一、Serverless架构模式简介
一. 简介
Serverless是一种无服务的架构,类似aws lambda。Serverless与跟传统架构不同,由开发者实现的服务端逻辑运行在无状态的计算容器中,它是由事件触发,短暂的(可能只存在于一次请求过程中),完全被第三方管理。另一种思考方式,这是函数服务‘Functions as a Service / FaaS’。
其实Serverless和FaaS是在不同维度概括述这个新架构的特性。Serverless从部署运维形态角度,强调其无需关注底层执行环境的优势;而FaaS则是描述是它以服务化的方式提供函数式计算能力。
在这个领域 AWS Lambda是先行者,随后其他厂商相继推出了自己的函数服务,比如Google Cloud Functions和阿里云函数服务等等。
二. 架构分析
Serverless应用通常基于的Event-driven编程范型。它的开发方式和经典的Event-condition-action (ECA)非常类似。其通常包含如下方面
- 事件(Event)的触发器:用于描述触发应用逻辑
- 事件处理器: 应该是无状态、原子化的任务,并能够从系统的上下文中进行数据交换。
- 事件的派发和调度:开发者可以声明事件处理器对底层计算资源需求,由系统根据需求自动分配计算资源并调度执行。
和过于技术范的“Functions as a Service”相比,Serverless显然更容易深入人心,然而这个名词也容易给人带来误解。Serverless应用并非不需要服务器作为计算资源,正确的理解是应用开发人员无需关注计算资源的获取和运维,由平台来按需分配计算资源,并保证应用执行的SLA。
正因为上述目标,Serverless/FaaS平台对底层计算环境的提出了特殊要求:
- 快速启动:需要对事件请求快速响应,能够在亚秒级完成启动
- 弹性扩展:可以按照应用需求,自动在群集上分配资源,按需伸缩,无需人工干预。
- 良好的隔离性:不同应用之间不相互干扰
- 健壮性:应用逻辑执行失败后,可以快速调度并重新执行
看到这里,我们可以看到容器技术(LXC, CGroup等)非常适合用于提供Serverless的计算环境。每次系统接收到事件,动态启动容器来执行业务逻辑即可。
下面介绍一个基于Docker的Serverless平台的一个高层次的参考架构,要点如下:
- Docker容器作为事件处理的计算环境运行
- 将函数化事件处理逻辑打包成为Docker镜像,利用镜像仓库进行管理和分发
- 事件调度器配合Docker集群来调度事件处理执行
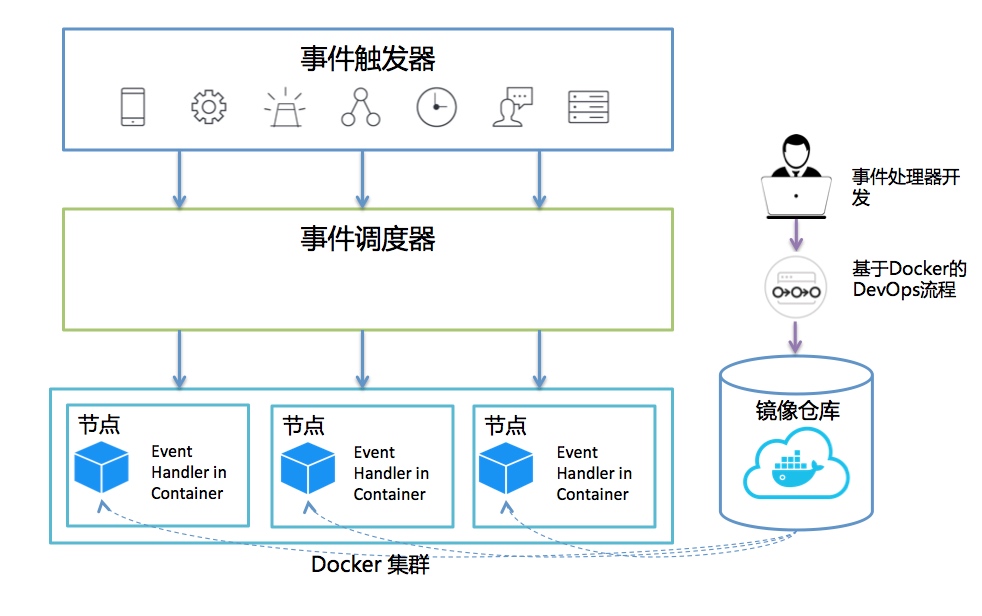
利用Docker容器的方法实现Serverless平台,有如下优势:
- 利用Docker提供的轻量级OS虚拟化能力,能够敏捷地创建事件执行运行环境,并提供基本的资源、安全隔离能力
