在上一篇《图解:进程与线程——实用主义理解》中我以为进程与线程创建好了就可以自动分成多个进程与线程,即一个函数被自动分成几个进程或者线程然后执行。
但是,后来发现似乎并不是这样的。在简单函数试验时发现速度确实提高了,可以参见之前的这篇文章《图解:进程与线程——实用主义理解》,但是我在一个爬虫项目试图运用多线程时发现与我没有用多线程时似乎速度没有快多少。——这是在提取一个网页中的跳转的url



但是如上图所示,虽然每页的url提取非常快,但是仍然是一页一页的按序提取的,我需要提取的url一共一百万个,每页12个链接,需要提取10万个网页需要花费很长的时间。
于是我想是不是我哪里理解错了。
之后看到一篇博文《Python学习笔记 concurrent.futures 模块》探讨另一个多线程包 ——"concurrent”

这里突然出现了线程池:
又是多方寻找测试才明白一个submit
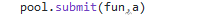
或者Thread
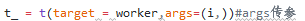
只是一个线程,多个线程需要自己提交多个函数或者一个函数进行执行环节的拆分(对于上面这个爬虫项目就要拆分页数);创建多个Thread对象
按照拆分页数进行拆分后提交多次后


或许划分为五个还是太慢了,但是电脑内存上升的也很快!!!!!
