文章目录
- (一)==、equals与hashCode
- (二)序列化
- (三)内部类
- (四)静态属性与静态方法的继承问题
- (五)Java编码方式
- (六)Java的异常体系
- 1、Java异常的基础知识
- 2、业务异常的通常处理机制(可选,局部异常处理)
- 3、全局异常处理(必须,上面第二步没处理的异常最后统一处理)
- 4、一些必须及时捕获处理异常的场景
- 5、一些关于处理异常的重要原则
- (七)final、finally、finalize区别与使用
(一)==、equals与hashCode
1、==
(1.1)介绍
java中的数据类型,可分为两类:
1.基本数据类型,也称原始数据类型(byte,short,char,int,long,float,double,boolean)
基本数据类型用= =比较的是数据的值。
2.引用类型(类、接口、数组)
引用类型用= =进行比较的是他们在内存中的存放地址。
所以,除非是同一个new出来的对象,他们的比较后的结果为true,否则比较后结果为false。
对象是放在堆中的,栈中存放的是对象的引用(地址)。由此可见’=='是对栈中的值进行比较的。如果要比较堆中对象的内容是否相同,那么就要重写equals方法了。
(1.2)实例
public static void main(String[] args) {
int int1 = 12;
int int2 = 12;
Integer Integer1 = new Integer(12);
Integer Integer2 = new Integer(12);
Integer Integer3 = new Integer(127);
Integer a1 = 127;
Integer b1 = 127;
Integer a = 128;
Integer b = 128;
String s1 = "str";
String s2 = "str";
String str1 = new String("str");
String str2 = new String("str");
System.out.println("int1==int2:" + (int1 == int2));//true
System.out.println("int1==Integer1:" + (int1 == Integer1));//true,Integer会自动拆箱为int,所以为true
System.out.println("Integer1==Integer2:" + (Integer1 == Integer2));//false,不同对象,在内存中存放位置不同
System.out.println("Integer3==b1:" + (Integer3 == b1));//false,Integer3指向new的对象地址,b1指向缓存中127的地址,地址不同,故为false
System.out.println("a1==b1:" + (a1 == b1));//true,a1,b1均指向缓存中127的地址
System.out.println("a==b:" + (a == b));//false,根据源码,a1,b1在127与-127范围之外时会指向new的对象地址
System.out.println("s1==s2:" + (s1 == s2));//true
System.out.println("s1==str1:" + (s1 == str1));//false
System.out.println("str1==str2:" + (str1 == str2));//fa;se
}
2、equals
(2.1)默认情况(没有覆盖equals方法)
Object的equals方法主要用于判断对象内存地址引用是不是同一个 地址(是不是同一个对象)
定义的equals与==等效
public boolean equals(Object obj) {
return (this == obj);
}
(2.2)覆盖equals方法
根据具体的代码确定equlas方法,覆盖后一般都是通过对象的内容是否相等来判断对象是否相等。下面是String类对equals方法进行重写
public boolean equals(Object anObject) {
if (this == anObject) {//参数是否为这个对象的引用
return true;
}
if (anObject instanceof String) {//参数是否为正确的类型
String anotherString = (String)anObject;
//获取关键域,判断关键域是否匹配
int n = count;
if (n == anotherString.count) {
char v1[] = value;
char v2[] = anotherString.value;
int i = offset;
int j = anotherString.offset;
while (n-- != 0) {
if (v1[i++] != v2[j++])
return false;
}
return true;
}
}
return false;
}
判断步骤:
1.若A==B 即是同一个String对象 返回true
2.若对比对象是String类型则继续,否则返回false
3.判断A、B长度是否一样,不一样的话返回false
4.逐个字符比较,若有不相等字符,返回false
3、hashCode
(3.1)定义
public native int hashCode();
hashCode()方法返回的就是一个hash码(int类型)。
hash码的主要用途就是在对对象进行散列的时候作为key输入,我们需要每个对象的hash码尽可能不同,这样才能保证散列的存取性能(将数据按特定算法指定到一个地址上)。事实上,Object类提供的默认实现确实保证每个对象的hash码不同(在对象的内存地址基础上经过特定算法返回一个hash码)。
(3.2)作用
hashCode只有在集合中用到,相当于集合的key,利用下标访问可以提高查找效率
Java中的集合(Collection)有两类,一类是List,再有一类是Set。前者集合内的元素是有序的,元素可以重复;后者元素无序,但元素不可重复。要想保证元素不重复,可两个元素是否重复应该依据什么来判断呢?
Java采用了哈希表的原理。当集合要添加新的元素时,先调用这个元素的hashCode方法,就一下子能定位到它应该放置的物理位置上。
如果这个位置上没有元素,它就可以直接存储在这个位置上,不用再进行任何比较了;(放入对象的hashcode与集合中任一元素的hashcode不相等)
如果这个位置上已经有元素了(hashcode相等),就调用它的equals方法与新元素进行比较,相同的话就不存,不相同就散列其它的地址。
所以这里存在一个冲突解决的问题。这样一来实际调用equals方法的次数就大大降低了,几乎只需要一两次。
(3.3)equals与hashCode
1.equals与hashCode关系
- 同一对象上多次调用hashCode()方法,总是返回相同的整型值。
- 如果a.equals(b),则一定有a.hashCode() 一定等于 b.hashCode()。
- 如果!a.equals(b),则a.hashCode() 不一定等于 b.hashCode()。此时如果a.hashCode() 总是不等于 b.hashCode(),会提高hashtables的性能。
- a.hashCode()==b.hashCode() 则 a.equals(b)可真可假
- a.hashCode()!= b.hashCode() 则 a.equals(b)为假。
2.实例
同时覆盖hashcode与equals方法
//学生类
public class Student {
private int age;
private String name;
public Student() {
}
public Student(int age, String name) {
super();
this.age = age;
this.name = name;
}
public int getAge() {
return age;
}
public String getName() {
return name;
}
public void setAge(int age) {
this.age = age;
}
public void setName(String name) {
this.name = name;
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + age;
result = prime * result + ((name == null) ? 0 : name.hashCode());
System.out.println("hashCode : "+ result);
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Student other = (Student) obj;
if (age != other.age)
return false;
if (name == null) {
if (other.name != null)
return false;
} else if (!name.equals(other.name))
return false;
return true;
}
}
运行结果:
stu1 == stu2 : false
stu1.equals(stu2) :true
list size:2
hashCode :775943
hashCode :775943
set size:1
结果分析:
重写equals保证姓名、年龄相等为同一对象
重写hashCode保证相同的对象不重复存入集合
stu1和stu2通过equals方法比较相等,而且返回的hashCode值一样,所以放入set集合中时只放入了一个对象。
3.equals与hashCode重写规范
(1)如果两个对象相同,那么他们的hashcode应该相等
若重写equals(Object obj)方法,有必要重写hashcode()方法,确保通过equals(Object obj)方法判断结果为true的两个对象具备相等的hashcode()返回值。
(2)如果两个对象不相同,他们的hashcode可能相同
如果equals(Object obj)返回false,即两个对象“不相同”,并不要求对这两个对象调用hashcode()方法得到两个不相同的数。
为了满足上述规范,覆盖equals方法时总要覆盖hashCode,这样该类才能结合所有基于散列的集合(如HashMap、HashSet、HashTable)一起正常运作
(二)序列化
1、什么是序列化?
