深度学习训练中BatchSize、学习率(及学习率下降策略的影响)
从优化本身来看它们是影响模型性能收敛最重要的参数。
学习率直接影响模型的收敛状态,batchsize则影响模型的泛化性能,两者又是分子分母的直接关系,相互也可影响。
文章目录
- 1 Batchsize对训练结果的影响(相同epoch轮数)
- 结果对比
- 1. Alexnet 2080s train_batchsize=32,val_batchsize=64。lr=0.01 GHIMyousan
- 2. Alexnet 2080 train_batchsize=64,val_batchsize=64,lr=0.01 GHIM-me 14k itera
- 3. Alexnet 2080s train_batchsize=64,val_batchsize=64,lr=0.02 GHIM-yousan
- 4 Squeezenet 2080s train_bs=64 val-bs=64 lr 0.01 GHIMyousan
- 4-重复性实验 Squeezenet 2080s train_bs=64 val-bs=64 lr 0.01 GHIM-me,结果还是过拟合 87%acc
- 5 ==mobilenetv1 2080s t-bs:64,v-bs:64 lr:0.01,GHIM-me==过拟合
- 5 ==mobilenetv2 2080s t-bs:64,v-bs:64 lr:0.01,GHIM-me==过拟合
- 6 mobilenetv1 2080 t-bs:64 v-bs:64 lr : 0.01 GHIM-me 拟合好的
- 6 mobilenetv2 2080 t-bs:64 v-bs:64 lr:0.01 GHIM-me 拟合好的
- 10 前人谈batchsize
- 结论
1 Batchsize对训练结果的影响(相同epoch轮数)
