文章目录
一、说明
昨天突然想着把PDF转成图片,昨天尝试了许久,没有成功,然后就很纳闷,图片合成PDF就可以,应该转成图片也可以吧,然后网上各种找解决这个问题的方法。
如果需要图片合成PDF的,可以参考一下我之前的一个博客:
使用img2pdf 模块将目录下图片合并成pdf
二、PDF转图片
方法1:PyMuPDF(成功)
①、安装PyMuPDF:
pip install PyMuPDF
②、转换图片代码:
import datetime
import os
import fitz # fitz就是pip install PyMuPDF
def pyMuPDF_fitz(pdfPath, imagePath):
startTime_pdf2img = datetime.datetime.now() # 开始时间
print("imagePath=" + imagePath)
pdfDoc = fitz.open(pdfPath)
for pg in range(pdfDoc.pageCount):
page = pdfDoc[pg]
rotate = int(0)
# 每个尺寸的缩放系数为1.3,这将为我们生成分辨率提高2.6的图像。
# 此处若是不做设置,默认图片大小为:792X612, dpi=96
zoom_x = 1.33333333 # (1.33333333-->1056x816) (2-->1584x1224)
zoom_y = 1.33333333
mat = fitz.Matrix(zoom_x, zoom_y).preRotate(rotate)
pix = page.getPixmap(matrix=mat, alpha=False)
if not os.path.exists(imagePath): # 判断存放图片的文件夹是否存在
os.makedirs(imagePath) # 若图片文件夹不存在就创建
pix.writePNG(imagePath + '/' + 'images_%s.png' % pg) # 将图片写入指定的文件夹内
endTime_pdf2img = datetime.datetime.now() # 结束时间
print('pdf2img时间=', (endTime_pdf2img - startTime_pdf2img).seconds)
if __name__ == "__main__":
# 1、PDF地址
pdfPath = 'demo1.pdf'
# 2、需要储存图片的目录
imagePath = './imgs'
pyMuPDF_fitz(pdfPath, imagePath)
使用时,只需要更改PDF地址和储存图片地址即可。
方法2:pdf2image(未成功)
①、安装pdf2image
pip install pdf2image
②、安装Poppler:
如果下载慢,可以下载我云盘中的:
下载地址: 密码:e17b
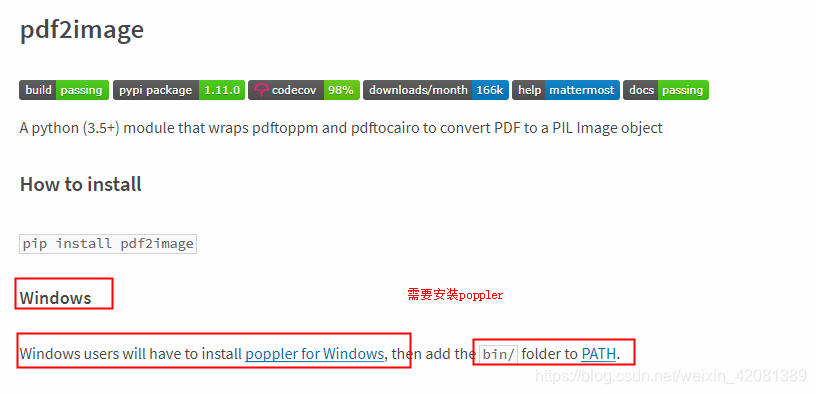
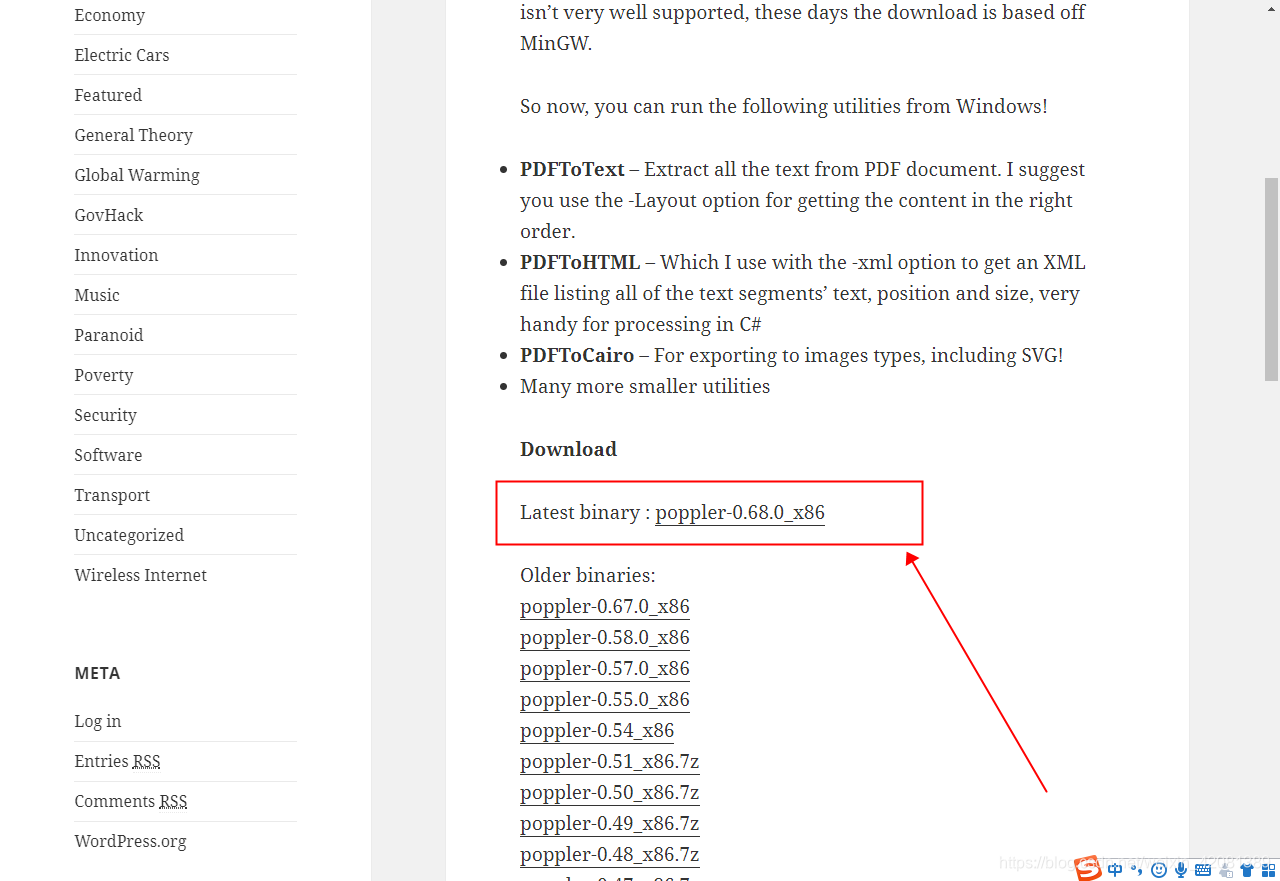
解压之后放到自己的软件盘,然后把bin目录添加到系统环境变量。然后重启电脑。
如果不重启,转换时会报错:pdf2image.exceptions.PDFInfoNotInstalledError: Unable to get page count. Is poppler installed and in PATH?。
但是我的重启之后还有有问题,不知道为什么,只能回家用家里电脑测试一下了,不知道是不是Windows弄不了。
我只是用了模块官方几句代码:就一直报错:
from pdf2image import convert_from_path, convert_from_bytes
from pdf2image.exceptions import (
PDFInfoNotInstalledError,
PDFPageCountError,
PDFSyntaxError
)
images = convert_from_path('demo1.pdf')
