10. 简述如何设置scrapy项目的代理IP
(1)找一些代理IP添加到settings.py中
(2)在middlewares.py中添加代理中间件:
class ProxyMiddleware(object):
def __init__(self, ip):
self.ip = ip
@classmethod
def from_crawler(cls, crawler):
return cls(ip=crawler.settings.get('PROXIES'))
def process_request(self, request, spider):
ip = random.choice(self.ip)
request.meta['proxy'] = ip
(3)在settings.py中注册代理IP中间件
11. 简述CrawlSpider中链接提取器的作用
link = LinkExtractor(allow=r'/all/hot/recent/\d+')
Step 1. 实例化一个链接提取器对象
Step 2. 从起始url响应页面中按照正则表达式提取指定url
Step 3. 将链接提取器注册给规则解析器
12. 简述CrawlSpider中规则解析器的作用
Step 1. 实例化一个规则提取器对象
Step 2. 规则解析器接收链接提取器发送的链接并对这些链接发起请求
Step 3. 根据指定的规则对返回页面内容指定解析规则callback,通过follow确定是否递归获取链接
Rule(link, callback='parse_item', follow=False),
13. 简述scrapy核心组件的工作原理
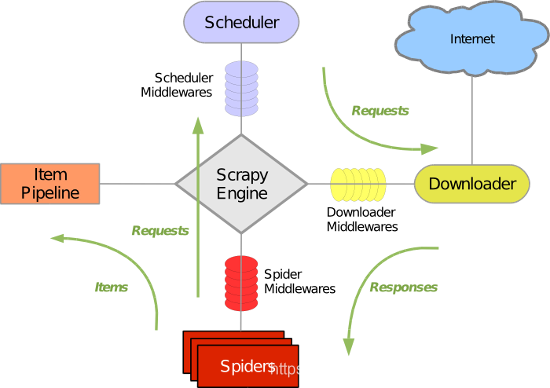
-
Spiders爬虫
爬虫就是干活的,编写业务逻辑代码,从特定的网页中提取自己需要的信息,每个Spider负责处理一个(些)特定网站。 -
Scrapy Engine引擎
引擎用于处理整个Scrapy系统的数据流,触发事务等,是整个框架的核心。 -
Scheduler调度器
调度器用来接收引擎发过来的请求并将其压入队列中,需要时弹出,可以简单理解为url调度器,可以去除重复的url。 -
Downloader下载器
下载器顾名思义就是用于下载网页并将内容返回给Spiders,Scrapy的下载器是建立在Twisted高效异步模型上的。 -
Item、Pipeline管道
管道负责处理Spiders从网页中抽取的实体并做持久化处理,同时可以验证实体的有效性、清楚无用信息。
Scrapy运行流程
-
引擎打开一个域名,蜘蛛处理这个域名,并让蜘蛛获取第一个爬取的
URL。 -
引擎从蜘蛛那获取第一个需要爬取的
URL,然后作为请求在调度中进行调度。 -
引擎从调度那获取接下来进行爬取的页面。
-
调度将下一个爬取的
URL返回给引擎,引擎将他们通过下载中间件发送到下载器。 -
当网页被下载器下载完成以后,响应内容通过下载中间件被发送到引擎。
-
引擎收到下载器的响应并将它通过蜘蛛中间件发送到蜘蛛进行处理。
-
蜘蛛处理响应并返回爬取到的项目,然后给引擎发送新的请求。
-
引擎将抓取到的内容发送到项目管道做持久化处理,并向调度发送新的请求。
-
系统重复第二步后面的操作,直到调度中没有请求,然后断开引擎与域之间的联系。
14. 原生scrapy框架为何不能实现分布式
其一:因为多台机器上部署的scrapy会各自拥有各自的调度器,这样就使得多台机器无法分配start_urls列表中的url。(多台机器无法共享同一个调度器)
其二:多台机器爬取到的数据无法通过同一个管道对数据进行统一的数据持久出存储。(多台机器无法共享同一个管道)
15.0. 简述一下什么是分布式
当项目需要计算的数据量非常大,任务又非常多,一台机器搞不定或者效率非常低的时候,就需要多台机器共同协作,最后将所有机器完成的任务汇总在一起,从而完成大量的任务。
比如分布式爬虫,就是将一个项目拷贝到多台电脑上,将多台主机组合起来共同完成一个爬取任务,这样可以大大提高爬取的效率。
15. 简述基于scrapy-redis分布式的流程
16. 简述一下scrapy中selenium的使用
当Engine将url对应的请求提交给Downloader之后,Downloader对目标网页进行下载,然后将下载到的页面数据封装成response之后返回给Engine,而Engine再将response转交给Spider。
Spider接收到的response对象中存储的页面数据是没有动态加载的,如果想获取动态加载的数据,则需要在Downloader Middlewares中对Downloader返回给Engine的response响应对象进行拦截,将其内部存储的页面数据替换成携带动态加载数据的内容。
替换的操作就需要用到selenium来模拟浏览器了,在Scrapy中使用selenium的流程如下:
(1)重写爬虫的构造方法,在该方法中使用selenium实例化一个浏览器对象;
(2)重写爬虫文件的close方法,在其内部关闭浏览器对象,在爬虫结束时被调用;
(3)重写Downloader Middlewares的process_response方法,让改方法对相应对象进行拦截和替换response中存储的页面数据;
(4)在配置文件中开启下载中间件。

