文章目录
- (一)计算机网络基础知识:从一次完整的网络请求过程分析
- (1)域名解析
- (2)TCP的三次握手四次挥手
- (3)建立TCP连接后发起HTTP请求,服务器响应HTTP请求
- 3.1)网络协议
- 3.2)TCP/IP协议(互联网协议)
- 3.3)HTTP协议
- (4)客户端浏览器解析html代码
- (5)同时请求html代码中的资源(如js、css、图片等)
- (6)最后浏览器对页面进行渲染并呈现给用户
- (二)socket
- (三)websocket
- (四)HTTPS协议
- (五)网络数据解析
(一)计算机网络基础知识:从一次完整的网络请求过程分析
(1)域名解析
1.1)域名与ip地址
(1)ip地址:ip地址是一个32位(4字节)的二进制数(IPV4),常见格式为:192.168.1.101.IP地址是IP协议移动的一种统一的地址格式,为互联网上每一个网络和每一台主机分配一个逻辑地址.
IPV4与IPV6的区别:IPv4 使用32位(4字节)地址,因此只有 4,294,967,296 个,但随着联网设备的增加,这些地址显然是不够用的,所以需要新的协议和更多的地址。IPv6 便是这个新的协议,IPV6有128位(8字节)地址,有2^128-1个地址,IPv6 的目的皆在解决 IPv4 枯竭的问题。
(2)域名:ip地址与域名是一对多的关系。一个ip地址可以对应多个域名,但是一个域名只有一个ip地址。ip地址是数字组成的,不方便记忆,所以有了域名。
1.2)域名系统(DNS——Domain Name System)
域名虽然便于人们记忆,但机器之间只能互相认识IP地址,它们之间的转换工作称为域名解析,域名解析需要由专门的域名解析服务器来完成,DNS就是进行域名解析的服务器。域名的最终指向是IP。
将主机名和域名转换为IP地址。(域名:www.qq.com->119.147.15.13)
a)DNS本质
用于TCP/IP应用程序的数据库,该数据库中记录了域名和IP的对应关系,同时也是一种用于客户端和服务端通讯的应用层的计算机网络协议。
b)域名的特点
1、分布式:将域名服务器分布式存储于不同计算机中,目前全球有13台根服务器
2、阶层式:域名格式采用分层结构,类似树状结构,一棵独立的DNS子树就是一个区域(zone),一个区域被委派了授权机构(唯一授权机构:网络信息中心NIC),该机构需搭建DNS服务区,记录该区域下的子域名和IP对应关系,并且该授权机构可以再委派该区域下的子区域的DNS系统,依此向下委派,形成阶梯式管理结构
3、建立缓存:当一个DNS服务器查询到域名和IP的映射关系后,会将该映射数据写入自己的缓存中,如果其他的主机再来询问相同的映射关系时,直接读取自己的缓存,而不需要再去询问其他服务器了
c)一次请求域名解析过程
迭代查询(服务端)和递归查询(客户端)(区别:递归是查询者变化,迭代是查询者不变)
以查询 zh.wikipedia.org 为例:
- 输入域名"zh.wikipedia.org",操作系统会先检查自己的本地hosts文件是否有这个网址映射关系。如果hosts没有这个域名的映射,则查询本地DNS解析器缓存。如果hosts与本地DNS服务器缓存都没有相应的网址映射关系,首先会找TCP/IP参数中设置的首选DNS服务器。
- 客户端发送查询报文"query zh.wikipedia.org"至DNS服务器,DNS服务器首先检查自身缓存,如果存在记录则直接返回结果。
- 如果记录老化或不存在,则:
(1)DNS服务器向根域名服务器发送查询报文"query zh.wikipedia.org",根域名服务器返回顶级域.org 的权威域名服务器地址。
(2)DNS服务器向 .org 域的权威域名服务器发送查询报文"query zh.wikipedia.org",得到二级域.wikipedia.org 的权威域名服务器地址。
(3)DNS服务器向 .wikipedia.org 域的权威域名服务器发送查询报文"query zh.wikipedia.org",得到主机 zh 的A记录,存入自身缓存并返回给客户端。


1.3)以Chrome浏览器为例,Chrome解析域名对应的IP地址
- Chrome浏览器会首先搜索浏览器自身的DNS缓存(可以使用 chrome://net-internals/#dns 来进行查看),浏览器自身的DNS缓存有效期比较短,且容纳有限,大概是1000条。如果自身的缓存中存在blog.csdn.net 对应的IP地址并且没有过期,则解析成功。
- 如果(1)中未找到,那么Chrome会搜索操作系统自身的DNS缓存(可以在命令行下使用 ipconfig /displaydns 查看)。如果找到且没有过期则成功。
- 如果(2)中未找到,那么尝试读取位于C:\Windows\System32\drivers\etc下的hosts文件,如果找到对应的IP地址则解析成功。
- 如果(3)中未找到,浏览器首先会找TCP/IP参数中设置的本地DNS服务器,并请求LDNS服务器来解析这个域名,这台服务器一般在你的城市的某个角落,距离你不会很远,并且这台服务器的性能都很好,一般都会缓存域名解析结果,大约80%的域名解析到这里就完成了。否则本地DNS服务器会请求根DNS服务器。
-本地DNS会把请求发至13台根DNS,根DNS服务器会返回所查询域的主域名服务器的地址(.net),本地DNS服务器使用该IP信息联系负责.net域的这台服务器。这台负责.net域的服务器收到请求后,会返回.net域的下一级DNS服务器地址(blog.csdn.net)给本地DNS服务器。以此类推,直至找到。
(2)TCP的三次握手四次挥手
2.1)准备知识
(1)ACK ,TCP协议规定只有ACK=1时有效,也规定连接建立后所有发送的报文的ACK必须为1。
(2)SYN,在连接建立时用来同步序号。当SYN=1而ACK=0时,表明这是一个连接请求报文。对方若同意建立连接,则应在响应报文中使SYN=1和ACK=1,因此SYN置1就表示这是一个连接请求或连接接受报文。
(3)FIN,用来释放一个连接。当 FIN = 1 时,表明此报文段的发送方的数据已经发送完毕,并要求释放连接。
2.2)三次握手
最初两端的TCP进程都处于CLOSED关闭状态,A主动打开连接,而B被动打开连接(由客户端执行connect触发)并开始监听。
(1)第一次握手:由Client发出请求连接数据包: SYN=1 ACK=0 seq=x,TCP规定SYN=1时不能携带数据,但要消耗一个序号,因此声明自己的序号是 seq=x,此时Client进入SYN-SENT(同步已发送)状态,等待Server确认;
(2)第二次握手:Server收到请求报文后,进行回复确认,即 SYN=1 ACK=1 seq=y,ack=x+1,此时Server进入SYN-RCVD(同步收到)状态,操作系统为TCP连接分配TCP缓存和变量;
(3)第三次握手:Client收到Server的确认(SYN+ACK)后,向Server发出确认报文段,即 ACK=1,seq=x+1, ack=y+1,TCP连接已经建立,Client进入ESTABLISHED(已建立连接)状态;
Server收到Client的确认后,也进入ESTABLISHED状态,完成三次握手;此时Client和Server可以开始传输数据。

2.3)四次挥手
数据传输结束后,通信的双方都可释放连接,A和B都处于ESTABLISHED状态。当Client没有数据再需要发送给服务端时,就需要释放客户端的连接,整个过程为:
(1)第一次挥手:当Client发起终止连接请求的时候,会发送一个(FIN为1,seq=u)的没有数据的报文,这时Client停止发送数据(但仍可以接受数据) ,进入FIN_WAIT1(终止等待1)状态,等待Server确认
(2)第二次挥手:Server收到连接释放报文后会给Client一个确认报文段(ACK=1,ack=u+1,seq=v), 进入CLOSE-WAIT(关闭等待)状态
Client收到Server的确认后进入FIN_WAIT2状态,等待Server请求释放连接,Server仍可向Client发送数据。
(3)第三次挥手:Server数据发送完成后,向Client发起请求连接释放报文(FIN=1,ACK=1,seq=w,ack = u+1),Server进入LAST-ACK(最后确认)状态,等待Client确认
(4)第四次挥手:Client收到连接释放报文段后,回复一个确认报文段(ACK=1,seq=u+1,ack=w+1),进入 TIME_WAIT(时间等待) 状态,Server收到后进入CLOSED(连接关闭)状态。经过等待2MSL 时间(最大报文生存时间),Client进入CLOSED状态。

2.4)面试问题
(1)三次握手中为什么Client最后还要发送一次确认呢?可以二次握手吗?=TCP三次握手的主要目的
回答:
为了实现可靠数据传输, TCP 协议的通信双方, 都必须维护一个序列号, 以标识发送出去的数据包中, 哪些是已经被对方收到的。 三次握手的过程即是通信双方相互告知序列号起始值, 并确认对方已经收到了序列号起始值的必经步骤
如果只是两次握手, 至多只有连接发起方的起始序列号能被确认, 另一方选择的序列号则得不到确认
1.1)为什么需要握手?
这里就引出了 TCP 与 UDP 的一个基本区别, TCP 是可靠通信协议, 而 UDP 是不可靠通信协议。
TCP 的可靠性含义: 接收方收到的数据是完整, 有序, 无差错的。
UDP 不可靠性含义: 接收方接收到的数据可能存在部分丢失, 顺序也不一定能保证。
UDP 和 TCP 协议都是基于同样的互联网基础设施, 且都基于 IP 协议实现, 互联网基础设施中对于数据包的发送过程是会发生丢包现象的, 为什么 TCP 就可以实现可靠传输, 而 UDP 不行?
TCP 协议为了实现可靠传输, 通信双方需要判断自己已经发送的数据包是否都被接收方收到, 如果没收到, 就需要重发。 为了实现这个需求, 很自然地就会引出序号(sequence number) 和 确认号(acknowledgement number) 的使用。
发送方在发送数据包(假设大小为 10 byte)时, 同时送上一个序号( 假设为 500),那么接收方收到这个数据包以后, 就可以回复一个确认号(510 = 500 + 10) 告诉发送方 “我已经收到了你的数据包, 你可以发送下一个数据包, 序号从 510 开始” 。
这样发送方就可以知道哪些数据被接收到,哪些数据没被接收到, 需要重发。
1.2)为什么需要三次握手?
正如上文所描述的,为了实现可靠传输,发送方和接收方始终需要同步( SYNchronize )序号。 需要注意的是, 序号并不是从 0 开始的, 而是由发送方随机选择的初始序列号 ( Initial Sequence Number, ISN )开始 。 由于 TCP 是一个双向通信协议, 通信双方都有能力发送信息, 并接收响应。 因此, 通信双方都需要随机产生一个初始的序列号, 并且把这个起始值告诉对方。
1.3)三次握手(理解版)
我们假设A和B是通信的双方。我理解的握手实际上就是通信,发一次信息就是进行一次握手。则对于三次握手:
第一次握手: A给B打电话说,你可以听到我说话吗?
第二次握手: B收到了A的信息,然后对A说: 我可以听得到你说话啊,你能听得到我说话吗?
第三次握手: A收到了B的信息,然后说可以的,我要给你发信息啦!
在三次握手之后,A和B都能确定这么一件事: 我说的话,你能听到; 你说的话,我也能听到。 这样,就可以开始正常通信了。
如果两次,那么B无法确定B的信息A是否能收到,所以如果B先说话,可能后面的A都收不到,会出现问题 。
如果四次,那么就造成了浪费,因为在三次结束之后,就已经可以保证A可以给B发信息,A可以收到B的信息; B可以给A发信息,B可以收到A的信息。
1.4)四次挥手(理解版)
同理,对于四次挥手:
A:“喂,我不说了 (FIN)。”A->FIN_WAIT1
B:“我知道了(ACK)。等下,上一句还没说完。Balabala……(传输数据)”B->CLOSE_WAIT | A->FIN_WAIT2
B:”好了,说完了,我也不说了(FIN)。”B->LAST_ACK
A:”我知道了(ACK)。”A->TIME_WAIT | B->CLOSED
A等待2MSL,保证B收到了消息,否则重说一次”我知道了”,A->CLOSED
这样,通过四次挥手,可以把该说的话都说完,并且A和B都知道自己没话说了,对方也没花说了,然后就挂掉电话(断开链接)了 。
(2)Server端易受到SYN攻击?
服务器端的资源分配是在二次握手时分配的,而客户端的资源是在完成三次握手时分配的,所以服务器容易受到SYN洪泛攻击,SYN攻击就是Client在短时间内伪造大量不存在的IP地址,并向Server不断地发送SYN包,Server则回复确认包,并等待Client确认,由于源地址不存在,因此Server需要不断重发直至超时,这些伪造的SYN包将长时间占用未连接队列,导致正常的SYN请求因为队列满而被丢弃,从而引起网络拥塞甚至系统瘫痪。
防范SYN攻击措施:降低主机的等待时间使主机尽快的释放半连接的占用,短时间受到某IP的重复SYN则丢弃后续请求。
(3)为什么A在TIME-WAIT状态必须等待2MSL的时间?
MSL最长报文段寿命Maximum Segment Lifetime,MSL=2
两个理由:1)保证A发送的最后一个ACK报文段能够到达B。2)防止“防止本次已失效的连接请求报文段出现在新的连接中。
1)这个ACK报文段有可能丢失,使得处于LAST-ACK状态的B收不到对已发送的FIN+ACK报文段的确认,B超时重传FIN+ACK报文段,而A能在2MSL时间内收到这个重传的FIN+ACK报文段,接着A重传一次确认,重新启动2MSL计时器,最后A和B都进入到CLOSED状态,若A在TIME-WAIT状态不等待一段时间,而是发送完ACK报文段后立即释放连接,则无法收到B重传的FIN+ACK报文段,所以不会再发送一次确认报文段,则B无法正常进入到CLOSED状态。
2)A在发送完最后一个ACK报文段后,再经过2MSL,就可以使本连接持续的时间内所产生的所有报文段都从网络中消失,使下一个新的连接中不会出现这种旧的连接请求报文段。
(4)为什么连接的时候是三次握手,关闭的时候却是四次握手?
因为当Server端收到Client端的SYN连接请求报文后,可以直接发送SYN+ACK报文。其中ACK报文是用来应答的,SYN报文是用来同步的。但是关闭连接时,当Server端收到FIN报文时,很可能并不会立即关闭SOCKET(服务端数据未传输完毕),FIN报文仅仅表示Client没有需要发送的数据,但是仍能接受数据,Server的数据未必全部发送出去,需要等待Server的数据发送完毕后发送FIN报文给Client才能表示同意关闭连接。
所以只能先回复一个ACK报文,告诉Client端,“你发的FIN报文我收到了”。只有等到我Server端所有的报文都发送完了,我才能发送FIN报文,因此不能一起发送。故需要四步握手。
建立连接时候ACK和SYN可以放在一个报文里发送给客户端。
连接关闭时ACK和FIN一般分开发送。
(5)如果已经建立了连接,但是客户端突然出现故障了怎么办?
TCP还设有一个保活计时器,显然,客户端如果出现故障,服务器不能一直等下去,白白浪费资源。服务器每收到一次客户端的请求后都会重新复位这个计时器,时间通常是设置为2小时,若两小时还没有收到客户端的任何数据,服务器就会发送一个探测报文段,以后每隔75秒钟发送一次。若一连发送10个探测报文仍然没反应,服务器就认为客户端出了故障,接着就关闭连接。
(6)更多知识点?
5.1通过序列号与确认应答提高可靠性
5.2重发超时的确定提高可靠性
5.3利用窗口控制(滑动窗口控制、窗口控制中重发机制)提高速度
2.5)整体通信流程