报错内容:
Exception in thread Thread-1:
Traceback (most recent call last):
File "D:\tools\Python3.6\lib\threading.py", line 916, in _bootstrap_inner
self.run()
File "D:\tools\Python3.6\lib\threading.py", line 864, in run
self._target(*self._args, **self._kwargs)
File "D:\tools\Python3.6\lib\subprocess.py", line 1084, in _readerthread
buffer.append(fh.read())
File "D:\tools\Python3.6\lib\codecs.py", line 322, in decode
(result, consumed) = self._buffer_decode(data, self.errors, final)
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xd6 in position 119: invalid continuation byte
Traceback (most recent call last):
File "D:\tools\Python3.6\lib\site-packages\pdf2image\pdf2image.py", line 420, in pdfinfo_from_path
raise ValueError
ValueError
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "D:/zjf_workspace/000、爬虫代码-基础的/scrapy_100_工具/8、图片处理/6、pdf转换成图片/7、pdf2image模块.py", line 9, in <module>
images = convert_from_path('demo1.pdf')
File "D:\tools\Python3.6\lib\site-packages\pdf2image\pdf2image.py", line 90, in convert_from_path
page_count = pdfinfo_from_path(pdf_path, userpw, poppler_path=poppler_path)["Pages"]
File "D:\tools\Python3.6\lib\site-packages\pdf2image\pdf2image.py", line 430, in pdfinfo_from_path
"Unable to get page count.\n%s" % err.decode("utf8", "ignore")
AttributeError: 'str' object has no attribute 'decode'
弄了快一天了,没有弄出来这个问题,我找到好多相似的博客,但是都不能运行,而且人家好想都没有出现这个问题,不知道我这里咋会这样,就先放这吧,后续如果解决再来补充。
方法3、wind(已经成功)
这个我昨天试了很久,一直报错,今天看到一个文章,赶紧是却少一个软件Ghostscript,但是下载又好慢呀,不知道什么鬼。
好像有个这个软件Ghostscript:
打算按着这个文章,再次测试:
可以用第三方库wand实,需要安装wand 、imagemagick和ghostscript。作者都成功了,那我就再试试吧。
①、安装wind
pip install Wand
②、安装imagemagick
安装过程注意勾选Install development headers and libraries for C and C++ 。安装后设置MAGICK_HOME环境变量,值为imagemagick的安装路径,并将安装路径加入path。
详情可参照此页面网页链接。
