人脸标记检测:ICCV2019论文解析
Learning Robust Facial Landmark Detection
via Hierarchical Structured Ensemble

论文链接:
http://openaccess.thecvf.com/content_ICCV_2019/papers/Zou_Learning_Robust_Facial_Landmark_Detection_via_Hierarchical_Structured_Ensemble_ICCV_2019_paper.pdf
摘要
基于热图回归的模型极大地促进了面部地标检测的进展。然而,缺乏结构约束总是会产生不准确的热图,导致地标检测性能差。虽然人们提出了层次结构建模方法来解决这一问题,但它们都严重依赖于人工设计的树结构。由于缺少或不准确地预测地标,设计的层次结构可能会被完全破坏。据本文所知,在深度学习的背景下,以前没有研究过如何通过发现面部标志点的内在关系,自动为其建立适当的结构模型。
本文提出了一种新的分层结构地标集成(HSLE)模型,将其作为结构约束,用于学习鲁棒的人脸地标检测。与现有的人工设计结构的方法不同,本文提出的HSLE模型是通过发现最稳健的模式来自动构建的,因此HSLE能够同时健壮地描述局部和整体的地标结构。本文提出的HSLE可以很容易地插入到任何现有的面部地标检测基线中,以进一步提高性能。大量的实验结果表明,本文的方法在获得最新性能方面显著优于基线。
- Introduction
面部地标检测,称为面部定位,是许多面部分析任务的关键,包括面部识别[35,64,30],面部建模[17,24]。由于面部形状、头部姿势、光线条件和背景遮挡的变化很大,面部地标检测仍然具有挑战性。最近,基于热图回归的模型[49,57,36,52,51]推动了面部地标检测的进展。基于热图回归的模型之所以成功,是因为利用似然热图来表示地标位置的概率分布。但是,如果出现异常情况(例如遮挡、照明、噪音或不受约束的姿势/表情变化),则会产生不准确的热图(例如带有偏差或干扰的热图),等)由于可靠性低或不充分的识别,导致面部标志点(图1.Row1)定位不准确甚至不正确。为了解决这一问题,基于heatmap回归模型的结构建模被提出,并在人脸标志点检测中取得了很好的效果,因为利用人脸标志点的结构约束可以修正和正确地重建上述不准确/模糊的标志点。然而,现有的整体结构建模对地标预测质量敏感,由于无约束的异常情况导致的地标缺失或检测不准确,所建结构可能完全失效,如图1.Row2所示。
因此,通过同时对标志点的整体和局部结构进行建模,人脸标志点的定位变得更加稳健。利用层次结构模型进行有效的局部结构建模,而不是用一个整体的密集连通图同时对既不具有资源效率也不具有推理能力的人脸标志的整体结构和局部结构进行建模。 在人脸标记检测领域,很少有文献[20,9,52]提出基于人工设计的树状层次结构的人脸标记层次化建模方法。
然而,由于人工设计的树状结构会因为标记的检测失败而被完全破坏,因此它们的性能对人脸标记的检测不具有鲁棒性。
因此,在这项工作中,本文试图回答一个重要的问题:本文能否自动构建一个更适合学习鲁棒性面部地标检测的层次结构?
本文提出了一种新的层次结构地标集合(HSLE)模型,用以层次化地表示人脸地标的整体和局部结构。
在这项工作中,本文首先将地标聚类成不同的组,每个组共享相同的地标,这使得本文的模型具有层次结构。HSLE本质上是一个有向图,它是为每个群自动构造的。 HSLE中的每个节点表示预先定义的地标,并且从连接节点之间传递的信息得到的关系表示为HSLE中的边。为了构造HSLE最可靠的结构,利用有限覆盖集模型发现节点间最稳健的连接。
由于从HSLE传播的结构约束,通过以端到端的方式与HSLE联合训练,基线面部地标检测器变得更加健壮(图1.Row3)。
在这项工作中,本文的贡献有四个方面:
(1)提出了一种新的层次结构地标集合(HSLE)模型,用于描述人脸地标的整体和局部结构。本文提出的HSLE可以很容易地插入到任何现有的面部地标检测基线中,以进一步提高性能。
(2)由于HSLE传播的结构约束,通过端到端的方式与HSLE联合训练,使得基线人脸地标检测变得更加健壮。
(3)与上述基于人工结构设计的方法相比,本文的自动学习层次结构通过发现最稳健的模式从数据中自动挖掘出结构约束,因此对故障标志点检测更可靠、更稳健。 (4) 本文的方法大大优于基准,以获得最新的结果。在300W数据集[40,41,42]和AFLW数据集[34]上进行了大量实验,验证了模型的有效性。