- 使用Docker镜像和镜像仓库,简单标准地对事件处理逻辑进行打包和在分布式环境下进行软件分发;通过Docker镜像的版本管理和追踪能力,可以管控应用发布,保证应用在大规模分布式环境中部署的一致性。
- 在Docker容器内部,开发人员可以自由选择使用不同的语言和框架进行事件处理,容器之间不会相互干扰。
- Docker容器提供了标准化的外界环境交互的能力,应用逻辑可以通过环境变量、文件卷或者网络来访问上下文状态信息。
- 对不同实现的Docker容器进行统一的标准化运维处理,大大减少运维的复杂性,可以更好地实现自动化运维
- 基于Docker编排技术(比如阿里云容器服务等)提供的集群管理和编排能力,可以大大简化事件调度器的实现
- 受益于成熟的Docker的DevOps流程,可以大大提升开发交付效率
二、Serverless架构的演进
Serverless架构风格挑战了软件设计和软件部署基础的现状,以实现最佳开发、最优运营和最优的管理开销。虽然它继承了微服务架构MSA的基本概念,但它已被赋予了新的架构模式,尽可能实现最高效的硬件利用。
尽管Serverless架构有显著的进步,但适应这种架构需要一个周全的过程,把企业解决方案精确映射到Serverless架构上。
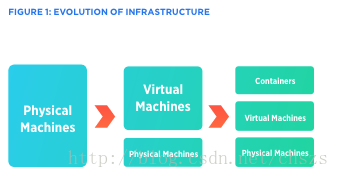
部署在物理服务器上的软件系统,其初始实现不能最佳地利用底层硬件的计算能力,因为在给定时间内只能有一个操作系统实例运行。随后的改造中,在计算资源中识别时间共享能力之后,多个虚拟计算机能够通过在它们之间切换CPU和I/O操作从而实现在相同硬件上的同时运行。
这种技术演进导致了行业中的许多创新,最重要的是云的诞生。此时,虚拟机是用于部署软件的隔离计算环境中最易于管理的、可扩展的和可编程的单元。Linux容器技术出现在2006年左右,当时Google实现了符合Linux内核特性的控制组。
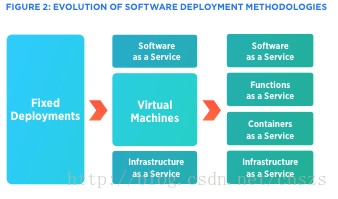
Linux容器自那时以来一直存在。然而,只有规模大、技术上超越的企业,比如谷歌,才能够规模化的使用它。到2012年,在欧洲,一个软件架构师讨论组引入了微服务架构的概念。在2013年晚些时候,Docker巧妙地填补了容器生态系统中的可访问性、可用性和支持服务的空白,因此,容器开始变得流行起来。
Linux容器打开了一个新的视野,将大型单片系统分解成独立的自包含服务,并以细粒度的资源利用来执行它们。为了加快这些进展,容器集群管理系统(如Kubernetes和Mesosphere)在同一时期开始提供端到端的容器即服务(CaaS)的能力。
到2015年晚些时候,AWS通过引入AWS Lambda实现了另一个飞跃,它可以通过按需运行微服务进一步节省软件部署成本,并在无负载时自动停止。这种概念类似于节能车辆中的停止-启动的特性,其自动关闭内燃机以降低燃料消耗。
它是如何工作的?