对象序列化是一个用于将对象状态转换为字节流的过程,可以将其保存到磁盘文件中或通过网络发送到任何其他程序;从字节流创建对象的相反的过程称为反序列化。
序列化以特定的方式对类实例的瞬时状态进行编码保存的一种操作.序列化作用的对象是类的实例.对实例进行序列化,就是保存实例当前在内存中的状态.包括实例的每一个属性的值和引用等.反序列化的作用便是将序列化后的编码解码成类实例的瞬时状态.申请等同的内存保存该实例.
序列化的作用就是为了保存java的类对象的状态,并将对象转换成可存储或者可传输的状态,用于不同jvm之间进行类实例间的共享。

2、为什么JAVA对象需要实现序列化?
序列化就是一种用来处理对象流的机制,所谓对象流也就是将对象的内容进行流化。我们可以对流化后的对象进行读写操作,也可将流化后的对象传输于网络之间(注:要想将对象传输于网络必须进行流化)因为在对对象流进行读写操作时会引发一些问题,而序列化机制正是用来解决这些问题的。
(若对象不进行序列化,则无法跨平台传输,安全性也无法得到保证)
3、序列化的方式?
方式1:要传递的类实现Serializable接口传递对象(Java自带)
(1)介绍
1.1)Serializable接口
Serializable是序列化的意思,表示将一个对象转换成可存储或可传输的状态。用于保存在内存中各种对象的状态,并且可以把保存的对象状态再读出来。
序列化后的对象可以在网络上进行传输,也可以存储到本地。对于任何需要被序列化的对象,都必须要实现接口Serializable,它只是一个标识接口,本身没有任何成员,只是用来标识说明当前的实现类的对象可以被序列化.
1.2)Java序列化应用场景
a.把内存中的对象状态保存到一个文件中或者数据库中时候;
b.用套接字在网络上传送对象的时候;
c.通过RMI传输对象的时候;…
(2)实例
使用Java序列化把对象存储到文件中,再从文件中读出来
创建序列化对象
public class Box implements Serializable{
private int width;
private int height;
public Box(int width, int height) {
this.width = width;
this.height = height;
}
public int getWidth() {
return width;
}
public void setWidth(int width) {
this.width = width;
}
public int getHeight() {
return height;
}
public void setHeight(int height) {
this.height = height;
}
@Override
public String toString() {
return "Child{" +
"width=" + width +
", height=" + height +
'}';
}
}
读写测试
使用ObjectOutputStream对象的writeObject()方法来进行对象的写入。
使用ObjectInputStream对象的readObject()方法来读取对象。
public class SerializableTest {
public static void main(String args[]) throws Exception{
File file = new File("box.out");
FileOutputStream fos = new FileOutputStream(file);
ObjectOutputStream out = new ObjectOutputStream(fos);
Box oldBox = new Box(10,20);
out.writeObject(oldBox);
out.close();
FileInputStream fis = new FileInputStream(file);
ObjectInputStream in = new ObjectInputStream(fis);
Box newBox = (Box)in.readObject();
in.close();
System.out.println(newBox.toString());
}
}
输出结果
Child{width=10, height=20}
方式2:要传递的类实现Parcelable接口传递对象(android专用)
(1)介绍
1.1)Parcelable接口
进行Android开发的时候,无法将对象的引用传给Activities或者Fragments,我们需要将这些对象放到一个Intent或者Bundle里面,然后再传递
不过不同于将对象进行序列化,Parcelable方式的实现原理是将一个完整的对象进行分解,而分解后的每一部分都是Intent所支持的数据类型,这样也就实现传递对象的功能了。
Parcelable作用:
1)永久性保存对象,保存对象的字节序列到本地文件中;
2)通过序列化对象在网络中传递对象;
3)通过序列化在进程间传递对象。
1.2)Android序列化应用场景
需要在多个部件(Activity或Service)之间通过Intent传递一些数据,简单类型(如:数字、字符串)的可以直接放入Intent。复杂类型必须实现Parcelable接口。
1)在使用内存的时候,Parcelable比Serializable性能高,所以推荐使用Parcelable。
2)Serializable在序列化的时候会产生大量的临时变量,从而引起频繁的GC。
3)Parcelable不能使用在要将数据存储在磁盘上的情况,因为Parcelable不能很好的保证数据的持续性在外界有变化的情况下。尽管Serializable效率低点,但此时还是建议使用Serializable 。
(2)实现
2.1)写实体类,实现Parcelable接口
1、复写describeContents方法和writeToParcel方法
2、实例化静态内部对象CREATOR,实现接口Parcelable.Creator
3、自定义构造方法,私有变量的set与get
public class Pen implements Parcelable{
private String color;
private int size;
// 系统自动添加,给createFromParcel里面用
protected Pen(Parcel in) {
color = in.readString();
size = in.readInt();
}
public static final Creator<Pen> CREATOR = new Creator<Pen>() {
/**
*
* @param in
* @return
* createFromParcel()方法中我们要去读取刚才写出的name和age字段,
* 并创建一个Person对象进行返回,其中color和size都是调用Parcel的readXxx()方法读取到的,
* 注意这里读取的顺序一定要和刚才写出的顺序完全相同。
* 读取的工作我们利用一个构造函数帮我们完成了
*/
@Override
public Pen createFromParcel(Parcel in) {
return new Pen(in); // 在构造函数里面完成了 读取 的工作
}
//供反序列化本类数组时调用的
@Override
public Pen[] newArray(int size) {
return new Pen[size];
}
};
@Override
public int describeContents() {
return 0; // 内容接口描述,默认返回0即可。
}
@Override
public void writeToParcel(Parcel dest, int flags) {
dest.writeString(color); // 写出 color
dest.writeInt(size); // 写出 size
}
// ======分割线,写写get和set
//个人自己添加
public Pen() {
}
//个人自己添加
public Pen(String color, int size) {
this.color = color;
this.size = size;
}
public String getColor() {
return color;
}
public void setColor(String color) {
this.color = color;
}
public int getSize() {
return size;
}
public void setSize(int size) {
this.size = size;
}
}
2.2)MainActivity与SecondActivity之间传递实体Bean
MainActivity
