数据库插入操作
#使用SQL INSERT语句向表employee插入记录
import MySQLdb
#打开数据库连接
db=MySQLdb.connect('127.0.0.1','hadoop','hadoop','pythondb',charset='utf8')
#使用cursor()方法获取操作游标
cursor=db.cursor()
#SQL插入语句
sql="INSERT INTO EMPLOYEE(FIRST_NAME,LAST_NAME,AGE,SEX,INCOME) VALUES ('Air','Zhong',33,'M',2000)"
try:
#执行sql语句
cursor.execute(sql)
#提交到数据库执行
db.commit()
except:
#发生错误时回滚
db.rollback()
print('done')
#关闭数据库连接
db.close()
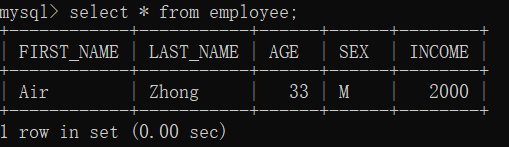
数据库查询操作
Python查询Mysql使用fetchone()方法获取单条数据,使用fetchall()方法获取多条数据
fetchone():该方法获取下一个查询结果集。结果集是一个对象
fetchall():接收全部的返回结果行
rowcount:这是一个只读属性,并返回执行execute()方法后影响的行数
示例:查询employee表中income字段大于1000的所有数据:
import MySQLdb
#打开数据库连接
db=MySQLdb.connect('127.0.0.1','hadoop','hadoop','pythondb',charset='utf8')
#使用cursor()方法获取操作游标
cursor=db.cursor()
#SQL查询语句
sql="SELECT * FROM EMPLOYEE WHERE INCOME > %s" % (1000)
try:
#执行SQL语句
cursor.execute(sql)
#获取所有记录列表
results=cursor.fetchall()
for row in results:
fname=row[0]
lname=row[1]
age=row[2]
sex=row[3]
income=row[4]
#打印结果
print("fname=%s,lname=%s,age=%s,sex=%s,income=%s" % (fname,lname,age,sex,income))
except:
print("Error:unable to fetch data")
#关闭数据库连接
db.close()
结果:
fname=Air,lname=Zhong,age=33,sex=M,income=2000.0
数据库更新操作示例:
将SEX字段为M的AGE字段递增1
import MySQLdb
#打开数据库连接
db=MySQLdb.connect('127.0.0.1','hadoop','hadoop','pythondb',charset='utf8')
#使用cursor()方法获取操作游标
cursor=db.cursor()
#SQL更新语句
sql="UPDATE EMPLOYEE SET AGE=AGE+1 WHERE SEX='%c'" % ('M')
try:
#执行sql语句
cursor.execute(sql)
#提交到数据库执行
db.commit()
except:
#发生错误时回滚
db.rollback()
print('done')
#关闭数据库连接
db.close()
结果:(用一下查询)
fname=Air,lname=Zhong,age=34,sex=M,income=2000.0
删除操作示例:
删除AGE大于20的所有数据
import MySQLdb
#打开数据库连接
db=MySQLdb.connect('127.0.0.1','hadoop','hadoop','pythondb',charset='utf8')
#使用cursor()方法获取操作游标
cursor=db.cursor()
#SQL更新语句
sql="DELETE FROM EMPLOYEE WHERE AGE>'%s'" % (20)
try:
#执行sql语句
cursor.execute(sql)
#提交到数据库执行
db.commit()
except:
#发生错误时回滚
db.rollback()
print('done')
#关闭数据库连接
db.close()
python mysql事务与错误处理
两个方法:commit(提交),rollback(回滚)
批量加载数据到MySQL表
1.创建mysql数据库pythonodb
2.创建数据表dcdata,包含x1~x8,label,共9列
3.文本数据集dcdata.data
4.逐行读取并插入到dcdata表中
5.提交事务
插入数据
#打开文件,读取所有文件存成列表
import re
import MySQLdb
#打开数据库连接
db=MySQLdb.connect('127.0.0.1','hadoop','hadoop','pythondb',charset='utf8')
#使用cursor()方法获取操作游标
cursor=db.cursor()
#如果数据表已经存在使用execute()方法删除表
cursor.execute('DROP TABLE IF EXISTS dcdata')
#创建数据表SQL语句
sql1='''CREATE TABLE dcdata(
x1 INT,
x2 INT,
x3 INT,
x4 INT,
x5 INT,
x6 FLOAT,
x7 FLOAT,
x8 INT,
label INT)'''
cursor.execute(sql1)
#关闭数据库连接
# db.close()
with open("dcdata.data",'r')as file:
#可以选择readline或者read的方式,但下面的代码要有所改变
data_list=file.readlines()
#遍历列表
for t in data_list:
#正则方式匹配处理字符串
text_list=re.split(r'\n',t)
text=re.split(r',',text_list[0])
# print(text)
#sql语句
sql2 = "INSERT INTO dcdata values (%s,%s,%s,%s,%s,%s,%s,%s,%s)"
#print(sql2)
#参数化方式传参
row_count=cursor.execute(sql2,[text[0],text[1],text[2],text[3],text[4],text[5],text[6],text[7],text[8]])