(3)建立TCP连接后发起HTTP请求,服务器响应HTTP请求
3.1)网络协议
网络协议是网络上所有设备(网络服务器、计算机及交换机、路由器、防火墙等)之间通信规则的集合,它规定了进行网络中的对等实体数据交换而建立的规则。由于大多数网络采用分层的体系结构,网络各层发送方与接收方(对等实体)应该用相同的网络协议才能相互交换信息。
Internet上的计算机采用TCP/IP协议。
3.2)TCP/IP协议(互联网协议)

(1)TCP/IP四层模型与OSI七层模型
a)OSI七层模型(法定标准)
1、模型架构
在7层模型中,每一层都提供一个特殊的网络功能。
下面3层(物理层、数据链路层、网络层)主要提供数据传输和交换功能,即以节点到节点之间的通信为主(通信子网)
传输层作为上下两部分的桥梁,是整个网络体系结构中最关键的部分;
上面3层(会话层、表示层和应用层)则以提供用户与应用程序之间的信息和数据处理功能为主(资源子网)
2、通信过程(打包+拆包)
3、各层功能及协议
1)应用层
定义:计算机用户及各种应用程序和网络之间的接口
功能:
1.直接向用户提供服务接口
2.完成用户请求的各种服务
协议:文件传输FTP,电子邮件SMTP,万维网HTTP…
2)表示层
定义:处理在两个通信系统中交换信息的表示方式,如编码、数据格式转换和加密解密等
功能:
1.数据格式处理2.数据编码3.压缩和解压缩4.数据的加密和解密
3)会话层
定义:向两个实体的表示层提供建立和使用连接的方法。将不同实体之间的表示层的连接称为会话。因此会话层的任务就是组织和协调两个会话进程之间的通信,并对数据交换进行管理。
功能:
1.会话管理:建立、管理、终止会话
2.出错控制:使用校验点可使会话在通信失效时从校验点/同步点继续恢复通信,实现数据同步。适用于传输大文件
4)传输层(通信子网(数据处理)和资源子网(数据传输)的桥梁)
定义:向用户提供可靠的、端到端((每个进程都用一个端口号唯一标识)的差错和流量控制,保证报文的正确传输。传输单位是报文段或用户数据报
功能:
1.传输连接管理:提供建立、连接和拆除传输连接的功能。传输层在网络层的基础上,提供“面向连接TCP”和“面向无连接UDP”两种服务
2.处理传输差错:(1)差错控制(2)流量控制
协议:TCP\UDP
5)网络层
定义:通过路由算法,为报文或分组通过通信子网选择最适当的路径,从源端传到目的端,为不同的网络设备提供通信服务。该层控制数据链路层与物理层之间的信息转发,建立、维持与终止网络的连接。传输单位是数据报。
一般的,数据链路层是解决统一网络内节点之间的通信,而网络层主要解决不同子网之间的通信。例如路由选择问题。
功能:
1、寻址:数据链路层中使用的物理地址(如MAC地址)仅解决网络内部的寻址问题。在不同子网之间通信时,为了识别和找到网络中的设备,每一子网中的设备都会被分配一 个唯一的地址。由于各个子网使用的物理技术可能不同,因此这个地址应当是逻辑地址(如IP地址)
2、交换:规定不同的交换方式。常见的交换技术有:线路交换技术和存储转发技术,后者包括报文转发技术和分组转发技术。
3、路由算法:当源节点和路由节点之间存在多条路径时,本层可以根据路由算法,通过网络为数据分组选择最佳路径,并将信息从最合适的路径,由发送端传送的接受端。
4、连接服务:与数据链路层的流量控制不同的是,前者控制的是网络相邻节点间的流量,后者控制的是从源节点到目的节点间的流量。其目的在于防止阻塞,并进行差错检测(包括:流量控制、差错控制、拥塞控制)
协议:IP
6)数据链路层
定义:接受来自物理层的位流形式的数据,并封装成帧,传送到上一层;同样,也将来自上一层的数据帧,拆装为位流形式的数据转发到物理层;并且还负责处理接受端发回的确认帧的信息,以便提供可靠的数据传输。
功能:1.成帧(定义帧的开始和结束)2.差错控制(帧错+位错)3.流量控制4.访问(接入)控制
7)物理层
定义:利用传输介质为数据链路层提供屋里连接,实现比特流的透明传输,屏蔽掉具体传输介质与物理设备的差异。使其上面的数据链路层不必考虑网络的具体传输介质是什么
透明传输的意义就是:不管传的是什么,所采用的设备只是起一个通道作用,把要传输的内容完好的传到对方!
b)TCP/IP四层模型(事实标准)
1、模型架构

2、各层功能
a)网络接口层(数据链路层)
(1)作用:实现互连在同一种数据链路(传输介质)结点之间帧传递
(2)传输单位:帧
(3)功能:组帧、差错控制、流量控制和传输管理
b)网络层(网际层)
(1)作用:实现网络中终端节点之间的通信(点对点)/实现多数据链路之间通信
(2)传输单位:数据报
(3)功能:1、封装数据成分组、包,路由选择2、流量控制、拥塞控制&网际互联
(4)协议:
a)Ip协议:提供网络结点之间的报文传送服务
IP协议三大作用模块:
(1) IP寻址:IP地址由网络和主机两部分标识组成。保证相互连接的整个网络中每台主机的IP地址不会重叠。
(2) 路由控制(最终节点为止的转发=实现多数据链路之间通信)
数据链路实现某一区间(一跳:源MAC地址到目标MAC地址之间传输帧的区间)内通信
IP层通过路由控制(经过多跳路由)实现源地址到目标地址之间的通信
多跳路由是指路由器或主机在转发IP数据包时只指定下一个路由器或主机,而不是将到最终目标地址为止的所有通路全都指定出来。因为每一个区间(跳)在在转发IP数据包时会分别指定下一跳的操作,直至包达到最终的目标地址。为了将数据包发给目标主机,所有主机都维护着一张路由控制表(Routing Table)。该表记录IP数据在下一步应该发给哪个路由器。IP包将根据这个路由表在各个数据链路上传输。

(3) IP分包与组包
每种数据链路的最大传输单元(MTU)都不尽相同,因为每个不同类型的数据链路的使用目的不同。使用目的不同,可承载的 MTU 也就不同。
任何一台主机都有必要对 IP 分片进行相应的处理。分片往往在网络上遇到比较大的报文无法一下子发送出去时才会进行处理。
经过分片之后的 IP 数据报在被重组的时候,只能由目标主机进行。路由器虽然做分片但不会进行重组。
b)ARP协议:实现IP地址向物理地址的映射\ RARP协议:实现物理地址向IP地址的映射
c)ICMP协议:探测&报告传输中产生的错误\IGMP协议:管理多播组测成员关系
c)传输层
(1)作用:主要为两台主机上的应用提供端到端的通信,为应用层(会话)提供可靠无误的数据传输服务,为网络层提供源端与目的端的端口信息。
(2)传输单位:报文段(TCP)/用户数据报(UDP)
(3)协议: TCP和UDP

(2)传输层的通信识别
i.端口号及协议
端口号:用来识别同一台计算机中进行通信的不同应用程序(传输层协议)
IP地址:用来识别TCP/IP网络中互连的主机和路由器(网际层协议)
MAC地址:用来识别同一链路中不同计算机(网络接口层协议)
端口(port)可理解为计算机与外界通讯交流的出口。TCP/IP协议的端口是指在Internet上,各个主机间通过TCP/IP协议发送和接受数据报,各个数据报根据其目的主机的ip地址进行互联网络的路由选择,从而将数据报传送到目的主机。由于大多数操作系统都支持多程序(进程)并发运行,那么目的主机应该根据端口号确定把接受到的数据报传送给众多运行的进程中的哪一个。
本地操作系统会给有需求的进程分配协议端口,每个协议端口由一个正整数标识,如80,139,145等等,并且开始监听这个端口,等待数据返回。当目的主机接受到数据报后,根据报文首部的目的端口号,把数据发送到相应端口,而与此端口相对应的那个进程会领取数据并等待下一组数据的到来。可将端口理解为队,操作系统为各个进程分配了不同的队,数据报按照目标端口被推入相应的队中,等待被进程取用。
端口不仅仅用于接受数据报,也用于发送数据报,这样数据报中会有标识源端口,以方便接收方能够顺利回传数据报到这个端口。
可理解为:IP地址是电脑结点的网络物理地址,相当于你家地址;端口是计算机逻辑通讯接口,不同应用程序使用不同的端口,可看做出入房子的门。一个ip地址的端口有65536个,通过端口号(0~65536)进行标识。(比如用于浏览网页服务的80端口,用于FTP服务的21端口等等)
ii.通信识别
通过IP地址(源IP地址、目标IP地址)、协议号、端口号(源端口号、目标端口号)五个元素识别一个通信


d)应用层
(1)作用:负责处理特定的应用进程(主机运行的程序)间通信&交互规则
(2)协议:HTTP协议:提供Internet网浏览服务\DNS协议:负责域名和IP地址的映射\SMTP协议:提供简单电子右键发送服务\POP、IMAP协议:提供邮箱服务器进行远程存取邮件\FTP协议:提供应用级文件传输服务\Telent协议:提供远程登录服务(明文)\ssh协议:提供远程登录服务(加密)
3、TCP/IP协议族
在TCP/TP协议族中,网络层IP提供的是一种不可靠的服务。它只是尽可能快地把分组从源节点送到目的节点,但不提供任何可靠性的保证。Tcp在不可靠的ip层上,提供了一个可靠的运输层,为了提供这种可靠的服务,TCP采用了超时重传、发送和接受端到端的确认分组等机制。