这里用GHIM-20,20类每类500张图,共10000张(train9000)(val1000),
共训练100个epoch(相当于对9000张图遍历了100遍,其中每迭代10次打印acc(遍历val_list共1000张)

这里用的Alexnet(分别设置了train_batchsize=32,和train_batchsize=64)
结果对比
1. Alexnet 2080s train_batchsize=32,val_batchsize=64。lr=0.01 GHIMyousan
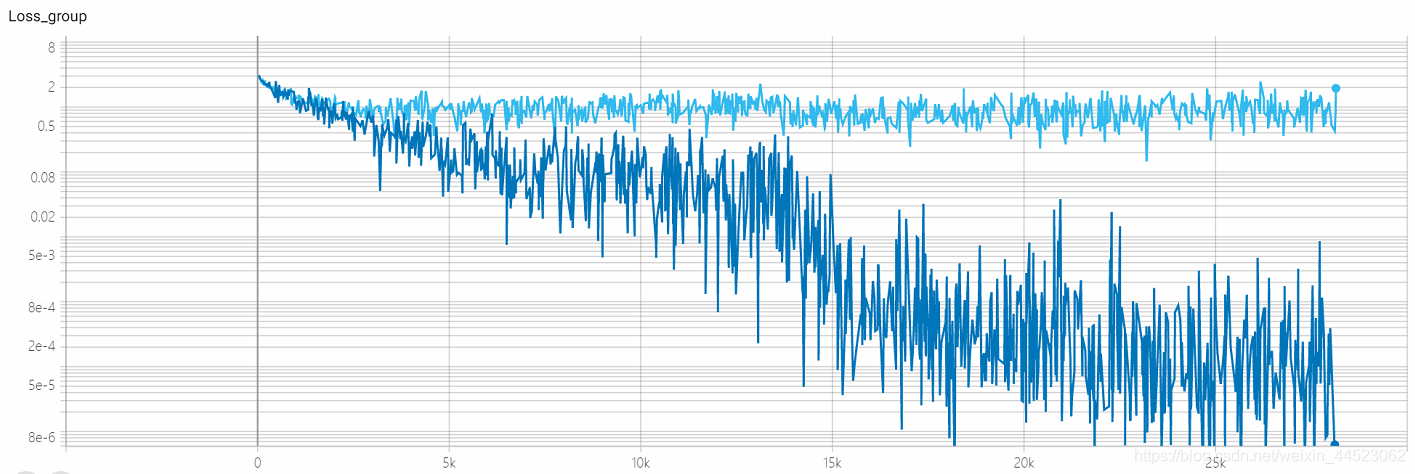
- 2080s 训练s 4.68h , 近28k次迭代==100epoch x 9000/32, 每一个train-batch记录一次loss 深蓝色
- val-batch记录一次 val-loss浅蓝色
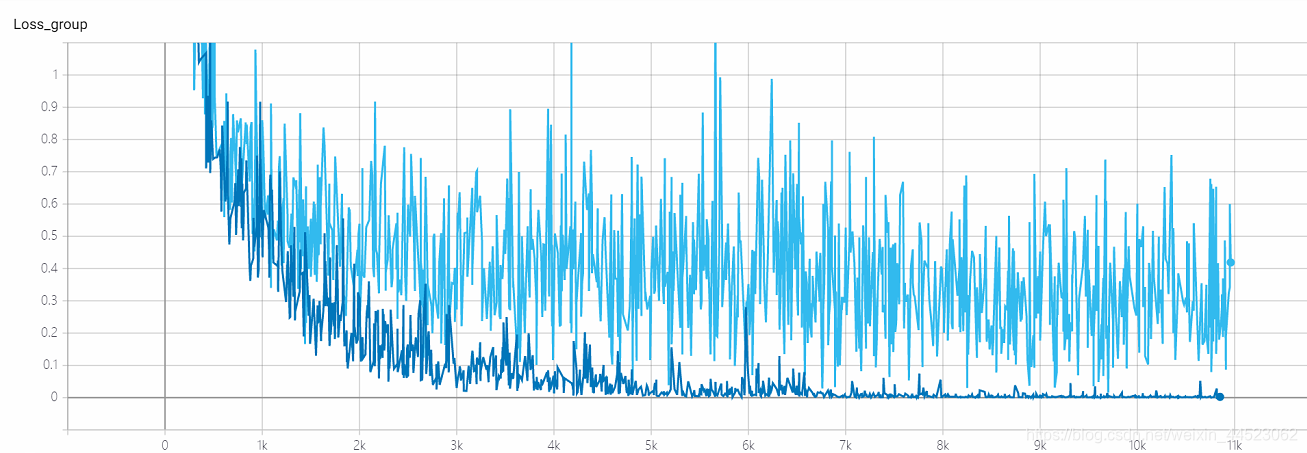
问题:loss算收敛了吗
acc-loss一直大于train-loss看出是过拟合问题
查看了一些解答
1.理论上不收敛,也就是说你设计的网络本身就存在问题,这也是首先应该考虑的因素: 梯度是否存在,即反向传播有没有断裂;
2.理论上是收敛的:-
学习率设置不合理(大多数情况),学习率设置太大,会造成不收敛,如果太小,会造成收敛速度非常慢;
-
Batchsize太大,陷入到局部最优,无法达到全局最优,故而无法继续收敛;
-
网络容量,浅层网络完成复杂的任务loss不下降是肯定的,网络设计太简单,一般情况下,网络的层数和节点数量越大,拟合能力就越强,如果层数和节点不够多,无法拟合复杂的情况,也会造成不收敛。
学习率step下降的基础0.01不算大啊,batchsize=32也不大,所以算是收敛了??(毕竟loss=0.0008也不算大)
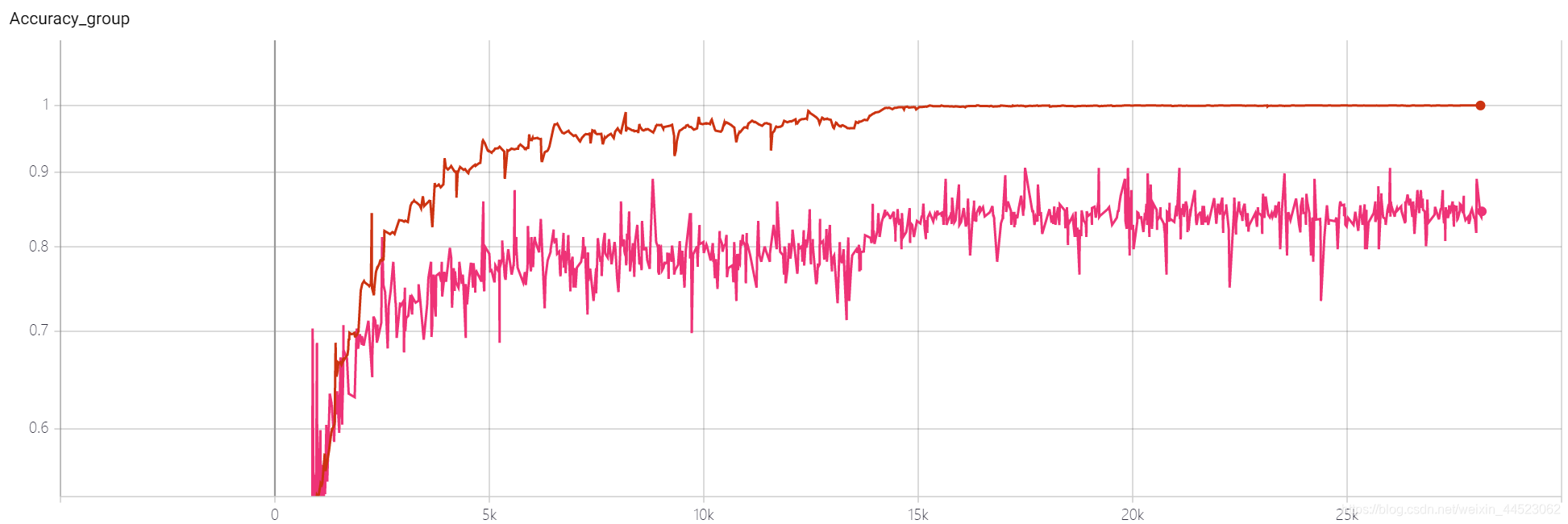