public class MainActivity extends Activity {
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
findViewById(R.id.mTvOpenNew).setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View v) {
Intent open = new Intent(MainActivity.this, SecondActivity.class);
Person person = new Person();
person.setName("一去二三里");
person.setAge(18);
// 传输方式一,intent直接调用putExtra
// public Intent putExtra(String name, Serializable value)
open.putExtra("put_ser_test", person);
// 传输方式二,intent利用putExtras(注意s)传入bundle
/**
Bundle bundle = new Bundle();
bundle.putSerializable("bundle_ser",person);
open.putExtras(bundle);
*/
startActivity(open);
}
});
// 采用Parcelable的方式
findViewById(R.id.mTvOpenThird).setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View v) {
Intent mTvOpenThird = new Intent(MainActivity.this,ThirdActivity.class);
Pen tranPen = new Pen();
tranPen.setColor("big red");
tranPen.setSize(98);
// public Intent putExtra(String name, Parcelable value)
mTvOpenThird.putExtra("parcel_test",tranPen);
startActivity(mTvOpenThird);
}
});
}
}
SecondActivity
public class SecondActivity extends Activity{
private TextView mTvSecondDate;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_second);
mTvSecondDate = (TextView) findViewById(R.id.mTvSecondDate);
// Intent intent = getIntent();
// Pen pen = (Pen)intent.getParcelableExtra("parcel_test");
Pen pen = (Pen)getIntent().getParcelableExtra("parcel_test");
mTvSecondDate = (TextView) findViewById(R.id.mTvSecondDate);
mTvSecondDate.setText("颜色:"+pen.getColor()+"\\n"
+"大小:"+pen.getSize());
}
}
Serializable 和Parcelable的对比
android上应该尽量采用Parcelable,效率至上
(1)编码上:
Serializable代码量少,写起来方便;Parcelable代码多一些
(2)效率上:
Parcelable的速度比高十倍以上;serializable的迷人之处在于你只需要对某个类以及它的属性实现Serializable 接口即可。Serializable 接口是一种标识接口(marker interface),这意味着无需实现方法,Java便会对这个对象进行高效的序列化操作。
这种方法的缺点是使用了反射,序列化的过程较慢。这种机制会在序列化的时候创建许多的临时对象,容易触发垃圾回收。
Parcelable方式的实现原理是将一个完整的对象进行分解,而分解后的每一部分都是Intent所支持的数据类型,这样也就实现传递对象的功能了
(三)内部类
1、什么是内部类
定义在类内部的类就被称为内部类。外部类按常规的类访问方式使用内部类,唯一的差别是内部类可以访问外部类的所有方法与属性,包括私有方法与属性。
内部类是一个编译时的概念。外部类outer.java内定义了一个内部类inner,一旦编译成功,就会生成两个完全不同的.class文件,分别是outer.class和outer$inner.class。
2、为什么要设计内部类
- 内部类是为了更好的封装,把内部类封装在外部类里,不允许同包其他类访问
- 内部类中的属性和方法即使是外部类也不能直接访问,相反内部类可以直接访问外部类的属性和方法,即使private
- 实现多继承:每个内部类都能独立地继承一个(接口的)实现,所以无论外围类是否已经继承了某个(接口的)实现,对于内部类都没有影响。
- 匿名内部类用于实现回调
3、内部类分类
(3.1)静态内部类
定义在类内部的静态类
3.1.1)代码
定义
public class Out {
private static int a;
private int b;
public static class Inner {
public void print() {
System.out.println(a);
}
}
}
Inner是静态内部类。静态内部类可以访问外部类所有静态变量和方法。静态内部类和一般类一致,可以定义静态变量、方法,构造方法等。
使用
Out.Inner inner = new Out.Inner();
inner.print();
外部类.静态内部类
3.1.2)实现原理
public class Out$Inner {
public Out$Inner() {
}
public void print() {
System.out.println(Out.access$000());
}
}
Out.java编译后会生成两个class文件,分别是Out.class和Out$Inner.class。因为这两个类处于同一个包下,所以静态内部类自然可以访问外部类的非私有成员。对外部类私有变量的访问则通过外部类的access$000()方法。
3.1.3)应用场景
与外部类关系密切且不依赖外部类实例。
Java集合类HashMap内部就有一个静态内部类Entry。Entry是HashMap存放元素的抽象,HashMap内部维护Entry数组用了存放元素,但是Entry对使用者是透明的。
(3.2)成员内部类
定义在类内部的非静态类称为成员内部类。
3.2.1)代码
定义
public class Out {
private static int a;
private int b;
public class Inner {
public void print() {
System.out.println(a);
System.out.println(b);
}
}
}
成员内部类可以访问外部类所有的变量和方法,包括静态和实例,私有和非私有。和静态内部类不同的是,每一个成员内部类的实例都依赖一个外部类的实例(成员内部类是依附外部类而存在的)。其它类使用内部类必须要先创建一个外部类的实例。
使用
Out out = new Out();
Out.Inner inner = out.new Inner();
inner.print();
注:
(1)成员内部类不能定义静态方法和变量(final修饰的除外)。这是因为成员内部类是非静态的,类初始化的时候先初始化静态成员,如果允许成员内部类定义静态变量,那么成员内部类的静态变量初始化顺序是有歧义的。
(2)成员内部类是依附于外围类的,所以只有先创建了外围类才能够创建内部类。
(3)成员内部类与外部类可以拥有同名的成员变量或方法,默认情况下访问的是成员内部类的成员。如果要外部类的同名成员,需用下面的形式访问:
OutterClass(外部类).this.成员
3.2.2)实现原理
Out.java编译后会生成两个class文件,分别是Out.class和Out$Inner.class。成员内部类的代码如下:
public class Out$Inner {
public Out$Inner(Out var1) {
this.this$0 = var1;
}
public void print() {
System.out.println(Out.access$000());
}
}
成员内部类访问外部类的私有变量和方法也是通过编译时生成的代码访问的。区别是,成员内部类的构造方法会添加一个外部类的参数。
解释:为什么Java中成员内部类可以访问外部类成员?