2. Related Works
自1992年以来,在面部地标检测领域取得了许多令人瞩目的成就。由于只有具有足够辨别力的地标(如眼角、鼠标角和鼻尖等)才能可靠地定位,结构约束通常被以前的经典艺术品采用,包括活动形状模型[13、10、37、12]、活动外观模型[11、18、43、23、46、31]、受约束的局部模型[14,29、44、2、28、45]和级联回归模型[6、58、65、39、7、8、25、47、66、22、55、54、56、67、19、51]。
这些方法大多从初始形状(如平均面部形状[3])开始,或者使用点分布模型(如[5,60])来实施这种约束。近年来,深卷积神经网络(CNN)在人脸标志点检测方面取得了新的进展[48、61、62、63、59、55、50、33]。特别是,最先进的面部地标检测性能主要是通过使用热图回归模型来实现的[49、57、36、52、51]。Merget等人[36]引入了一个完全卷积的局部全局上下文网络,并将一个简单的基于PCA的二维形状模型定义为一个整体结构约束。吴等人[52]提出了一种以边界线为几何结构的边界感知人脸对齐模型。 很少有文献[20,9]关注整体和局部结构的层次建模。
Ghiasiet al.[20]提出了一种用于面部标记定位的分层可变形零件模型,该模型由一个手动设计的零件树组成。每个部分都连接到星型拓扑中的一组地标。如果树的根节点丢失,它们的模型将失败。Chu等人[9]提出了一个结构化的特征学习框架来解释人体姿势估计中身体关节之间的相关性。文[52]中还采用了双向树结构模型,该模型通过手工指定在相邻关节之间传递信息。
由于人脸标志点的数目远大于姿态估计中使用的关节数目,因此,人工设计的树结构也不能很好地解决这么多人脸标志点之间的信息传递问题。与文献[20]和[9]不同,本文提出的HSLE模型是通过发现最稳健的模式来自动构造的。因此,本文的HSLE能够同时有力地描述局部和整体地标结构。据本文所知,本文的工作是第一个为地标自动建模的工作,通过发现它们的内在关系。
- Our Method
如导言所述,同时对整体和局部结构进行建模将有助于更有力地定位面部标志点。提出了一种分层结构地标集成(HSLE)模型,将其作为结构约束,用于学习鲁棒的人脸地标检测。拟议方法的框架如图2所示。整个模型可以以端到端的方式共同学习。提出的HSLE模型作为人脸标志点的层次结构约束。

