Paxos算法流程
Paxos算法解决的问题正是分布式一致性问题,即一个分布式系统中的各个进程如何就某个值(决议)达成一致。
Paxos算法运行在允许宕机故障的异步系统中,不要求可靠的消息传递,可容忍消息丢失、延迟、乱序以及重复。它利用大多数 (Majority) 机制保证了2F+1的容错能力,即2F+1个节点的系统最多允许F个节点同时出现故障。
一个或多个提议进程 (Proposer) 可以发起提案 (Proposal),Paxos算法使所有提案中的某一个提案,在所有进程中达成一致。系统中的多数派同时认可该提案,即达成了一致。最多只针对一个确定的提案达成一致。
Paxos将系统中的角色分为提议者 (Proposer),决策者 (Acceptor),和最终决策学习者 (Learner):
- Proposer: 提出提案 (Proposal)。Proposal信息包括提案编号 (Proposal ID) 和提议的值 (Value)。
- Acceptor:参与决策,回应Proposers的提案。收到Proposal后可以接受提案,若Proposal获得多数Acceptors的接受,则称该Proposal被批准。
- Learner:不参与决策,从Proposers/Acceptors学习最新达成一致的提案(Value)。
在多副本状态机中,每个副本同时具有Proposer、Acceptor、Learner三种角色。
 Paxos算法中的角色
Paxos算法中的角色
Paxos算法通过一个决议分为两个阶段(Learn阶段之前决议已经形成):
- 第一阶段:Prepare阶段。Proposer向Acceptors发出Prepare请求,Acceptors针对收到的Prepare请求进行Promise承诺。
- 第二阶段:Accept阶段。Proposer收到多数Acceptors承诺的Promise后,向Acceptors发出Propose请求,Acceptors针对收到的Propose请求进行Accept处理。
- 第三阶段:Learn阶段。Proposer在收到多数Acceptors的Accept之后,标志着本次Accept成功,决议形成,将形成的决议发送给所有Learners。
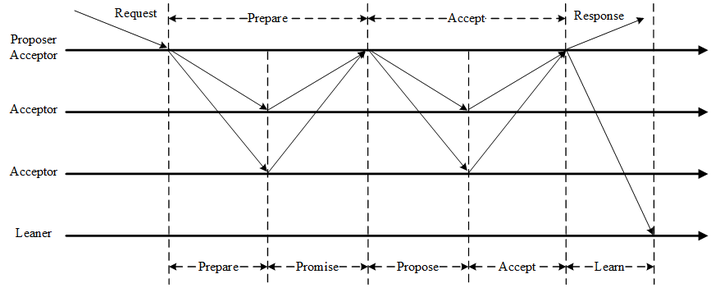 Paxos算法流程
Paxos算法流程
Paxos算法流程中的每条消息描述如下:
- Prepare: Proposer生成全局唯一且递增的Proposal ID (可使用时间戳加Server ID),向所有Acceptors发送Prepare请求,这里无需携带提案内容,只携带Proposal ID即可。
- Promise: Acceptors收到Prepare请求后,做出“两个承诺,一个应答”。
两个承诺:
1. 不再接受Proposal ID小于等于(注意:这里是<= )当前请求的Prepare请求。
2. 不再接受Proposal ID小于(注意:这里是< )当前请求的Propose请求。
一个应答:
不违背以前作出的承诺下,回复已经Accept过的提案中Proposal ID最大的那个提案的Value和Proposal ID,没有则返回空值。
- Propose: Proposer 收到多数Acceptors的Promise应答后,从应答中选择Proposal ID最大的提案的Value,作为本次要发起的提案。如果所有应答的提案Value均为空值,则可以自己随意决定提案Value。然后携带当前Proposal ID,向所有Acceptors发送Propose请求。
- Accept: Acceptor收到Propose请求后,在不违背自己之前作出的承诺下,接受并持久化当前Proposal ID和提案Value。
- Learn: Proposer收到多数Acceptors的Accept后,决议形成,将形成的决议发送给所有Learners。
Paxos算法伪代码描述如下:
 Paxos算法伪代码
Paxos算法伪代码
- 获取一个Proposal ID n,为了保证Proposal ID唯一,可采用时间戳+Server ID生成;
- Proposer向所有Acceptors广播Prepare(n)请求;
- Acceptor比较n和minProposal,如果n>minProposal,minProposal=n,并且将 acceptedProposal 和 acceptedValue 返回;