总结为2点:1、内部类对象的创建依赖于外部类对象;2、内部类对象持有指向外部类对象的引用。
1 编译器自动为内部类添加一个类型为Outer,名字为this$0的成员变量,这个成员变量就是指向外部类对象的引用;
2 编译器自动为内部类的构造方法添加一个类型为Outer的参数,在构造方法内部使用这个参数为内部类中添加的成员变量赋值;
3 在调用内部类的构造函数初始化内部类对象时, 会默认传入外部类的引用。
3.2.3)应用场景
静态内部类&成员内部类对比
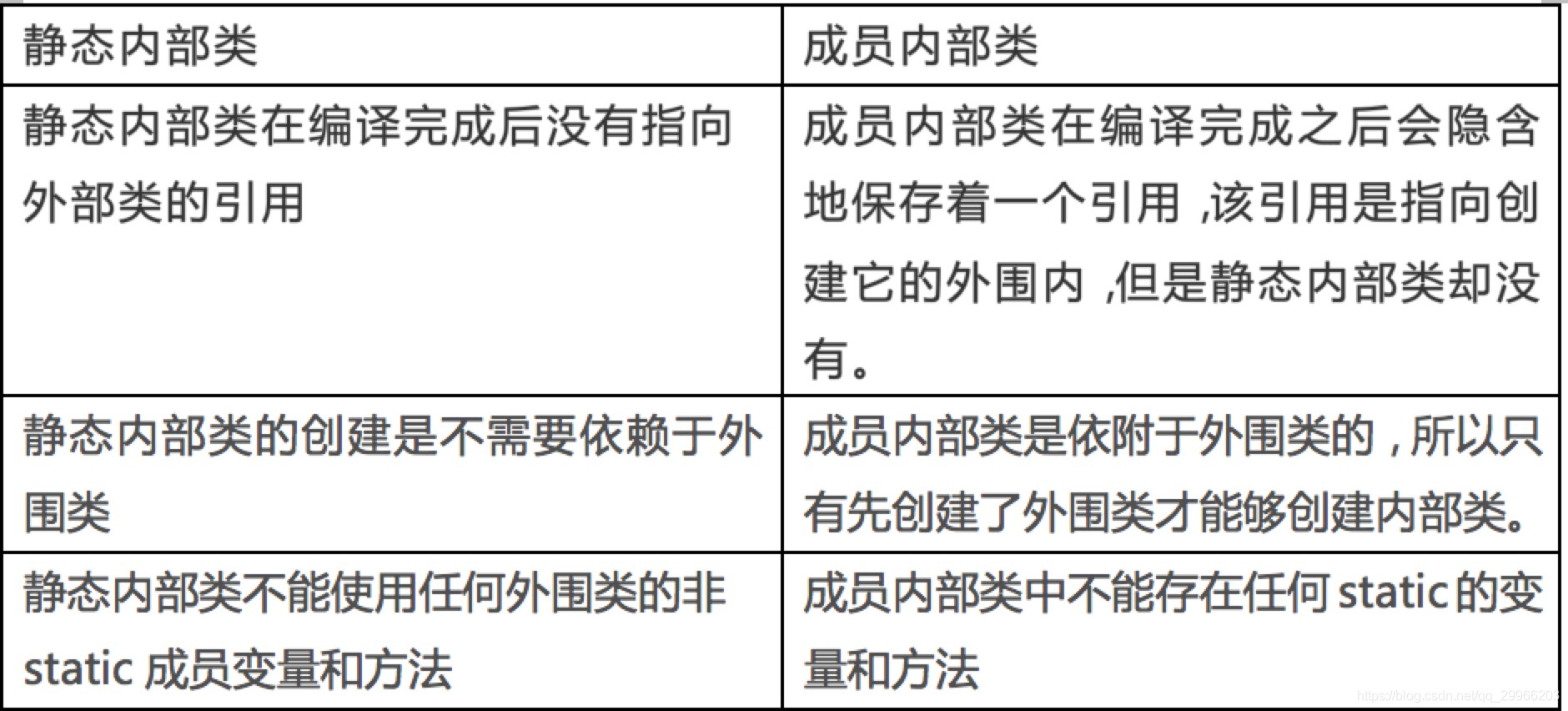
(3.3)局部内部类&闭包
1、局部内部类
定义在外部类方法中的类,叫局部类
3.3.1)代码
定义
public class Out {
private static int a;
private int b;
public void test(final int c) {
final int d = 1;
class Inner {
public void print() {
System.out.println(a);
System.out.println(b);
System.out.println(c);
System.out.println(d);
}
}
}
public static void testStatic(final int c) {
final int d = 1;
class Inner {
public void print() {
System.out.println(a);
//定义在静态方法中的局部类不可以访问外部类的实例变量
//System.out.println(b);
System.out.println(c);
System.out.println(d);
}
}
}
}
局部类只能在定义该局部类的方法中使用。定义在实例方法中的局部类可以访问外部类的所有变量和方法,定义在静态方法中的局部类只能访问外部类的静态变量和方法。同时局部类还可以访问方法的参数和方法中的局部变量,这些参数和变量必须要声明为final的。否则会报错
Cannot refer to a non-final variable x inside an inner class defined in a different method
3.3.2)实现原理
Out.java编译后局部类会生成相应的class文件。
class Out$1Inner {
Out$1Inner(Out var1, int var2) {
this.this$0 = var1;
this.val$c = var2;
}
public void print() {
System.out.println(Out.access$000());
System.out.println(Out.access$100(this.this$0));
System.out.println(this.val$c);
System.out.println(1);
}
}
和成员内部类类似,生成的局部类的构造方法包含了外部类的参数,并且还包含了定义局部类方法的参数。
解释了为什么局部类访问的变量需要final修饰?
基本知识:内部类和外部类是处于同一个级别的,方法内部的类不是在调用方法时才会创建的,它们一样也被事先编译了,内部类也不会因为定义在方法中就会随着方法的执行完毕就被销毁。(内部类只有没有引用指向该对象时,才回被GC回收)
问题1:外部类方法结束时候,局部变量就会销毁,但内部类对象可能还存在,并指向一个不存在的局部变量。
问题2:局部变量复制为内部类的成员变量时,必须保证两个变量一致。在内部类修改成员变量,方法中局部变量也会跟着改变。
解决:将局部变量设置为final,
这样编译器会将final局部变量"复制"作为局部内部类中的数据成员(且此时为常量)
使内部类无法去修改这个变量。保证复制的数据成员与原始变量一致。
仿佛局部变量的"生命周期"延长了
3.3.3)应用场景
局部内部类是嵌套在方法和作用域内的,对于这个类的使用主要是应用与解决比较复杂的问题,想创建一个类来辅助我们的解决方案,但又不希望这个类是公共可用的,所以就产生了局部内部类,局部内部类和成员内部类一样被编译,只是它的作用域发生了改变,它只能在该方法和属性中被使用,出了该方法和属性就会失效。
2、闭包
2.1)定义
闭包就是把函数以及变量包起来,使得变量的生存周期延长。闭包跟面向对象是一棵树上的两条枝,实现的功能是等价的。
闭包(Closure)是一种能被调用的对象,它保存了创建它的作用域的信息。JAVA并不能显式地支持闭包,但是在JAVA中,闭包可以通过“接口+内部类”(接口实例化)来实现。
2.2)使用
闭包是实现回调的一种很灵活的方式
public class OutClass {
private void readBook(){
System.out.println("read book");
}
public InnerClass getInnerClass(){
return new InnerClass();
}
public class InnerClass{
public void read(){
readBook();
}
}
}
在该例种InnerClass即是一个闭包,它包含了OutClass的对象;调用InnerClass的read()方法会回调OutClass的readBook()方法。
2.3)应用
一个接口程序员和一个基类作家都有一个相同的方法work,相同的方法名,但是其含义完全不同,这时候就需要闭包。
interface Writer {//作家基类
void work(){};
}
interface programmer{//程序员接口
void work();
}
闭包实现
public class WriterProgrammer extends Writer {
@Override
public void work(){
//写作
}
public void code(){
//写代码
}
public ProgrammerInner getProgrammerInner(){
return new ProgrammerInner();
}
class ProgrammerInner implements programmer{
@Override
public void work(){
code();
}
}
}
使用
public static void main(String[] args) {
WriterProgrammer writerProgrammer = new WriterProgrammer();
writerProgrammer.work();
writerProgrammer.getProgrammerInner().work();
}
问题
匿名函数里的变量引用,也叫做变量引用泄露,会导致线程安全问题,因此如果在匿名类内部引用函数局部变量,必须将其声明为final,即不可变对象。
(3.4)匿名内部类
3.4.1)代码
匿名内部类需要提前定义(必须存在)
public class Out {
private static int a;
private int b;
private Object obj = new Object() {
private String name = "匿名内部类";
@Override
public String toString() {
return name;
}
};
public void test() {
Object obj = new Object() {
@Override
public String toString() {
System.out.println(b);
return String.valueOf(a);
}
};
System.out.println(obj.toString());
}
}
3.4.2)实现原理
Out.java编译后匿名内部类会生成相应的class文件。
class Out$1 {
private String name;
Out$1(Out var1) {
this.this$0 = var1;
this.name = "匿名内部类";
}
public String toString() {
return this.name;
}
}
匿名内部类可以访问外部类所有的变量和方法。
3.4.3)应用场景
匿名内部类常用于回调函数,比如我们常用的绑定监听的时候。
public interface OnClickListener {
/**
* Called when a view has been clicked.