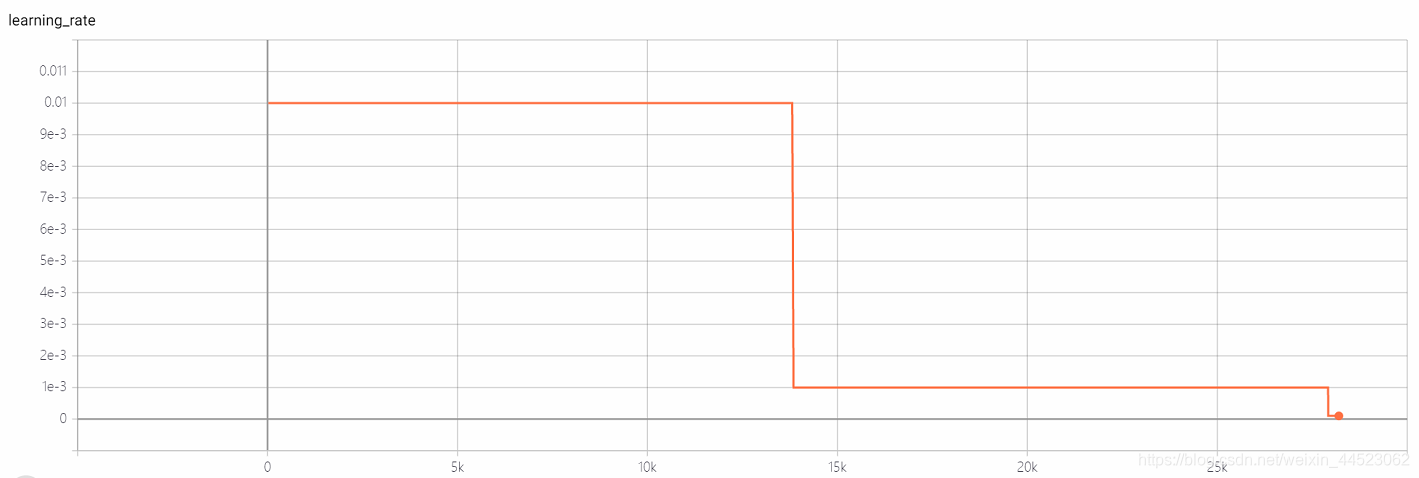
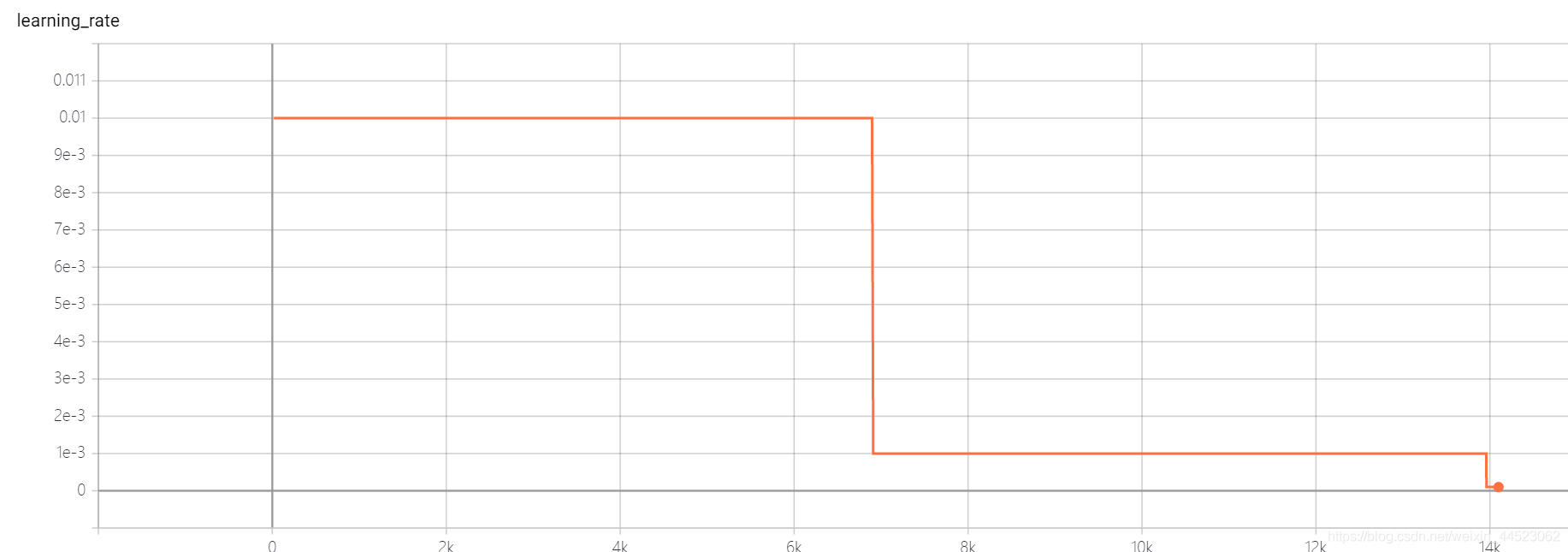
acc曲线如下图:看图迭代到15k次基本就拟合好了(也就是epoch=15000*32/9000=53轮),有趣的是此时正好对应学习率从0.01下降到0.001
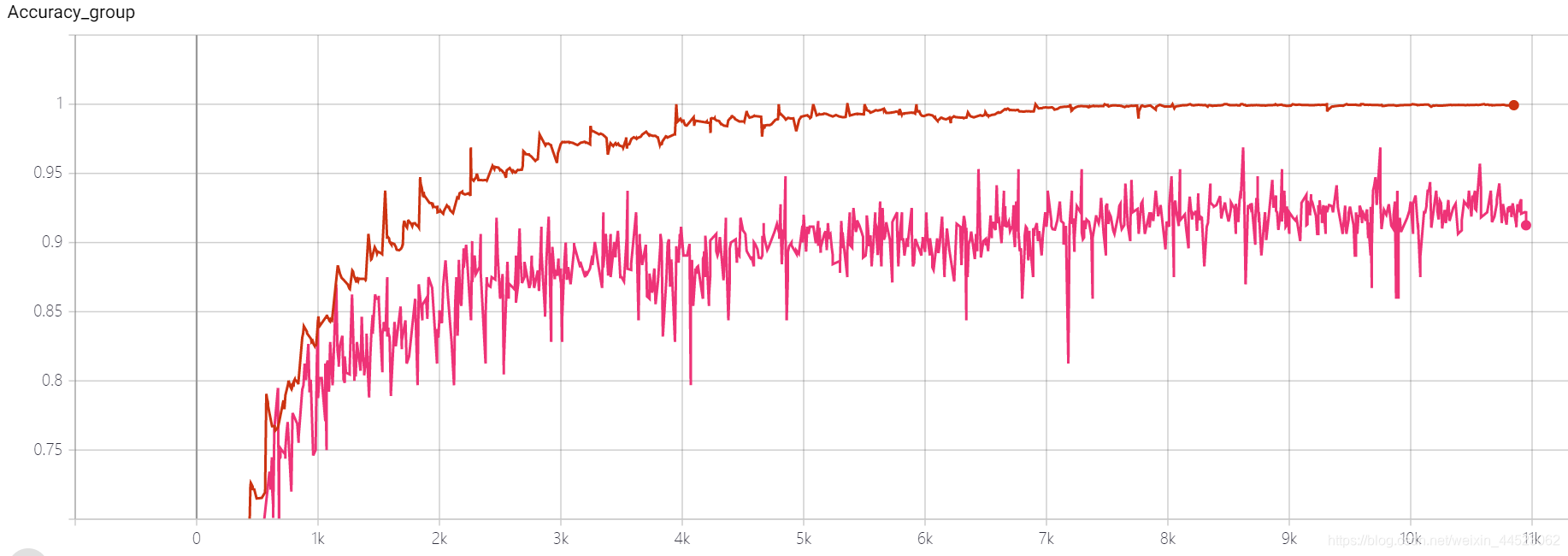
问题:为什么 val的acc84%上不去
训练集表现好,测试集差为过拟合,说明学习的特征还是不够泛化,
那是哪个层学习的特征不够好呢
过拟合解决
1.原因:- 出现过拟合的原因训练集的数量级和模型的复杂度不匹配,
- 训练集的数量级要小于模型的复杂度;
- 训练集和测试集特征分布不一致;
- 样本里的噪音数据…
2.解决方案
(simpler model structure、 data augmentation、 regularization、 dropout、early stopping、ensemble、重新清洗数据)
-
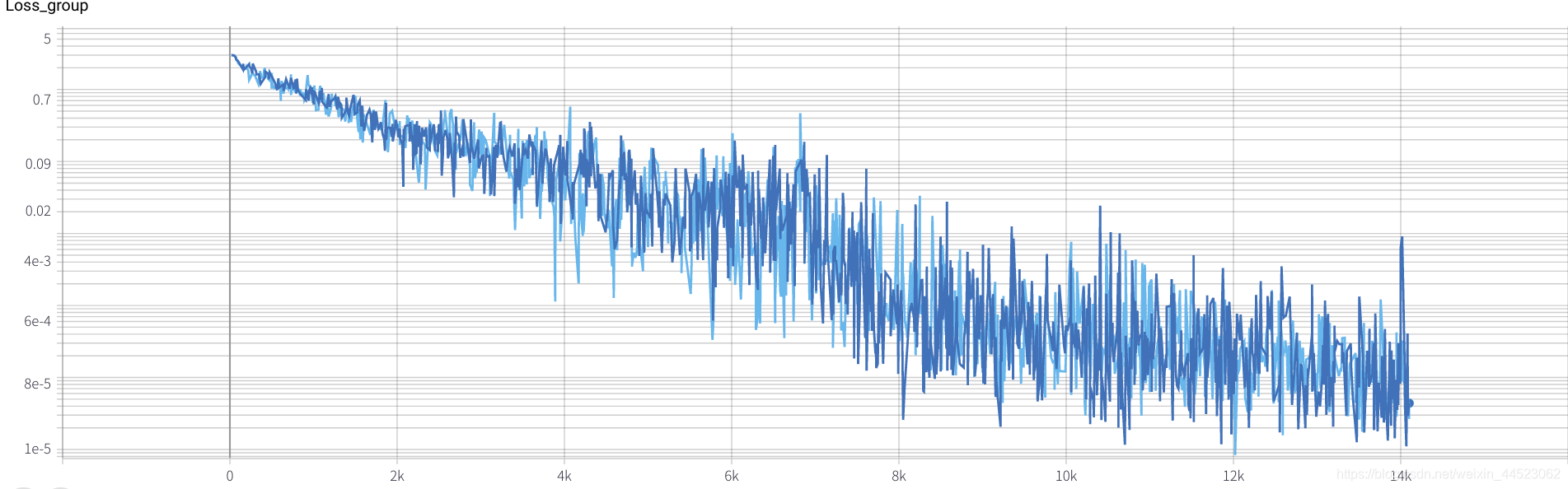
2. Alexnet 2080 train_batchsize=64,val_batchsize=64,lr=0.01 GHIM-me 14k itera
2080 train_batchsize=64,迭代4.5k基本拟合好了(4500*64/9000=32轮),且train和val都比较好。而且拟合都好
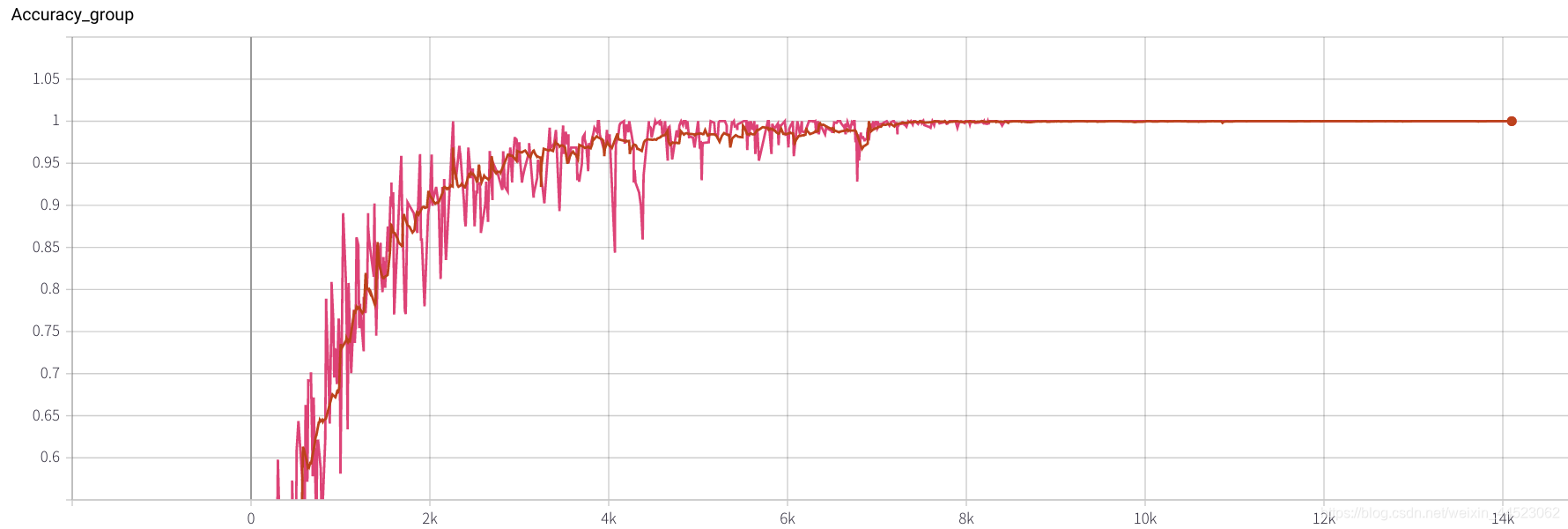
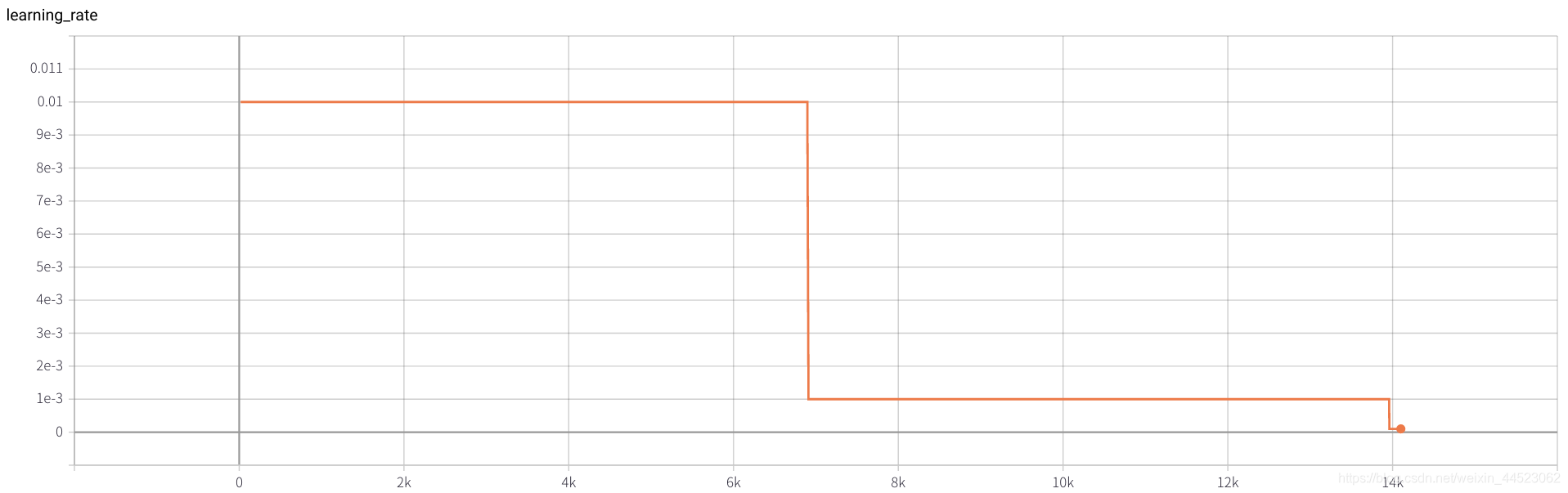
3. Alexnet 2080s train_batchsize=64,val_batchsize=64,lr=0.02 GHIM-yousan
2080s, 没收敛还是过拟合???