③、安装ghostscript
我做天一直尝试,就是保错:
报错内容
Traceback (most recent call last):
File "D:/zjf_workspace/000、爬虫代码-基础的/scrapy_100_工具/8、图片处理/6、pdf转换成图片/1、wand.py", line 7, in <module>
image_pdf = Image(filename='demo1.pdf')
File "D:\tools\Python3.6\lib\site-packages\wand\image.py", line 8230, in __init__
units=units)
File "D:\tools\Python3.6\lib\site-packages\wand\image.py", line 8710, in read
self.raise_exception()
File "D:\tools\Python3.6\lib\site-packages\wand\resource.py", line 243, in raise_exception
raise e
wand.exceptions.DelegateError: FailedToExecuteCommand `"gswin32c.exe" -q -dQUIET -dSAFER -dBATCH -dNOPAUSE -dNOPROMPT -dMaxBitmap=500000000 -dAlignToPixels=0 -dGridFitTT=2 "-sDEVICE=pngalpha" -dTextAlphaBits=4 -dGraphicsAlphaBits=4 "-r72x72" "-sOutputFile=C:/Users/WB-ZJF~1/AppData/Local/Temp/magick-5508WXCmlxua21eN%d" "-fC:/Users/WB-ZJF~1/AppData/Local/Temp/magick-5508Te_4KPmLv3_D" "-fC:/Users/WB-ZJF~1/AppData/Local/Temp/magick-5508byOzda8sSbWf"' (ϵͳ�Ҳ���ָ�����ļ���
) @ error/delegate.c/ExternalDelegateCommand/459
感觉就是跟这个有关吧,但是下载又下载不动,估计也是只能明天测试了,如果有Windows做成小伙伴欢迎赐教,我也只能回家再下载测试了,公司电脑不知道为什么下载不动。
我下载好的ghostscript
如果你看到这里了,可以下载我下载好的:
我这个关于PDF转图片的所有软件都放到这里了,需要可以下载,比网上和度盘都下载快。
ghostscript的文件名称:gs950w64.exe
软件下载地址: 密码:duym
④、代码:
这个是我找到之后修改的,但是报错问题还没有解决,只能后续解决补充了。先用第一个方法用着吧。
上面几个下载好就可以直接使用我这个代码了,这个代码是我成功测试之后的,修改PDF地址和图片储存地址即可。
# coding:utf-8
from wand.image import Image
def wind_imagemagick_ghostscript(pdf_path, imgs_dir):
# 将pdf文件转为jpg图片文件
# ./PDF_FILE_NAME 为pdf文件路径和名称
# image_pdf = Image(filename='./demo1.pdf', resolution=300)
image_pdf = Image(filename=pdf_path)
image_jpeg = image_pdf.convert('jpeg')
# wand已经将PDF中所有的独立页面都转成了独立的二进制图像对象。我们可以遍历这个大对象,并把它们加入到req_image序列中去。
req_image = []
for img in image_jpeg.sequence:
img_page = Image(image=img)