*
* @param v The view that was clicked.
*/
void onClick(View v);
}
view.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View v) {
Toast.makeText(v.getContext(),"click",Toast.LENGTH_SHORT).show(); }
});
4、内部类总结
(4.1)内部类特点
1.非静态内部类对象不仅指向该内部类,还指向实例化该内部类的外部类对象的内存。
2.内部类和普通类一样可以重写Object类的方法,如toString方法;并且有构造函数,执行顺序依旧是先初始化属性,再执行构造函数
3.在编译完之后,会出现(外部类.class)和(外部类﹩内部类.class)两个类文件名。
4.内部类可以被修饰为private,只能被外部类所访问。事实上一般也都是如此书写。
5.内部类可以被写在外部类的任意位置,如成员位置,方法内。
(4.2)内部类访问外部类
- 静态时,静态内部类只能访问外部类静态成员;非静态内部类都可以直接访问。(原因是:内部类有一个外部类名.this的指引)当访问外部类静态成员出现重名时,通过(外部类名.静态成员变量名)访问。如,Out.show();
- 重名情况下,非静态时,内部类访问自己内部类通过this.变量名。访问外部类通过(外部类名.this.变量名)访问 。如Out.this.show();
- 在没有重名的情况下,无论静态非静态,内部类直接通过变量名访问外部成员变量。
(4.3)外部类访问内部类 - 内部类为非静态时,外部类访问内部类,必须建立内部类对象。建立对象方法,如前所述。
- 内部类为静态时,外部类访问非静态成员,通过(外部类对象名.内部类名.方法名)访问,如new Out().In.function();
- 内部类为静态时,外部类访问静态成员时,直接通过(外部类名.内部类名.方法名),如 Out.In.funchtion();
- 当内部类中定义了静态成员时,内部类必须是静态的;当外部静态方法访问内部类时,内部类也必须是静态的才能访问。
(四)静态属性与静态方法的继承问题
1、静态属性与静态方法是否能被继承
(1.1)实例
Parent.java
public class Parent {//父类
public String normalStr = "Normal member of parent.";
public static String staticStr = "Static member of parent.";
public void normalMethod(){
System.out.println("Normal method of parent.");
}
public static void staticMethod(){
System.out.println("Static method of parent.");
}
}
ChildA.java
public class ChildA extends Parent {
//子类A继承父类所有属性与方法
}
Main.java
public class Main {
public static void main(String[] args) {
Parent child = new ChildA();
System.out.println(child.normalStr);
System.out.println(child.staticStr);
child.normalMethod();
child.staticMethod();
}
}
结果
Normal member of parent.
Static member of parent.
Normal method of parent.
Static method of parent.
(1.2)结论
子类可以继承父类的非静态方法与非静态属性。
子类可以继承父类的静态方法与静态属性。
2、静态属性与静态方法是否能被重写
(2.1)实例
Parent.java
public class Parent {//父类
public String normalStr = "Normal member of parent.";
public static String staticStr = "Static member of parent.";
public void normalMethod(){
System.out.println("Normal method of parent.");
}
public static void staticMethod(){
System.out.println("Static method of parent.");
}
}
ChildA.java
public class ChildB extends Parent {
//子类B继承父类所有属性与方法
public String normalStr = "Normal member of child.";
public static String staticStr = "Static member of child.";
public void normalMethod(){
System.out.println("Normal method of child.");
}
public static void staticMethod(){
System.out.println("Static method of child.");
}
}
Main.java
public class Main {
public static void main(String[] args) {
Parent child = new ChildB();
System.out.println(child.normalStr);
System.out.println(Parent.staticStr);
child.normalMethod();
Parent.staticMethod();
}
}
结果
Normal member of parent.
Static member of parent.
Normal method of child.
Static method of parent.
(2.2)结论
子类不可以重写父类的静态/非静态属性。父类的同名属性会被隐藏。
子类可以重写覆盖父类的非静态方法但不可重写覆盖父类静态方法。
3、结论
对于非静态的属性和方法
- 对于非静态属性,子类可以继承父类的非静态属性。但是当子类和父类有相同的非静态属性时,并没有重写并覆盖父类的非静态属性,只是隐藏了父类的非静态属性。
- 对于非静态的方法,子类可以继承父类的非静态方法并可以重写覆盖父类的非静态属性方法。
对于静态的属性和方法
- 对于静态的属性,子类可以继承父类的静态属性。但是和非静态的属性一样,会被隐藏。
- 对于静态的方法,子类可以继承父类的静态方法。但是子类不可重写覆盖父类的静态方法,子类的同名静态方法会隐藏父类的静态方法。
4、原因
其实,java中静态属性(静态变量)和静态方法没有继承这一说的,当然更没有被重写(overwrite),而是叫隐藏.