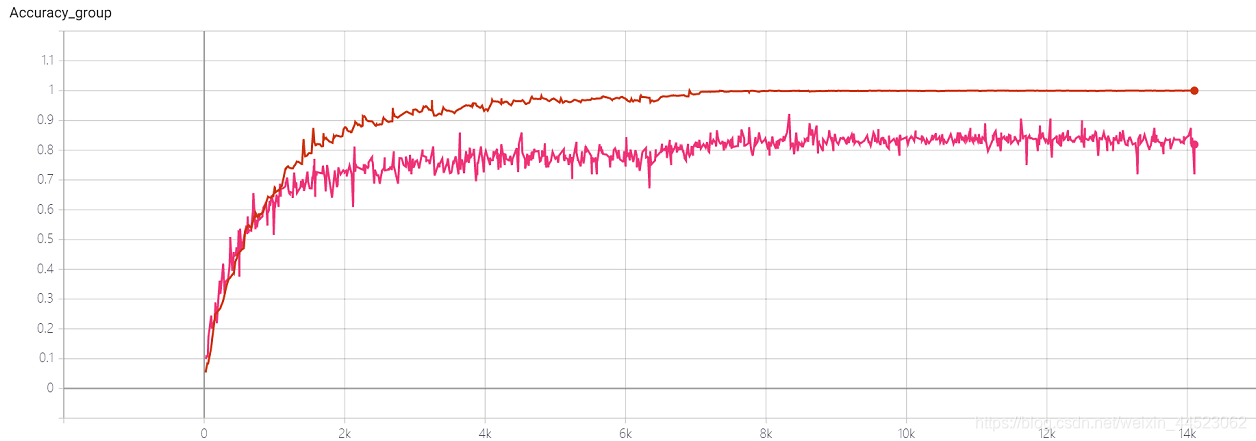
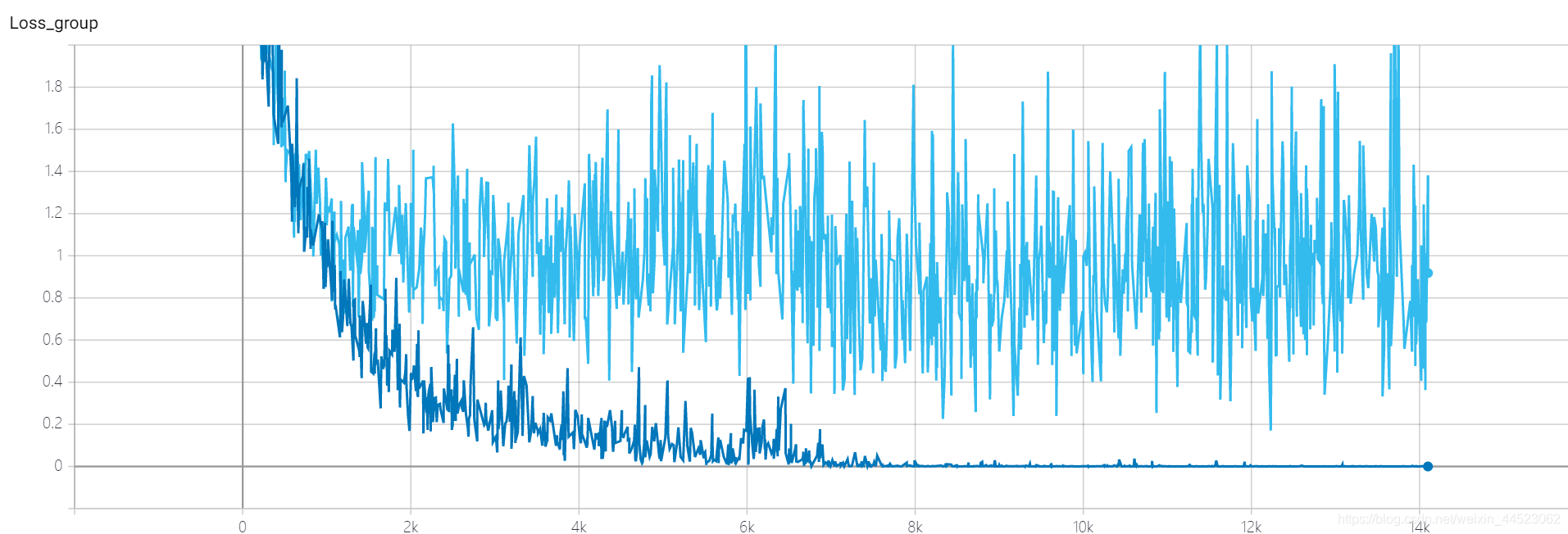
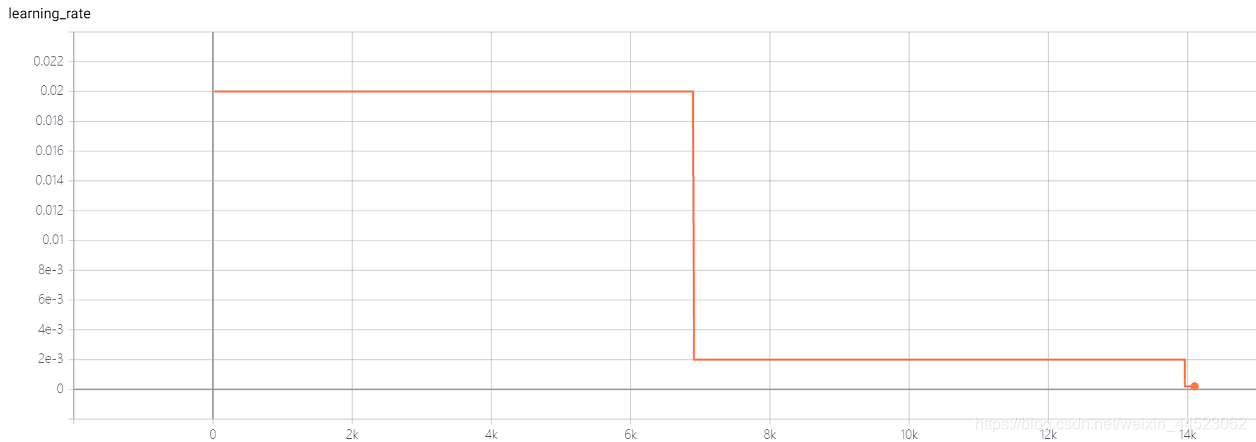
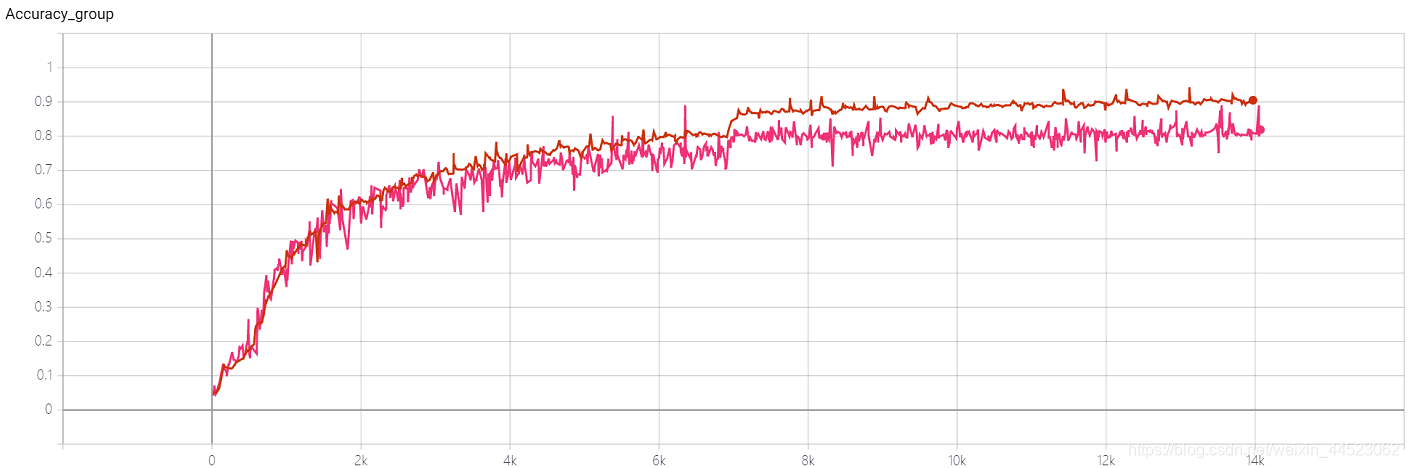
4 Squeezenet 2080s train_bs=64 val-bs=64 lr 0.01 GHIMyousan

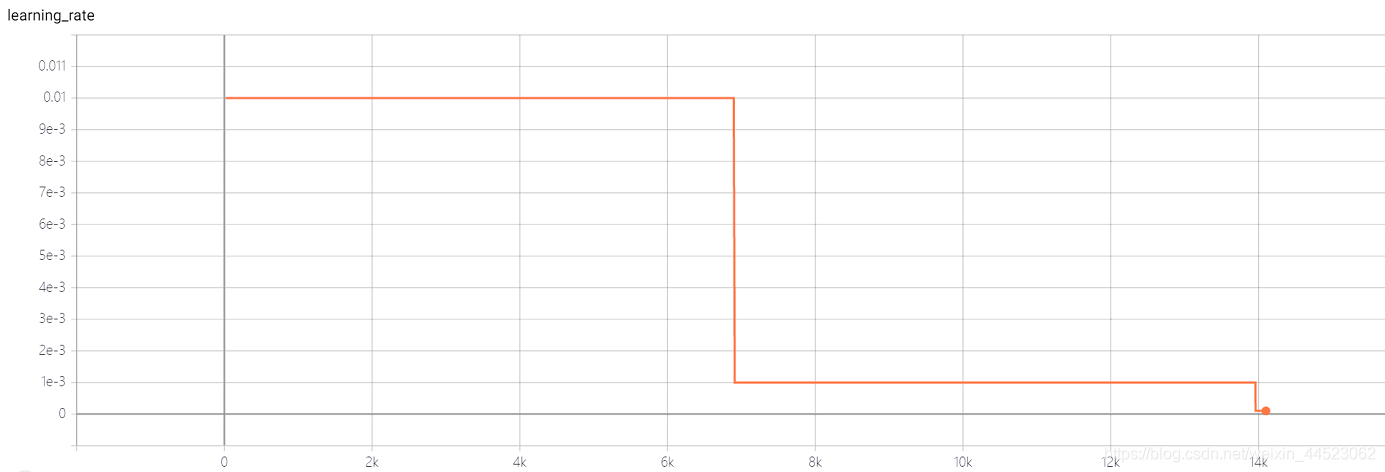
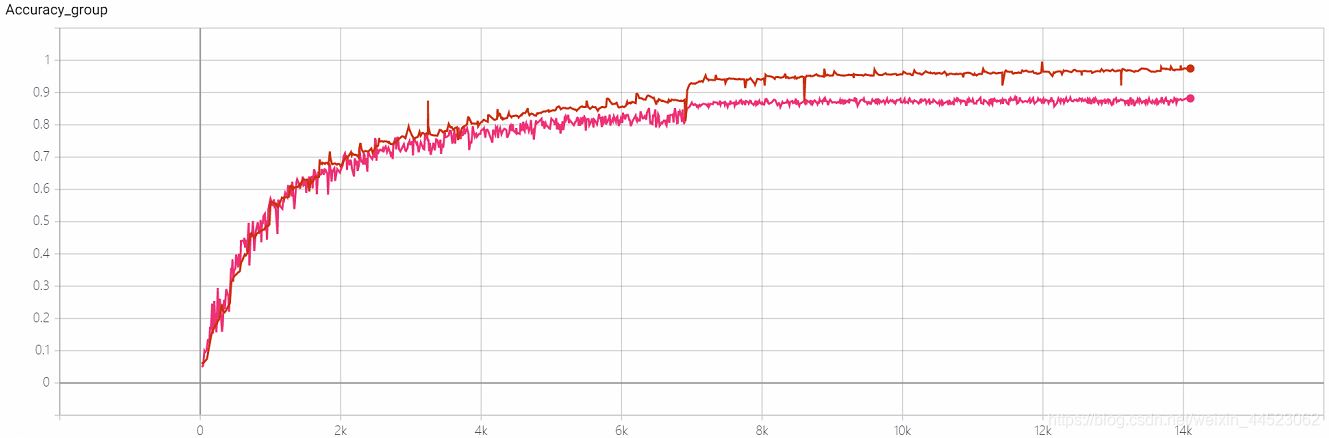
4-重复性实验 Squeezenet 2080s train_bs=64 val-bs=64 lr 0.01 GHIM-me,结果还是过拟合 87%acc
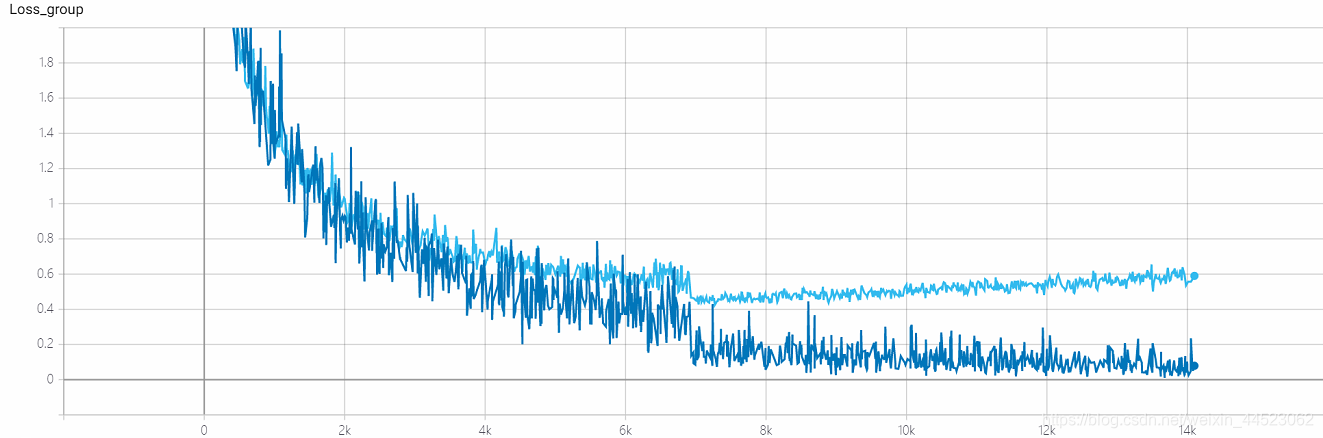
