在前面我们已经介绍了Zookeeper的原生客户端和ZkClinet了,这里我们在介绍一种Zookeeper客户端——Curator,它也是开源的zk客户端,在原生API基础上封装的。在使用Curator之前,我们需要引入依赖
<!--对zookeeper的底层api的一些封装-->
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-framework</artifactId>
<version>4.3.0</version>
</dependency>
<!--封装了一些高级特性,如:Cache事件监听、选举、分布式锁、分布式Barrier-->
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-recipes</artifactId>
<version>4.3.0</version>
</dependency>
在使用Curator客户端去连接Zookeeper的时候,我们有两种方式去连接,首先我们看一种,其中Curator传递一个参数new ExponentialBackoffRetry(1000, 3),这参数的意思是表示首次连接1秒,失败后会重试3次,重试连接的时间每次会进行叠加
public class CuratorTest {
public static final String CONNENT_ADDR = "192.168.80.130:2181";
public static void main(String[] args) {
CuratorFramework curatorFramework = CuratorFrameworkFactory.newClient(CONNENT_ADDR,
5000, 5000, new ExponentialBackoffRetry(1000, 3));
curatorFramework.start();
}
}
Curator的连接的方式是fluent风格的,就是我们jdk8中lambda表达式一样,属于链式编程的风格。看下列的代码是不是和我们之前介绍的建造者模式来构造实体类是不是很类似
public class CuratorTest {
public static final String CONNENT_ADDR = "192.168.80.130:2181";
public static void main(String[] args) {
CuratorFramework curatorFramework = CuratorFrameworkFactory.builder()
.connectString(CONNENT_ADDR)
.connectionTimeoutMs(5000) //连接超时时间
.sessionTimeoutMs(5000) //会话超时时间
.retryPolicy(new ExponentialBackoffRetry(1000, 3))
.build();
curatorFramework.start();
}
}
创建节点
下面连接上后,我们就要开始创建我们的节点了,Curator客户端也是和ZkClinet一样,是支持我们递归创建所需的父节点的,我们只需加上.creatingParentsIfNeeded()
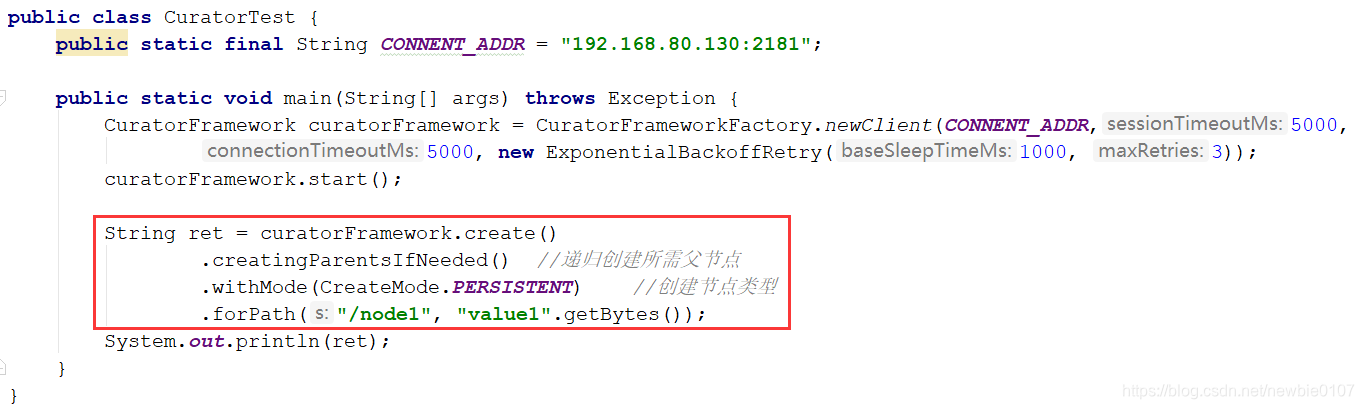
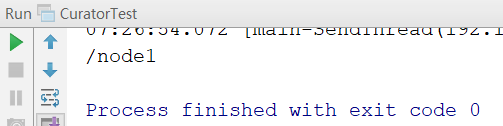
删除节点
既然支持递归创建父节点,那么它也是支持递归删除我们的父节点的,加上.deletingChildrenIfNeeded()即可,另外删除的时候我们可以添加.guarantedd()保证删除,以及使用版本控制,如下:

读取数据节点
然后我们再来看看如何读取节点中的数据信息,其实也很简单,如下:
Stat stat = new Stat();
byte[] bytes = curatorFramework.getData().storingStatIn(stat).forPath("/node1");
System.out.println(new String(bytes));
System.out.println(stat);
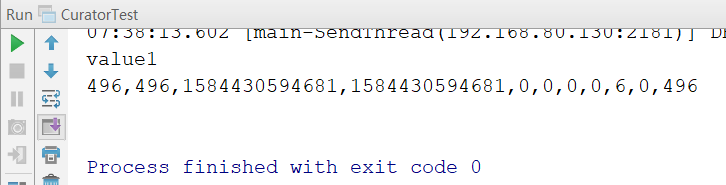
修改数据节点