- 静态方法和属性是属于类的,调用的时候直接通过类名.方法名即可,不需要继承机制也可以调用。如果子类里面定义了同样的静态方法和属性,那么这时候父类的静态方法或属性称之为"隐藏"(hide)。如果你想要调用父类的静态方法和属性,直接通过父类名.方法或变量名完成。至于是否继承一说,子类是有“继承”静态方法和静态属性,但是跟实例方法和属性(实例变量)的继承是不一样的意思(这里要切记),静态的"继承",通过子类能调用相关的静态变量与静态方法。
- 多态之所以能够实现依赖于继承、接口和重写、重载(继承和重写最为关键)。有了继承和重写就可以实现父类的引用指向不同子类的对象。重写的功能是:"重写"后子类的优先级要高于父类的优先级,但是静态变量与静态方法的“隐藏”是没有这个优先级之分的。
- 静态属性(静态变量)、静态方法无继承,但有隐藏,静态方法又不能被重写,因此不能实现多态。非静态方法(实例发方法)可以被继承和重写,因此可以实现多态。
(五)Java编码方式
一、字节与字符
字节(Byte)=8bit 默认数据的最小单位
字符(Character)=2byte=16bit(Java默认UTF-16编码)
char: 2 byte
boolean: 1 byte
short: 2 byte
int: 4 byte
float: 4 byte
long: 8 byte
double: 8 byte
二、为何要编码——如何让计算机表示人类能够理解的符号
1、计算机中存储信息的最小单元是1byte即8bit,所以能表示的字符范围是 0~255 个
2、人类要表示的符号太多,无法用一个字节来完全表示
3、需要一个新的数据结构char来表示这些字符。char与byte之间转换需要编码与解码
编码:字节与字符的转换方式
三、各类编码规范
3.1 ASCII
我们知道,在计算机内部,所有的信息最终都表示为一个二进制的字符串。每一个二进制位(bit)有0和1两种状态,因此八个二进制位就可以组合出256种状态,这被称为一个字节(byte)。也就是说,一个字节一共可以用来表示256种不同的状态,每一个状态对应一个符号,就是256个符号,从0000000到11111111。
上个世纪60年代,美国制定了一套字符编码,对英语字符与二进制位之间的关系,做了统一规定。这被称为ASCII码,一直沿用至今。
ASCII码一共规定了128个字符的编码,比如空格"SPACE"是32(二进制00100000),大写的字母A是65(二进制01000001)。这128个符号(包括32个不能打印出来的控制符号),只占用了一个字节的后面7位,最前面的1位统一规定为0。
3.2 ISO-8858-1
但西方世界不光只有英语一门语言。包括德语,法语,西班牙语都有自己的特殊字母。每个国家都可以定义属于自己语言的特殊编码标准,而且大小照样不超过256。因为ASCII码中本身就有很多空码位没有使用。
128 个字符显然是不够用的,于是 ISO 组织在 ASCII 码基础上又制定了一些列标准用来扩展 ASCII 编码,它们是 ISO-8859-1~ISO-8859-15,其中 ISO-8859-1 涵盖了大多数西欧语言字符,所有应用的最广泛。ISO-8859-1 仍然是单字节编码,它总共能表示 256 个字符。
3.3 GB2312
信息交换用汉字编码字符集 基本集
双字节编码,总的编码范围是 A1-F7,其中从 A1-A9 是符号区,总共包含 682 个符号,从 B0-F7 是汉字区,包含 6763 个汉字。
3.4 GBK
汉字内码扩展规范
扩展 GB2312,加入更多的汉字,它的编码范围是 8140~FEFE(去掉 XX7F)总共有 23940 个码位,它能表示 21003 个汉字,它的编码是和 GB2312 兼容的,也就是说用 GB2312 编码的汉字可以用 GBK 来解码,并且不会有乱码。
这也是很多文件默认使用的编码,有时候打开文件中文变乱码了,这时候就需要规定编码方式为GBK。
3.5 Unicode
Unicode只是一个符号集,它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储。
在出现Unicode之前,几乎每一种文字都有一套自己的编码方式。同一段“字节流”,在美帝可能是"hello world",到我们天朝就变成“锟斤拷” ,“烫烫烫”了。
ISO 试图想创建一个全新的超语言字典,世界上所有的语言都可以通过这本字典来相互翻译。故这本字典很复杂。最初,每个字符占用2个字节,总共65535个字符空间。从第四版开始加入的“扩展字符集”开始使用4个字节(32 bit)编码。目前Unicode收录的字符规模大概在12万左右。
Unicode只是一套符号的编码,计算机对Unicode字符具体存取方式有:UTF-16(字符用2字节表示)、UTF-32(字符用4字节表示)、UTF-8(字符不定长)
3.5.1 UTF-16
UTF-16 具体定义了 Unicode 字符在计算机中存取方法。UTF-16 用两个字节来表示 Unicode 转化格式,这个是定长的表示方法,不论什么字符都可以用两个字节表示,两个字节是 16 个 bit,所以叫 UTF-16。
UTF-16 表示字符非常方便,每两个字节表示一个字符,这个在字符串操作时就大大简化了操作,这也是 Java 以 UTF-16 作为内存的字符存储格式的一个很重要的原因。
用 UTF-16 编码将 char 数组放大了一倍,单字节范围内的字符,在高位补 0 变成两个字节,中文字符也变成两个字节。从 UTF-16 编码规则来看,仅仅将字符的高位和地位进行拆分变成两个字节。特点是编码效率非常高,规则很简单,但是这对于存储来说是极大的浪费,可以看到补了很多的0,文本文件的大小会因此大出二三倍,这是无法接受的。
3.5.2 UTF-8
互联网的普及,强烈要求出现一种统一的编码方式。UTF-8就是在互联网上使用最广的一种Unicode的实现方式。
UTF-8最大的一个特点,就是它是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。
UTF-8的编码规则很简单,只有二条:
1、对于单字节的符号,字节的第一位设为0,后面7位为这个符号的unicode码。因此对于英语字母,UTF-8编码和ASCII码是相同的。
2、对于n字节的符号(n>1),第一个字节的前n位都设为1,第n+1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的unicode码。
四、几种编码格式的比较
1、GB2312 与 GBK 编码规则类似,但是 GBK 范围更大,它能处理所有汉字字符,所以 GB2312 与 GBK 比较应该选择 GBK。