#显示操作结果
print('SQL语句影响的行数为%d' % row_count)
db.commit()
db.close()
结果:

浏览数据
#打开文件,读取所有文件存成列表
import re
import MySQLdb
#打开数据库连接
db=MySQLdb.connect('127.0.0.1','hadoop','hadoop','pythondb',charset='utf8')
#使用cursor()方法获取操作游标
cursor=db.cursor()
#SQL查询语句
sql="SELECT * FROM dcdata WHERE label = %s" % (1)
i=0
try:
#执行SQL语句
cursor.execute(sql)
#获取所有记录列表
results=cursor.fetchall()
for row in results:
x1=row[0]
x2=row[1]
x3=row[2]
x4=row[3]
x5=row[4]
x6=row[5]
x7=row[6]
x8=row[7]
label=row[8]
#打印结果
print("x1=%s,x2=%s,x3=%s,x4=%s,x5=%s,x6=%s,x7=%s,x8=%s,label=%s" % (x1,x2,x3,x4,x5,x6,x7,x8,label))
i=i+1
except:
print("Error:unable to fetch data")
print("符合条件的记录数:",(i))
#关闭数据库连接
db.close()
结果(最后几行):
x1=9,x2=170,x3=74,x4=31,x5=0,x6=44.0,x7=0.403,x8=43,label=1
x1=1,x2=126,x3=60,x4=0,x5=0,x6=30.1,x7=0.349,x8=47,label=1
符合条件的记录数: 269
python数据表合并
pandas提供了一个类似于关系数据库的连接(join)操作的方法
可以根据一个或多个键将不同DataFrame中的行连接起来,语法如下:
merge(left,right,how=‘inner’,on=None,left_on=None,right_on=None,left_index=False,right_index=False,sort=True,suffixes=(’_x’,’_y’),copy=True,indicator=False)
python的pandas库中的merge()支持各种内外连接
left与right:两个不同的DataFrame
how:合并(连接)方式——inner(内连接),left(左外连接),right(右外连接),outer(全外连接)。默认为inner
on:指的是用于连接的列索引名称,必须存在左右两个DataFrame对象中,如果没有指定且其他参数也未指定则以两个DataFrame的列名交集作为连接键
left_on:左侧DataFrame中用作连接键的列名;这个参数左右列名不相同,但代表的含义相同时非常有用。
right_on:右侧DataFrame中用作连接键的列名
left_index:使用左侧DataFrame中的行索引作为连接键
right_index:使用右侧DataFrame中的行索引作为连接键
sort:默认为True,待合并的数据进行排序,在大多数情况下设置为False可以提高性能
suffixes:字符串值组成的元组,用于指定当左右DataFrame存在相同列名时在列名后面附加的后缀名称,默认为(’_x’,’_y’)
copy:默认为True,总是将数据复制到数据结构中;大多数情况下设置为False可以提高性能
合并语法
sql
SELECT * FROM df1 INNER JOIN df2 ON df1.key=df2.key;
SELECT * FROM df1,df2 where df1.key=df2.key
pandas
pd.merge(df1,df2,on=‘key’)
pd.merge(df1,df2,on=‘key’,how=‘left’)
合并示例
from pandas import Series,DataFrame,merge
import numpy as np
data=DataFrame([{"id":0,"name":'lxh',"age":20,"cp":'lm'},{"id":1,"name":'xiao',"age":40,"cp":'ly',},
{"id":2,"name":'hua',"age":4,"cp":'yry'},{"id":3,"name":'be',"age":70,"cp":'old'}])
data1=DataFrame([{"id":100,"name":'lxh','cs':10},{"id":101,"name":'xiao',"cs":40},
{"id":102,"name":'hua2',"cs":50}])
data2=DataFrame([{"id":0,"name":'lxh',"cs":10},{"id":101,"name":'xiao',"cs":40},{"id":102,"name":'hua2',"cs":50}])
print("单个列名做为内连接的连接键\r\n",merge(data,data1,on="name",suffixes=('_a',"_b")))
print("多列名做为内连接的连接键\r\n",merge(data,data2,on=("name","id")))
print("不指定on则以两个DataFrame的列名交集做为连接键\r\n",merge(data,data2))#这里使用了id与name
#使用右边的DataFrame的行索引作为连接键
##设置行索引名称
indexed_data1=data1.set_index("name")
print("使用右边的DataFrame的行索引做为连接键\r\n",merge(data,indexed_data1,left_on='name',right_index=True))
结果:
单个列名做为内连接的连接键
age cp id_a name cs id_b
0 20 lm 0 lxh 10 100
1 40 ly 1 xiao 40 101
多列名做为内连接的连接键
age cp id name cs
0 20 lm 0 lxh 10
不指定on则以两个DataFrame的列名交集做为连接键
age cp id name cs
0 20 lm 0 lxh 10
使用右边的DataFrame的行索引做为连接键
age cp id_x name cs id_y
0 20 lm 0 lxh 10 100
1 40 ly 1 xiao 40 101