尽管术语“Serverless”乍一看是荒谬的,但其实际的意义在于,部署软件无需涉及基础设施的建设。Serverless平台可以根据需要自动构建、部署和启动服务的整个过程。用户只需注册所需的业务功能及其资源需求。
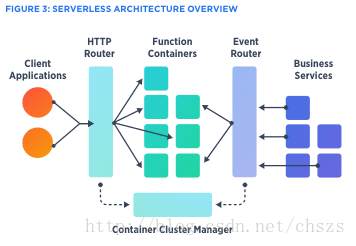
显然,这样的功能可以分为两种主要类型:由客户端请求触发的功能,和需要通过时间触发器或事件触发的后台执行的功能。
通常,这种Serverless系统可以使用具有动态路由器的容器集群管理器(CCM)来实现,该动态路由器可以按需调整容器。然而,还需要考虑路由器的延迟、容器的创建时间、语言支持、协议支持、功能接口、函数初始化时间、配置参数的传递、提供证书文件等。
尽管这种部署方式要求在没有负载时停止容器,但实际上在服务请求之后很快就停止容器,这种开销也将是昂贵的,因为在短时间间隔内可能有更多的请求进入。因此,更通常的做法是,在Serverless计算容器中将保留预先配置的时间段以便能重用于对服务的更多请求。这类似于PaaS平台中的自动缩放行为。一旦服务被扩展了,实例将被保留一段时间以便能及时处理更多的请求,而不会立即终止它们。
在此我向大家推荐一个架构学习交流群。交流学习群号:575745314 里面会分享一些资深架构师录制的视频录像:有Spring,MyBatis,Netty源码分析,高并发、高性能、分布式、微服务架构的原理,JVM性能优化、分布式架构等这些成为架构师必备的知识体系。还能领取免费的学习资源,目前受益良多
三、Serverless架构的优缺点
Serverless架构或Serverless计算是软件架构风格向分布式系统发展结果,而当前建立一个系统的标准是面向服务架构(SOA)或者是SOA之微服务架构。
下面看看Serverless的目标和优缺点权衡。
低运营成本
微服务架构中的服务需要一直运行,实际上,在高负载情况下每个服务都不止一个实例,这样才能完成高可用性,在Serverless架构中则是没有事件发生时不会有服务运行,主机平台会只有在需要时才会执行相应的函数,按照云计算pay-as-you-go原则,如果没有东西运行,你就不必付款。
在Serverless架构中,扩展和自动扩展是没有问题的,当负载增加,会让受影响的函数以并行方式运行得更频繁。
弹性配置也在Serverless架构中很有效率,对于传统的云计算环境你会说:
“我愿意买3G内存,然后以后暂时就不需要再扩展了”。
而现在你会说:
“我会为X类型的30000个事件付费,为Y类型的5000个事件付费,然后以后暂时就不需要再扩展了”。
很明显,Serverless计算针对资源的使用是有效率的,特别具有运营的可操作性。
风险1:厂商锁定
平台会提供Serverless架构给大玩家,比如AWS Lambda,运行它需要使用AWS指定的服务,比如API网关,DynamoDB,S3等等,一旦你在这些服务上开发一个复杂系统,你会粘牢AWS,以后只好任由他们涨价定价了。