2、UTF-16 与 UTF-8 都是处理 Unicode 编码,它们的编码规则不太相同,相对来说 UTF-16 编码效率最高,字符到字节相互转换更简单,进行字符串操作也更好。它适合在本地磁盘和内存之间使用,可以进行字符和字节之间快速切换,如 Java 的内存编码就是采用 UTF-16 编码。但是它不适合在网络之间传输,因为网络传输容易损坏字节流,一旦字节流损坏将很难恢复,想比较而言 UTF-8 更适合网络传输,对 ASCII 字符采用单字节存储,另外单个字符损坏也不会影响后面其它字符,在编码效率上介于 GBK 和 UTF-16 之间,所以 UTF-8 在编码效率上和编码安全性上做了平衡,是理想的中文编码方式。
五、总结
总而言之,一切都是字节流,其实没有字符流这个东西。字符只是根据编码集对字节流翻译之后的产物。而编码集是人为规定的产物。
六、Java对字符的处理
(1)IO操作中存在的编码
我们知道涉及到编码的地方一般都在字符到字节或者字节到字符的转换上,而需要这种转换的场景主要是在 I/O 的时候,这个 I/O 包括磁盘 I/O 和网络 I/O,关于网络 I/O 部分在后面将主要以 Web 应用为例介绍。下图是 Java 中处理 I/O 问题的接口:
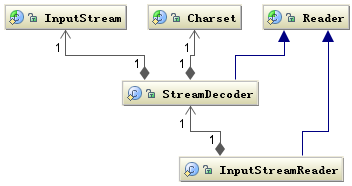
Reader 类是 Java 的 I/O 中读字符的父类,而 InputStream 类是读字节的父类,InputStreamReader 类就是关联字节到字符的桥梁,它负责在 I/O 过程中处理读取字节到字符的转换,而具体字节到字符的解码实现它由 StreamDecoder 去实现,在 StreamDecoder 解码过程中必须由用户指定 Charset 编码格式。值得注意的是如果你没有指定 Charset,将使用本地环境中的默认字符集,例如在中文环境中将使用 GBK 编码。
写的情况也是类似,字符的父类是 Writer,字节的父类是 OutputStream,通过 OutputStreamWriter 转换字符到字节。如下图所示:
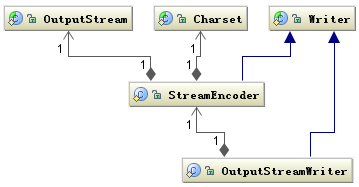
同样 StreamEncoder 类负责将字符编码成字节,编码格式和默认编码规则与解码是一致的。
如下面一段代码,实现了文件的读写功能:
String file = "c:/stream.txt";
String charset = "UTF-8";
// 写字符换转成字节流
FileOutputStream outputStream = new FileOutputStream(file);
OutputStreamWriter writer = new OutputStreamWriter(
outputStream, charset);
try {
writer.write("这是要保存的中文字符");
} finally {
writer.close();
}
// 读取字节转换成字符
FileInputStream inputStream = new FileInputStream(file);
InputStreamReader reader = new InputStreamReader(
inputStream, charset);
StringBuffer buffer = new StringBuffer();
char[] buf = new char[64];
int count = 0;
try {
while ((count = reader.read(buf)) != -1) {
buffer.append(buffer, 0, count);
}
} finally {
reader.close();
}
(2)内存中操作中的编码
在 Java 开发中除了 I/O 涉及到编码外,最常用的应该就是在内存中进行字符到字节的数据类型的转换,Java 中用 String 表示字符串,所以 String 类就提供转换到字节的方法,也支持将字节转换为字符串的构造函数。如下代码示例:
- getBytes(charset)
这是java字符串处理的一个标准函数,其作用是将字符串所表示的字符按照charset编码,并以字节方式表示。注意字符串在java内存中总是按unicode编码存储的。比如"中文",正常情况下(即没有错误的时候)存储为"4e2d 6587",如果charset为"gbk",则被编码为"d6d0 cec4",然后返回字节"d6 d0 ce c4".如果charset为"utf8"则最后是"e4 b8 ad e6 96 87".如果是"iso8859-1",则由于无法编码,最后返回 “3f 3f”(两个问号)。
java.class类的编码为:unicode;
windows默认的编码为:中文:gb2312; 英文:iso8859;
String str = "张三" ;
byte[] jiema= str.getBytes("gb2312") ; //解码
String bianma = new String(jiema,"UTF-8");//编码 如果上面的解码不对 可能出现问题
- new String(charset)
这是java字符串处理的另一个标准函数,和上一个函数的作用相反,将字节数组按照charset编码进行组合识别,最后转换为unicode存储。参考上述getBytes的例子,“gbk” 和"utf8"都可以得出正确的结果"4e2d 6587",但iso8859-1最后变成了"003f 003f"(两个问号)。
因为utf8可以用来表示/编码所有字符,所以new String( str.getBytes( “utf8” ), “utf8” ) === str,即完全可逆。 - setCharacterEncoding()
该函数用来设置http请求或者相应的编码。
对于request,是指提交内容的编码,指定后可以通过getParameter()则直接获得正确的字符串,如果不指定,则默认使用iso8859-1编码,需要进一步处理。参见下述"表单输入".值得注意的是在执行setCharacterEncoding()之前,不能执行任何getParameter()。java doc上说明:This method must be called prior to reading request parameters or reading input using getReader()。而且,该指定只对POST方法有效,对GET方法无效。分析原因,应该是在执行第一个getParameter()的时候,java将会按照编码分析所有的提交内容,而后续的getParameter()不再进行分析,所以setCharacterEncoding()无效。而对于GET方法提交表单是,提交的内容在URL中,一开始就已经按照编码分析所有的提交内容,setCharacterEncoding()自然就无效。
对于response,则是指定输出内容的编码,同时,该设置会传递给浏览器,告诉浏览器输出内容所采用的编码。
(六)Java的异常体系
1、Java异常的基础知识
异常知识体系树如下图:
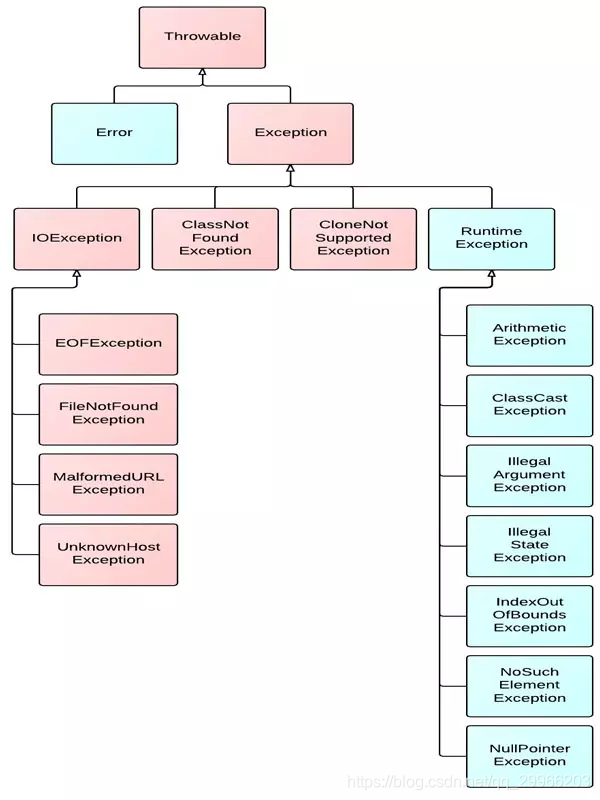
Java异常以Throwable开始,扩展出Error和Exception。
