最近再学崔庆才大神的《python3:网络爬虫开发实战》,已经爬取到了相关信息,但是下载出错。
出现预设的下载报错[scrapy.core.scraper] WARNING: Dropped: IMAGE Downloaded Failed
但是用的pycharm的terminal 没有出现报错,scrapy运行正常。
而在学习中对其中许多参数不了解,不知道为什么import,又有什么用。于是去找了scrapy的文档,地址:https://docs.scrapy.org/en/latest/。
其中最不理解的就是这个 image_paths = [x[‘path’] for ok, x in results if ok],列表推导式比较长且存在不认识的参数 x[‘path’] 和results。
这两个参数在Downloading and processing files and images中,地址:https://docs.scrapy.org/en/latest/topics/media-pipeline.html。
原文翻译为:item_completed()保证接收到的元组列表保留get_media_requests()方法返回的请求的相同顺序 。这是该results参数的典型值:[(True,{‘checksum’:‘2b00042f7481c7b056c4b410d28f33cf’, ‘path’:‘full/0a79c461a4062ac383dc4fade7bc09f1384a3910.jpg’,
‘url’:‘http://www.example.com/files/product1.pdf’}),
(False,Failure(…))]
也就是说 def get_media_requests(self, item, info):下载的内容会返回一个results,这是一个dict,path就是其中的一个键。
在了解之后,就开始查找失败的原因。terminal下载失败时我的网络正常:[scrapy.core.engine] DEBUG: Crawled (200) <GET https://images.so.com/zjl?ch=beauty&listtype=new&tl=625&temp=1&sn=30; def parse(self, response):的数据也正常:{‘id’: ‘a31883048378f8e3157d8fbeb2ff6d33’,
‘thumb’: ‘https://p3.ssl.qhimgs1.com/sdr/200_200_/t01d6f87e3e9cd758ad.jpg’,
‘title’: ‘小清新戴眼镜可爱美女旅途写真’,
‘url’: ‘https://p3.ssl.qhimgs1.com/t01d6f87e3e9cd758ad.jpg’}
因而问题可能存在于pipelines.py中,而依据上面文档中的解释,进行了测试
1、get_media_request():

返回结果正常,说明可以正常下载,不会存在防盗链之类的问题。
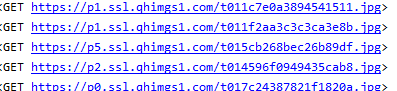
2、测试 def item_completed(self, results, item, info):
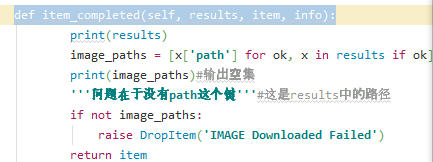
结果输出[],一开始以为是没有path这个键,但从scrapy文档中发现并不是这样的,这个是scrapy内置输出的一个字典内容。

但是在print(results)中出现[(False, <twisted.python.failure.Failure builtins.AttributeError: ‘str’ object has no attribute ‘spilt’>)]
,这个报错不是很明白,但是仔细阅读后发现问题在spilt,拼写出错,因为split()而不是spilt().
最后下载成功
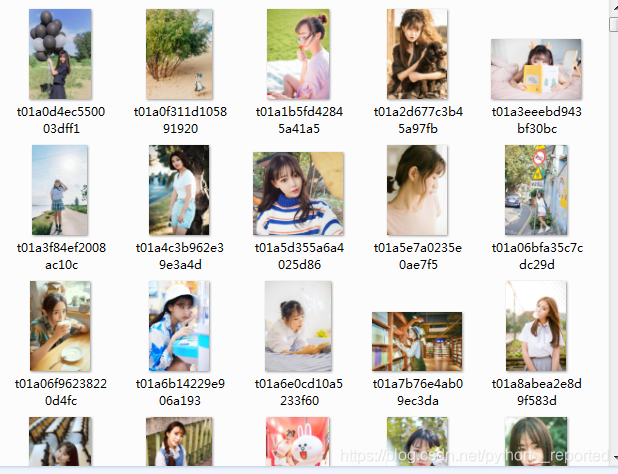
这其中要感谢博主KimihaSukiDa的《scrapy框架下载图片失败原因(记自己踩的坑)》给我的思路:“下载失败的原因可能是:1、url不正确。2、储存路径不正确”
参见:
[1]https://blog.csdn.net/weixin_40841243/article/details/94482506?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522158527347119725247616619%2522%252C%2522scm%2522%253A%252220140713.130056874…%2522%257D&request_id=158527347119725247616619&biz_id=0&utm_source=distribute.pc_search_result.none-task