复杂性和低聚合
多少年来,软件工程师为高聚合和低复杂性奋斗,领域驱动设计和微服务是完美的配合,因为他们总结过去多少年的软件工程经验。
如果开发者忽视这些经验教训是会有风险的,特别是在构建Serverless架构时,它们会遭遇不可维护的函数地狱,在这个情况下,低运营成本优势也许会被更高维护成本超过。
四、创建自己的 Serverless 短链服务
代码逻辑
这里的代码逻辑比如简单:
- 创建短链时,使用生成一个四位的字符串
- 将原有的 URL 和生成的 URL 存储到 DynamoDB 中
- 在返回的 HTML 中,输出对应的 URL
- 重定向时,从 DynamoDB 读取对应的短链
- 如果短链存在,则执行 302 重定向;如果不存在,则返回一个 404。
创建首页
首页只是一个简单的 HTML 表单:

当我们提交的时候,就会触发对应的 POST 请求。
生成短链
如上所述,对于个短链请求,我们要做这么几件事:
- 解析出提交表单中的链接
- 根据 URL 生成对应的短链
- 将对应的 URL 和短链的对应关系存储到 DynamoDB 中
- 如果成功,则返回生成的短链;失败则,返回一个 400
事实上,在存储 URL 和短链的 map 之前,我们应该先判断一下数据中是否已经有相应的短链。不过,对于这种只针对于我一个用户的短链服务来说,这个步骤有点浪费钱——毕竟要去扫描一遍数据库。所以,我也不想去添加这样的扩展功能。
接下来,让我们回到代码中去,代码的主要逻辑都是在 Promise 里,按顺序往下执行。
解析出提交表单中的链接
首先,我们通过 querystring 库来解决中表单中的链接。

根据 URL 生成对应的短链
接着,使用 Node.js 中的 crypto.randomBytes 方法来生成八位的伪随机码。

于生成的伪随机码是 Buffer 类型,因此需要转换为字符串。同时,因为生成的短链中不应该有 “=+/”,它会导致生成的 URL 有异常。于是,我们便替换掉伪随机码中的这些特殊字体。最后,截取生成的字符串的前 4 位。
现在,我们就可以将其存储到数据中了。
存储到 Dynamo 数据库中。
对应的存储逻辑如下所示,我们 new 了一个 DocumentClient 对象,然后直接存储到数据库中。put 函数中的对象,即是对应的参数。

最后,我们返回了 slug,用于接下来的处理。
返回短链给用户
一切处理正常的话,我们将向用户返回最后的内容:

其中的 HTML 部分的渲染逻辑如下所示:
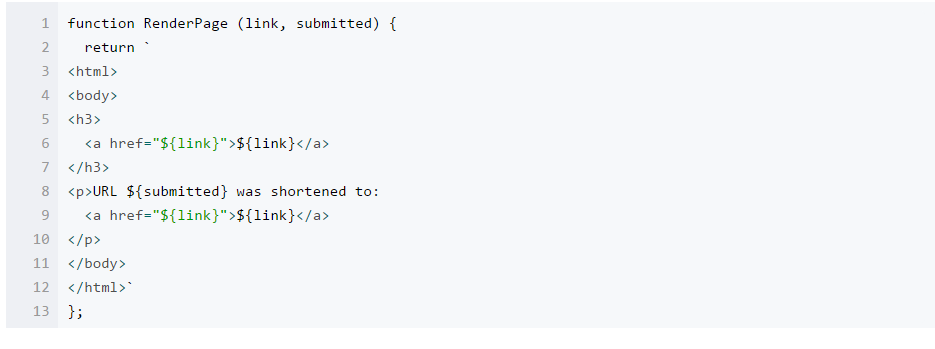
是的,只是返回短链和原有的链接了。
好了,现在我们已经拥有这个短链了。接下来,就是点击这个短链,看看背后会发生些什么?