5 mobilenetv1 2080s t-bs:64,v-bs:64 lr:0.01,GHIM-me过拟合
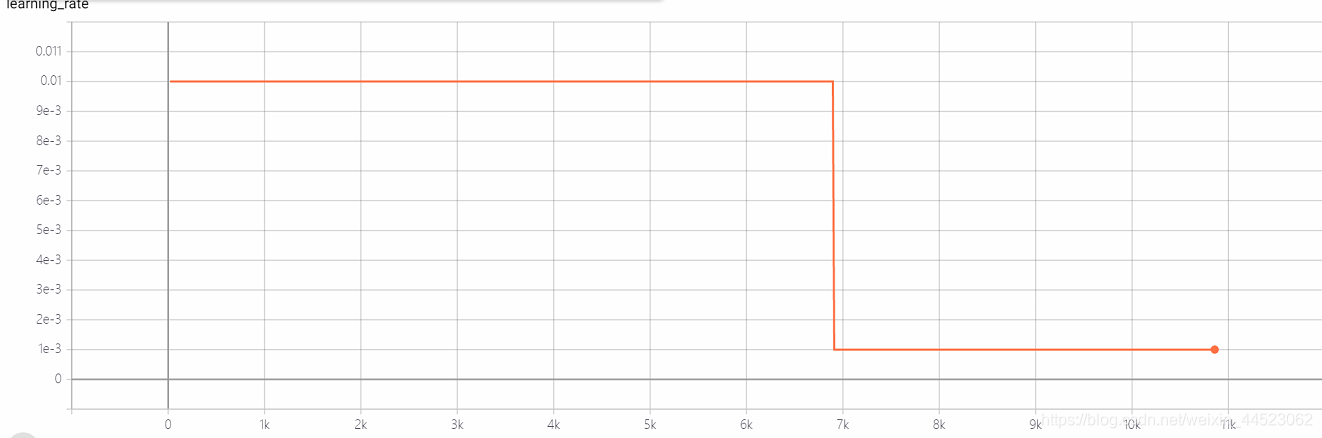
5 mobilenetv2 2080s t-bs:64,v-bs:64 lr:0.01,GHIM-me过拟合
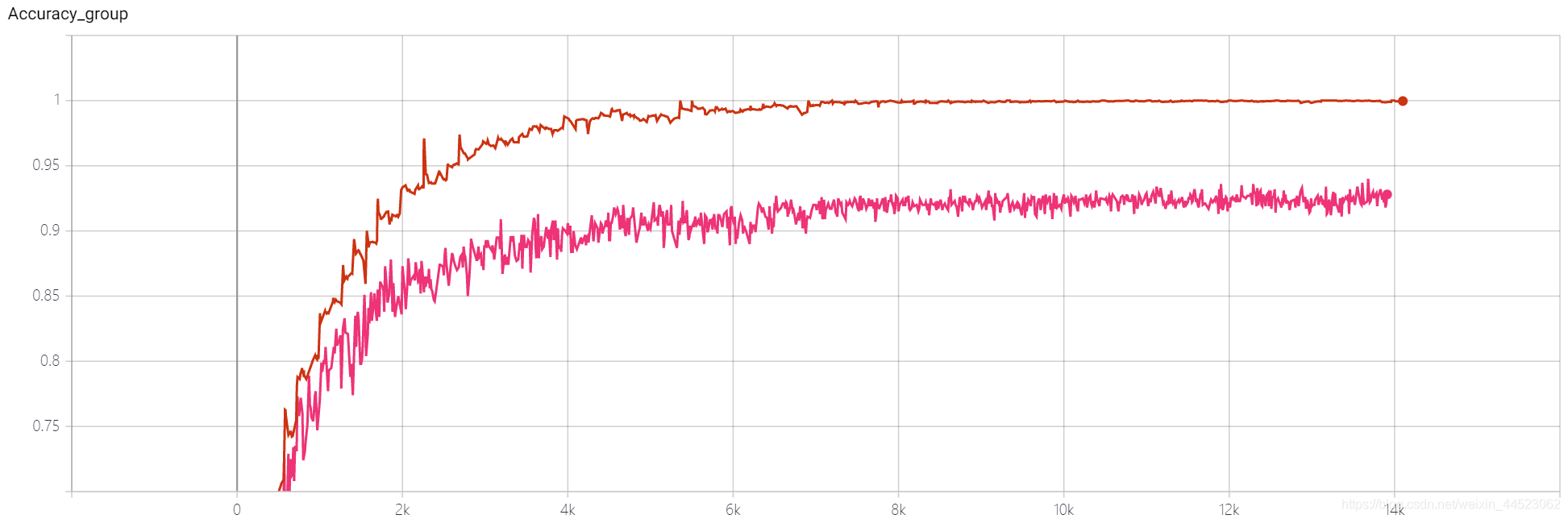
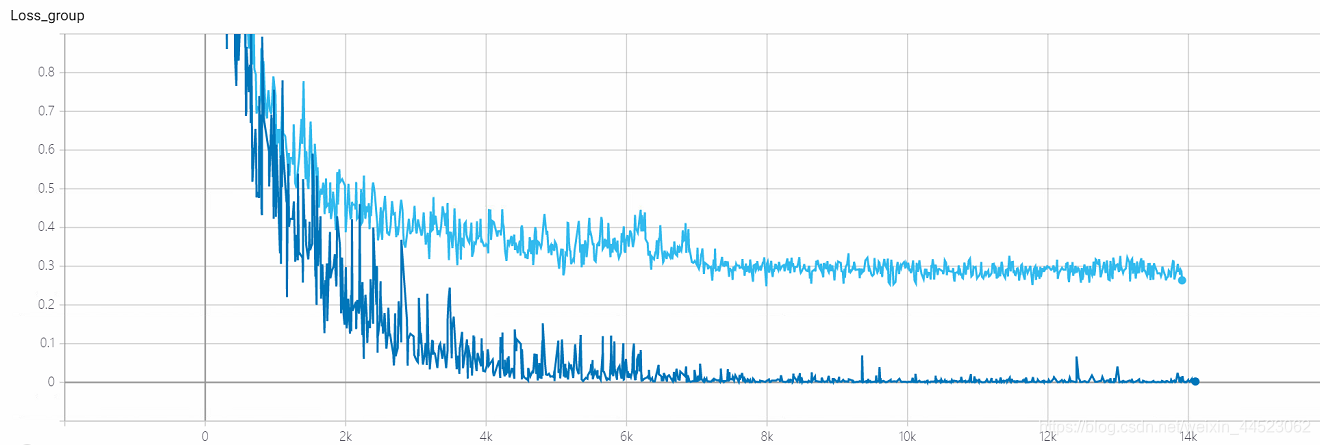
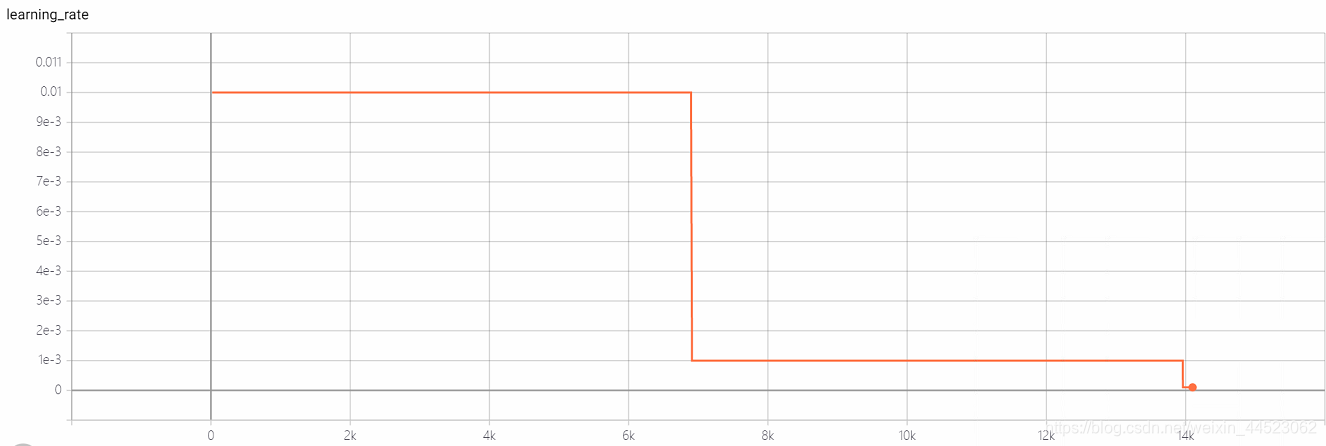
6 mobilenetv1 2080 t-bs:64 v-bs:64 lr : 0.01 GHIM-me 拟合好的
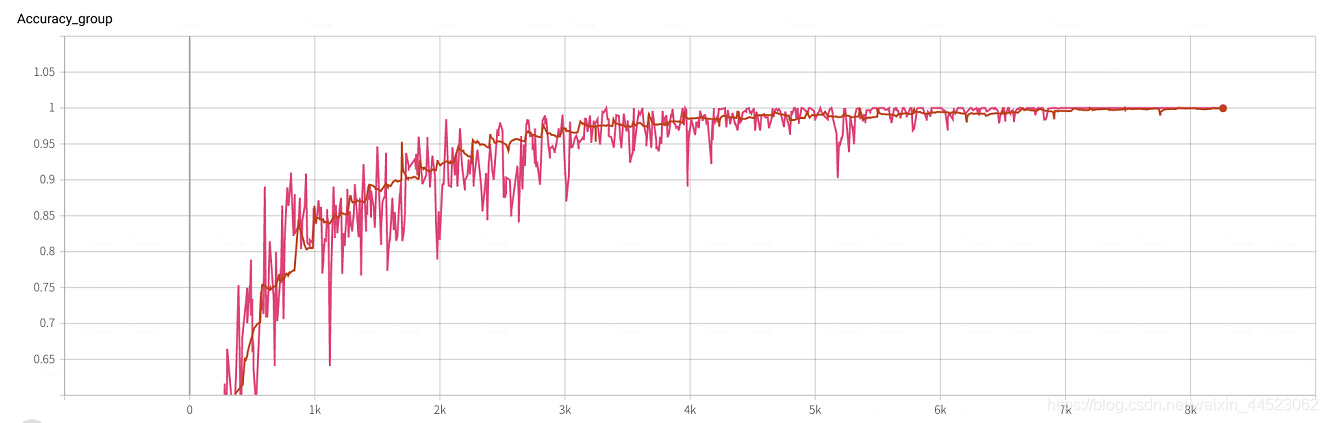

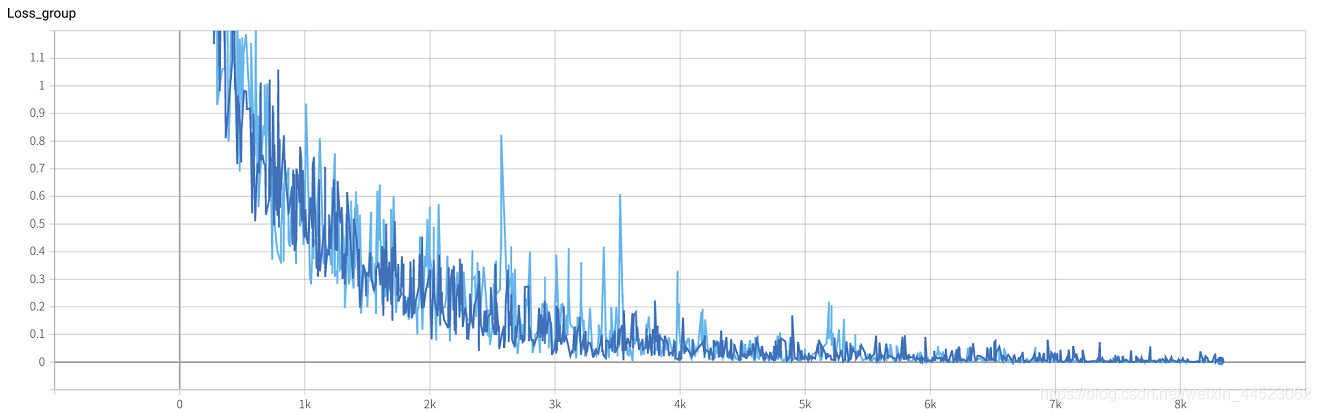
6 mobilenetv2 2080 t-bs:64 v-bs:64 lr:0.01 GHIM-me 拟合好的