在这一部分中,本文在回顾传统的覆盖集模型的基础上,初步提出了本文的层次结构地标集成(HSLE)模型。然后提出了将地标聚类为集合的策略。最后,本文介绍了构建HSLE模型的模式发现方法以及一些训练问题。
然而,不恰当的地标结构会使结构约束失效。例如,有两个不合适的地标组合,如图3(a)和图3(b)所示。在图3(a)中,如果节点“C”丢失,其他节点将不会收到任何信息。在图3(b)中,如果节点“C”丢失,其他节点将被误导,因为其他节点只能从一个节点接收信息。Dai等人[15]提出了一个检测器集合的覆盖集的概念。(n,t,m)覆盖集是由若干m元子结构组成的n元集。对于任何t单元,必须存在至少一个m单元子结构,其单元都属于这些t单元。也就是说,如果错过的节点不超过(n-t)个,则至少存在一个子结构。图3(c)和图3(d)示出了两个不同的(5,4,3)覆盖集,图3(e)示出了一个完全连通图,它也是(5,3,3)覆盖集。
节点和边
如上所述,HSLE本质上是一个有向图模型。HSLE中的每个节点都表示预先确定的地标。由连接节点之间传递的信息表示的关系在HSLE中表示为边。在[9]之后,本文实现了作为卷积核的信息传递。这个有限的覆盖集模型强制要求每个地标至少包含在一个子结构中。图3(f)示出了一个构建的地标集合的示例。
相对关系稳定的地标(一对地标之间的关系应在一定程度上对头部姿态或面部表情保持不变)最好聚类成同一个集合。地标聚类操作的目标函数可以写成:

为了解决这个问题,本文首先随机选取一幅训练图像。图像中的地标被聚集成 利用K-means的不同群体[32]。如果一个地标的差异小于一个阈值,它可能同时被分为不同的组。地标和聚类中心之间的距离将由V2重新确定,以满足等式3中定义的约束条件。为当前聚类结果计算E。本文多次运行这个过程,选择E最小的聚类结果作为构建HSLE的最终聚类结果。
由于求解方程2是一个组合优化问题,因此将采用由[15]启发的随机方法来确定HSLE的最稳健结构。将每个集合的有限覆盖集初始化为全连通图。在每个步骤中,如果满足等式2中定义的约束条件,本文将从任意有限覆盖集中随机移除一条边。在包含更多边的集合中,具有更高误差度量的地标之间的边具有更大的移除概率。此过程结束,直到获得最小有限覆盖集的集合。这个集合中的所有元素一起构成了HSLE的结构。为了实现最稳健的结构,类似于地标聚类策略,本文将整个过程运行多次。选择误差测度最小的最小有限覆盖集集合来构造HSLE结构。结构构造过程总结为算法1,f(·)是计算剩余边数的函数。




4. Experiment
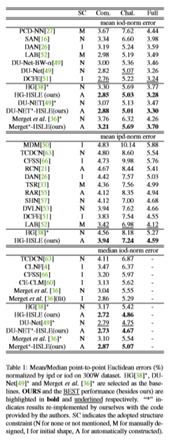
为了验证模型的有效性,本文在两个数据集上对模型进行了评估。300W[40,41,42]:训练用3148幅图像,测试用689幅图像。测试数据集分为三个子集:公共子集(554个图像)、挑战子集(135个图像)和完整子集(689个图像)。每幅图像都有68个地标。AFLWFull[67]:训练用20k图像和测试用4386图像。每幅图像都有19个地标。为了在准确度和效率之间进行权衡,使用17个集合在300W数据集上分层描述68个面部标志点的结构,使用4/5/8/11/14集合分别在AFLW数据集上分层描述19个面部标志点的结构。每个系综由13个3元子结构组成的(6,4,3)有限覆盖集组成。
在300W[40,41,42]数据集上,本文将端到端训练模型与最新方法进行了比较。本文报告了由瞳孔间距离(ipd范数)和眼间距离(iod范数)标准化的平均点对点欧氏误差,以及由眼间距离(iod范数)标准化的中值点对点欧氏误差。为了与所有其他方法进行比较,本文展示了文献中发表的原始结果。结果见表1。 实验结果表明,本文的方法持续且显著地优于3种不同的最新基线,从而获得与最新方法相当的结果。也就是说,由于HSLE传播的结构约束,通过与HSLE联合训练,基线面部地标检测器变得更加健壮。这一现象表明,通过学习层次结构约束,人脸地标检测具有更强的鲁棒性。在300W数据集上,本文将本文提出的模型的累积误差分布曲线与8Stacked Hourglass[38]基线模型进行对比,如图4所示。
由于不同的面部标志具有不同的辨别力,因此应该为更具辨别力的标志分配更高的权重。为此,本文报告了300W数据集上的加权平均iod范数误差。本文根据68个面部标志的区别将其分为三类(图5)。a类包含具有最低区分的地标(例如轮廓),c类包含具有最高区分的地标(例如眼角),b类包含所有其他剩余的地标。本文根据地标的类别赋予它们不同的权重。结果见表2。第一列中的数字表示相关权重。从表2中可以了解到,通过本文的HSLE模型,具有更高辨别力的面部标志可以实现更多的改进,这使得本文提出的想法对于大多数应用来说更有意义。
300W数据集的一些定性结果如图6所示。不同颜色边界的图像分别来自一个基线和所提出的HSLE模型。无约束条件下的图像结果表明,由于HSLE模型传播的结构约束,采用端到端的方式与HSLE联合训练,使得基线人脸地标检测器具有更强的鲁棒性。