4、通信过程(封装+解封)
• ① 应用程序处理
首先应用程序会进行编码处理,这些编码相当于 OSI 的表示层功能;
编码转化后,邮件不一定马上被发送出去,这种何时建立通信连接何时发送数据的管理功能,相当于 OSI 的会话层功能。
• ② TCP 模块的处理
TCP 根据应用的指示,负责建立连接、发送数据以及断开连接。TCP 提供将应用层发来的数据顺利发送至对端的可靠传输。为了实现这一功能,需要在应用层数据的前端附加一个 TCP 首部。
• ③ IP 模块的处理
IP 将 TCP 传过来的 TCP 首部和 TCP 数据合起来当做自己的数据,并在 TCP 首部的前端加上自己的 IP 首部。IP 包生成后,参考路由控制表决定接受此 IP 包的路由或主机。
• ④ 网络接口(以太网驱动)的处理
从 IP 传过来的 IP 包对于以太网来说就是数据。给这些数据附加上以太网首部并进行发送处理,生成的以太网数据包将通过物理层传输给接收端。
• ⑤ 网络接口(以太网驱动)的处理
主机收到以太网包后,首先从以太网包首部找到 MAC 地址判断是否为发送给自己的包,若不是则丢弃数据。
如果是发送给自己的包,则从以太网包首部中的类型确定数据类型,再传给相应的模块,如 IP、ARP 等。这里的例子则是 IP 。
• ⑥ IP 模块的处理
IP 模块接收到 数据后也做类似的处理。从包首部中判断此 IP 地址是否与自己的 IP 地址匹配,如果匹配则根据首部的协议类型将数据发送给对应的模块,如 TCP、UDP。这里的例子则是 TCP。
另外吗,对于有路由器的情况,接收端地址往往不是自己的地址,此时,需要借助路由控制表,在调查应该送往的主机或路由器之后再进行转发数据。
• ⑦ TCP 模块的处理
在 TCP 模块中,首先会计算一下校验和,判断数据是否被破坏。然后检查是否在按照序号接收数据。最后检查端口号,确定具体的应用程序。数据被完整地接收以后,会传给由端口号识别的应用程序。
• ⑧ 应用程序的处理
接收端应用程序会直接接收发送端发送的数据。通过解析数据,展示相应的内容。
3.3)HTTP协议
一.TCP/IP通信传输流
利用 TCP/IP 协议族进行网络通信时,会通过分层顺序与对方进行通信。
• 首先作为发送端的客户端在应用层(HTTP 协议)发出一个想看某个 Web 页面的 HTTP 请求。
• 接着,为了传输方便,在传输层(TCP 协议)把从应用层处收到的数据(HTTP 请求报文)进行分割,并在各个报文上打上标记序号及端口号后转发给网络层。
• 在网络层(IP 协议),增加作为通信目的地的 MAC 地址后转发给链路层。这样一来,发往网络的通信请求就准备齐全了。
• 接收端的服务器在链路层接收到数据,按序往上层发送,一直到应用层。当传输到应用层,才能算真正接收到由客户端发送过来的 HTTP请求。

五层网络模型
五层网络模型用于理解网络框架

- 物理层:主要作用是定义物理设备之间如何传输数据。
- 数据链路层:在通信的实体之间建立数据链路连接。
- 网络层:为数据在结点之间传输创建逻辑链路。
- 传输层:向用户提供端到端(End-to-End)的服务,传输层向高层屏蔽了下层数据通信的细节,作为Android开发者,需要对这一层的TCP/IP,UDP协议非常了解。
- 应用层:为应用软件提供了很多服务,构建于TCP协议之上,屏蔽网络的传输相关细节。这一层需要了解Http,Ftp等协议。
二.定义
2.1 HTTP协议
HTTP协议(HyperText Transfer Protocol,超文本传输协议)是用于从WWW服务器传输超文本到本地浏览器的传输协议。在Internet上的Web服务器上存放的都是超文本信息,客户机需要通过HTTP协议传输所要访问的超文本信息。
HTTP是一个基于TCP/IP通信协议传递数据(HTML、图片文件,查询结果等)
HTTP是一个属于应用层的面向对象的协议
HTTP协议工作于客户端-服务端(请求-响应 C/S)架构上
HTTP简单快速,客户向服务器请求服务时只需传送请求方法和路径。请求方法常用的有GET、HEAD、POST,每种方法规定了客户与服务器联系的类型不同。由于HTTP协议简单,使HTTP服务器的程序规模小,因而通信速度很快。且HTTP允许传输任意类型的数据对象,正在传输的类型由Content-Type加以标记。
HTTP是一个无连接的协议:无连接的含义是限制每次连接只处理一个请求。服务器处理完客户的请求,并收到客户的应答后,即断开连接。采用这种方式可以节省传输时间。
HTTP是一个无状态的协议:无状态是指协议对于事务处理没有记忆能力。缺少状态意味着如果后续处理需要前面的信息,则它必须重传,这样可能导致每次连接传送的数据量增大。另一方面,在服务器不需要先前信息时它的应答就较快。
2.2 URI与URL
(1)URI:uniform resource identifier,统一资源标识符,用来唯一的标识一个资源。Web上可用的每种资源如HTML文档、图像、视频片段、程序等都是一个来URI来定位的。
URI一般由三部组成:①访问资源的命名机制②存放资源的主机名③资源自身的名称,由路径表示,着重强调于资源。
(2)URL:uniform resource locator,统一资源定位器,它是一种具体的URI,即URL可以用来标识一个资源,而且还指明了如何locate这个资源。
采用URL可以用一种统一的格式来描述各种信息资源,包括文件、服务器的地址和目录等。URL一般由三部组成:①协议(或称为服务方式)②存有该资源的主机IP地址(有时也包括端口号)③主机资源的具体地址。如目录和文件名等
一个URL完整格式:
http://www.aspxfans.com:8080/news/index.asp?boardID=5&ID=24618&page=1#name
- 协议部分:该URL的协议部分为“http:”,这代表网页使用的是HTTP协议。在"HTTP"后面的“//”为分隔符
- 域名部分:该URL的域名部分为“www.aspxfans.com”。也可以使用IP地址作为域名使用
- 端口部分(可省略):跟在域名后面的是端口"8080",域名和端口之间使用“:”作为分隔符。如果省略端口部分,将采用默认端口80
- 虚拟目录部分(可省略):从域名后的第一个“/”开始到最后一个“/”为止,是虚拟目录部分。本例中的虚拟目录是“/news/”
- 文件名部分(可省略):从域名后的最后一个“/”开始到“?”或"#"或结束为止
虚拟目录和文件名部分统称为指定请求资源的URI(WEB上任意可用资源) - 锚部分(可省略):从“#”开始到最后,都是锚部分。本例中的锚部分是“name”
- 参数部分:从“?”开始到“#”为止之间的部分为参数部分,又称搜索部分、查询部分。本例中的参数部分为“boardID=5&ID=24618&page=1”。参数可以允许有多个参数,参数与参数之间用“&”作为分隔符。
2.3 HTTP工作过程
(1)客户端通过网络与Web服务端的HTTP端口(默认80)建立TCP连接(TCP协议)
(2)客户端向服务器发送HTTP请求命令,如:GET/sample/hello.jsp HTTP/1.1
(3)客户端发送请求头信息,之后发送一空白行通知服务器已结束该头信息发送
(4)服务器对客户端的请求进行应答,如:HTTP/1.1 200 OK
(5)服务器返回响应头信息,之后发送一空白行通知客户端已结束该头信息发送
(6)服务器向客户端发送数据,以 Content-Type 响应头信息所描述的格式发送用户所请求的实际数据
(7)服务器关闭TCP连接
如果客户端或者服务器在其头信息加入了这行代码 Connection:keep-alive ,TCP 连接在发送后将仍然保持打开状态,于是,客户端可以继续通过相同的连接发送请求。保持连接节省了为每个请求建立新连接所需的时间,还节约了网络带宽。
三.HTTP协议基础
3.1 通过请求和响应的交换达成通信
http协议规定,请求从客户端开始发出,并由服务端响应请求并返回。Http允许传输任意类型的数据对象。正在传输的类型由Content-Type标记
3.2 HTTP是不保存状态的协议
3.3 使用Cookie的状态管理
HTTP 是一种无状态协议。协议自身不对请求和响应之间的通信状态进行保存。可是随着 Web 的不断发展,我们的很多业务都需要对通信状态进行保存。于是我们引入了 Cookie 技术。
Cookie 技术通过在请求和响应报文中写入 Cookie 信息来控制客户端的状态。Cookie 会根据从服务器端发送的响应报文内的一个叫做 Set-Cookie 的首部字段信息,通知客户端保存Cookie。当下次客户端再往该服务器发送请求时,客户端会自动在请求报文中加入 Cookie 值后发送出去。服务器端发现客户端发送过来的 Cookie 后,会去检查究竟是从哪一个客户端发来的连接请求,然后对比服务器上的记录,最后得到之前的状态信息。
cookie交互流程:
(1)第一次客户端发送请求报文(没有cookie)
GET /reader/ HTTP/1.1
Host: hackr.jp
(2)服务端发送响应报文(生成cookie信息)
HTTP/1.1 200 OK
Date: Thu, 12 Jul 2012 05:45:32 GMT
Server: Apache
< Set-Cookie: sid=1342077140226724; path=/; … >
Content-Type: text/plain; charset=UTF-8
(3)第二次客户端发送请求报文(存在cookie信息)
GET /image/ HTTP/1.1
Host: hackr.jp
Cookie: sid=1342077140226724
(4)请求URI定位互联网上资源
(5)(告知服务器意图的)HTTP方法
(6)(非)持久连接
HTTP1.1采用持久连接:只要任意一端没有明确提出断开连接,则保持 TCP 连接状态。旨在建立一次 TCP 连接后进行多次请求和响应的交互
HTTP1.0采用非持久连接:每个连接只能处理一个请求-响应事务
(7)管线化(并行发送多请求,且不用一个接一个等待响应)
四.HTTP协议报文结构
4.1 HTTP报文
用于 HTTP 协议交互的信息被称为 HTTP 报文。请求端(客户端)的 HTTP 报文叫做请求报文;响应端(服务器端)的叫做响应报文。HTTP 报文本身是由多行(用 CR+LF 作换行符)数据构成的字符串文本
4.2 HTTP报文结构
(4.2.1)请求报文结构

通常一个HTTP请求报文由请求行、请求报头、空行和请求数据4个部分组成。
a)请求行
- Method 用于请求的方法(请求访问服务器类型)一共八种
- Request-URI 请求URI(请求访问的资源对象)是一个统一资源标识符,如:/index.htm
- HTTP-Version HTTP版本号HTTP/1.1
- CRLF表示回车和换行(除了作为结尾的CRLF外,不允许出现单独的CR或LF字符)
GET /index.htm HTTP/1.1
请求方法(Method)是HTTP客户端程序(如浏览器)向服务器发送请求时指明的请求类型。
常见的请求类型为PUT和GET,但HTTP协议共定义了八种请求类型来表明对Request-URI指定的资源的不同操作方式。
HTTP请求方法
| 请求类型 | 说明 |
|---|---|
| OPTIONS | 返回服务器针对特定资源所支持的HTTP请求方法。也可以利用向Web服务器发送’*'的请求来测试服务器的功能性。 |
| HEAD | 向服务器索要与GET请求相一致的响应,只不过响应体将不会被返回。这一方法可以在不必传输整个响应内容的情况下,就可以获取包含在响应消息头中的元信息。 |
| GET | 向特定的资源发出请求。 |
| POST | 向指定资源提交数据进行处理请求(例如提交表单或者上传文件)。数据被包含在请求体中。POST请求可能会导致新的资源的创建和/或已有资源的修改。 |
| PUT | 向指定资源位置上传其最新内容。 |
| DELETE | 请求服务器删除Request-URI所标识的资源。 |
| TRACE | 回显服务器收到的请求,主要用于测试或诊断。 |
| CONNECT | HTTP/1.1协议中预留给能够将连接改为管道方式的代理服务器。 |
POST与GET请求区别