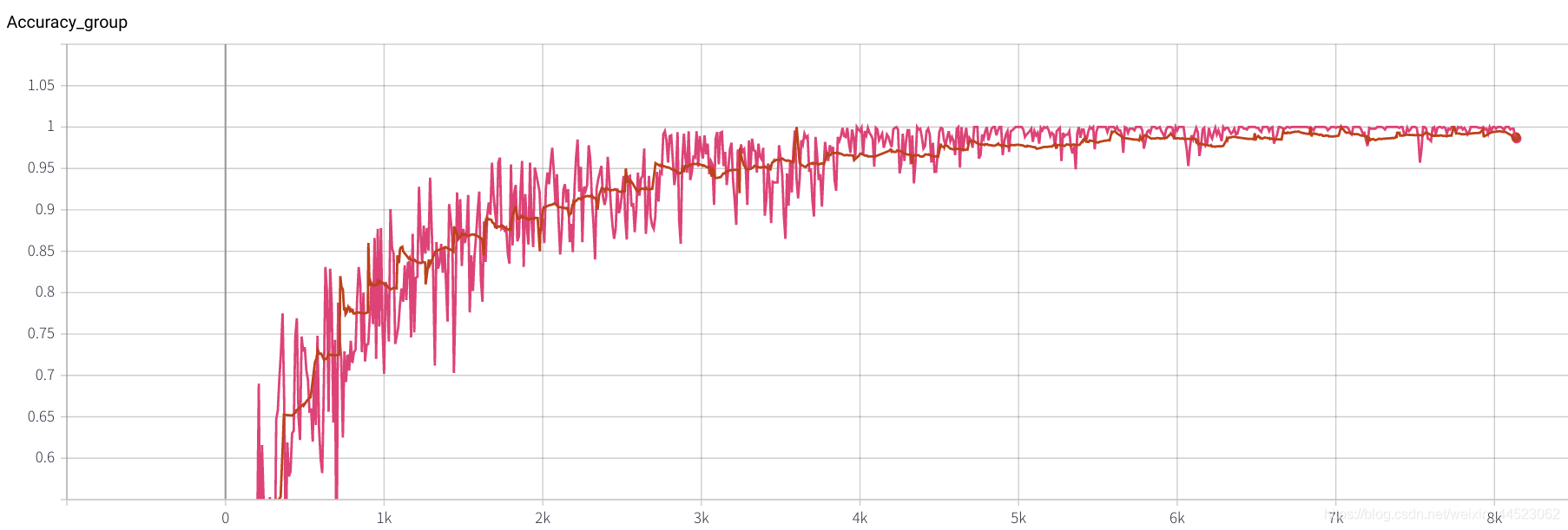
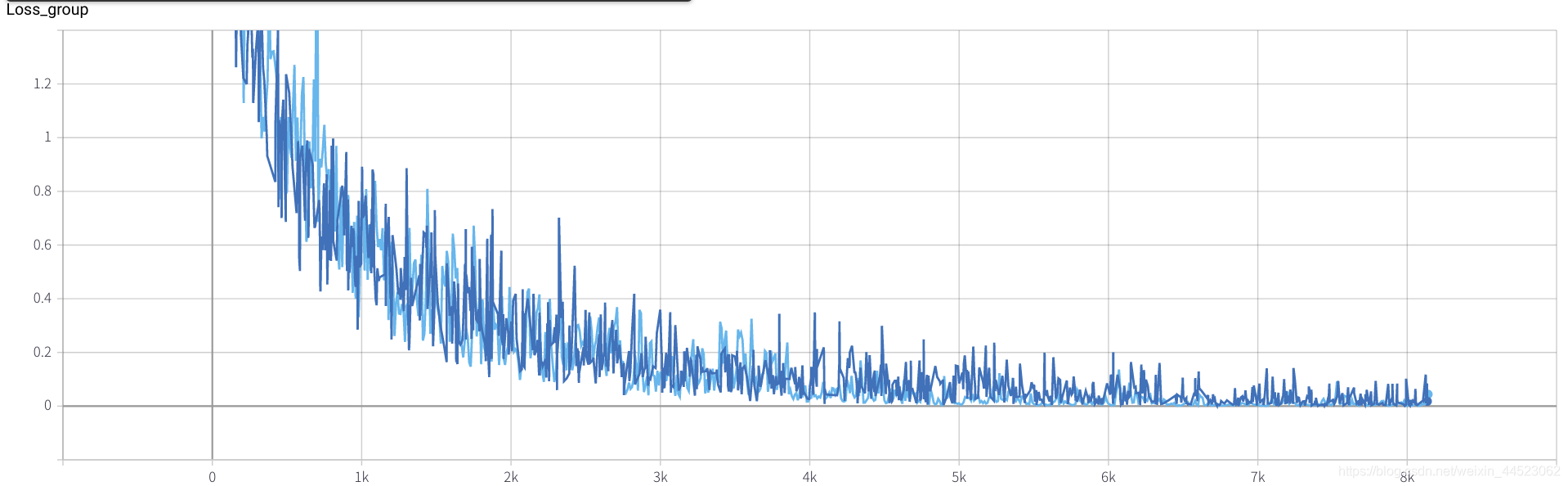
lr=0.01
10 前人谈batchsize
1 在一定范围内,一般来说 Batch_Size 越大,其确定的下降方向越准,引起训练震荡越小。
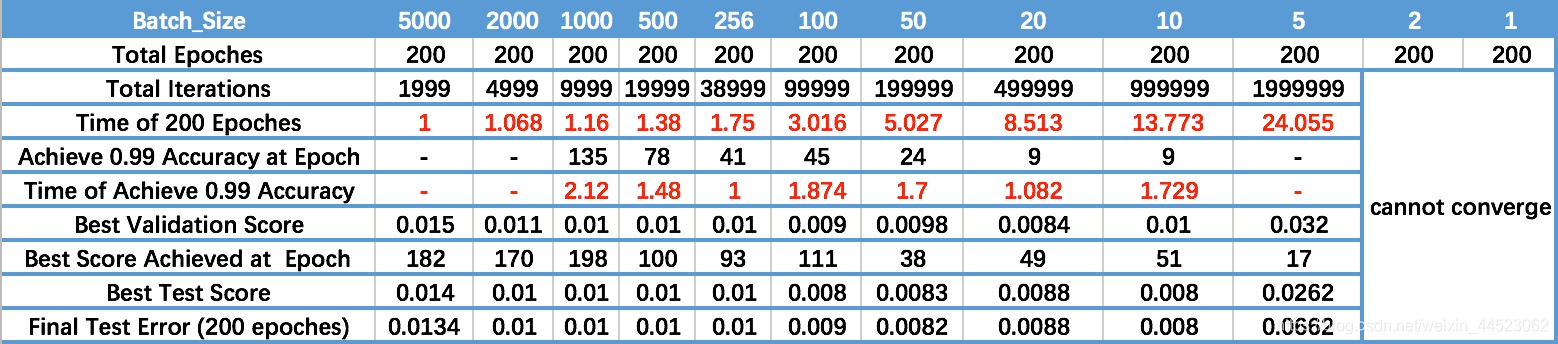
- 随着 Batch_Size 增大,达到相同精度所需要的 epoch 数量越来越多。倒数第三行
- 随着 Batch_Size 增大,处理相同数据量的速度越快。
- 由于上述两种因素的矛盾, Batch_Size 增大到某个时候,达到时间上的最优。
- 由于最终收敛精度会陷入不同的局部极值,因此 Batch_Size 增大到某些时候,达到最终收敛精度上的最优。