- Proposer接收到过半数回复后,如果发现有acceptedValue返回,将所有回复中acceptedProposal最大的acceptedValue作为本次提案的value,否则可以任意决定本次提案的value;
- 到这里可以进入第二阶段,广播Accept (n,value) 到所有节点;
- Acceptor比较n和minProposal,如果n>=minProposal,则acceptedProposal=minProposal=n,acceptedValue=value,本地持久化后,返回;否则,返回minProposal。
- 提议者接收到过半数请求后,如果发现有返回值result >n,表示有更新的提议,跳转到1;否则value达成一致。
下面举几个例子,实例1如下图:
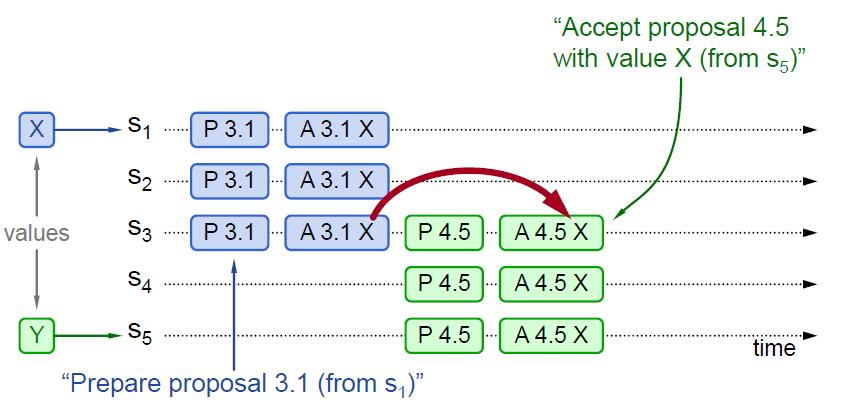 Paxos算法实例1
Paxos算法实例1
图中P代表Prepare阶段,A代表Accept阶段。3.1代表Proposal ID为3.1,其中3为时间戳,1为Server ID。X和Y代表提议Value。
实例1中P 3.1达成多数派,其Value(X)被Accept,然后P 4.5学习到Value(X),并Accept。
 Paxos算法实例2
Paxos算法实例2
实例2中P 3.1没有被多数派Accept(只有S3 Accept),但是被P 4.5学习到,P 4.5将自己的Value由Y替换为X,Accept(X)。
 Paxos算法实例3
Paxos算法实例3
实例3中P 3.1没有被多数派Accept(只有S1 Accept),同时也没有被P 4.5学习到。由于P 4.5 Propose的所有应答,均未返回Value,则P 4.5可以Accept自己的Value (Y)。后续P 3.1的Accept (X) 会失败,已经Accept的S1,会被覆盖。
Paxos算法可能形成活锁而永远不会结束,如下图实例所示:
 Paxos算法形成活锁
Paxos算法形成活锁
回顾两个承诺之一,Acceptor不再应答Proposal ID小于等于当前请求的Prepare请求。意味着需要应答Proposal ID大于当前请求的Prepare请求。
两个Proposers交替Prepare成功,而Accept失败,形成活锁(Livelock)。
Multi-Paxos算法
原始的Paxos算法(Basic Paxos)只能对一个值形成决议,决议的形成至少需要两次网络来回,在高并发情况下可能需要更多的网络来回,极端情况下甚至可能形成活锁。如果想连续确定多个值,Basic Paxos搞不定了。因此Basic Paxos几乎只是用来做理论研究,并不直接应用在实际工程中。
实际应用中几乎都需要连续确定多个值,而且希望能有更高的效率。Multi-Paxos正是为解决此问题而提出。Multi-Paxos基于Basic Paxos做了两点改进:
- 针对每一个要确定的值,运行一次Paxos算法实例(Instance),形成决议。每一个Paxos实例使用唯一的Instance ID标识。
- 在所有Proposers中选举一个Leader,由Leader唯一地提交Proposal给Acceptors进行表决。这样没有Proposer竞争,解决了活锁问题。在系统中仅有一个Leader进行Value提交的情况下,Prepare阶段就可以跳过,从而将两阶段变为一阶段,提高效率。
 Multi-Paxos流程
Multi-Paxos流程
Multi-Paxos首先需要选举Leader,Leader的确定也是一次决议的形成,所以可执行一次Basic Paxos实例来选举出一个Leader。选出Leader之后只能由Leader提交Proposal,在Leader宕机之后服务临时不可用,需要重新选举Leader继续服务。在系统中仅有一个Leader进行Proposal提交的情况下,Prepare阶段可以跳过。
Multi-Paxos通过改变Prepare阶段的作用范围至后面Leader提交的所有实例,从而使得Leader的连续提交只需要执行一次Prepare阶段,后续只需要执行Accept阶段,将两阶段变为一阶段,提高了效率。为了区分连续提交的多个实例,每个实例使用一个Instance ID标识,Instance ID由Leader本地递增生成即可。
Multi-Paxos允许有多个自认为是Leader的节点并发提交Proposal而不影响其安全性,这样的场景即退化为Basic Paxos。
Chubby和Boxwood均使用Multi-Paxos。ZooKeeper使用的Zab也是Multi-Paxos的变形。