标准答案:
- get在浏览器回退时是无害的,而post会再次请求
- get产生的url地址可以被收藏,而post不会
- get请求会被浏览器主动缓存,而post不会,除非手动设置
- get请求只能进行url编码,而post支持多种编码方式
- get请求参数会被完整保留在浏览历史记录里,而post中的参数不会被保留
- get 请求在url中传送的参数有长度限制,而post没有
- 对参数的数据类型,get只接受ascll字符,而post没有限制
- get比post更安全,因为参数直接暴露在url上,所以不能用来传递敏感信息
- get参数通过url传递,poet放在request body中
b)请求头部
服务端需要的附加信息(报文主体大小、所使用的语言、认证信息等内容)。
在请求行之后会有0个或者多个请求报头,每个请求报头都包含一个名字和一个值,它们之间用“:”分割。请求头部会以一个空行,发送回车符和换行符,通知服务器以下不会有请求头。
具体的请求头见下请求头部,典型的请求头有:
- Host:请求的主机名,允许多个域名同处一个IP地址,即虚拟主机
- User-Agent:发送请求的浏览器类型、操作系统等信息
- Accept:客户端可识别的内容类型列表,用于指定客户端接收那些类型的信息
- Accept-Encoding:客户端可识别的数据编码
- Accept-Language:表示浏览器所支持的语言类型
- Connection:允许客户端和服务器指定与请求/响应连接有关的选项,例如这是为Keep-Alive则表示保持连接。
- Transfer-Encoding:告知接收端为了保证报文的可靠传输,对报文采用了什么编码方式。
c)空行
报文首部与报文主体间空行隔开
d)主体(报文实体)
请求数据
举例
POST http://patientapi.shoujikanbing.com/api/common/getVersion HTTP/1.1 //请求行
Content-Length: 226 //请求报头
Content-Type: application/x-www-form-urlencoded
Host: patientapi.shoujikanbing.com
Connection: Keep-Alive
User-Agent: Mozilla/5.0 (Linux; U; Android 4.4.4; zh-cn; MI NOTE LTE Build/KTU84P) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1
Accept-Encoding: gzip
//不能省略的空格,下面是请求数据
clientversion=2_2.0.0&time=1459069342&appId=android&channel=hjwang&sessionId=0d1cee1f31926ffa8894c64804efa855101d56eb21caf5db5dcb9a4955b7fbc9&token=b191944d680145b5ed97f2f4ccf03058&deviceId=869436020220717&type=2&version=2.0.0
访问地址为:http://patientapi.shoujikanbing.com/api/common/getVersion,请求的方法是POST,用于获取版本信息,
(4.2.2)响应报文结构

a)状态行
- HTTP-Version 服务器HTTP协议版本号HTTP/1.1
- Status-Code 服务器返回的响应状态代码的状态码200
- Reason-Phrase 状态代码的文本描述
状态码
状态代码有三位数字组成,第一个数字定义了响应的类别,共分五种类别:
1xx:指示信息–表示请求已接收,继续处理
2xx:成功–表示请求已被成功接收、理解、接受
3xx:重定向–要完成请求必须进行更进一步的操作
4xx:客户端错误–请求有语法错误或请求无法实现
5xx:服务器端错误–服务器未能实现合法的请求
3.状态消息ok
HTTP/1.1 200 OK
b)响应头部
客户端需要的附加信息(报文主体大小、所使用的语言、认证信息等内容),用于客户端传递自身信息的响应。响应报头见下响应头部,常见的响应报头有:
-
Location:用于重定向接受者到一个新的位置,常用在更换域名的时候
-
Server:包含可服务器用来处理请求的系统信息,与User-Agent请求报头是相对应的
c)空行
报文首部与报文实体用空行隔开
c)主体(报文实体)
响应正文,服务器返回给客户端的文本信息
HTTP/1.1 200 OK
Date: Fri, 22 May 2009 06:07:21 GMT
Content-Type: text/html; charset=UTF-8
<html>
<head></head>
<body>
<!--body goes here-->
</body>
</html>
4.3 消息头部(Header)
请求和响应常见的通用Header

(4.3.1)请求头部
HTTP请求头中比较重要的字段

(4.3.2) 响应Header
响应头中比较重要的字段

如何保存Token呢?比如二次登陆,又或者其它接口需要这个Token才能去访问,那么我们可能需要使用set-cookie字段,以下是set-cookie中参数的含义。

五.Cookie和Session
均是解决HTTP无状态协议的一种记录客户状态的机制。
5.1 什么是Cookie?——客户端的通行证
Cookie意为“甜饼”,是由W3C组织提出,最早由Netscape社区发展的一种机制。目前Cookie已经成为标准,所有的主流浏览器如IE、Netscape、Firefox、Opera等都支持Cookie。
由于HTTP是一种无状态的协议,服务器单从网络连接上无从知道客户身份。怎么办呢?就给客户端们颁发一个通行证吧,每人一个,无论谁访问都必须携带自己通行证。这样服务器就能从通行证上确认客户身份了。这就是Cookie的工作原理。
Cookie实际上是一小段的文本信息。客户端请求服务器,如果服务器需要记录该用户状态,就使用response向客户端浏览器颁发一个Cookie。客户端浏览器会把Cookie保存起来。当浏览器再请求该网站时,浏览器把请求的网址连同该Cookie一同提交给服务器。服务器检查该Cookie,以此来辨认用户状态。服务器还可以根据需要修改Cookie的内容。
如果我们不设置Cookie过期时间,那么这个Cookie将不存放在硬盘上,当浏览器关闭的时候,Cookie就消失了。如果我们设置这个时间为若干天之后,那么这个Cookie会保存在客户端硬盘中,即使浏览器关闭,这个值仍然存在,下次访问相应网站时,同 样会发送到服务器上。
5.2 什么是Session?——服务端的客户档案
Session是另一种记录客户状态的机制,不同的是Cookie保存在客户端浏览器中,而Session保存在服务器上。客户端浏览器访问服务器的时候,服务器把客户端信息以某种方式记录在服务器上。
如果说Cookie机制是通过检查客户身上的“通行证”来确定客户身份的话,那么Session机制就是通过检查服务器上的“客户明细表”来确认客户身份。Session相当于程序在服务器上建立的一份客户档案,客户来访的时候只需要查询客户档案表就可以了。它的工作流程如下:
(1)客户第一次访问时需要为该客户创建Session
(2)在创建Session的同时,服务器会为Session生成一个唯一的Session Id。
(3)在Session创建完成后,就可以调用Session的相关方法往Session中增加内容。
(4)当客户端再次发送请求的时候,会将这个Session Id带上,服务器接收到这个请求之后就会依据Session Id找到对应的Session来确认客户端的身份。
一般情况下,服务器会在一定时间内(默认30分钟)保存这个 Session,过了时间限制,就会销毁这个Session。在销毁之前,程序员可以将用户的一些数据以Key和Value的形式暂时存放在这个 Session中。当然,也有使用数据库将这个Session序列化后保存起来的,这样的好处是没了时间的限制,坏处是随着时间的增加,这个数据 库会急速膨胀,特别是访问量增加的时候。一般还是采取前一种方式,以减轻服务器压力。
5.3 Cookie和Session区别
a.存放的位置不同:
Cookie保存在客户端,而Session保存在服务端。
简单的说,当你登录一个网站的时候,如果web服务器端使用的是session,那么所有的数据都保存在服务器上面,客户端每次请求服务器的时候会发送 当前会话的session_id,服务器根据当前session_id判断相应的用户数据标志,以确定用户是否登录,或具有某种权限。由于数据是存储在服务器 上面,所以你不能伪造,但是如果你能够获取某个登录用户的session_id,用特殊的浏览器伪造该用户的请求也是能够成功的。
如果浏览器使用的是 cookie,那么所有的数据都保存在浏览器端,比如你登录以后,服务器设置了 cookie用户名(username),那么,当你再次请求服务器的时候,浏览器会将username一块发送给服务器,这些变量有一定的特殊标记。服 务器会解释为 cookie变量。所以只要不关闭浏览器,那么 cookie变量便一直是有效的,所以能够保证长时间不掉线。如果你能够截获某个用户的 cookie变量,然后伪造一个数据包发送过去,那么服务器还是认为你是合法的。所以,使用 cookie被攻击的可能性比较大。如果设置了的有效时间,那么它会将 cookie保存在客户端的硬盘上,下次再访问该网站的时候,浏览器先检查有没有 cookie,如果有的话,就读取该 cookie,然后发送给服务器。如果你在机器上面保存了某个论坛 cookie,有效期是一年,如果有人入侵你的机器,将你的 cookie拷走,然后放在他的浏览器的目录下面,那么他登录该网站的时候就是用你的的身份登录的。所以 cookie是可以伪造的。
b.存取的方式不同:
Cookie中只能保存ASCII字符串,Session中可以保存任意类型的数据,甚至Java Bean乃至任何Java类、对象等。
c.安全性的不同:
Cookie存储在客户端,对客户端是可见的,可被客户端窥探、复制、修改。而Session存储在服务器上,不存在敏感信息泄露的风险
Cookies的安全性能一直是倍受争议的。虽然Cookies是保存在本机上的,但是其信息的完全可见性且易于本地编辑性,往往可以引起很多的安全问题。所以Cookies到底该不该用,到底该怎样用,就有了一个需要给定的底线。
典型应用:(1)判断用户是否登陆过网站,以便下次登录时能够直接登录。(2)购物车的处理与设计。
d.有效期上的不同:
Cookie的过期时间可以被设置很长。Session依赖于名为JSESSIONI的Cookie,其过期时间默认为-1,只要关闭了浏览器窗口,该Session就会过期,因此Session不能完成信息永久有效。如果Session的超时时间过长,服务器累计的Session就会越多,越容易导致内存溢出。
e.对服务器造成的压力不同:
每个用户都会产生一个session,如果并发访问的用户过多,就会产生非常多的session,耗费大量的内存。因此,诸如Google、Baidu这样的网站,不太可能运用Session来追踪客户会话。
f.浏览器支持不同:
Cookie运行在浏览器端,若浏览器不支持Cookie,需要运用Session和URL地址重写。
g.跨域支持不同:
Cookie支持跨域访问(设置domain属性实现跨子域),Session不支持跨域访问
Cookies是属于Session对象的一种。但有不同,Cookies不会占服务器资源,是存在客服端内存或者一个cookie的文本文件中;而“Session”则会占用服务器资源。所以,尽量不要使用Session,而使用Cookies。但是我们一般认为cookie是不可靠的,session是可靠地,但是目前很多著名的站点也都以来cookie。有时候为了解决禁用cookie后的页面处理,通常采用url重写技术,调用session中大量有用的方法从session中获取数据后置入页面。
Session是由应用服务器维持的一个服务器端的存储空间,用户在连接服务器时,会由服务器生成一个唯一的SessionID,用该SessionID 为标识符来存取服务器端的Session存储空间。而SessionID这一数据则是保存到客户端,用Cookie保存的,用户提交页面时,会将这一 SessionID提交到服务器端,来存取Session数据。这一过程,是不用开发人员干预的。所以一旦客户端禁用Cookie,那么Session也会失效。
服务器也可以通过URL重写的方式来传递SessionID的值,因此不是完全依赖Cookie。如果客户端Cookie禁用,则服务器可以自动通过重写URL的方式来保存Session的值,并且这个过程对程序员透明。
5.4 Token、Cookie&Session联系
Cookie
cookie 是一个非常具体的东西,指的就是浏览器里面能永久存储的一种数据,仅仅是浏览器实现的一种数据存储功能。
cookie由服务器生成,发送给浏览器,浏览器把cookie以key-value形式保存到某个目录下的文本文件内,下一次请求同一网站时会把该cookie发送给服务器。由于cookie是存在客户端上的,所以浏览器加入了一些限制确保cookie不会被恶意使用,同时不会占据太多磁盘空间,所以每个域的cookie数量是有限的。
Session
session 从字面上讲,就是会话。这个就类似于你和一个人交谈,你怎么知道当前和你交谈的是张三而不是李四呢?对方肯定有某种特征(长相等)表明他就是张三。
session 也是类似的道理,服务器要知道当前发请求给自己的是谁。为了做这种区分,服务器就要给每个客户端分配不同的“身份标识”,然后客户端每次向服务器发请求的时候,都带上这个“身份标识”,服务器就知道这个请求来自于谁了。至于客户端怎么保存这个“身份标识”,可以有很多种方式,对于浏览器客户端,大家都默认采用 cookie 的方式。
服务器使用session把用户的信息临时保存在了服务器上,用户离开网站后session会被销毁。这种用户信息存储方式相对cookie来说更安全,可是session有一个缺陷:如果web服务器做了负载均衡,那么下一个操作请求到了另一台服务器的时候session会丢失。
Token
(1)简介
在Web领域基于Token的身份验证随处可见。在大多数使用Web API的互联网公司中,tokens 是多用户下处理认证的最佳方式。大部分你见到过的API和Web应用都使用tokens。例如Facebook, Twitter, Google+, GitHub等。
具有以下几点特性:
1、无状态、可扩展
2、支持移动设备
3、跨程序调用
4、安全
(2)旧的验证方式——Session:基于服务器验证方式
我们都是知道HTTP协议是无状态的,这种无状态意味着程序需要验证每一次请求,从而辨别客户端的身份。程序需要通过在服务端存储的登录信息来辨别请求的。这种方式一般都是通过存储Session来完成。
随着Web,应用程序,已经移动端的兴起,这种验证的方式逐渐暴露出了问题。尤其是在可扩展性方面。
基于服务器验证方式暴露的一些问题
1.Seesion内存开销
每次认证用户发起请求时,服务器需要去创建一个记录来存储信息。当越来越多的用户发请求时,内存的开销也会不断增加。
2.可扩展性
在服务端的内存中使用Seesion存储登录信息,伴随而来的是可扩展性问题。
3.CORS(跨域资源共享)
当我们需要让数据跨多台移动设备上使用时,跨域资源的共享会是一个让人头疼的问题。在使用Ajax抓取另一个域的资源,就可以会出现禁止请求的情况。
4.CSRF(跨站请求伪造)
用户在访问银行网站时,他们很容易受到跨站请求伪造的攻击,并且能够被利用其访问其他的网站。
在这些问题中,可扩展性是最突出的。因此我们有必要去寻求一种更有行之有效的方法。
(3)基于Token的验证原理
基于Token的身份验证是无状态的,我们不将用户信息存在服务器或Session中。这种概念解决了在服务端存储信息时的许多问题。NoSession意味着你的程序可以根据需要去增减机器,而不用去担心用户是否登录。
基于Token的身份验证的过程如下:
1.用户通过用户名和密码发送请求。
2.程序验证。
3.程序返回一个签名的token 给客户端。
4.客户端储存token,并且每次用于每次发送请求。
5.服务端验证token并返回数据。
每一次请求都需要token。token应该在HTTP的头部发送从而保证了Http请求无状态。我们同样通过设置服务器属性Access-Control-Allow-Origin: ,让服务器能接受到来自所有域的请求。需要主要的是,在ACAO头部标明(designating)时,不得带有像HTTP认证,客户端SSL证书和cookies的证书。
Token实现思路:

1.用户登录校验,校验成功后就返回Token给客户端。
2.客户端收到数据后保存在客户端
3.客户端每次访问API是携带Token到服务器端。
4.服务器端采用filter过滤器校验。校验成功则返回请求数据,校验失败则返回错误码
当我们在程序中认证了信息并取得token之后,我们便能通过这个Token做许多的事情。我们甚至能基于创建一个基于权限的token传给第三方应用程序,这些第三方程序能够获取到我们的数据(当然只有在我们允许的特定的token)
通过使用Token,便可不用保存session id。服务端只需要生成token,然后验证token。本质上是使用CPU计算时间来获取了session的存储空间。
(4)Token优势
1、无状态、可扩展
在客户端存储的Tokens是无状态的,并且能够被扩展。基于这种无状态和不存储Session信息,负载负载均衡器能够将用户信息从一个服务传到其他服务器上。
如果我们将已验证的用户的信息保存在Session中,则每次请求都需要用户向已验证的服务器发送验证信息(称为Session亲和性)。用户量大时,可能会造成一些拥堵。
但是不要着急。使用tokens之后这些问题都迎刃而解,因为tokens自己hold住了用户的验证信息。
2、安全性
请求中发送token而不再是发送cookie能够防止CSRF(跨站请求伪造)。即使在客户端使用cookie存储token,cookie也仅仅是一个存储机制而不是用于认证。不将信息存储在Session中,让我们少了对session操作。
token是有时效的,一段时间之后用户需要重新验证。我们也不一定需要等到token自动失效,token有撤回的操作,通过token revocataion可以使一个特定的token或是一组有相同认证的token无效。
3、可扩展性
Tokens能够创建与其它程序共享权限的程序。例如,能将一个随便的社交帐号和自己的大号(Fackbook或是Twitter)联系起来。当通过服务登录Twitter(我们将这个过程Buffer)时,我们可以将这些Buffer附到Twitter的数据流上(we are allowing Buffer to post to our Twitter stream)。
使用tokens时,可以提供可选的权限给第三方应用程序。当用户想让另一个应用程序访问它们的数据,我们可以通过建立自己的API,得出特殊权限的tokens。
4、多平台跨域
我们提前先来谈论一下CORS(跨域资源共享),对应用程序和服务进行扩展的时候,需要介入各种各种的设备和应用程序。只要用户有一个通过了验证的token,数据和资源就能够在任何域上被请求到。
六.浏览器访问一个url所经历的过程
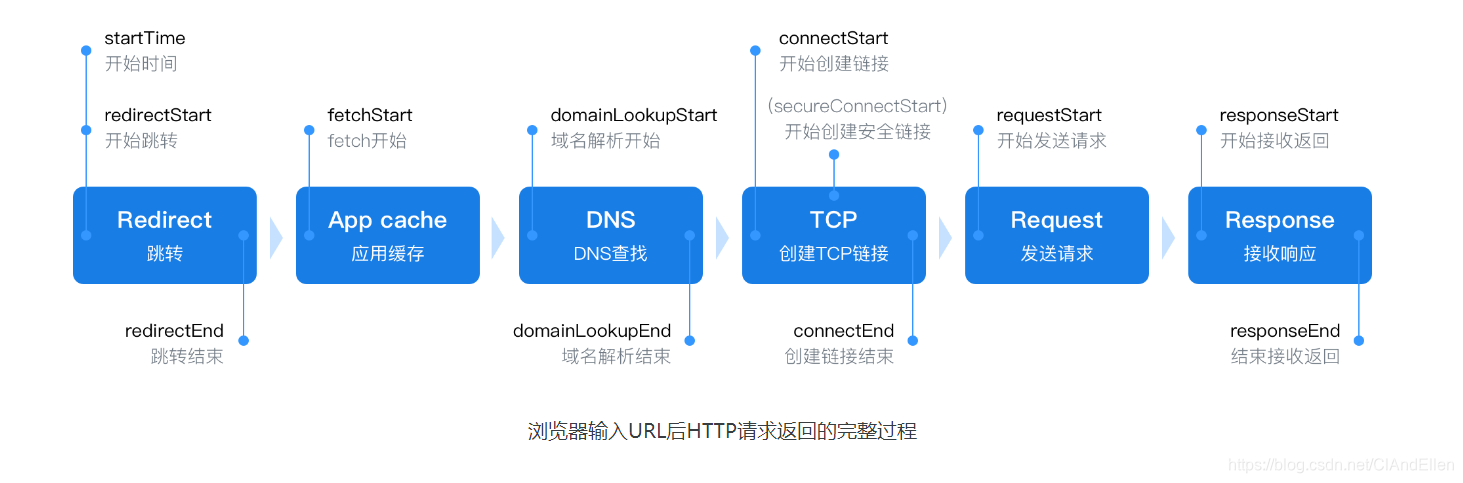
(4)客户端浏览器解析html代码
(5)同时请求html代码中的资源(如js、css、图片等)
(6)最后浏览器对页面进行渲染并呈现给用户
(二)socket
1.定义
即套接字,是通信的基石,是应用层 与 TCP/IP 协议族通信的中间软件抽象层,本质为一个封装了 TCP / IP协议族 的编程接口(API)(不是协议,是一个编程调用接口,通过socket才能实现http协议,属于传输层)网络上的两个程序通过Socket实现一个双向的通信连接从而进行数据交换。
Socket是网络通信过程中端点的抽象表示,包含进行网络通信必须的五种信息:连接使用协议、(本地主机IP地址,本地进程的协议端口)、(远地主机IP地址,远地进程协议端口)。
Socket一般成对出现,一对套接字(其中一个运行在服务端一个运行在客户端):
Socket ={(IP地址1:PORT端口号),(IP地址2:PORT端口号)}

Socket是一个接口,在用户进程与TCP/IP协议之间充当中间人,完成TCP/IP协议的书写,用户只需理解接口即可。
Socket是应用层与TCP/IP协议族通信的中间软件抽象层,它是一组接口。在设计模式中,Socket其实就是一个门面模式,它把复杂的TCP/IP协议族隐藏在Socket接口后面,对用户来说,一组简单的接口就是全部,让Socket去组织数据,以符合指定的协议。
应用层通过传输层进行数据通信时,TCP会遇到同时为多个应用程序进程提供并发服务的问题。多个TCP连接或多个应用程序进程可能需要通过同一个TCP协议端口传输数据。为了区别不同的应用程序进程和连接,许多计算机操作系统为应用程序与TCP/IP协议交互提供了Socket接口。应用层可以和传输层通过Socket接口,区分来自不同应用程序进程或网络连接的通信,实现数据传输的并发服务。
2.客户/服务器模型
2.1原理
Socket是面向客户/服务器模型而设计的,针对客户和服务器程序提供不同的Socket系统调用。客户随机申请一个Socket,系统为之分配一个Socket号;服务器拥有全局公认的Socket,任何客户都可以向它发出连接请求和信息请求。
应用层通过传输层进行数据通信时,TCP会遇到同时为多个应用程序提供并发服务的问题,多个TCP连接多个应用程序进程可能需要通过同一个TCP协议端口传输数据,为了区别不同的应用程序进程和连接,许多计算机操作系统为应用程序与TCP/IP协议交互提供了套接字(socket)接口,应用层可以和传输层通过socket接口区分来自于不同应用进程或网络连接的通信,实现数据传输的并发服务。
即Socket相当于一个封装了TCP/IP协议的API,提供了程序内部与外界通信的端口,并为通信双方提供了数据传输通道。Socket类型为流套接字(streamsocket)和数据报套接字(datagramsocket)。流套接字将TCP作为其端对端协议,提供了一个可信赖的字节流服务。数据报套接字使用UDP协议,提供数据打包发送服务。
2.2连接过程
通信模型

套接字之间的连接过程可以分为三个步骤:服务器监听,客户端请求,连接确认。
- 服务器监听
是服务器端套接字并不定位具体的客户端套接字,而是处于等待连接的状态,实时监控网络状态。 - 客户端请求
是指由客户端的套接字提出连接请求,要连接的目标是服务器端的套接字。为此,客户端的套接字必须首先描述它要连接的服务器的套接字,指出服务器端套接字的地址和端口号,然后就向服务器端套接字提出连接请求。 - 连接确认
是指当服务器端套接字监听到或者说接收到客户端套接字的连接请求,它就响应客户端套接字的请求,建立一个新的线程,把服务器端套接字的描述发给客户端,一旦客户端确认了此描述,连接就建立好了。而服务器端套接字继续处于监听状态,继续接收其他客户端套接字的连接请求。