Error是程序代码无法处理的错误,比如OutOfMemoryError、ThreadDeath等。这些异常发生时,Java虚拟机(JVM)一般会选择线程终止退出,其表示程序在运行期间出现了十分严重、不可恢复的错误,应用程序只能中止运行。
Exception分运行时异常和非运行时异常。运行时异常都是RuntimeException类及其子类异常,如NullPointerException、IndexOutOfBoundsException等,这些异常也是不检查异常,程序代码中自行选择捕获处理,也可以不处理。这些异常一般是由程序逻辑错误引起的,程序代码应该从逻辑角度尽可能避免这类异常的发生。所有继承Exception且不是RuntimeException的异常都是非运行时异常,也称检查异常,如上图中的IOException和ClassNotFoundException,编译器会对其作检查,故程序中一定会对该异常进行处理,处理方法要么在方法体中声明抛出checked Exception,要么使用catch语句捕获checked Exception进行处理,不然不能通过编译。
2、业务异常的通常处理机制(可选,局部异常处理)
(2.1)不想处理或未知的异常一直往外抛直至到最上层集中处理,注意集中处理,处理时必须输出对应的日志。
如:利用Sring mvc支持异常集中处理特性
不想处理或未知的异常从dao->service->controller往上抛,然后在controller统一集中处理,当然可按需集中处理,如不处理统一交给全局异常处理。
注意:异常集中处理时不能丢掉或吃掉异常,一定要把异常捕获并后台输出错误日志,但页面上不能输出错误日志,且响应状态码不能设置为200,要按需设置为40x或50x。

(2.2)Jsp页面处理异常
Jsp代码抛出异常并结合errorPage搭配组合使用。如:新建一个异常接收页面error.jsp,在该页面指定<%@ page isErrorPage=“true”%>,然后其他jsp页面的异常处理指向它,<%@ page errorPage=“error.jsp”%>当然可按需处理,如不处理统一给全局异常处理。
注意:error.jsp不能丢掉或吃掉异常,一定要把异常捕获并后台输出错误日志,但页面上不能输出错误日志,且error.jsp的响应状态码不能设置为200,要按需设置为40x或50x。
3、全局异常处理(必须,上面第二步没处理的异常最后统一处理)
(3.1)通过web.xml配置接收异常的页面

其他http响应状态码按需配置,如400、502、503、504等
(3.2)按指定异常配置接收异常页面

注意:此异常接收处理页面不能用静态页必须是动态页,且不能丢掉或吃掉异常,一定要把异常捕获并后台输出错误日志,但页面上不能输出错误日志,且异常接收页面的响应状态码不能设置为200,要按需设置为40x或50x。
以上第二和第三部分互为一体,有些异常需要局部处理的按需处理。有些异常可以进行全局处理。
4、一些必须及时捕获处理异常的场景
- 用多线程实现的定时任务在循环处理数据时出现异常必须及时处理,否则执行时会退出。
- 页面豆腐块接口或供外接口必须处理异常,如出现异常返回空字符串或其他指定格式的信息提示返回。
- ajax异步调用的接口必须处理异常,如出现异常返回空字符串或其他指定格式的信息提示返回。
5、一些关于处理异常的重要原则
- 捕获异常是为了处理它,捕获异常后吃掉不作任何处理是毫无节操无人品的耍流氓,至少要输出简单的错误日志提示,如果不想处理它,请将该异常抛给它的调用者。捕获异常后不处理的代码示例:
try{
Do something;
}catch(Exeception e){
//此处无任何代码处理异常,挖坑作死的节奏!
}
- 异常不要用来做流程或条件控制,因为异常的处理效率比较低。
- 防止出现空指针异常是程序员的基本修养,注意该异常产生的场景。
- 当方法判断出错该返回时应该抛出异常,该抛异常就得抛,而不是返回一些错误值,如返回-1 或者 -2 之类的错误值。
- 如需处理处理异常,其处理的粒度不能太粗,如几百行代码放到一个try-catch 块中处理,应该一个一个异常放在各自的try-catch 块中处理。
- 对于一个应用来说,应该要有自己的一套整体的异常处理机制,当各种异常发生时能得到相应统一的处理风格,将友好的异常信息反馈给用户。
(七)final、finally、finalize区别与使用
1、final 修饰符(关键字)
final用于控制成员、方法或者是一个类是否可以被重写或者继承等功能。
(1)如果类被声明为final,意味着它不能再派生出新的子类,不能作为父类被继承。
(2)将变量或者方法声明为final,可以保证他们在使用中不被改变。其初始化可以在两个地方:一是其定义处,也就是说,在final变量定义时直接给其赋值;二是构造函数中。这2个地方只能选其一,要么在定义处直接给其赋值,要么在构造函数中给值,并且在以后的引用中,只能读取,不可修改。被声明为final的方法也同样只能使用,不能重写。
2、finally(用于异常处理)
一般是用于异常处理中,提供finally块来执行任何的清楚操作,try{} catch(){} finally{}。finally关键字是对java异常处理模型的最佳补充。**finally结构使代码总会执行,不关有无异常发生。**使得finally可以维护对象的内部状态,并可以清理非内存资源。
finally在try,catch中可以有,可以没有。如果trycatch中有finally则必须执行finally块中的操作。一般情况下,用于关闭文件的读写操作,或者是关闭数据库的连接等等。
3、finalize(用于垃圾回收)
finalize这个是方法名。在java中,允许使用finalize()方法在垃圾收集器将对象从内存中清理出去之前做必要的清理工作。这个方法是Object类中定义的,因此,所有的类都继承了它。finalize()方法是在垃圾收集器删除对象之前对这个对象调用的。
一旦垃圾回收器准备释放对象所占的内存空间,如果对象覆盖了Object的finalize()并且函数体内不为空,就会首先调用对象的finalize(),然后在下一次垃圾回收动作发生的时候真正回收对象所占的空间。
尽量避免使用finalize():
1、finalize()不一定会被调用, 因为java的垃圾回收器的特性就决定了它不一定会被调用.
2、就算finalize()函数被调用, 它被调用的时间充满了不确定性, 因为程序中其他线程的优先级远远高于执行finalize()函数线程的优先级。也许等到finalize()被调用,数据库的连接池或者文件句柄早就耗尽了.
3、如果一种未被捕获的异常在使用finalize方法时被抛出,这个异常不会被捕获,finalize方法的终结过程也会终止,造成对象出于破坏的状态。被破坏的对象又很可能导致部分资源无法被回收, 造成浪费.
4、finalize()和垃圾回收器的运行本身就要耗费资源, 也许会导致程序的暂时停止.