req_image.append(img_page.make_blob('jpeg'))
# 遍历req_image,保存为图片文件
i = 0
for img in req_image:
ff = open(imgs_dir + '\\' + str(i) + '.jpeg', 'wb')
ff.write(img)
ff.close()
i += 1
if __name__ == '__main__':
pdf_path = r"demo1.pdf"
imgs_dir = r"imgs"
wind_imagemagick_ghostscript(pdf_path, imgs_dir)
方法4、imagemagick+ghostscript(已经成功)
这个还是我看到一篇博客:
之后,然后第三个方法也成功了,然后测试这个也成功了,具体步骤:
这些软件可以直接去我的云盘下载,如果失效自己就官网下载吧:
软件集合下载地址: 密码:duym
①、安装imagemagick
安装过程注意勾选Install development headers and libraries for C and C++ 。安装后设置MAGICK_HOME环境变量,值为imagemagick的安装路径,并将安装路径加入path。
详情可参照此页面网页链接。
建议优先去我网盘下载(如果还有效)。
②、安装ghostscript
如果你也是Windows64位,去我云盘下载:
③、cmd命令转换:
一个命令转换:
magick .\demo1.pdf .\111\demo.jpg
查看执行命令和效果:
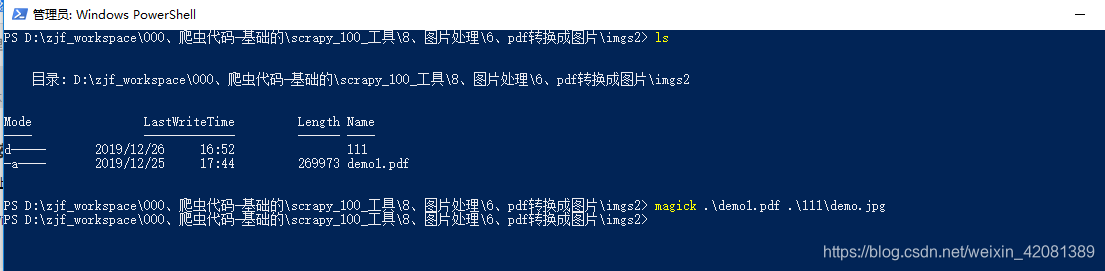
111目录下面的图片:(可以看出,自动从刚刚输入的jpg前面自动demo后面加上递增后缀,这个可以PDF的页面顺序下标对应)
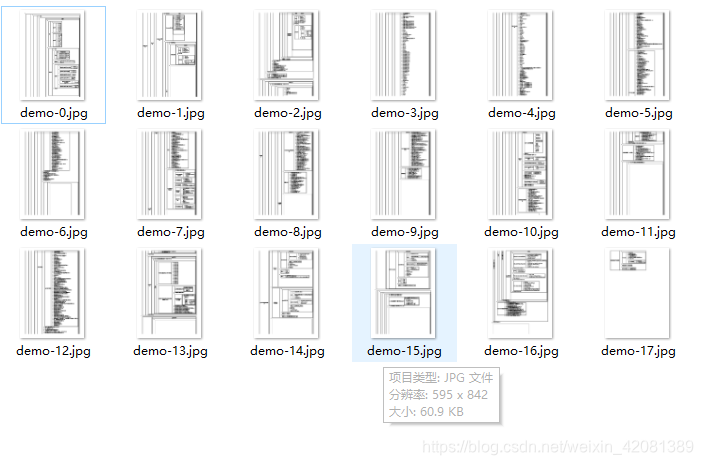
④、一般只是转换一俩个上一步就行了,如果数量过多,可以用python写个脚本。
import os
def os_magick(pdf_path,img_dir,file_name):
os.system(r'magick {} {}/{}.jpg'.format(pdf_path,img_dir,file_name))
if __name__ == '__main__':
pdf_path = r"demo1.pdf"
img_dir = r'imgs3'
# 图片名字的前缀
file_name = 'demo'
os_magick(pdf_path,img_dir,file_name)
注意点:
- pdf_path 和img_dir 必须填写绝对路径地址(我这里我前面地址删除了,看懂就好)
- 文件名的前缀可以自己定义
- 如果数量过多,并且需要储存的文件夹不同,可以自动创建目录,不过最后出入函数的还是绝对路径。
我的这个生成效果:
参考:
https://github.com/Belval/pdf2image
ttp://blog.alivate.com.au/poppler-windows/
https://imagemagick.org/script/download.php#windows
http://docs.wand-py.org/en/0.4.4/guide/install.html#install-imagemagick-windows
https://ghostscript.com/download/gsdnld.html
https://www.jianshu.com/p/f57cc64b9f5e
https://www.twblogs.net/a/5d483d89bd9eee541c30323b
http://blog.sciencenet.cn/blog-597740-1136907.html
https://www.jb51.net/article/160622.htm
https://www.ancii.com/an676u83y/
https://blog.csdn.net/qq_24127015/article/details/85111371