3.Socket与Http区别
(1)定义
Socket是套接字,对TCP/IP协议的封装。对端(IP地址和端口)的抽象表示。
HTTP协议是通信协议,是利用TCP在Web服务器和浏览器之间数据传输的协议。
Socket和HTTP协议本质上就不同。SOCKET本质对TCP/IP的封装,从而提供给程序员做网络通信的接口(即端口通信)。可理解为HTTP是一辆轿车模型框架,提供了所有封装和数据传递的形式;Socket是发动机,提供了网络通信的能力。
(2)功能
Socket:属于传输层,因为 TCP / IP协议属于传输层,解决的是数据如何在网络中传输的问题。
HTTP协议:属于 应用层,解决的是如何包装数据。
(3)工作方式
Http
采用 请求—响应 方式。
即建立网络连接后,当 客户端 向 服务器 发送请求后,服务器端才能向客户端返回数据。
可理解为:是客户端有需要才进行通信。
Socket
采用 服务器主动发送数据 的方式。
即建立网络连接后,通信双方即可开始发送数据内容,直到双方连接断开。即服务器可主动发送消息给客户端,实现信息的主动推送;而不需要由客户端向服务器发送请求。
可理解为:是服务器端有需要才进行通信。
因此Socket链接相对来说比较方便。但缺点是,客户端到服务器之间的通信往往需要穿越多个中间节点,例如路由器、网关、防火墙等,大部分防火墙默认会关闭长时间处于非活跃状态的连接而导致 Socket 连接断连,因此需要通过轮询告诉网络,该连接处于活跃状态。
使用场景为:
服务器端主动向客户端推送数据,保持客户端与服务器数据的实时与同步
4.实现
4.1 基于TCP协议的网络通信
1. 使用ServerSocket创建TCP服务端
Java中能接受其他通信实体连接请求的类是ServerSocket,ServerSocket对象用于监听来自客户端拿到Socket连接,如果没有连接,它将一直处于等待状态。
ServerSocket ss =new ServerSocket(30000);
while(true){
Socket s = ss.accept();
……
}
使用步骤:
- 创建ServerSocket对象,绑定监听的端口;
- 调用accept()方法监听客户端的请求;
- 连接建立后,通过输入流InputStream读取接收到的数据;
- 通过输出流OutputStream向客户端发送响应信息;
- 调用close()方法关闭相关资源。
public class SocketServer {
public static void main(String[] args) throws IOException {
//1.创建一个服务器端Socket,即ServerSocket,指定绑定的端口,并监听此端口
ServerSocket serverSocket = new ServerSocket(12345);
InetAddress address = InetAddress.getLocalHost();
String ip = address.getHostAddress();
Socket socket = null;
//2.调用accept()等待客户端连接
System.out.println("~~~服务端已就绪,等待客户端接入~,服务端ip地址: " + ip);
socket = serverSocket.accept();
//3.连接后获取输入流,读取客户端信息
InputStream is=null;
InputStreamReader isr=null;
BufferedReader br=null;
OutputStream os=null;
PrintWriter pw=null;
is = socket.getInputStream(); //获取输入流
isr = new InputStreamReader(is,"UTF-8");
br = new BufferedReader(isr);
String info = null;
while((info=br.readLine())!=null){
//循环读取客户端的信息
System.out.println("客户端发送过来的信息" + info);
}
socket.shutdownInput();//关闭输入流
socket.close();
}
}
2.使用Socket创建TCP客户端
构造器中指定远程主机时既可使用InetAddress来指定,也可直接使用String对象来指定,但程序通常使用String对象来指定远程IP地址。
Socket s = new Socket("192.168.1.88",30000);
使用步骤:
- 创建Socket对象,指明需要连接的服务器的IP地址和端口号;
- 连接建立后,通过输出流OutputStream向服务器发送请求信息;
- 通过输入流InputStream获取服务器响应的信息;
- 调用close()方法关闭套接字。
public class MainActivity extends AppCompatActivity implements View.OnClickListener {
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
Button btn_accept = (Button) findViewById(R.id.btn_accept);
btn_accept.setOnClickListener(this);
}
@Override
public void onClick(View v) {
new Thread() {
@Override
public void run() {
try {
acceptServer();
} catch (IOException e) {
e.printStackTrace();
}
}
}.start();
}
private void acceptServer() throws IOException {
//1.创建客户端Socket,指定服务器地址和端口
Socket socket = new Socket("172.16.2.54", 12345);
//2.获取输出流,向服务器端发送信息
OutputStream os = socket.getOutputStream();//字节输出流
PrintWriter pw = new PrintWriter(os);//将输出流包装为打印流
//获取客户端的IP地址
InetAddress address = InetAddress.getLocalHost();
String ip = address.getHostAddress();
pw.write("客户端:~" + ip + "~ 接入服务器!!");
pw.flush();
socket.shutdownOutput();//关闭输出流
socket.close();
}}
}}
4.2 基于UDP协议的网络通信
UDP以数据报作为数据的传输载体,在进行传输时首先要把传输的数据定义成数据报(Datagram),在数据报中指明数据要到达的Socket(主机IP地址和端口号),然后再将数据以数据报的形式发送出去。
1. 使用DatagramSocket创建TCP服务端
使用步骤:
- 创建DatagramSocket对象,指定端口号;
- 创建DatagramPacket对象,用于接收客户端发送的数据;
- 调用DatagramSocket的receiver()方法接收信息;
- 读取数据。
- 调用DatagramSocket的close()方法关闭资源。
public class UPDServer {
public static void main(String[] args) throws IOException {
/*
* 接收客户端发送的数据
*/
// 1.创建服务器端DatagramSocket,指定端口
DatagramSocket socket = new DatagramSocket(12345);
// 2.创建数据报,用于接收客户端发送的数据
byte[] data = new byte[1024];// 创建字节数组,指定接收的数据包的大小
DatagramPacket packet = new DatagramPacket(data, data.length);
// 3.接收客户端发送的数据
System.out.println("****服务器端已经启动,等待客户端发送数据");
socket.receive(packet);// 此方法在接收到数据报之前会一直阻塞
// 4.读取数据
String info = new String(data, 0, packet.getLength());
System.out.println("我是服务器,客户端说:" + info);
/*
* 向客户端响应数据
*/
// 1.定义客户端的地址、端口号、数据
InetAddress address = packet.getAddress();
int port = packet.getPort();
byte[] data2 = "欢迎您!".getBytes();
// 2.创建数据报,包含响应的数据信息
DatagramPacket packet2 = new DatagramPacket(data2, data2.length, address, port);
// 3.响应客户端
socket.send(packet2);
// 4.关闭资源
socket.close();
}
}
2.使用DatagramSocket创建TCP客户端
使用步骤:
- 创建InetAddress对象等,定义要发送的信息;
- 创建DatagramPacket对象,包含将要发送的信息;
- 创建DatagramSocket对象;
- 调用DatagramSocket对象的send()方法发送数据。
- 调用DatagramSocket对象的close()方法关闭资源。
public class UDPClient {
public static void main(String[] args) throws IOException {
/*
* 向服务器端发送数据
*/
// 1.定义服务器的地址、端口号、数据
InetAddress address = InetAddress.getByName("localhost");
int port = 8800;
byte[] data = "用户名:admin;密码:123".getBytes();
// 2.创建数据报,包含发送的数据信息
DatagramPacket packet = new DatagramPacket(data, data.length, address, port);
// 3.创建DatagramSocket对象
DatagramSocket socket = new DatagramSocket();
// 4.向服务器端发送数据报
socket.send(packet);
/*
* 接收服务器端响应的数据
*/
// 1.创建数据报,用于接收服务器端响应的数据
byte[] data2 = new byte[1024];
DatagramPacket packet2 = new DatagramPacket(data2, data2.length);
// 2.接收服务器响应的数据
socket.receive(packet2);
// 3.读取数据
String reply = new String(data2, 0, packet2.getLength());
System.out.println("我是客户端,服务器说:" + reply);
// 4.关闭资源
socket.close();
}
}
(三)websocket
1.定义
WebSocket protocol 是HTML5一种新的协议。它借鉴了socket这种思想,为web应用程序客户端和服务端之间(注意是客户端服务端)提供了一种全双工通信机制(full-duplex)。同时,它又是一种新的应用层协议。一开始的握手需要借助HTTP请求完成。
URL格式为
ws://echo.websocket.org/?encoding=text HTTP/1.1
可以看到除了前面的协议名和http不同之外,它的表示地址就是传统的url地址。
websocket是基于浏览器端的web技术,肯定不能脱离HTTP而单独存在。websocket建立连接时一开始的握手需要借助HTTP请求来完成。具体来讲:
- 客户端创建一个websocket实例,并绑定一个需要连接到的服务器地址
- 客户端连接到服务端时,会向服务端发送一个HTTP报文
报文中有一个upgrade首部,用于告诉服务端需要将通信协议切换到websocket - 服务端将通信协议切换到websocket协议,并发送给客户端一个HTTP响应报文,状态码为101,表示同意客户端协议转换请求。
以上过程称为websocket协议握手(websocket handshake),均是利用HTTP通信完成的。经过握手后,客户端与服务端就建立了websocket连接,可以开始数据传输,并且以后通信都走websocket协议。
2.原理
WebSocket同HTTP一样也是应用层的协议,但是它是一种双向通信协议,是建立在TCP之上的。连接过程需要进行握手:
- 浏览器、服务器建立TCP连接,三次握手。这是通信的基础,传输控制层,若失败后续都不执行。
- TCP连接成功后,浏览器通过HTTP协议向服务器传送WebSocket支持的版本号等信息。(开始前的HTTP握手)
- 服务器收到客户端的握手请求后,同样采用HTTP协议回馈数据。
- 当收到了连接成功的消息后,通过TCP通道进行传输通信。
websocket握手需要借助于HTTP协议,建立连接后通信过程使用websocket协议。同时需要了解的是,该websocket连接还是基于我们刚才发起http连接的那个TCP连接。一旦建立连接之后,我们就可以进行数据传输了,websocket提供两种数据传输:文本数据和二进制数据。
基于以上分析,我们可以看到,websocket能够提供低延迟,高性能的客户端与服务端的双向数据通信。它颠覆了之前web开发的请求处理响应模式,并且提供了一种真正意义上的客户端请求,服务器推送数据的模式,特别适合实时数据交互应用开发。
3.websocket与HTTP
WebSocket 是 HTML5 一种新的协议。它实现了浏览器与服务器全双工通信,能更好的节省服务器资源和带宽并达到实时通讯,它建立在 TCP 之上,同 HTTP 一样通过 TCP 来传输数据,但与HTTP协议也有不同:
相同点
- 都是一样基于TCP的,都是可靠性传输协议。
- 都是应用层协议。
不同点
- 双向通信
WebSocket是双向通信协议,模拟Socket协议,可以双向发送或接受信息。在建立连接后,WebSocket 服务器和 Browser/Client Agent 都能主动的向对方发送或接收数据。HTTP是单向的。是一种请求-响应协议,需要客户端发出请求,服务端进行响应。 - 三次握手
WebSocket是需要握手进行建立连接的。WebSocket在建立握手时,数据是通过HTTP传输的。但是建立之后,在真正传输时候是不需要HTTP协议的。 - 持久连接
相对于传统 HTTP 每次请求-应答都需要客户端与服务端建立连接的模式,WebSocket 是类似 Socket 的 TCP 长连接的通讯模式,一旦 WebSocket 连接建立后,后续数据都以帧序列的形式传输。在客户端断开 WebSocket 连接或 Server 端断掉连接前,不需要客户端和服务端重新发起连接请求。在海量并发及客户端与服务器交互负载流量大的情况下,极大的节省了网络带宽资源的消耗,有明显的性能优势,且客户端发送和接受消息是在同一个持久连接上发起,实时性优势明显。