重定向短链
首先,我们先在我们的 serverless.yml 中,将短链的路径配置为参数:
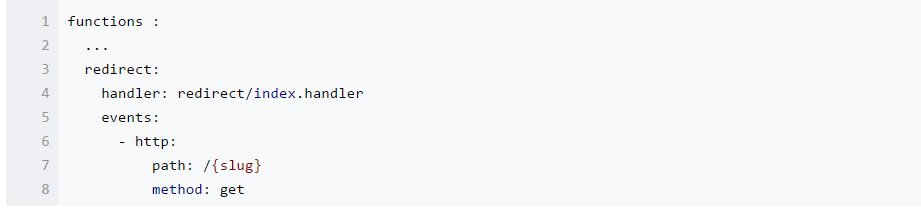
然后,从数据库中按短链的 slug 查找对应的 URL:
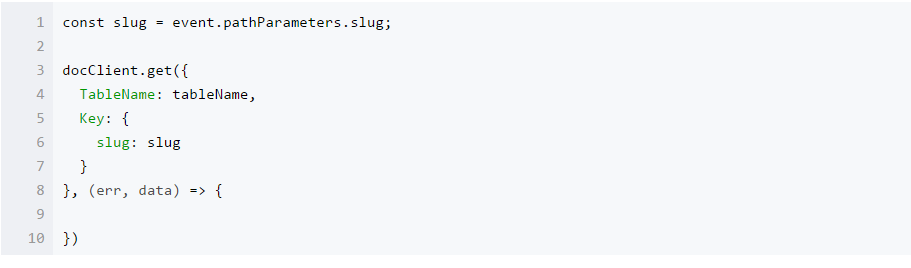
如果存在对应的短链,则 302 重定向对原有的 URL:

如果没有,则返回一个 404。
我们的代码就是这么的简单,现在让我们来部署测试一下。
部署及测试短链服务
如果你还没有 clone 代码的话,执行下面的命令来安装:
![]()
然后执行 yarn install 来安装对应的依赖。
如果你在 Route53 上注册有相应的域名,修改一下 serverless.yml 文件中的域名,我们就可以使用 serverless create_domain 来创建域名的路由。
紧接着,执行 serverless deploy 来部署。
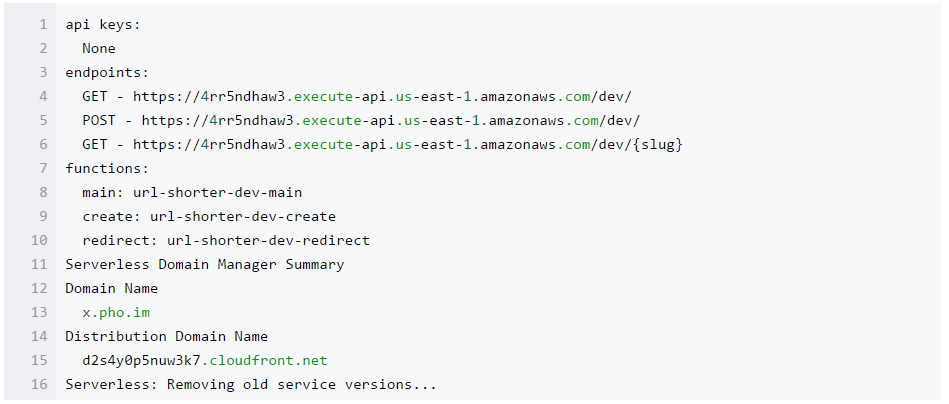
一切准备就绪了。
例如:
- 访问 https://x.pho.im/
- 然后输入一个链接,如:https://github.com/phodal/serverless-guide
- 复制生成的地址:https://x.pho.im/rgQC,并返回
- 看是否会重定向到我们的网站上。
五、Serverless 微服务的持续交付
架构图如下:
在这个架构中,我们采用了前后端分离的技术。我们把 HTML,JS, CSS 等静态内容部署在 S3 上,并通过 CloudFront 作为 CDN 构成了整个架构的前端部分。
我们把 Amazon API Gateway 作为后端的整体接口连接后端的各种风格的微服务,无论是运行在 Lambda 上的函数,还是运行在 EC2 上的 Java 微服务,他们整体构成了这个应用的后端部分。
从这个架构图上我们可以明显的看到 前端(Frontend)和后端(Backend)的区分。
持续部署流水线的设计和实现
任何 DevOps 部署流水线都可以分为三个阶段:待测试,待发布,已发布。
由于我们的架构是前后端分离的,因此我们为前端和后端分别构造了两条流水线,使得前后端开发可以独立。如下图所示:
在这种情况下,前端团队和后端团队是两个不同的团队,可以独立开发和部署,但在发布的时候则有些不同。由于用户是最后感知功能变化的。
因此,为了避免界面报错找不到接口,在新增功能的场景下,后端先发布,前端后发布。在删除功能的场景下,前端先发布,后端后发布。
我们采用 Jenkins 构建我们的流水线,Jenkins 中已经含有足够的 AWS 插件可以帮助我们完成整个端到端的持续交付流水线。
前端流水线
前端持续交付流水线如下所示:
前端流水线的各步骤过程如下:
-
我们采用 BDD/ATDD 的方式进行前端开发。用 NightWatch.JS 框架做 端到端的测试,mocha 和 chai 用于做某些逻辑的验证;
-
我们采用单代码库主干(develop 分支)进行开发,用 master 分支作为生产环境的部署。生产环境的发布则是通过 Pull Request 合并的。在合并前,我们会合并提交;
-
前端采用 Webpack 进行构建,形成前端的交付产物。在构建之前,先进行一次全局测试;
-
由于 S3 不光可以作为对象存储服务,也可以作为一个高可用、高性能而且成本低廉的静态 Web 服务器。所以我们的前端静态内容存储在 S3 上。每一次部署都会在 S3 上以 build 号形成一个新的目录,然后把 Webpack 构建出来的文件存储进去;