2 大的batchsize性能下降是因为训练时间不够长,本质上并不是batchsize的问题,在同样的epochs下的参数更新变少了,因此需要更长的迭代次数。
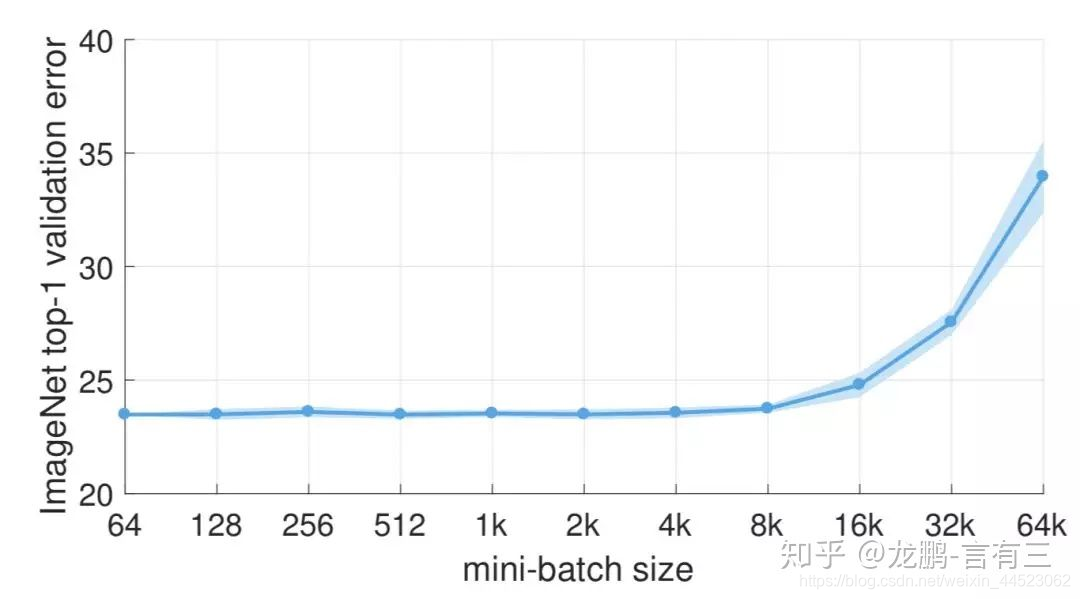
batchsize=8k之后错误率上升
3 大的batchsize收敛到sharp minimum,而小的batchsize收敛到flat minimum,后者具有更好的泛化能力。
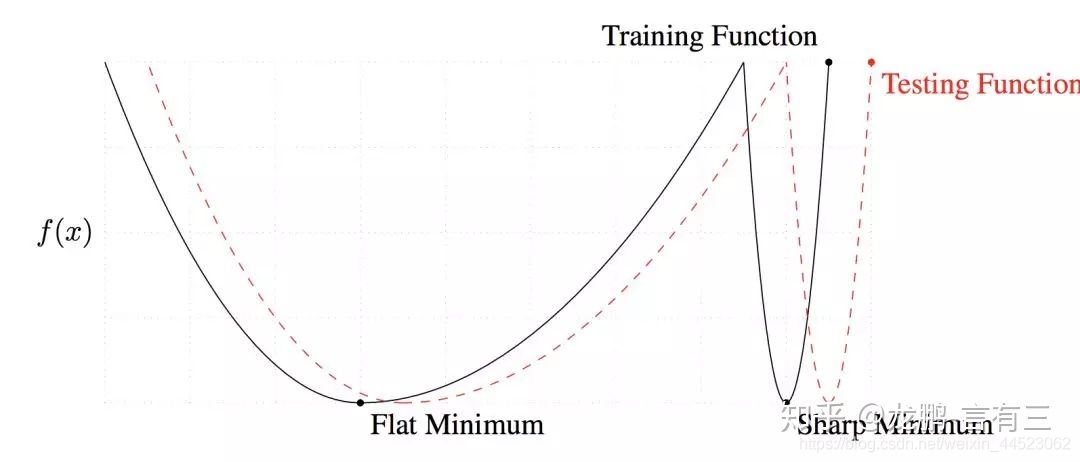
两者的区别就在于变化的趋势,一个快一个慢,如上图,造成这个现象的主要原因是小的batchsize带来的噪声有助于逃离sharp minimum。
4 Batchsize增加,学习率应随者增加
通常当我们增加batchsize为原来的N倍时,要保证经过同样的样本后更新的权重相等,按照线性缩放规则,学习率应该增加为原来的N倍[5]。但是如果要保证权重的方差不变,则学习率应该增加为原来的sqrt(N)倍[7],目前这两种策略都被研究过,使用前者的明显居多。