4.websocket与socket
相同点
- 均是基于TCP的长连接模式
- 均是一种双向通信协议
不同点
Socket不是协议,是位于应用层和传输层之间封装TCP/IP协议的接口,两台主机通信,必须通过socket建立TCP连接
Websocket是应用层协议
5.实现
客户端
var ws = new WebSocket(“ws://echo.websocket.org”); //实例化新的WebSocket客户端对象,WebSocket客户端对象会自动解析并识别为WebSocket请求,从而连接服务端端口,执行双方握手过程
ws.onopen = function(){ws.send(“Test!”); };
ws.onmessage = function(evt){console.log(evt.data);ws.close();};
ws.onclose = function(evt){console.log(“WebSocketClosed!”);};
ws.onerror = function(evt){console.log(“WebSocketError!”);};
服务端
6.应用
即时通讯,替代轮询
网站上的即时通讯是很常见的,比如网页的QQ,聊天系统等。按照以往的技术能力通常是采用轮询、Comet技术解决。
HTTP协议是非持久化的,单向的网络协议,在建立连接后只允许浏览器向服务器发出请求后,服务器才能返回相应的数据。当需要即时通讯时,通过轮询在特定的时间间隔(如1秒),由浏览器向服务器发送Request请求,然后将最新的数据返回给浏览器。这样的方法最明显的缺点就是需要不断的发送请求,而且通常HTTP request的Header是非常长的,为了传输一个很小的数据 需要付出巨大的代价,是很不合算的,占用了很多的宽带。
缺点:会导致过多不必要的请求,浪费流量和服务器资源,每一次请求、应答,都浪费了一定流量在相同的头部信息上
然而WebSocket的出现可以弥补这一缺点。在WebSocket中,只需要服务器和浏览器通过HTTP协议进行一个握手的动作,然后单独建立一条TCP的通信通道进行数据的传送。
(四)HTTPS协议
一.HTTP传输数据的问题
超文本传输协议HTTP协议被用于在web浏览器和网站服务器之间传递信息。HTTP协议以明文方式发送内容,不提供任何方式的数据加密,如果攻击者截取了web浏览器和网站服务器之间的传输报文,就可以直接读懂其中的信息,因此HTTP协议不适合传输一些敏感信息,比如信用卡号,密码等。
为了解决HTTP协议的这一缺陷,需要使用使用另一种协议,安全套接字层超文本传输协议HTTPS。HTTPS在HTTP的基础上加入SSL(Secure Sockets Layer 安全套接字层)协议,SSL依靠证书来验证服务器的身份,为浏览器和服务器之间的通信加密。
传输的是明文(username=chy
password=123),隐私数据容易容易泄露——解决方案:对传输数据进行加密——Https:将数据加密后再传输(5$#^&*)
二.HTTPS简介
HTTPS(Hyper Text Transfer Protocol over Secure Socket Layer)是以安全为目标的Http通道,可理解为HTTP的加强版。实现原理是再HTTP下加入SSL层,SSL负责加密和解密数据(HTTPS = HTTP + SSL)
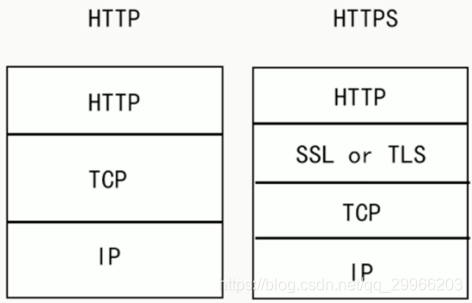
HTTPS的特点在于:
- 内容加密:采用混合加密技术,中间者无法直接查看明文内容。
混合加密:结合对称加密和非对称加密技术。客户端使用对称密钥对传输数据进行加密, 然后用非对称密钥对对称密钥进行加密。所以网络上传输的数据是被对称加密过的密文和用非对称加密后的密钥。因此即使被黑客截取。由于没有私钥,所以无法获取加密明文的密钥,也无法获取明文数据。 - 验证身份:确保浏览器访问的网站是经过CA验证的可信任网站。
- 数据完整性:防止传输的内容被中间人冒充或篡改。
三.HTTPS和HTTP区别
- 定义上:
HTTP:超文本传输协议,是一个基于请求与响应,无状态的,应用层的协议,常基于TCP/IP协议传输数据,互联网上应用最为广泛的一种网络协议,所有的WWW文件都必须遵守这个标准。设计HTTP的初衷是为了提供一种发布和接收HTML页面的方法。
HTTPS:HTTPS是身披SSL外壳的HTTP。HTTPS是一种通过计算机网络进行安全通信的传输协议,经由HTTP进行通信,利用SSL/TLS建立全信道,加密数据包。HTTPS使用的主要目的是提供对网站服务器的身份认证,同时保护交换数据的隐私与完整性。 - HTTPS协议需要CA申请证书(交费)(权威机构颁发证书——安全|自己生成的证书——不安全)
- HTTP是超文本传输协议,信息是明文传输。HTTPS协议是SSL+HTTP协议构建的可进行加密传输、身份认证的安全的网络协议
- HTTP和HTTPS使用不同连接方式,端口也不同(http:80,https:443)
四.SSL/TLS
4.1 简介
SSL(Secure Sockets Layer 安全套接层),及其继任者传输层安全(Transport Layer Security,TLS)是为网络通信提供安全及数据完整性的一种安全协议。TLS与SSL在传输层对网络连接进行加密。
SSL协议位于TCP/IP协议与各种应用层协议之间,为数据通讯提供安全支持。SSL协议可分为两层:
- SSL记录协议(SSL Record Protocol):它建立在可靠的传输协议(如TCP)之上,为高层协议提供数据封装、压缩、加密等基本功能的支持。 (通过对称加密实现,用来保证数据传输过程中完整性和私密性)
- SSL握手协议(SSL Handshake Protocol):它建立在SSL记录协议之上,用于在实际的数据传输开始前,通讯双方进行身份认证、协商加密算法、交换加密密钥等。(通过非对称加密实现,负责握手过程的身份认证)
4.2 SSL加密算法
(1)对称加密
原理:加密算法是公开的,靠的是密钥来加密数据。使用一个密钥加密,使用相同的密钥才能解密
常用算法:DES,3DES,AES
优点:计算量小,加密和解密速度较快,适合加密较大数据
缺点:在传输加密数据之前需要传递密钥,密钥传输容易泄露;一个用户需要对应一个密钥,服务器管理密钥比较麻烦
(2)非对称加密
原理:加密算法是公开的,有一个公钥,一个私钥(公钥和私钥不是随机的,由加密算法生成);公钥加密只能私钥解密,私钥加密只能公钥解密,加密解密需要不同密钥
常用算法:RSA
优点:可以传输公钥(服务器—>客户端)和公钥加密的数据(客户端->服务器),数据传输安全
缺点:计算量大,加密和解密速度慢
4.3SSL证书种类
(1)域名型https证书(DVSSL),信任等级一般,只需网站的真实性便可办法证书保护网站;
(2)企业型https证书(OVSSL),信任等级强,需验证企业身份,审核严格,安全性高;
(3)增强型https证书(EVSSL),信任等级最高,一般用于银行证券等金融机构,审核严格,安全性最高,可激活绿色网址栏
PS:自己生成的证书——访问https网站:显示证书无效,存在危险(不受信任的证书)
五.Https的工作原理
5.1原理
发送方将对称加密的密钥通过非对称加密的公钥进行加密,接收方使用私钥进行解密得到对称加密的密钥,再通过对称加密交换数据。Https协议通过对称加密(传输快,传输交换数据)和非对称加密(安全,传输密钥)结合处理实现的。
5.2通信过程
- 浏览器发起往服务器的443端口发起请求"https://www.baidu.com"(及之后的对称加密算法)。
- 服务器中有公钥和私钥,收到请求,会将公钥和服务器身份认证信息通过SSL数字证书返回给浏览器;
服务端,都有公钥、私钥和证书:
私钥用来加密发出去的信息;
公钥用来解密收到的信息;
证书用来证明身份,一般证书包含公钥以及身份认证信息;这里的证书可以是向某个权威机构申请的,也可以是自制的。区别在于自己办法的证书需要客户端验证通过,才可以继续访问;而使用受信任的公司申请的证书则不会弹出提示页面。
-
浏览器进入数字证书认证环节,这一部分是浏览器内置的TLS完成的:
(1)首先浏览器会从内置的证书列表中索引,找到服务器下发证书对应的机构,如果没有找到,此时就会警告用户该证书不是由权威机构颁发,是不可信任的(浏览器显示https警告)。如果查到了对应的机构,则取出该机构颁发的公钥。
(2)用机构的证书公钥解密得到证书的内容和证书签名,内容包括网站的网址、网站的公钥、证书的有效期等。浏览器会先验证证书签名的合法性。签名通过后,浏览器验证证书记录的网址是否和当前网址是一致的,不一致会警告用户。如果网址一致会检查证书有效期,证书过期了也会警告用户。这些都通过认证时,浏览器就可以安全使用证书中的网站公钥了。
(3)浏览器生成一个随机数R,并使用网站公钥对R进行加密。(R就是之后数据传输的对称密钥) -
浏览器将加密的R传送给服务器。
-
服务器用自己的私钥解密得到R。
-
服务器以R为密钥使用了对称加密算法加密网页内容并传输给浏览器。
-
浏览器以R为密钥使用对应的对称解密算法获取网页内容。
总结
前5步其实就是HTTPS的握手过程,这个过程主要是认证服务端证书(内置的公钥)的合法性。
因为非对称加密计算量较大,整个通信过程只会用到一次非对称加密算法(主要是用来保护传输客户端生成的用于对称加密的随机数私钥)。后续内容的加解密都是通过一开始约定好的对称加密算法进行的。
握手过程采用了一次非对称加密,对密钥加密。使得浏览器与服务器双方知道传输数据过程对称加密算法的规则(对称密钥)。
数据传输过程采用多次对称加密,对传输数据加密。浏览器和服务器用握手过程获得的对称加密规则获取传输数据。