-
我们采用 Cloudfront 作为 CDN,这样可以和 S3 相互集成。只需要把 S3 作为 CDN 的源,在发布时修改对应发布的目录就可以了。
由于我们做到了前后端分离。因此前端的数据和业务请求会通过 Ajax 的方式请求后端的 Rest API,而这个 Rest API 是由 Amazon API Gateway 通过 Swagger 配置生成的。
前端只需要知道 这个 API Gateway,而无需知道 API Gateway 的对应实现。
后端流水线
后端持续交付流水线如下所示:
后端流水线的各步骤过程如下:
-
我们采用 “消费者驱动的契约测试” 进行开发,先根据前端的 API 调用构建出相应的 Swagger API 规范文件和示例数据。然后,把这个规范上传至 AWS API Gateway,AWS API Gateway 会根据这个文件生成对应的 REST API。前端的小伙伴就可以依据这个进行开发了;
-
之后我们再根据数据的规范和要求编写后端的 Lambda 函数。我们采用 NodeJS 作为 Lambda 函数的开发语言。并采用 Jest 作为 Lambda 的 TDD 测试框架;
-
和前端一样,对于后端我们也采用单代码库主干(develop 分支)进行开发,用 master 分支作为生产环境的部署;
-
由于 AWS Lambda 函数需要打包到 S3 上才能进行部署,所以我们先把对应的构建产物存储在 S3 上,然后再部署 Lambda 函数;
-
我们采用版本化 Lambda 部署,部署后 Lambda 函数不会覆盖已有的函数,而是生成新版本的函数。然后通过别名(Alias)区分不同前端所对应的函数版本。默认的
$LATEST,表示最新部署的函数;此外我们还创建了 Prod,PreProd, uat 三个别名,用于区分不同的环境。这三个别名分别指向函数某一个发布版本。例如:函数 func 我部署了 4 次,那么 func 就有 4 个版本(从 1 开始);
然后,函数 func 的
$LATEST别名指向 4 版本。别名 PreProd 和 UAT 指向 3 版本,别名 Prod 在 2 版本; -
技术而 API 的部署则是修改 API Gateway 的配置,使其绑定到对应版本的函数上去。由于 API Gateway 支持多阶段(Stage)的配置,我们可以采用和别名匹配的阶段绑定不同的函数;
-
完成了 API Gateway 和 Lamdba 的绑定之后,还需要进行一轮端到端的测试以保证 API 输入输出正确;
-
测试完毕后,再修改 API Gateway 的生产环境配置就可以了。
部署的效果如下所示:
无服务器微服务的持续交付新挑战
在实现以上的持续交付流水线的时候,我们踩了很多坑。但经过我们的反思,我们发现是云计算颠覆了我们很多的认识,当云计算把某些成本降低到趋近于 0 时。我们发现了以下几个新的挑战:
-
如果你要 Stub,有可能你走错了路;
-
测试金子塔的倒置;
-
你不再需要多个运行环境,你需要一个多阶段的生产环境 (Multi-Stage Production);
-
函数的管理和 NanoService 反模式。
-
在此我向大家推荐一个架构学习交流群。交流学习群号:575745314 里面会分享一些资深架构师录制的视频录像:有Spring,MyBatis,Netty源码分析,高并发、高性能、分布式、微服务架构的原理,JVM性能优化、分布式架构等这些成为架构师必备的知识体系。还能领取免费的学习资源,目前受益良多