- Discussion
为了更清楚地研究HSLE模型对整体性能的影响,本文进一步对AFLW数据集进行了补充实验[34]。为了进行评估,使用了AFLW完整方案[67]。如表3所示,本文的方法可以实现一致的改进。
不同基线的实验
本文在表1中报告了3个不同的最新基线的结果。实验结果验证了该方法的有效性。本文进一步以堆叠的沙漏为基线,但堆叠不同数量的沙漏模组进行实验。表3的第1/3行和第4/6行显示,所提出的HSLE模型始终优于分别堆叠4/8个沙漏模块的基线,这也验证了所提出的显式应用结构约束优于通过堆叠多个沙漏隐式合并它。
与手工设计的结构约束方法的比较
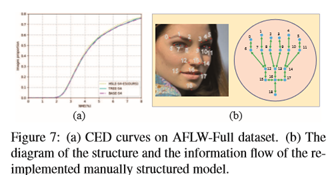
手动结构约束的瓶颈在于难以应用于大量地标,因此手动设计的结构约束(如[9])不适合300W数据集(每幅图像注释68个地标)。对于每个图像有19个标记的AFLW全数据集,本文重新实现了一个手动设计的19个节点的双向树结构模型(图7(b))参见[9]。表3和图7(a)中的第2/3行和第5/6行显示,本文提出的模型始终优于手动设计的结构约束,这表明用本文的方法自动学习的层次结构约束不仅更适合于大量的地标,但也比手工设计的约束更加健壮。
不同设置的HSLE
在AFLW数据集上,本文使用不同的x-(n,t,m)设置(4/5/8/11/14-(6,4,3))对本文的模型进行了评估,结果表明本文的模型总是改善了基线。模型的复杂度随着x,n的增加和t的减小而增加,参数大小的不断增加并不能进一步改善性能,如表3第7∼11行所示。此外,为了描述68个地标的结构约束,当应用17–(6,4,3)设置时,参数的数目增加了35802,有221个子结构用于传递信息。如果应用完全连接的图或所谓的1-(68,3,3)设置,参数的数量将增加8118792,并且将是50116子结构,用于传递信息。为了在准确性和效率之间进行权衡,本文主要报告了19个地标的5-(6,4,3)设置和68个地标的17-(6,4,3)设置的结果。

6. Conclusion
本文提出了一种用于学习鲁棒性人脸地标检测的层次结构地标集成(HSLE)模型。由于HSLE传播的结构约束,通过端到端的方式与HSLE联合训练,使得基线面部地标检测器具有更强的鲁棒性。通过大量的实验验证了该方法的有效性,表明通过学习层次结构约束,人脸标志点检测可以更加稳健。与基线模型相比,该模型在Intel i7-9700K(3.60GHz×8)CPU和Nvidia GeForce GTX 1080Ti(11GB)GPU上的运行时间增加了约36ms。