5.3优缺点
优点
- 使用HTTPS协议可认证用户和服务器,确保数据发送到正确的客户机和服务器
- HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,要比HTTP协议安全,防止数据在传输过程中被窃取,确保数据的完整性
- HTTPS是现行架构下最安全的解决方案,虽然不是绝对安全,但是它大幅度增加了中间人攻击的成本
缺点
- 相同网络环境下,HTTPS协议会使页面的加载时间延长50%,增加10%~20%耗电,此外,HTTPS协议还会影响缓存,增加数据开销和功耗(增加了加密解密过程)
- HTTPS协议的安全是有范围的,在黑客攻击、拒绝服务攻击、服务器劫持方面几乎起不到什么作用
- 最关键的,SSL证书信用链体系并不安全,特别是再某些国家可以控制CA根证书的情况下,中间人攻击一样可行
- 成本方面:
(1)SSL的专业证书需要购买,功能越强大,费用越高
(2)SSL证书通常需要绑定固定IP,为服务器增加固定IP会增加一定费用
(3)HTTPS连接服务器端资源占用高,相同负载下会增加带宽和投入成本
六.HTTPS的现状
2017年1月发布的Chrome 56浏览器开始把收集密码或信用卡数据的HTTP页面标记为“不安全”,若用户使用2017年10月推出的Chrome 62,带有输入数据的HTTP页面和所有以无痕模式浏览的HTTP页面都会被标记为“不安全”,此外,苹果公司强制所有iOS App在2017年1月1日前使用HTTPS加密。可见HTTPS正在逐渐取代HTTP协议。
(五)网络数据解析
(5.1)Json数据解析
JSON(JavaScript Object Notation, JS 对象简谱) 是一种轻量级的数据交换格式。它基于ECMAScript (欧洲计算机协会制定的js规范)的一个子集,采用完全独立于编程语言的文本格式来存储和表示数据。简洁和清晰的层次结构使得 JSON 成为理想的数据交换语言。 易于人阅读和编写,同时也易于机器解析和生成,并有效地提升网络传输效率。
(5.1.1)原生JSONObject
1、JSONObject&JSONArray表示形式
JSONObject的数据是用 { } 来表示的
{
"id":"1",
"courseID":"化学",
"title":"滴定实验",
"content":"下周二实验楼201必须完成"
}
JSONArray的数据是由JSONObject构成的数组,用 [ { } , { } , …… , { } ] 来表示的
[
{
"id":"1",
"courseID":"数学",
"title":"一加一等于几"
},
{
"id":"2",
"courseID":"语文",
"title":"请背诵全文"
}
]
2、JSONObject&JSONArray 与 JSON格式字符串 转换
反序列化:JSONObject&JSONArray -> JSON格式字符串
String jsonStr = jsonObject.toString();
String jsonStr = jsonArray.toString();
序列化:JSONObject&JSONArray <- JSON格式字符串
/*json字符串最外层是大括号时:*/
JSONObject jsonObject = new JSONObject(jsonStr);
/*json字符串最外层是方括号时:*/
JSONArray jsonArray = new JSONArray(jsonStr);
3、JSONObject获取数据
(1)从JSONArray中获得JSONObject
/*JSONObject 获取jsonArray :需要数组的字段名*/
JSONArray jsonArray = jsonObject.getJSONArray("children");
/*jsonArray获取JSONObject : 需要遍历数组*/
for (int i = 0; i < jsonArray.length(); i++) {
JSONObject jsonObject = jsonArray.getJSONObject(i);
}
(2)从JSONObject中获取具体数据
int mid= jsonObject.getInt("id");
String mcourse=jsonObject.getString("courseID");
(5.1.2)FastJson
阿里巴巴FastJson是一个Json处理工具包,包括“序列化”和“反序列化”两部分,它可以解析JSON格式的字符串,支持将Java Bean序列化为JSON字符串,也可以从JSON字符串反序列化到JavaBean。它具备如下特征:
(1)速度最快,测试表明,fastjson具有极快的性能,超越任其他的Java Json parser。包括自称最快的JackJson;
(2)功能强大,完全支持Java Bean、集合、Map、日期、Enum,支持范型,支持自省;无依赖,能够直接运行在Java SE 5.0以上版本;支持Android;开源 (Apache 2.0)
1、引入依赖
import com.alibaba.fastjson.JSON;
2、构造实体类
package com.json.bean;
public class Person {
private String id ;
private String name;
private int age ;
public Person(){
}
public Person(String id,String name,int age){
this.id=id;
this.name=name;
this.age=age;
}
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "解析json字符串后获取的person对象:id的值是" +
id + ", name的值是" + name + ", age的值是" + age + "";
}
}
3、JSON格式字符串与javaBean之间的转换
javabean转化成json字符串
//javabean转化为json字符串
Person person = new Person("1","fastjson",1);
String jsonString = JSON.toJSONString(person);
//javaarray转化为json字符串
Person person1 = new Person("1","fastjson1",1);
Person person2 = new Person("2","fastjson2",2);
List<Person> persons = new ArrayList<Person>();
persons.add(person1);
persons.add(person2);
String jsonString = JSON.toJSONString(persons);
json字符串转换成javabean
//将json字符串转化成javabean对象
person =JSON.parseObject(jsonString,Person.class);
//将json字符串转换为javaarray
List<Person> persons2 = JSON.parseArray(jsonString,Person.class);
//输出解析后的person对象,也可以通过调试模式查看persons2的结构
System.out.println("person1对象:"+persons2.get(0).toString());
System.out.println("person2对象:"+persons2.get(1).toString());
(5.1.3)Gson
Gson工具类GsonUtil
public class GsonUtil {
private static Gson gson = null;
static {
if (gson == null) {
gson = new Gson();
}
}
private GsonUtil() {
}
/**
* 将object对象转成json字符串
*
* @param object
* @return
*/
public static String GsonString(Object object) {
String gsonString = null;
if (gson != null) {
gsonString = gson.toJson(object);
}
return gsonString;
}
/**
* 将gsonString转成泛型bean
*
* @param gsonString
* @param cls
* @return
*/
public static <T> T GsonToBean(String gsonString, Class<T> cls) {
T t = null;
if (gson != null) {
t = gson.fromJson(gsonString, cls);
}
return t;
}
/**
* 转成list
* 泛型在编译期类型被擦除导致报错
*
* @param gsonString
* @param cls
* @return
*/
public static <T> List<T> GsonToList(String gsonString, Class<T> cls) {
List<T> list = null;
if (gson != null) {
list = gson.fromJson(gsonString, new TypeToken<List<T>>() {
}.getType());
}
return list;
}
/**
* 转成list
* 解决泛型问题
*
* @param json
* @param cls
* @param <T>
* @return
*/
public static <T> List<T> jsonToList(String json, Class<T> cls) {
Gson gson = new Gson();
List<T> list = new ArrayList<T>();
JsonArray array = new JsonParser().parse(json).getAsJsonArray();
for (final JsonElement elem : array) {
list.add(gson.fromJson(elem, cls));
}
return list;
}
/**
* 转成list中有map的
*
* @param gsonString
* @return
*/
public static <T> List<Map<String, T>> GsonToListMaps(String gsonString) {
List<Map<String, T>> list = null;
if (gson != null) {
list = gson.fromJson(gsonString,
new TypeToken<List<Map<String, T>>>() {
}.getType());
}
return list;
}
/**
* 转成map的
*
* @param gsonString
* @return
*/
public static <T> Map<String, T> GsonToMaps(String gsonString) {
Map<String, T> map = null;
if (gson != null) {
map = gson.fromJson(gsonString, new TypeToken<Map<String, T>>() {
}.getType());
}
return map;
}
}
(5.1.4)JSONObject、FastJson与Gson三者对比
把Java对象JSON序列化,Jackson速度最快,在测试中比Gson快接近50%,FastJSON和Gson速度接近。
把JSON反序列化成Java对象,FastJSON、Jackson速度接近,Gson速度稍慢,不过差距很小。
(5.2)XML数据解析
(5.2.1)Dom
DOM(Document Object Model) 是一种用于XML文档的对象模型,可用于直接访问XML文档的各个部分。它是一次性全部将内容加载在内存中,生成一个树状结构,它没有涉及回调和复杂的状态管理。 缺点是加载大文档时效率低下。
public class DomPersonService {
/**
* @param inStream
* @return
* @throws Exception
*/
public static List<Person> getPersons(InputStream inStream)
throws Exception {
List<Person> persons = new ArrayList<Person>();
//文档的解析
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
Document document = builder.parse(inStream);
//操作对象树
Element root = document.getDocumentElement();//返回文档根元素
NodeList personNodes = root.getElementsByTagName("person");
for (int i = 0; i < personNodes.getLength(); i++) {
Element personElement = (Element) personNodes.item(i);
int id = new Integer(personElement.getAttribute("id"));
Person person = new Person();
person.setId(id);
NodeList childNodes = personElement.getChildNodes();
for (int y = 0; y < childNodes.getLength(); y++) {
if (childNodes.item(y).getNodeType() == Node.ELEMENT_NODE) {
if ("name".equals(childNodes.item(y).getNodeName())) {
String name = childNodes.item(y).getFirstChild()
.getNodeValue();
person.setName(name);
}
else if ("age".equals(childNodes.item(y).getNodeName())) {
String age = childNodes.item(y).getFirstChild()
.getNodeValue();
person.setAge(new Short(age));
}
}
}
persons.add(person);
}
inStream.close();
return persons;
}
}
使用DOM解析XML文件
public void testDOMGetPersons() throws Throwable {
InputStream inStream = this.getClass().getClassLoader()
.getResourceAsStream("person.xml");
List<Person> persons = DomPersonService.getPersons(inStream);
for (Person person : persons) {
Log.i(TAG, person.toString());
}
}
(5.2.2)Sax
SAX(Simple API for XML) 使用流式处理的方式,它并不记录所读内容的相关信息。它是一种以事件为驱动的XML API,解析速度快,占用内存少。使用回调函数来实现。 缺点是不能倒退。
public class SAXForHandler extends DefaultHandler {
/**
* -----------------SAX解析XML----------------------
*/
private static final String TAG = "SAXForHandler";
private List<Person> persons;
private String perTag;// 通过此变量,记录前一个标签的名称
Person person;// 记录当前Person
public List<Person> getPersons() {
return persons;
}
@Override
public void characters(char[] ch, int start, int length)
throws SAXException {
String data = new String(ch, start, length).trim();
if ( ! "".equals(data.trim())) {
Log.i(TAG, "content: " + data.trim());
}
if ("name".equals(perTag)) {
person.setName(data);
}
else if ("age".equals(perTag)) {
person.setAge(new Short(data));
}
super.characters(ch, start, length);
}
@Override
public void endDocument() throws SAXException {
Log.i(TAG, "***endDocument()***");
super.endDocument();
}
@Override
public void endElement(String uri, String localName, String qName)
throws SAXException {
Log.i(TAG, qName + "***endElement()***");
if ("person".equals(localName)) {
persons.add(person);
person = null;
}
perTag = null;
super.endElement(uri, localName, qName);
}
@Override
public void startDocument() throws SAXException {
persons = new ArrayList<Person>();
Log.i(TAG, "***startDocument()***");
super.startDocument();
}
@Override
public void startElement(String uri, String localName, String qName,
Attributes attributes) throws SAXException {//localName标签名,fullName带命名空间的标签名,attribute存放该标签所有属性
if ("person".equals(localName)) {
for (int i = 0; i < attributes.getLength(); i++) {
Log.i(TAG, "attributeName:" + attributes.getLocalName(i)
+ "_attribute_Value:" + attributes.getValue(i));
person = new Person();
person.setId(Integer.valueOf(attributes.getValue(i)));
// person.setId(Integer.parseInt(attributes.getValue(i)));
}
}
perTag = localName;
Log.i(TAG, qName + "***startElement()***");
super.startElement(uri, localName, qName, attributes);
}
}
使用SAX解析XML文件
/**
* *****************************使用SAX解析XML文件*******************
* 输入流是指向程序中读入数据
* @throws Throwable
*/
public void testSAXGetPersons() throws Throwable {
InputStream inputStream = this.getClass().getClassLoader()
.getResourceAsStream("person.xml");
SAXForHandler saxForHandler = new SAXForHandler();
//用工厂模式解析XML
SAXParserFactory spf = SAXParserFactory.newInstance();
SAXParser saxParser = spf.newSAXParser();
saxParser.parse(inputStream, saxForHandler);
// 第二种方式解析XML
// XMLReader xmlReader = saxParser.getXMLReader();
// xmlReader.setContentHandler(handler);
// xmlReader.parse(new InputSource(inputStream));
List<Person> persons = saxForHandler.getPersons();
inputStream.close();
for (Person person : persons) {
Log.i(TAG, person.toString());
}
}
(5.2.3)Pull
Pull内置于Android系统中。也是官方解析布局文件所使用的方式。Pull与SAX有点类似,都提供了类似的事件,如开始元素和结束元素。不同的是,SAX的事件驱动是回调相应方法,需要提供回调的方法,而后在SAX内部自动调用相应的方法。而Pull解析器并没有强制要求提供触发的方法。因为他触发的事件不是一个方法,而是一个数字。它使用方便,效率高。
public class PullPersonService {
/**
* ------------------------使用PULL解析XML-----------------------
* @param inStream
* @return
* @throws Exception
*/
public static List<Person> getPersons(InputStream inStream)
throws Exception {
Person person = null;
List<Person> persons = null;
XmlPullParser pullParser = Xml.newPullParser();
pullParser.setInput(inStream, "UTF-8");
int event = pullParser.getEventType();// 触发第一个事件
while (event != XmlPullParser.END_DOCUMENT) {
switch (event) {
case XmlPullParser.START_DOCUMENT:
persons = new ArrayList<Person>();
break;
case XmlPullParser.START_TAG:
if ("person".equals(pullParser.getName())) {
int id = new Integer(pullParser.getAttributeValue(0));
person = new Person();
person.setId(id);
}
if (person != null) {
if ("name".equals(pullParser.getName())) {
person.setName(pullParser.nextText());
}
if ("age".equals(pullParser.getName())) {
person.setAge(new Short(pullParser.nextText()));
}
}
break;
case XmlPullParser.END_TAG:
if ("person".equals(pullParser.getName())) {
persons.add(person);
person = null;
}
break;
}
event = pullParser.next();
}
return persons;
}
}
PULL解析XML文件
public void testPullGetPersons() throws Throwable {
InputStream inStream = this.getClass().getClassLoader()
.getResourceAsStream("person.xml");
List<Person> persons = PullPersonService.getPersons(inStream);
for (Person person : persons) {
Log.i(TAG, person.toString());
}
}
(5.2.4)Dom、Sax与Pull三者对比
- 内存占用:SAX、Pull比DOM要好;
- 编程方式:SAX采用事件驱动,在相应事件触发的时候,会调用用户编好的方法,也即每解析一类XML,就要编写一个新的适合该类XML的处理类。DOM是W3C的规范,Pull简洁。
- 访问与修改:SAX采用流式解析,DOM随机访问。
- 访问方式:SAX,Pull解析的方式是同步的,DOM逐字逐句。
(5.3)Json数据 & XML数据比较
(5.3.1)代码比较
- Json
{
"name": "中国",
"province": [{
"name": "黑龙江",
"cities": {
"city": ["哈尔滨", "大庆"]
}
}, {
"name": "广东",
"cities": {
"city": ["广州", "深圳", "珠海"]
}
}]
}
- XML
<?xml version="1.0" encoding="utf-8"?>
<country>
<name>中国</name>
<province>
<name>黑龙江</name>
<cities>
<city>哈尔滨</city>
<city>大庆</city>
</cities>
</province>
<province>
<name>广东</name>
<cities>
<city>广州</city>
<city>深圳</city>
<city>珠海</city>
</cities>
</province>
</country>
(5.3.2)特点比较
| JSON | XML | 结论 | |
|---|---|---|---|
| 可读性 | 简易语法 | 规范的标签形式 | 平分秋色,不同场景下各有优势 |
| 可扩展性 | 可扩展 | 可扩展 | 因为 JSON是JS标准的子集合,所以它在JS处理扩展时更优优势,可存储JS复合对象 |
| 编码难度 | 可编码 | 支持Dom4j、Dom、SAX等 | XML编码方式有很多,但是JSON也可以很快的编码,并且在代码量(对结构解析)上要较XML少 |
| 解码难度 | 平 | 平 | 各不相同,解码要看被解码的数据格式和编码规则,JSON和XML都遵循自己的解码方式 |
(5.3.3)Json优势
- JSON数据清晰
- JSON有很多工具类支持它的转换
- JSON在所有主流浏览器有很好的支持
- JSON在传输时数据量更小
- JSON在JS中有天然的语言优势(因为它是标准的子集合)