5 提升Batchsize大小等同 添加学习率衰减
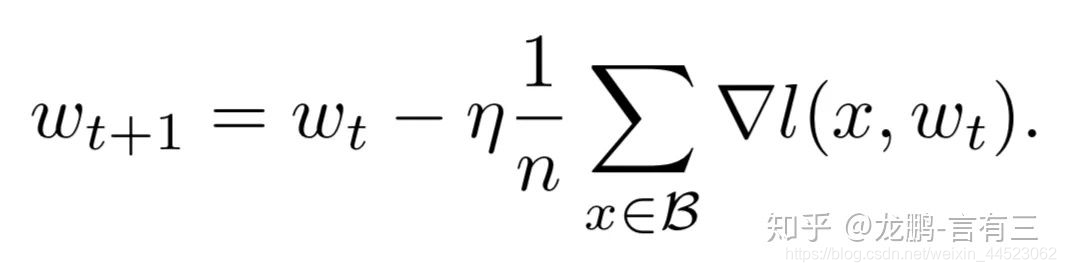
这实际上从SGD的权重更新式子就可以看出来两者确实是等价的,文中通过充分的实验验证了这一点
结论
1 如果增加了学习率,那么batch size最好也跟着增加,这样收敛更稳定。
2尽量使用大的学习率,因为很多研究都表明更大的学习率有利于提高泛化能力。如果真的要衰减,可以尝试其他办法,比如增加batch size,学习率对模型的收敛影响真的很大,慎重调整。
3 用bn的坏处就是不能用太小的batch size,要不然mean和variance就偏了。所以现在一般是显存能放多少就放多少。而且实际调起模型来,真的是数据分布和预处理更为重要,数据不行的话 玩再多花招也没用
参考阅读
https://zhuanlan.zhihu.com/p/29247151
https://zhuanlan.zhihu.com/p/64864995