Stub ?别逗了
很多开发者最初都想在本地建立一套开发环境。
由于 AWS 多半是通过 API 或者 CloudFormation 操作,因此开发者在本地开发的时候对于 AWS 的外部依赖进行打桩(Stub) 进行测试,例如集成 DynamoDB(一种 NoSQL 数据库)。
当然你也可以运行本地版的 DynamoDB,但组织自动化测试的额外代价极高。然而随着微服务和函数规模的增加,这种管理打桩和构造打桩的虚拟云资源的代价会越来越大,但收效却没有提升。
另一方面,往往需要修改几行代码立即生效的事情,却要执行很长时间的测试和部署流程,这个性价比并不是很高。
这时我们意识到一件事:如果某一个环节代价过大,你需要思考一下这个环节存在的必要性。
由于 AWS 提供了很好的配置隔离机制,于是为了得到更快速的反馈,我们放弃了 Stub 或构建本地 DynamoDB,而是直接部署在 AWS 上进行集成测试。
只在本地执行单元测试,由于单元测试是 NodeJS 的函数,所以非常好测试。
另外一方面,我们发现了一个有趣的事实,那就是:
测试金子塔的倒置
由于我们采用 ATDD 进行开发,然后不断向下进行分解。在统计最后的测试代码和测试工作量的的时候,我们有了很有趣的发现:
End-2-End (UI)的测试代码占 30% 左右,占用了开发人员 30% 的时间(以小时作为单位)开发和测试。
集成测试(函数、服务和 API Gateway 的集成)代码占 45% 左右,占用了开发人员 60% 的时间(以小时作为单位)开发和测试。
单元测试的测试代码占 25% 左右,占用了 10% 左右的时间开发和测试。
-
我们并没有太多的手动测试,绝大部分自动化。除了验证手机端的部署以外,几乎没有手工测试工作量;
-
我们的自动化测试都是必要的,且没有重复;
-
我们的单元测试足够,且不需要增加单元测试。
但为什么会造成这样的结果呢,经过我们分析。是由于 AWS 供了很多功能组件,而这些组件你无需在单元测试中验证(减少了很多 Stub 或者 Mock),只有通过集成测试的方式才能进行验证。
因此,Serverless 基础设施大大降低了单元测试的投入,但把这些不同的组件组合起来则劳时费力。
如果你有多套不一致的环境,那你的持续交付流水线配置则是很困难的。因此我们意识到:
你不再需要多个运行环境,你只需要一个多阶段的生产环境 (Multi-Stage Production)
通常情况下,我们会有多个运行环境,分别面对不同的人群:
-
面向开发者的本地开发环境;
-
面向测试者的集成环境或测试环境(Test,QA 或 SIT);
-
面向业务部门的测试环境(UAT 环境);
-
面向最终用户的生产环境(Production 环境)。
然而多个环境带来的最大问题是环境基础配置的不一致性。加之应用部署的不一致性。带来了很多不可重现问题。
在 DevOps 运动,特别是基础设施即代码实践的推广下,这一问题得到了暂时的缓解。然而无服务器架构则把基础设施即代码推向了极致:
只要能做到配置隔离和部署权限隔离,资源也可以做到同样的隔离效果。
我们通过 DNS 配置指向了同一个的 API Gateway,这个 API Gateway 有着不同的 Stage:我们只有开发(Dev)和生产(Prod)两套配置,只需修改配置以及对应 API 所指向的函数版本就可完成部署和发布。