判断节点是否存在及获取子节点

异步操作
另外Curator客户端还支持异步操作的,比如我们可以异步的创建一个节点,我们使用inBackgroud来创建一个后台进行,然后就可以异步创建我们的节点了
ExecutorService executorService = Executors.newFixedThreadPool(1);
CountDownLatch countDownLatch = new CountDownLatch(1);
curatorFramework.create()
.creatingParentsIfNeeded()
.withMode(CreateMode.PERSISTENT)
.inBackground(new BackgroundCallback() {
@Override
public void processResult(CuratorFramework curatorFramework, CuratorEvent curatorEvent) throws Exception {
System.out.println("resultCode:" + curatorEvent.getResultCode() + ", eventType:" + curatorEvent.getType());
countDownLatch.countDown();
}
}, executorService)
.forPath("/node1");
countDownLatch.await();
executorService.shutdown();
这里我们使用了一个固定线程为1的线程池去执行的;另外还使用了CountDownLatch来保证节点创建成功,打印出信息,一般在项目中是不需要的,这里是为了防止测试程序过早结束。
还是上述是用来匿名内部类,这里我们也是可以改为lambda表达式的,更加贴近Curator的fluent风格,我们发现lambda表达式其实也是非常简单的,我们需要将匿名内部类的方法参数放置在 -> 前,方法中的处理内容放置在 -> 后即可,这里为了避免和外部变量重名,参数命名后加了一个数字2用于区分
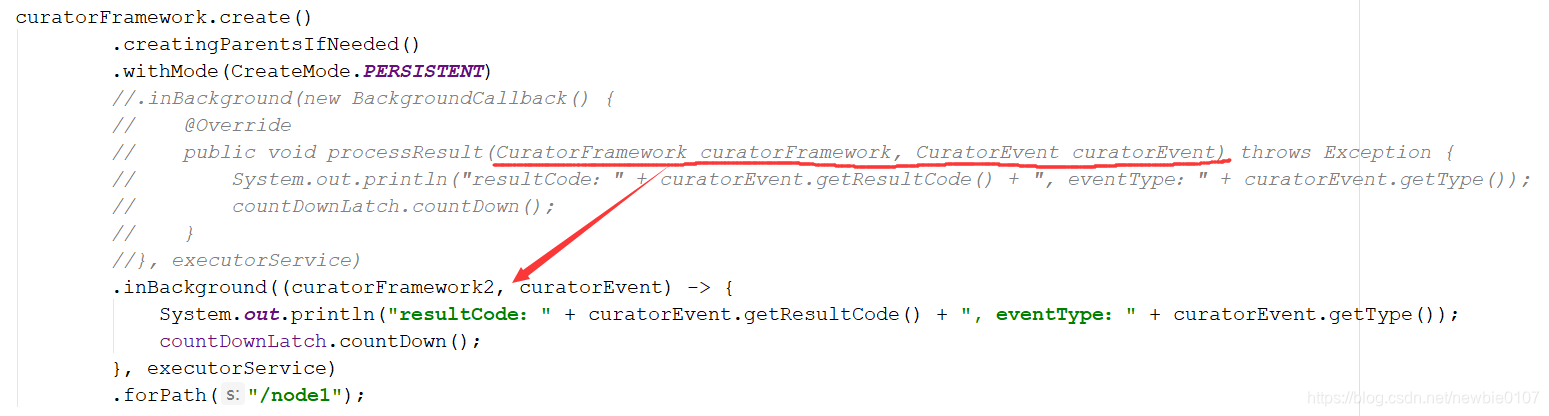
事务操作
最后我们还要提一下,Curator比较牛逼的地方在于,它还支持事务操作,如下:
public class CuratorTest {
public static final String CONNENT_ADDR = "192.168.80.130:2181";
public static void main(String[] args) throws Exception {
CuratorFramework curatorFramework = CuratorFrameworkFactory.newClient(CONNENT_ADDR, 5000,
5000, new ExponentialBackoffRetry(1000, 3));
curatorFramework.start();
Collection<CuratorTransactionResult> curatorTransactionResults = curatorFramework.inTransaction()
.create().forPath("/node1", "value1".getBytes()).and()
.create().forPath("/node2", "value2".getBytes()).and()
.setData().forPath("/node3", "value3".getBytes()).and().commit();
//遍历输出结果
for(CuratorTransactionResult result : curatorTransactionResults) {
System.out.println("执行结果是:" + result.getForPath() + "->" + result.getType());
}
}
}

如果我们使用的版本较高,可能.inTransaction()已经不建议使用了,那我们也可以选择使用.transaction()