然而,多个函数的多版本管理增加了操作复杂性和配置性,使得整个持续交付流水线多了很多认为操作导致持续交付并不高效。于是我们在思考:
对函数的管理和 “NanoServices 发模式”
根据微服务的定义,AWS API Gateway 和 Lambda 的组合确实满足 微服务的特征,这看起来很美好。就像下图一样:
但当 Lambda 函数多了,管理众多的函数的发布就成为了很高的一件事。而且, 可能会变成 “NanoService 反模式”(https://www.infoq.com/news/2014/05/nano-services):
Nanoservice is an antipattern where a service is too fine-grained. A nanoservice is a service whose overhead (communications, maintenance, and so on) outweighs its utility.
如何把握微服务的粒度和函数的数量,就变成了一个新的问题。Serverless Framework (https://serverless.com/),就是解决这样的问题的。
它认为微服务是由一个多个函数和相关的资源所组成。因此,才满足了微服务可独立部署可独立服务的属性。
它把微服务当做一个用于管理 Lambda 的单元。所有的 Lambda 要按照微服务的要求来组织。Serverless Framework 包含了三个部分:
-
一个 CLI 工具,用于创建和部署微服务;
-
一个配置文件,用于管理和配置 AWS 微服务所需要的所有资源;
-
一套函数模板,用于让你快速启动微服务的开发。
此外,这个工具由 AWS 自身推广,所以兼容性很好。但是,我们得到了 Serverless 的众多好处,却难以摆脱对 AWS 的依赖。
因为 AWS 的这一套架构是和别的云平台不兼容的。所以,这就又是一个 “自由的代价” 的问题。
CloudNative 的持续交付
在实施 Serverless 的微服务期间,发生了一件我认为十分有意义的事情。我们客户想增加一个很小的需求。
我和两个客户方的开发人员,客户的开发经理,以及客户业务部门的两个人要实现一个需求。当时我们 6 个人在会议室里面讨论了两个小时。
讨论两个小时之后我们不光和业务部门定下来了需求(这点多么不容易),与此同时我们的前后端代码已经写完了,而且发布到了生产环境并通过了业务部门的测试。
由于客户内部流程的关系,我们仅需要一个生产环境发布的批准,就可以完成新需求的对外发布!
在这个过程中,由于我们没有太多的环境要准备,并且和业务部门共同制定了验收标准并完成了自动化测试的编写。这全得益于 Serverless 相关技术带来的便利性。
我相信在未来的环境,如果这个架构,如果在线 IDE 技术成熟的话(由于 Lambda 控制了代码的规模,因此在线 IDE 足够),那我们可以大量缩短我们需求确定之后到我功能上线的整体时间。
通过以上的经历,我发现了 CloudNative 持续交付的几个重点:
-
优先采用 SaaS 化的服务而不是自己搭建持续交付流水线;
-
开发是离不开基础设施配置工作的;
-
状态和过程分离,把状态通过版本化的方式保存到配置管理工具中。
而在这种环境下,Ops 工作就只剩下三件事:
-
设计整体的架构,除了基础设施的架构以外,还要关注应用架构。以及优先采用的 SaaS 服务解决问题;
-
严格管理配置和权限并构建一个快速交付的持续交付流程;
-
监控生产环境。
剩下的事情,就全部交给云平台去做。